正则表达式-----------------------------------C#的正则表达式
为了避免以后这样的情况,在此记录下正则表达式的一些基本使用方法附带小的实例。让以后在使用时能一目了然知道他的使用,为开发节约时间,同时也分享给大家
正则元字符
在说正则表达式之前我们先来看看通配符,我想通配符大家都用过。通配符主要有星号(*)和问号(?),用来模糊搜索文件。winodws中我们常会使用搜索来查找一些文件。如:*.jpg,XXX.docx的方式,来快速查找文件。其实正则表达式和我们通配符很相似也是通过特定的字符匹配我们所要查询的内容信息。已下代码都是区分大小写。
常用元字符
| 代码 | 说明 |
| . | 匹配除换行符以外的任意字符。 |
| \w | 匹配字母或数字或下划线或汉字。 |
| \s | 匹配任意的空白符。 |
| \d | 匹配数字。 |
| \b | 匹配单词的开始或结束。 |
| [ck] | 匹配包含括号内元素的字符 |
| ^ | 匹配行的开始。 |
| $ | 匹配行的结束。 |
| \ | 对下一个字符转义。比如$是个特殊的字符。要匹配$的话就得用\$ |
| | | 分支条件,如:x|y匹配 x 或 y。 |
反义元字符
| 代码 | 说明 |
| \W | 匹配任意不是字母,数字,下划线,汉字的字符。 |
| \S | 匹配任意不是空白符的字符。等价于 [^ \f\n\r\t\v]。 |
| \D | 匹配任意非数字的字符。等价于 [^0-9]。 |
| \B | 匹配不是单词开头或结束的位置。 |
| [^CK] | 匹配除了CK以外的任意字符。 |
特殊元字符
| 代码 | 说明 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
限定符
| 代码 | 说明 |
| * | 匹配前面的子表达式零次或多次。 |
| + | 匹配前面的子表达式一次或多次。 |
| ? | 匹配前面的子表达式零次或一次。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。 |
| {n,} | n 是一个非负整数。至少匹配n 次。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
懒惰限定符
| 代码 | 说明 |
| *? |
重复任意次,但尽可能少重复。 如 "acbacb" 正则 "a.*?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,只会匹配尽可能少的字符 ,而"acbacb"最少字符的结果就是"acb" 。 |
| +? | 重复1次或更多次,但尽可能少重复。与上面一样,只是至少要重复1次。 |
| ?? |
重复0次或1次,但尽可能少重复。 如 "aaacb" 正则 "a.??b" 只会取到最后的三个字符"acb"。 |
| {n,m}? |
重复n到m次,但尽可能少重复。 如 "aaaaaaaa" 正则 "a{0,m}" 因为最少是0次所以取到结果为空。 |
| {n,}? |
重复n次以上,但尽可能少重复。 如 "aaaaaaa" 正则 "a{1,}" 最少是1次所以取到结果为 "a"。 |
捕获分组
| 代码 | 说明 |
| (exp) | 匹配exp,并捕获文本到自动命名的组里。 |
| (?<name>exp) | 匹配exp,并捕获文本到名称为name的组里。 |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号以下为零宽断言。 |
| (?=exp) |
匹配exp前面的位置。 如 "How are you doing" 正则"(?<txt>.+(?=ing))" 这里取ing前所有的字符,并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为"How are you do"; |
| (?<=exp) |
匹配exp后面的位置。 如 "How are you doing" 正则"(?<txt>(?<=How).+)" 这里取"How"之后所有的字符,并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为" are you doing"; |
| (?!exp) |
匹配后面跟的不是exp的位置。 如 "123abc" 正则 "\d{3}(?!\d)"匹配3位数字后非数字的结果 |
| (?<!exp) |
匹配前面不是exp的位置。 如 "abc123 " 正则 "(?<![0-9])123" 匹配"123"前面是非数字的结果也可写成"(?!<\d)123" |
得到上面秘籍后我们可以小试牛刀...
小试牛刀
在C#中使用正则表达式主要是通过Regex类来实现。命名空间:using System.Text.RegularExpressions。
其中常用方法:
| 名称 | 说明 |
| IsMatch(String, String) | 指示 Regex 构造函数中指定的正则表达式在指定的输入字符串中是否找到了匹配项。 |
| Match(String, String) | 在指定的输入字符串中搜索 Regex 构造函数中指定的正则表达式的第一个匹配项。 |
| Matches(String, String) | 在指定的输入字符串中搜索正则表达式的所有匹配项。 |
| Replace(String, String) | 在指定的输入字符串内,使用指定的替换字符串替换与某个正则表达式模式匹配的所有字符串。 |
| Split(String, String) | 在由 Regex 构造函数指定的正则表达式模式所定义的位置,拆分指定的输入字符串。 |
在使用正则表达式前我们先来看看“@”符号的使用。
学过C#的人都知道C# 中字符串常量可以以@ 开头声名,这样的优点是转义序列“不”被处理,按“原样”输出,即我们不需要对转义字符加上 \ (反斜扛),就可以轻松coding。如:
如要在一个用 @ 引起来的字符串中包括一个双引号,就需要使用两对双引号了。这时候你不能使用 \ 来转义爽引号了,因为在这里 \ 的转义用途已经被 @ “屏蔽”掉了。如:
字符串匹配:
在实际项目中我们常常需要对用户输入的信息进行验证。如:匹配用户输入的内容是否为数字,是否为有效的手机号码,邮箱是否合法....等。
实例代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
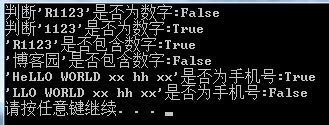
string RegexStr = string.Empty;#region 字符串匹配RegexStr = "^[0-9]+$"; //匹配字符串的开始和结束是否为0-9的数字[定位字符]Console.WriteLine("判断'R1123'是否为数字:{0}", Regex.IsMatch("R1123", RegexStr));Console.WriteLine("判断'1123'是否为数字:{0}", Regex.IsMatch("1123", RegexStr));RegexStr = @"\d+"; //匹配字符串中间是否包含数字(这里没有从开始进行匹配噢,任意位子只要有一个数字即可)Console.WriteLine("'R1123'是否包含数字:{0}", Regex.IsMatch("R1123", RegexStr));Console.WriteLine("'博客园'是否包含数字:{0}", Regex.IsMatch("博客园", RegexStr));//感谢@zhoumy的提醒..已修改错误代码RegexStr = @"^Hello World[\w\W]*"; //已Hello World开头的任意字符(\w\W:组合可匹配任意字符)Console.WriteLine("'HeLLO WORLD xx hh xx'是否已Hello World开头:{0}", Regex.IsMatch("HeLLO WORLD xx hh xx", RegexStr, RegexOptions.IgnoreCase));Console.WriteLine("'LLO WORLD xx hh xx'是否已Hello World开头:{0}", Regex.IsMatch("LLO WORLD xx hh xx", RegexStr,RegexOptions.IgnoreCase));//RegexOptions.IgnoreCase:指定不区分大小写的匹配。#endregion |
显示结果:
字符串查找:
实例代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
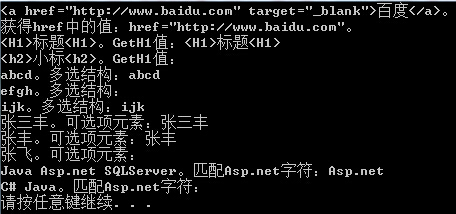
string RegexStr = string.Empty; #region 字符串查找RegexStr = @"href=""[\S]+"""; // ""匹配"Match mt = Regex.Match(LinkA, RegexStr);Console.WriteLine("{0}。", LinkA);Console.WriteLine("获得href中的值:{0}。", mt.Value);RegexStr = @"<h[^23456]>[\S]+<h[1]>"; //<h[^23456]>:匹配h除了2,3,4,5,6之中的值,<h[1]>:h匹配包含括号内元素的字符Console.WriteLine("{0}。GetH1值:{1}", "<H1>标题<H1>", Regex.Match("<H1>标题<H1>", RegexStr, RegexOptions.IgnoreCase).Value);Console.WriteLine("{0}。GetH1值:{1}", "<h2>小标<h2>", Regex.Match("<h2>小标<h2>", RegexStr, RegexOptions.IgnoreCase).Value);//RegexOptions.IgnoreCase:指定不区分大小写的匹配。RegexStr = @"ab\w+|ij\w{1,}"; //匹配ab和字母 或 ij和字母Console.WriteLine("{0}。多选结构:{1}", "abcd", Regex.Match("abcd", RegexStr).Value);Console.WriteLine("{0}。多选结构:{1}", "efgh", Regex.Match("efgh", RegexStr).Value);Console.WriteLine("{0}。多选结构:{1}", "ijk", Regex.Match("ijk", RegexStr).Value);RegexStr = @"张三?丰"; //?匹配前面的子表达式零次或一次。Console.WriteLine("{0}。可选项元素:{1}", "张三丰", Regex.Match("张三丰", RegexStr).Value);Console.WriteLine("{0}。可选项元素:{1}", "张丰", Regex.Match("张丰", RegexStr).Value);Console.WriteLine("{0}。可选项元素:{1}", "张飞", Regex.Match("张飞", RegexStr).Value);/* 例如:July|Jul 可缩短为 July?4th|4 可缩短为 4(th)?*///匹配特殊字符RegexStr = @"Asp\.net"; //匹配Asp.net字符,因为.是元字符他会匹配除换行符以外的任意字符。这里我们只需要他匹配.字符即可。所以需要转义\.这样表示匹配.字符Console.WriteLine("{0}。匹配Asp.net字符:{1}", "Java Asp.net SQLServer", Regex.Match("Java Asp.net SQLServer", RegexStr).Value);Console.WriteLine("{0}。匹配Asp.net字符:{1}", "C# Java", Regex.Match("C# Java", RegexStr).Value);#endregion |
显示结果:
贪婪与懒惰
|
1
2
3
4
5
6
7
8
9
10
|
string f = "fooot";//贪婪匹配RegexStr = @"f[o]+";Match m1 = Regex.Match(f, RegexStr);Console.WriteLine("{0}贪婪匹配(匹配尽可能多的字符):{1}", f, m1.ToString());//懒惰匹配RegexStr = @"f[o]+?";Match m2 = Regex.Match(f, RegexStr);Console.WriteLine("{0}懒惰匹配(匹配尽可能少重复):{1}", f, m2.ToString()); |
显示结果:
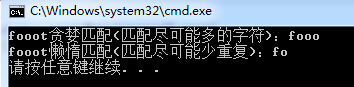
从上面的例子中我们不难看出贪婪与懒惰的区别,他们的名子取的都很形象。
贪婪匹配:匹配尽可能多的字符。
懒惰匹配:匹配尽可能少的字符。
(exp)分组
在做爬虫时我们经常获得A中一些有用信息。如href,title和显示内容等。
|
1
2
3
4
5
6
7
|
string TaobaoLink = "<a href=\"http://www.taobao.com\" title=\"淘宝网 - 淘!我喜欢\" target=\"_blank\">淘宝</a>";RegexStr = @"<a[^>]+href=""(\S+)""[^>]+title=""([\s\S]+?)""[^>]+>(\S+)</a>";Match mat = Regex.Match(TaobaoLink, RegexStr);for (int i = 0; i < mat.Groups.Count; i++){ Console.WriteLine("第"+i+"组:"+mat.Groups[i].Value);} |
显示结果:
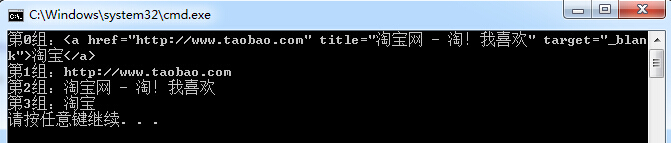
在正则表达式里使用()包含的文本自动会命名为一个组。上面的表达式中共使用了4个()可以认为是分为了4组。
输出结果共分为:4组。
0组:为我们所匹配的字符串。
1组:是我们第一个括号[href=""(\S+)""]中(\S+)所匹配的网址信息。内容为:http://www.taobao.com。
2组:是第二个括号[title=""([\s\S]+?)""]中所匹配的内容信息。内容为:淘宝网 - 淘!我喜欢。
这里我们会看到+?懒惰限定符。title=""([\s\S]+?)"" 这里+?的下一个字符为"双引号,"双引号在匹配字符串后面还有三个。+?懒惰限定符会尽可能少重复,所他会匹配最前面那个"双引号。如果我们不使用+?懒惰限定符他会匹配到:淘宝网 - 淘!我喜欢" target= 会尽可能多重复匹配。
3组:是第三个括号[(\S+)]所匹配的内容信息。内容为:淘宝。
说明:反义元字符所对应的元字符都能组合匹配任意字符。如:[\w\W],[\s\S],[\d\D]..
(?<name>exp) 分组取名
当我们匹配分组信息过多后,在某种场合只需取当中某几组信息。这时我们可以对分组取名。通过分组名称来快速提取对应信息。
|
1
2
3
4
|
string Resume = "基本信息姓名:CK|求职意向:.NET软件工程师|性别:男|学历:本专|出生日期:1988-08-08|户籍:湖北.孝感|E - Mail:9245162@qq.com|手机:15000000000";RegexStr = @"姓名:(?<name>[\S]+)\|\S+性别:(?<sex>[\S]{1})\|学历:(?<xueli>[\S]{1,10})\|出生日期:(?<Birth>[\S]{10})\|[\s\S]+手机:(?<phone>[\d]{11})";Match matc = Regex.Match(Resume, RegexStr);Console.WriteLine("姓名:{0},手机号:{1}", matc.Groups["name"].ToString(), matc.Groups["phone"].ToString()); |
显示结果:
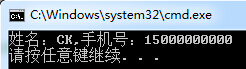
通过(?<name>exp)可以很轻易为分组取名。然后通过Groups["name"]取得分组值。
获得页面中A标签中href值
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
string PageInfo = @"<hteml> <div id=""div1""> <a href=""http://www.baidu.con"" target=""_blank"">百度</a> <a href=""http://www.taobao.con"" target=""_blank"">淘宝</a> <a href=""http://www.cnblogs.com"" target=""_blank"">博客园</a> <a href=""http://www.google.con"" target=""_blank"">google</a> </div> <div id=""div2""> <a href=""/zufang/"">整租</a> <a href=""/hezu/"">合租</a> <a href=""/qiuzu/"">求租</a> <a href=""/ershoufang/"">二手房</a> <a href=""/shangpucz/"">商铺出租</a> </div> </hteml>";RegexStr = @"<a[^>]+href=""(?<href>[\S]+?)""[^>]*>(?<text>[\S]+?)</a>";MatchCollection mc = Regex.Matches(PageInfo, RegexStr);foreach (Match item in mc){ Console.WriteLine("href:{0}--->text:{1}",item.Groups["href"].ToString(),item.Groups["text"].ToString());} |
显示结果:
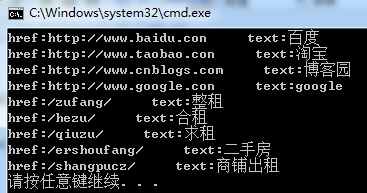
Replace 替换字符串
用户在输入信息时偶尔会包含一些敏感词,这时我们需要替换这个敏感词。
|
1
2
3
4
5
|
string PageInputStr = "靠.TMMD,今天真不爽....";RegexStr = @"靠|TMMD|妈的";Regex rep_regex = new Regex(RegexStr);Console.WriteLine("用户输入信息:{0}", PageInputStr);Console.WriteLine("页面显示信息:{0}", rep_regex.Replace(PageInputStr, "***")); |
显示结果:
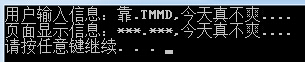
对一些敏感词直接替换成***代替。
Split 拆分字符串
|
1
2
3
4
5
6
7
8
|
string SplitInputStr = "1xxxxx.2ooooo.3eeee.4kkkkkk.";RegexStr = @"\d";Regex spl_regex = new Regex(RegexStr);string[] str = spl_regex.Split(SplitInputStr);foreach (string item in str){ Console.WriteLine(item);} |
显示结果:
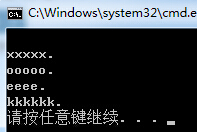
根据数字截取字符串。
首先,我们先看几个实际的例子:
1. 验证输入字符是否
javascript:
var ex = "^\\w+$";
var re = new RegExp(ex,"i");
return re.test(str);
VBScript
Dim regEx,flag,ex
ex = "^\w+$"
Set regEx = New RegExp
regEx.IgnoreCase = True
regEx.Global = True
regEx.Pattern = ex
flag = regEx.Test( str )
C#
System.String ex = @"^\w+$";
System.Text.RegularExpressions.Regex reg = new Regex( ex );
bool flag = reg.IsMatch( str );
2. 验证邮件格式
C#
System.String ex = @"^\w+@\w+\.\w+$";
System.Text.RegularExpressions.Regex reg = new Regex( ex );
bool flag = reg.IsMatch( str );
3. 更改日期的格式(用 dd-mm-yy 的日期形式代替 mm/dd/yy 的日期形式)
C#
String MDYToDMY(String input)
{
return Regex.Replace(input,
"\\b(?\\d{1,2})/(?\\d{1,2})/(?\\d{2,4})\\b",
"${day}-${month}-${year}");
}
4. 从 URL 提取协议和端口号
C#
String Extension(String url)
{
Regex r = new Regex(@"^(?\w+)://[^/]+?(?:\d+)?/",
RegexOptions.Compiled);
return r.Match(url).Result("${proto}${port}");
}
这里的例子可能是我们在网页开发中,通常会碰到的一些正则表达式,尤其在第一个例子中,给出了使用javascript,vbScript,C#等不同语言的实现方式,大家不难看出,对于不同的语言来说,正则表达式没有区别,只是正则表达式的实现类不同而已。而如何发挥正则表达式的公用,也要看实现类的支持。
(摘自msdn: Microsoft .NET 框架 SDK 提供大量的正则表达式工具,使您能够高效地创建、比较和修改字符串,以及迅速地分析大量文本和数据以搜索、移除和替换文本模式。ms-help://MS.VSCC/MS.MSDNVS.2052/cpgenref/html/cpconregularexpressionslanguageelements.htm)
下面我们逐个来分析这些例子:
1-2,这两个例子很简单,只是简单的验证字符串是否符合正则表达式规定的格式,其中使用的语法,在第一篇文章中都已经介绍过了,这里做一下简单的描述。
第1个例子的表达式: ^\w+$
^ -- 表示限定匹配开始于字符串的开始
\w – 表示匹配英文字符
+ -- 表示匹配字符出现1次或多次
$ -- 表示匹配字符到字符串结尾处结束
验证形如asgasdfs的字符串
第2个例子的表达式: ^\w+@\w+.\w+$
^ -- 表示限定匹配开始于字符串的开始
\w – 表示匹配英文字符
+ -- 表示匹配字符出现1次或多次
@ -- 匹配普通字符@
\. – 匹配普通字符.(注意.为特殊字符,因此要加上\转译)
$ -- 表示匹配字符到字符串结尾处结束
验证形如dragontt@sina.com的邮件格式
第3 个例子中,使用了替换,因此,我们还是先来看看正则表达式中替换的定义:
(ms-help://MS.VSCC/MS.MSDNVS.2052/cpgenref/html/cpconsubstitutions.htm)
替换
字符
含义
$123
替换由组号 123(十进制)匹配的最后一个子字符串。
${name}
替换由 (? ) 组匹配的最后一个子字符串。
$$
替换单个“$”字符。
$&
替换完全匹配本身的一个副本。
$`
替换匹配前的输入字符串的所有文本。
$'
替换匹配后的输入字符串的所有文本。
$+
替换最后捕获的组。
$_
替换整个输入字符串。
分组构造
(ms-help://MS.VSCC/MS.MSDNVS.2052/cpgenref/html/cpcongroupingconstructs.htm)
分组构造
定义
( )
捕获匹配的子字符串(或非捕获组;有关更多信息,请参阅正则表达式选项中的 ExplicitCapture 选项。)使用 () 的捕获根据左括号的顺序从 1 开始自动编号。捕获元素编号为零的第一个捕获是由整个正则表达式模式匹配的文本。
(?<name> )
将匹配的子字符串捕获到一个组名称或编号名称中。用于 name 的字符串不能包含任何标点符号,并且不能以数字开头。可以使用单引号替代尖括号,例如 (?'name')。
(?<name1-name2> )
平衡组定义。删除先前定义的 name2 组的定义并在 name1 组中存储先前定义的 name2 组和当前组之间的间隔。如果未定义 name2 组,则匹配将回溯。由于删除 name2 的最后一个定义会显示 name2 的先前定义,因此该构造允许将 name2 组的捕获堆栈用作计数器以跟踪嵌套构造(如括号)。在此构造中,name1 是可选的。可以使用单引号替代尖括号,例如 (?'name1-name2')。
(?: )
非捕获组。
(?imnsx-imnsx: )
应用或禁用子表达式中指定的选项。例如,(?i-s: ) 将打开不区分大小写并禁用单行模式。有关更多信息,请参阅正则表达式选项。
(?= )
零宽度正预测先行断言。仅当子表达式在此位置的右侧匹配时才继续匹配。例如,\w+(?=\d) 与后跟数字的单词匹配,而不与该数字匹配。此构造不会回溯。
(?! )
零宽度负预测先行断言。仅当子表达式不在此位置的右侧匹配时才继续匹配。例如,\b(?!un)\w+\b 与不以 un 开头的单词匹配。
(?<= )
零宽度正回顾后发断言。仅当子表达式在此位置的左侧匹配时才继续匹配。例如,(?<=19)99 与跟在 19 后面的 99 的实例匹配。此构造不会回溯。
(?
零宽度负回顾后发断言。仅当子表达式不在此位置的左侧匹配时才继续匹配。
(?> )
非回溯子表达式(也称为贪婪子表达式)。该子表达式仅完全匹配一次,然后就不会逐段参与回溯了。(也就是说,该子表达式仅与可由该子表达式单独匹配的字符串匹配。)
我们还是先简单的了解一下这两个概念:
分组构造:
最基本的构造方式就是(),在左右括号中括起来的部分,就是一个分组;
更进一步的分组就是形如:(?<name> )的分组方式,这种方式与第一种方式的不同点,就是对分组的部分进行了命名,这样就可以通过该组的命名来获取信息;
(还有形如(?= )等等的分组构造,我们这篇的例子中也没有使用到,下次我们在来介绍)
替换:
上面提到了两种基本的构造分组方式()以及(?<name> ),通过这两种分组方式,我们可以得到形如$1,${name}的匹配结果。
这样说,可能概念上还是有些模糊,我们还是结合上面的例子来说:
第三个例子的正则表达式为:\\b(?\\d{1,2})/(?\\d{1,2})/(?\\d{2,4})\\b
(解释一下,为什么这里都是\\一起用:这里是C#的例子,在C#语言中\是转译字符,要想字符串中的\不转译,就需要使用\\或者在整个字符串的开始加上@标记,即上面等价与
@”\b(?\d{1,2})/(?\d{1,2})/(?\d{2,4}\b”)
\b -- 是一种特殊情况。在正则表达式中,除了在 [] 字符类中表示退格符以外,\b 表示字边界(在 \w 和 \W 字符之间)。在替换模式中,\b 始终表示退格符
(?\d{1,2}) – 构造一个名为month的分组,这个分组匹配一个长度为1-2的数字
/ -- 匹配普通的/字符
(?\d{1,2}) --构造一个名为day的分组,这个分组匹配一个长度为1-2的数字
/ -- 匹配普通的/字符
(?\d{2,4}\b”) --构造一个名为year的分组,这个分组匹配一个长度为2-4的数字
这里还不能够看出这些分组的作用,我们接着看这一句
${day}-${month}-${year}
${day} – 获得上面构造的名为day的分组匹配后的信息
- -- 普通的-字符
${month} --获得上面构造的名为month的分组匹配后的信息
- -- 普通的-字符
${year} --获得上面构造的名为year的分组匹配后的信息
举例来说:
将形如04/02/2003的日期使用例3种的方法替换
(?\d{1,2}) 分组将匹配到04由${month}得到这个匹配值
(?\d{1,2}) 分组将匹配到02由${day}得到这个匹配值
(?\d{1,2}) 分组将匹配到2003由${year}得到这个匹配值
了解了这个例子后,我们在来看第4个例子就很简单了。
第4个例子的正则
^(?\w+)://[^/]+?(?:\d+)?/
^ -- 表示限定匹配开始于字符串的开始
(?\w+) – 构造一个名为proto的分组,匹配一个或多个字母
: -- 普通的:字符
// -- 匹配两个/字符
[^/] – 表示这里不允许是/字符
+? – 表示指定尽可能少地使用重复但至少使用一次匹配
(?:\d+) – 构造一个名为port的分组,匹配形如:2134(冒号+一个或多个数字)
? – 表示匹配字符出现0次或1次
/ -- 匹配/字符
最后通过${proto}${port}来获取两个分组构造的匹配内容
正则表达式-----------------------------------C#的正则表达式的更多相关文章
- Java 常用正则表达式,Java正则表达式,Java身份证校验,最新手机号码正则表达式
Java 常用正则表达式,Java正则表达式,Java身份证校验,最新手机号码校验正则表达式 ============================== ©Copyright 蕃薯耀 2017年11 ...
- Linux通配符与基础正则表达式、扩展正则表达式
在Linux命令行操作或者SHELL编程中总是容易混淆一些特殊字符的使用,比如元字符‘*’号,作为通配符匹配文件名时表示0个到无穷多个任意字符.而作为正则表达式匹配字符串时,表示重复0个到无穷多个的前 ...
- 正则表达式-RegExp-常用正则表达式
正则表达式-RegExp-常用正则表达式 作者:nuysoft/JS攻城师/高云 QQ:47214707 EMail:nuysoft@gmail.com 声明:本文为原创文章,如需转载,请注明来源 ...
- python正则表达式(2)--编译正则表达式re.compile
编译正则表达式-- re.compile 使用re的一般步骤是先将正则表达式的字符串形 式编译为pattern实例,然后使用pattern实例处理文本并获取匹配结果(一个Match实例(值为True) ...
- bash基础——grep、基本正则表达式、扩展正则表达式、fgrep
grep grep全称:Globally search a Regular Expression and Print 全局搜索正则表达式 正规表达式本质上是一种"表示方法", 只要 ...
- jQuery源码分析-02正则表达式-RegExp-常用正则表达式
2.4 常用正则表达式在网上找到一篇广为流传的文章<常用正则表达式>,逐一分析,不足地方进行补充和纠正. 常用的数字正则(严格匹配) 正则 含义 ^[1-9]\d*$ 匹配正整数 ^-[1 ...
- C# 正则表达式及常用正则表达式
元字符 描述 .点 匹配任何单个字符.例如正则表达式r.t匹配这些字符串:rat.rut.r t,但是不匹配root. $ 匹配行结束符.例如正则表达式weasel$ 能够匹配字符串"He' ...
- 常用的正则表达式归纳—JavaScript正则表达式
来源:http://www.ido321.com/856.html 1.正则优先级 首先看一下正则表达式的优先级,下表从最高优先级到最低优先级列出各种正则表达式操作符的优先权顺序: 2.常用的正则表达 ...
- 廖雪峰Java9正则表达式-1正则表达式入门-2正则表达式匹配规则
正则表达式的匹配规则: 从左到右按规则匹配 匹配规则及示例 可以匹配 不能匹配 "abc" "abc" 不能匹配:"ab", "A ...
- 廖雪峰Java9正则表达式-1正则表达式入门-1正则表达式简介
1.使用代码来判断字符串 场景: 判断字符串是否是有效的电话号码:"010-12345678", "123ABC456" 判断字符串是否是有效的电子邮箱地址:& ...
随机推荐
- Android调用Webservice发送文件
一服务器端C#这里有三个上传方法1.uploadFile( byte []bs, String fileName); PC机操作是没有问题2. uploadImage(String filename, ...
- django 中多字段主键(复合、联合主键)
django中不支持双主键.多主键. 要实现类似功能可以: classMeta: unique_together=(("driver","restaurant" ...
- WebAPI Action的几种返回值类型
void 返回204状态码 HttpResponseMessage Convert directly to an HTTP response message. IHttpActionResult Ca ...
- [转]JSTL 与 JSP 或者 Java 相互传递变量的代码
原文地址:http://blog.csdn.net/joyous/article/details/6689861 两种方式 <c:set var="s1" value=&qu ...
- Thinkphp动态切换主题
'DEFAULT_THEME' => '2014', 'TMPL_DETECT_THEME' => true, // 自动侦测模板主题 'THEME_LIST' => '2012,2 ...
- nginx servername配置域名网站可以正常登录,servername配置IP+Port却无法正常登录
由于业务的原因,需要将网站从通过域名访问变换为通过IP+PORT的访问方式: 以前的配置: server { listen ; server_name wx.xxxx.com; } 以前的登录页面: ...
- 如何在CentOS或者RHEL上启用Nux Dextop仓库 安装shutter截图工具
Nux Dextop是一个面对CentOS.RHEL.ScientificLinux的含有许多流行的桌面和多媒体相关的包的第三方RPM仓库(比如:Ardour,Shutter等等).目前,Nux De ...
- Android——音乐播放器完善——进度条显示当前播放进度,加可拖动进度条(未待解决完问题)
效果: 问题:可拖动进度条随进度条移动时,会致使音乐卡顿(待解决) xml <?xml version="1.0" encoding="utf-8"?&g ...
- windows已阻止此软件因为无法验证发行者怎么办
出现提示windows已阻止此软件因为无法验证发行者怎么解决?有的时候访问某些网站会出现类似的提示.导致不能正常运行某个插件,遇到这个问题一般是浏览器的安全级别设置太高了,没有允许脚本控件运行 设 ...
- Linux中cp直接覆盖不提示的方法
新做了服务器,cp覆盖时,无论加什么参数-f之类的还是提示是否覆盖,这在大量cp覆盖操作的时候是不能忍受的. 把a目录下的文件复制到b目录 cp –r a/* b 执行上面的命令时,b存在的每个文件都 ...