【Algorithm】堆排序
堆是一种完全二叉树结构,并且其满足一种性质:父节点存储值大于(或小于)其孩子节点存储值,分别称为大顶堆、小顶堆。堆一般采用数组进行存储(从下标为0开始)。则父节点位置为i,那么其左孩子为2*i + 1,右孩子为2*i + 2。
一. 算法描述
- 建堆:先使长度为N数组形成一个N个节点组成的大顶堆(从第N/2个元素开始)
- 交换:然后将堆顶元素与末尾元素交换
- 筛选:再对N-1长的堆调整为大顶堆(从堆顶元素开始);反复进行,直到堆节点数为1时,结束堆排序。
例子:给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
1)构建大顶堆
首先,根据该数组元素构建一个完全二叉树,得到

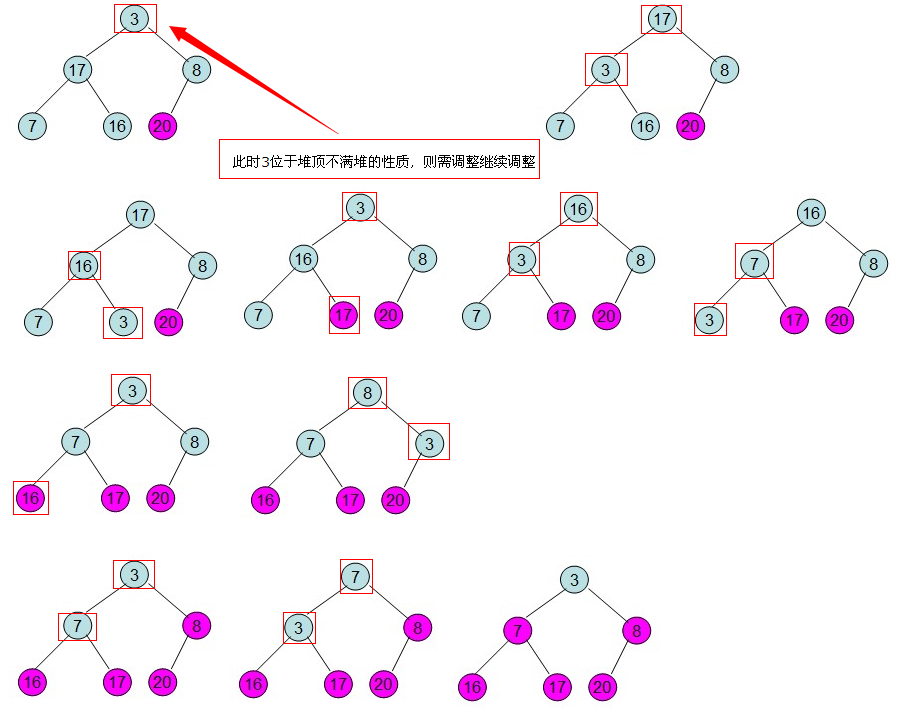
然后,需要构造初始堆,则从最后一个非叶节点(N/2)开始调整,调整过程如下:


这样就得到了初始堆。即每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换(交换之后可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整)。有了初始堆之后就可以进行排序了。
2)交换

3)筛选
二. 算法实现
#include<stdio.h>
void HeapSort(int array[],int length);
void HeapAdjust(int array[],int i,int nLength);
void main(){
int intArr[] = {,,,,,,,,,};
int n = sizeof(intArr) / sizeof(intArr[]); // 计算整型数组的长度
int i;
HeapSort(intArr, n); // 打印输出结果
for(i = ; i < n; i++){
printf("%d ",intArr[i]);
}
printf("\n"); } /*
* 堆排序算法, 分为三步:
* 第一步:建堆;
* 第二步:堆顶与最后一个元素交换;
* 第三步:重新调整堆(从堆顶开始),之后重复二三步
*/
void HeapSort(int array[],int length){
int tmp, i ;
//调整序列的前半部分元素,调整完之后第一个元素是序列的最大的元素
//length/2 - 1是最后一个非叶节点,此处"/"为整除
for(i = length/ - ; i >= ; --i){
HeapAdjust(array,i,length);
}
//从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
for(i = length-; i > ; --i){
//把第一个元素和当前的最后一个元素交换,
//保证当前的最后一个位置的元素都是在现在的这个序列之中最大的
///Swap(&array[0],&array[i]);
tmp = array[i];
array[i] = array[];
array[] = tmp;
//不断缩小调整heap的范围,每一次调整完毕保证第一个元素是当前序列的最大值
HeapAdjust(array, , i);
}
} /*
* array是待调整的堆数组,i是待调整的数组元素的位置,nlength是数组的长度
* 本函数功能是:根据数组array构建大根堆
*/
void HeapAdjust(int array[],int i,int nLength){
int nChild;
int nTemp;
for(; *i+ < nLength; i = nChild){
//左孩子
nChild = * i + ;
//得到子结点中较大的结点
if(nChild < nLength- && array[nChild+] > array[nChild]){
++nChild;
}
//如果较大的子结点大于父结点那么把较大的子结点往上移动,替换它的父结点
if(array[i] < array[nChild]){
nTemp = array[i];
array[i] = array[nChild];
array[nChild] = nTemp;
}else{
//否则退出循环
break;
}
}
}
三. 算法分析
- 平均时间复杂度:O(nlog2n)
- 空间复杂度:O(1) (用于交换数据)
- 稳定性:不稳定
- 由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
参考资料
[1] http://www.cnblogs.com/dolphin0520/archive/2011/10/06/2199741.html
[2] http://zh.wikipedia.org/zh-cn/%E5%A0%86%E7%A9%8D%E6%8E%92%E5%BA%8F
[3] http://blog.csdn.net/cjf_iceking/article/details/7928254
【Algorithm】堆排序的更多相关文章
- algorithm: heap sort in python 算法导论 堆排序
An Python implementation of heap-sort based on the detailed algorithm description in Introduction to ...
- HDU 1425 sort(堆排序/快排/最大堆/最小堆)
传送门 Description 给你n个整数,请按从大到小的顺序输出其中前m大的数. Input 每组测试数据有两行,第一行有两个数n,m(0<n,m<1000000),第二行包含n个各不 ...
- 排序练习【sdut 1582】【堆排序】
排序 Time Limit: 1000ms Memory limit: 32678K 有疑问?点这里^_^ 题目描述 给你N(N<=100)个数,请你按照从小到大的顺序输出. 输入 输入数 ...
- 1306.Sequence Median(堆排序)
1306 URAL真是没水题 以为简单的排序就好了 ME 内存限制很紧 堆排序 或者 STL 用堆排序做的 正好复习一下 都忘了 #include <iostream> #include ...
- Heapsort 堆排序算法详解(Java实现)
Heapsort (堆排序)是最经典的排序算法之一,在google或者百度中搜一下可以搜到很多非常详细的解析.同样好的排序算法还有quicksort(快速排序)和merge sort(归并排序),选择 ...
- 算法设计手冊(第2版)读书笔记, Springer - The Algorithm Design Manual, 2ed Steven S.Skiena 2008
The Algorithm Design Manual, 2ed 跳转至: 导航. 搜索 Springer - The Algorithm Design Manual, 2ed Steven S.Sk ...
- 《github一天,一个算术题》:堆算法接口(堆排序、堆插入和堆垛机最大的价值,并删除)
阅览.认为.编写代码! /********************************************* * copyright@hustyangju * blog: http://blo ...
- C++ 头文件系列 (algorithm)
简介 algorithm头文件是C++的标准算法库,它主要应用在容器上. 因为所有的算法都是通过迭代器进行操作的,所以算法的运算实际上是和具体的数据结构相分离的 ,也就是说,具有低耦合性. 因此,任何 ...
- David MacKay:用信息论解释 '快速排序'、'堆排序' 本质与差异
这篇文章是David MacKay利用信息论,来对快排.堆排的本质差异导致的性能差异进行的比较. 信息论是非常强大的,它并不只是一个用来分析理论最优决策的工具. 从信息论的角度来分析算法效率是一件很有 ...
随机推荐
- Android自定义一款带进度条的精美按键
Android中自定义View并没有什么可怕的,拿到一个需要自定义的View,首先要做的就是把它肢解,然后思考每一步是怎样实现的,按分析的步骤一步一步的编码实现,最后你就会发现达到了你想要的效果.本文 ...
- asp.net给文件分配自己主动编号,如【20140710-1】
在开发办公软件的时候,须要给非常多文件什么的东西分配一个编号.是依照日期来的,比方2014.07.10的第一个文件编号就为20140710-1,这一天的第二个文件编号就为20140710-2,以此类推 ...
- JavaScript 之 ScriptManager.RegisterStartupScript的应用
如果页面中不用Ajax,cs中运行某段js代码方式可以是: Page.ClientScript.RegisterStartupScript(Page.GetType(), "", ...
- JAVA中使用Apache HttpComponents Client的进行GET/POST请求使用案例
一.简述需求 平时我们需要在JAVA中进行GET.POST.PUT.DELETE等请求时,使用第三方jar包会比较简单.常用的工具包有: 1.https://github.com/kevinsawic ...
- 转:NGNIX模块开发——nginx的配置系统
From:http://tengine.taobao.org/book/chapter_02.html nginx的配置系统 nginx的配置系统由一个主配置文件和其他一些辅助的配置文件构成.这些配置 ...
- 算法笔记_233:二阶魔方旋转(Java)
目录 1 问题描述 2 解决方案 1 问题描述 魔方可以对它的6个面自由旋转. 我们来操作一个2阶魔方(如图1所示): 为了描述方便,我们为它建立了坐标系. 各个面的初始状态如下:x轴正向:绿x轴 ...
- EL和OGNL表达式的区分
OGNL是通常要结合Struts 2的标志一起使用,如<s:property value="#xx" /> struts页面中不能单独使用,el可以单独使用 ${ses ...
- bat 十进制转16进制
@echo offset code=0123456789ABCDEF:enterset /p num=输入你要转换的十进制数字:echo %num%|findstr "[^0-9]" ...
- Android——自定义多击事件
一:使用场景 Android本身内置了点击.双击事件,但是某些时候,我们可能需要多击事件. 例如:某个秘密入口,为了避免用户误操作点击.双击到了触发开关而进入到不该被用户看到的页面,我们可以为入口控件 ...
- cocos2d-js 自定义事件监听派发
熟悉js的dom事件或者flash事件的,基本都能立马明白cc.eventManager的用法. cc.eventManager有两种注册监听器的方式,一种是原生事件,例如 cc.eventManag ...