【大数据系列】hadoop核心组件-MapReduce
一、引入
hadoop的分布式计算框架(MapReduce是离线计算框架)
二、MapReduce设计理念
移动计算,而不是移动数据。
Input HDFS先进行处理切成数据块(split) map sort reduce 输出数据(output HDFS)
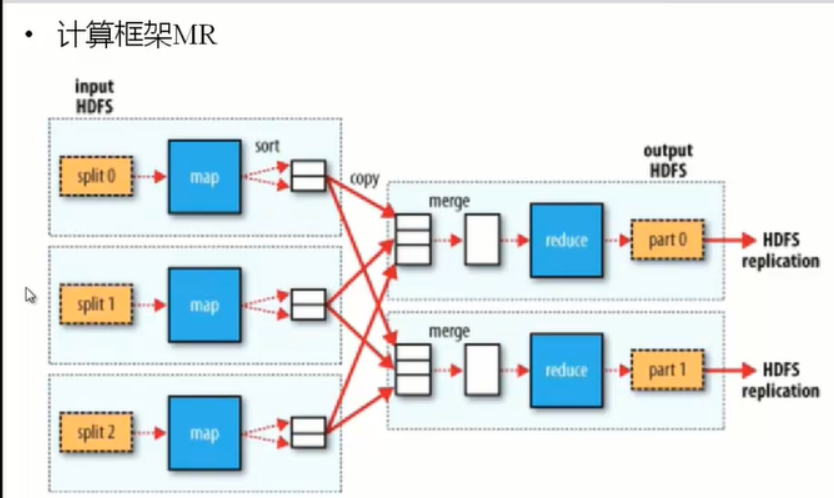
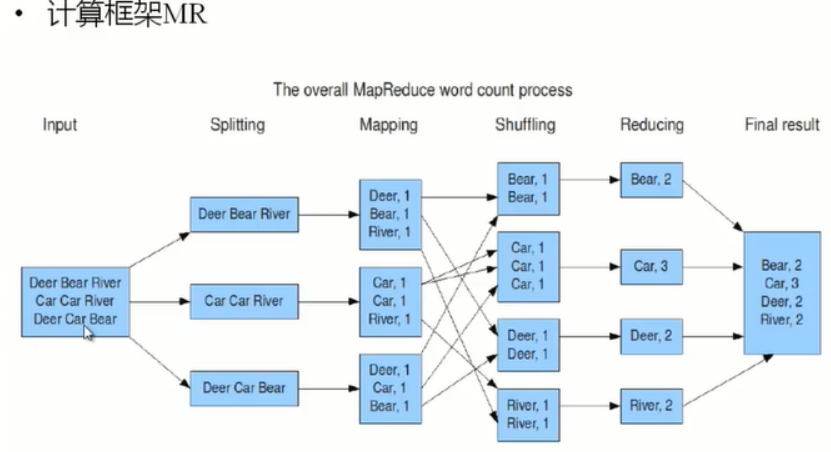
三、示例
Mapping是根据我们书写的模式执行的。
四、hadoop计算框架Shuffle
怎样将map task的输出结果有效的传送到reduce端,也就是说,Shuffle描述着数据从map task输出到reduce task输入的这段过程
1、在mapper和reducer中间的一个步骤
2、可以把mapper的输出按照某种key值重新切分和组合成n份,把key值符合某种范围的输出送到特定的reducer那里去处理。
3、 可以简化reducer过程
Partition的作用是根据key或value及reduce的数量来觉得当前的这对输出最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
4、 每个map task都有一个内存缓冲区(默认是100MB),存储着map的输出结果。
当缓存区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘(spill)
溢写是由单独线程来完成,不影响往缓冲区写map的线程,溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写比的比例(spill.percent,默认是0.8),假如是100MB,溢写线程启动的时候锁定这80MB的内存,执行溢写过程,Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
当溢写线程启动后,需要对这80MB空间的key做排序。
(Map端执行过程)
假如Client设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的value加起来。减少溢写到磁盘的数据量(reducer1,word1,[9])
当整个map task结束后再对次哦按中这个map task产生的所有临时文件做合并(Merge),对于“word1”就是这样的:{“word1”,[5,8,2,…]},假如有Combiner,{word1[15],}最终产生一个文件。
Reduce从tasktracker copy数据
Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置
Merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。Merge从不同的tasktracker上拿到的数据,{word1[15,17,2]}
Combiner会优化MapReduce的中间结果,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。
(reducer端)
Copy过程,简单的拉取数据,Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
Merge阶段,这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size来设置,因为Shuffle阶段Reduce不允许,所以应该把大部分的内存都给Shuffle用。
Reducer的输入文件,不断的merge后,最终会生成一个“最终文件”,这个文件可能在磁盘上,也可能在内存上,直接作为Rducer的输入,当Rueducer的输入文件已定,整个Shuffle才最终结束,然后就是Reducer执行,把结果放到HDFS上。
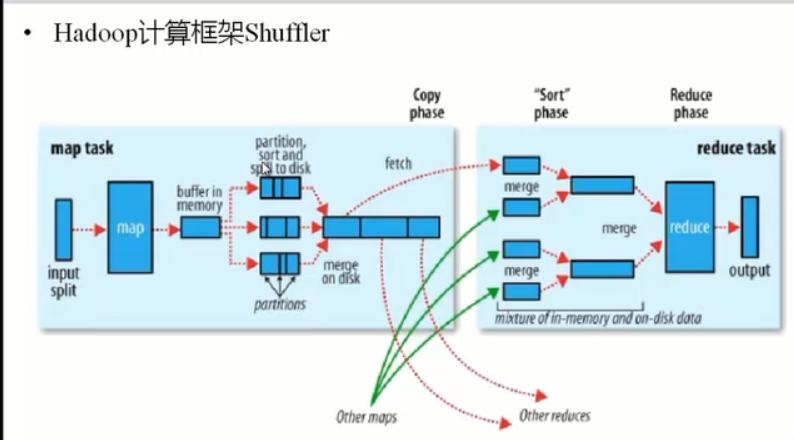
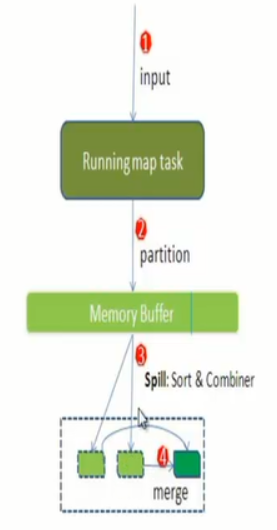

五、MapReduce的Split大小:
Max.split:100MB
Min.split:10MB
Block:64MB
Max(min.split,min(max.split,block))
六、MapReduce的架构
1、 一主多从架构
2、主JobTracker
负责调度分配每一个子任务task运行在TaskTracker上,如果发现有失败的etask就重新分配其任务到其他节点,每一个hadoop集群中只一个JobTracker一般它运行在Master节点上
3、从TaskTracker
TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务,为了减少网络带宽TaskTracker最好运行在HDFS的DataNode上
七、MapReduce安装
1.选择一台作为JobTracker(例如node3)
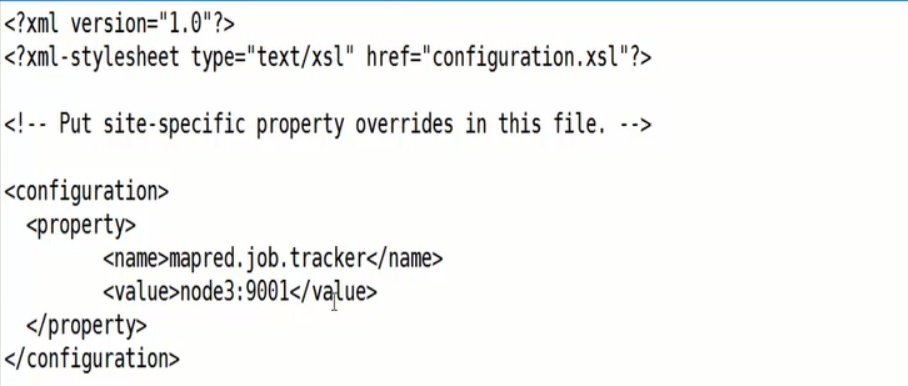
2. 编辑mapred-site.xml(NameNode机器上的)
3、将刚才编辑的文件同步到别的机器上
4、 启动(star-all.sh)如果没有安装mapreduce的时候启动使用hdfs-start.sh
5、访问http://node3.50030
6、编写测试wordCount类
package org.slp; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException;
import java.util.StringTokenizer; /**
* Created by sanglp on 2017/7/16.
*/
public class WcMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
/**
* 每次调用map方法会传入split中一行数据key:该行数据所在文件中的位置下标。value:这行行行数据
* map会调用多次的
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//super.map(key, value, context);
String line = value.toString();
StringTokenizer st = new StringTokenizer(line);//输入以空格切开
while (st.hasMoreTokens()){
String world = st.nextToken();
context.write(new Text(world),new IntWritable(1));//map的输出
}
} }package org.slp; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* Created by sanglp on 2017/7/16.
*/
public class WcReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//super.reduce(key, values, context);
int sum = 0 ;
for(IntWritable i : values){
sum = sum+i.get();
}
context.write(key,new IntWritable(sum));
}
}package org.slp; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* Created by sanglp on 2017/7/16.
*/
public class JobRun {
public static void main(String[] args){
Configuration conf = new Configuration();
conf.set("mapred.job.tracker","node1:9001");
try {
Job job = new Job(conf);
job.setJarByClass(JobRun.class);
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); job.setNumReduceTasks(1);//设置reduce任务的个数
//mapreduce输入数据所在目录或文件
FileInputFormat.addInputPath(job,new Path("/usr/input/wc"));
//mr执行之后的输出数据的目录
FileOutputFormat.setOutputPath(job,new Path("/usr/out/wc"));
try {
System.exit(job.waitForCompletion(true)?0:1);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}7、将编写的文件导出为jar包命名为wc.jar
8、./hadoop jar /root/wc.jar com.slp.mr.JobRun

【大数据系列】hadoop核心组件-MapReduce的更多相关文章
- 大数据基石——Hadoop与MapReduce
本文始发于个人公众号:TechFlow 近两年AI成了最火热领域的代名词,各大高校纷纷推出了人工智能专业.但其实,人工智能也好,还是前两年的深度学习或者是机器学习也罢,都离不开底层的数据支持.对于动辄 ...
- 大数据笔记10:大数据之Hadoop的MapReduce的原理
1. MapReduce(并行处理的框架) 思想:分而治之,一个大任务分解成多个小的子任务(map),并行执行后,合并结果(Reduce) (1)大任务分解成多个小任务,这个过程就是map: (2)多 ...
- 【大数据系列】基于MapReduce的数据处理 SequenceFile序列化文件
为键值对提供持久的数据结构 1.txt纯文本格式,若干行记录 2.SequenceFile key-value格式,若干行记录,类似于map 3.编写写入和读取的文件 package com.slp; ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- 大数据系列之分布式计算批处理引擎MapReduce实践
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制. WordCount: 1.应用场景,在大量文件中存储了 ...
- 大数据系列4:Yarn以及MapReduce 2
系列文章: 大数据系列:一文初识Hdfs 大数据系列2:Hdfs的读写操作 大数据谢列3:Hdfs的HA实现 通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
随机推荐
- thinkphp模板中使用方法
1.php中的方法使用 <?php $var_num = "13966778888"; $str = substr_replace($var_num,'*****',3,5) ...
- win用VNC远程Ubuntu教程
转载:https://blog.csdn.net/jiangchao3392/article/details/73251175 1.安装Xrdp Windows远程桌面使用的是RDP协议,所以ubun ...
- 前端图片压缩上传(纯js的质量压缩,非长宽压缩)
此demo为大于1M对图片进行压缩上传 若小于1M则原图上传,可以根据自己实际需求更改. demo源码如下: <!DOCTYPE html> <html> <head&g ...
- 树莓派获取ip地址发送到邮箱
公网 ip.sh curl http://members.3322.org/dyndns/getip >>/email/ip.log python /email/mail.py ##### ...
- 谈谈Android中的SurfaceTexture
2015.7.2更新 由于很多人要代码,我把代码下载链接放在这里了.不过还是要说一下,surfaceTexture和OpenGL ES结合才能发挥出它最大的效果,我这种写法只是我自己的想法,还有很多种 ...
- 按键精灵如何调用Excel及按键精灵写入Excel数据的方法教程---入门自动操作表格
首先来建立一个新的Excel文档,在桌面上点击右键,选择[新建]-[Excel工作表],命名为[新手学员]. 现在这个新Excel文档是空白的,我们接下来会通过按键精灵的脚本来打开并写入一些数据.打开 ...
- VS2010 正则批量替换头文件路径
最近在项目实践中,需要统一对工程头文件进行重构,具体要求是,将之前 #include "../../abc/def.h" 类似的头文件引用路径 替换为#include &q ...
- Hibernate的七种映射关系之基本映射
说到关系,在这个世界无处不在,我们必须以某个关系的节点存在在这个世界网中.比如父子关系,师生关系,上下属关系甚至是危险关系.数据也是一样的,它的存在必为某其他节点做准备. Hibernate有七种映射 ...
- 【CTR】各公司方法
LR + 海量高纬离散特征 GBDT + 少量低纬连续特征 (Yahoo & Bing) GBDT + LR (FaceBook) FM + DNN (百度凤巢) MLR (阿里妈妈) FTR ...
- 6 云计算系列之Nova安装与配置
preface 上面安装好了glance,下面就开始部署nova计算服务了. nova组件介绍 首先介绍下nova各个组件. api 用来接收和响应外部的请求唯一途径,支持Openstack api, ...