LTR之RankSvm
两种对比:
1.深度学习CNN提特征+RankSVM
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to Rank的几类常用的方法:pointwise,pairwise,listwise。这篇博客就很多公司在实际中通常使用的pairwise的方法进行介绍,首先我们介绍相对简单的 RankSVM 和 IR SVM。
1. RankSVM
RankSVM的基本思想是,将排序问题转化为pairwise的分类问题,然后使用SVM分类模型进行学习并求解。
1.1 排序问题转化为分类问题
对于一个query-doc pair,我们可以将其用一个feature vector表示:x。而排序函数为f(x),我们根据f(x)的大小来决定哪个doc排在前面,哪个doc排在后面。即如果f(xi) > f(xj),则xi应该排在xj的前面,反之亦然。可以用下面的公式表示:
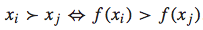
理论上,f(x)可以是任意函数,为了简单起见,我们假设其为线性函数: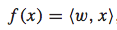 。
。
如果这个排序函数f(x)是一个线性函数,那么我们便可以将一个排序问题转化为一个二元分类问题。理由如下:
首先,对于任意两个feature vector xi和 xj,在f(x)是线性函数的前提下,下面的关系都是存在的:
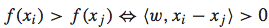
然后,便可以对xi和 xj的差值向量考虑二元分类问题。特别地,我们可以对其赋值一个label:
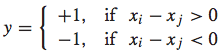

1.2 SVM模型解决排序问题
将排序问题转化为分类问题之后,我们便可以使用常用的分类模型来进行学习,这里我们选择了Linear SVM,同样的,可以通过核函数的方法扩展到 Nonlinear SVM。
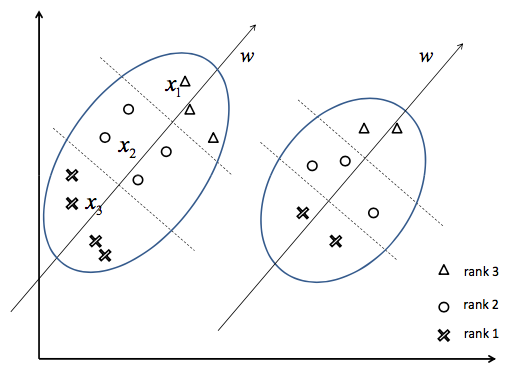
如下面左图所示,是一个排序问题的例子,其中有两组query及其相应的召回documents,其中documents的相关程度等级分为三档。而weight vector w对应了排序函数,可以对query-doc pair进行打分和排序。
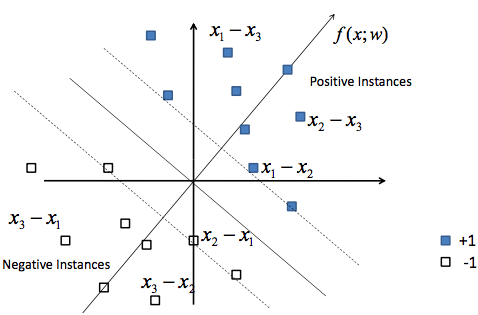
而下面右图则展示了如何将排序问题转化为分类问题。在同一个组内(同一个query下)的不同相关度等级的doc的feature vector可以进行组合,形成新的feature vector:x1-x2,x1-x3,x2-x3。同样的,label也会被重新赋值,例如x1-x2,x1-x3,x2-x3这几个feature vector的label被赋值成分类问题中的positive label。进一步,为了形成一个标准的分类问题,我们还需要有negative samples,这里我们就使用前述的几个新的positive feature vector的反方向向量作为相应的negative samples:x2-x1,x3-x1,x3-x2。另外,需要注意的是,我们在组合形成新的feature vector的时候,不能使用在原始排序问题中处于相同相似度等级的两个feature vector,也不能使用处于不同query下的两个feature vector。
1.2 SVM模型的求解过程
转化为了分类问题后,我们便可以使用SVM的通用方式进行求解。首先我们可以得到下面的优化问题:
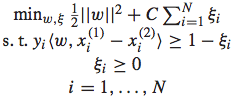
通过将约束条件带入进原始优化问题的松弛变量中,可以进一步转化为非约束的优化问题:
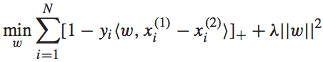
加和的第一项代表了hinge loss,第二项代表了正则项。primal QP problem较难求解,如果使用通用的QP解决方式则费时费力,我们可以将其转化为dual problem,得到一个易于求解的形式:
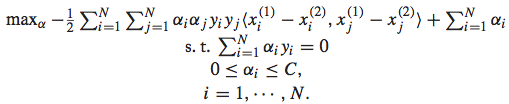
而最终求解得到相应的参数后,排序函数可以表示为:
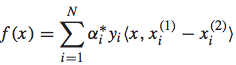
于是,RankSVM方法求解排序问题的步骤总结起来,如下图所示:
2. IR SVM
2.1 loss function的改造
上面介绍的RankSVM的基本思想是,将排序问题转化为pairwise的分类问题,然后使用SVM分类模型进行学习并求解。所以其在学习过程中,是使用了0-1分类损失函数(虽然实际上是用的替换损失函数hinge loss)。而这个损失函数的优化目标跟Information Retrieval的Evaluation常用指标(不仅要求各个doc之间的相对序关系正确,而且尤其重视Top的doc之间的序关系)还是存在gap的。所以有研究人员对此进行了研究,通过对RankSVM中的loss function进行改造从而使得优化目标更好地与Information Retrieval问题的常用评价指标相一致。
首先,我们通过一些例子来说明RankSVM在应用到文本排序的时候遇到的一些问题,如下图所示。

第一个问题就是,直接使用RankSVM的话,会将不同相似度等级的doc同等看待,不会加以区分。这在具体的问题中又会有两种形式:
1)Example 1中,3 vs 2 和 3 vs 1的两个pair,在0-1 loss function中是同等看待的,即它们其中任一对的次序的颠倒对loss function的增加大小是一样的。而这显然是不合理的,因为3 vs 1的次序颠倒显然要比 3 vs 2的次序的颠倒要更加严重,需要给予不同的权重来区分。
2)Example 2中,ranking-1是position 1 vs position 2的两个doc的位置颠倒了,ranking-2是position 3 vs position 4的两个doc的位置颠倒了,这两种情况在0-1 loss function中也是同等看待的。这显然也是不合理的,由于IR问题中对于Top doc尤其重视,ranking-1的问题要比ranking-2的问题更加严重,也是需要给予不同的权重加以区分。
第二个问题是,RankSVM对于不同query下的doc pair同等看待,不会加以区分。而不同query下的doc的数目是很不一样的。如Example 3所示,query-4的doc书目要更多,所以在训练过程中,query-4下的各个doc pair的训练数据对于模型的影响显然要比query-3下的各个doc pair的影响更大,所以最终结果的模型会有bias。
IR SVM针对以上两个问题进行了解决,它使用了cost sensitive classification,而不是0-1 classification,即对通常的hinge loss进行了改造。具体来说,它对来自不同等级的doc pair,或者来自不同query的doc pair,赋予了不同的loss weight:
1)对于Top doc,即相似度等级较高的doc所在的pair,赋予较大的loss weight。
2)对于doc数目较少的query,对其下面的doc pair赋予较大的loss weight。

2.2 IR SVM的求解过程
IR SVM的优化问题可以表示如下:
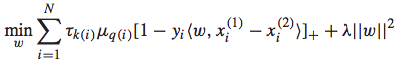
其中,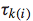 代表了隶属于第k档grade pair的instance的loss weight值。这个值的确定有一个经验式的方法:对隶属于这一档grade pair的两个doc,随机交换它们的排序位置,看对于NDCG@1的减少值,将所有的减少值求平均就得到了这个loss weight。可以想象,这个loss weight值越大,说明这个pair的doc对于整体评价指标的影响较大,所以训练时候的重要程度也相应较大,这种情况一般对应着Top doc,这样做就是使得训练结果尤其重视Top doc的排序位置问题。反之亦然。
代表了隶属于第k档grade pair的instance的loss weight值。这个值的确定有一个经验式的方法:对隶属于这一档grade pair的两个doc,随机交换它们的排序位置,看对于NDCG@1的减少值,将所有的减少值求平均就得到了这个loss weight。可以想象,这个loss weight值越大,说明这个pair的doc对于整体评价指标的影响较大,所以训练时候的重要程度也相应较大,这种情况一般对应着Top doc,这样做就是使得训练结果尤其重视Top doc的排序位置问题。反之亦然。
而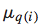 这个参数则对应了query的归一化系数。可以表示为
这个参数则对应了query的归一化系数。可以表示为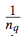 ,即该query下的doc数目的倒数,这个很好理解,如果这个query下的doc数目较少,则RankSVM训练过程中相对重视程度会较低,这时候通过增加这个权重参数,可以适当提高这个query下的doc pair的重要程度,使得模型训练中能够对不同的query下的doc pair重视程度相当。
,即该query下的doc数目的倒数,这个很好理解,如果这个query下的doc数目较少,则RankSVM训练过程中相对重视程度会较低,这时候通过增加这个权重参数,可以适当提高这个query下的doc pair的重要程度,使得模型训练中能够对不同的query下的doc pair重视程度相当。
IR SVM的优化问题如下:
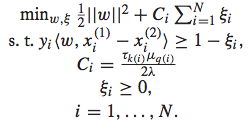
同样地,也需要将其转化为dual problem进行求解:
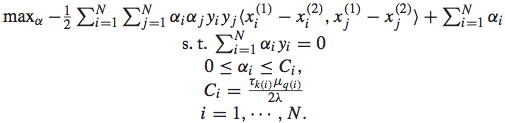
而最终求解得到相应的参数后,排序函数可以表示为:
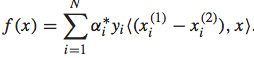
于是,IR SVM方法求解排序问题的步骤总结起来,如下图所示:

版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。
2.deep rank
LTR之RankSvm的更多相关文章
- [笔记]RankSVM 和 IR SVM
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- Learning to Rank算法介绍:RankSVM 和 IR SVM
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- 阿里云 RTC QoS 弱网对抗之 LTR 及其硬件解码支持
LTR 弱网对抗由于需要解码器的反馈,因此用硬件解码器实现时需要做一些特殊处理.另外,一些硬件解码器对 LTR 的实现不是特别完善,会导致出现解码错误.本文为 QoS 弱网优化系列的第三篇,将为您详解 ...
- [LTR] 信息检索评价指标(RP/MAP/DCG/NDCG/RR/ERR)
一.RP R(recall)表示召回率.查全率,指查询返回结果中相关文档占所有相关文档的比例:P(precision)表示准确率.精度,指查询返回结果中相关文档占所有查询结果文档的比例: 则 PR 曲 ...
- [LTR] RankLib.jar 包介绍
一.介绍 RankLib.jar 是一个学习排名(Learning to rank)算法的库,目前已经实现了如下几种算法: MART RankNet RankBoost AdaRank Coordin ...
- Boosting and Its Application in LTR
1 Boosting概述 2 Classification and Regression Tree 3 AdaBoost 3.1 算法框架 3.2 原理:Additive Modeling 4 Gra ...
- Invalid YGDirection 'vertical'. should be one of: ( inherit, ltr, rtl )
react native 路由( react-native-router-flux )跳转页面一直都报错 本项目解决方法:不是路由的问题,是跳转的页面有有问题,删除下图标记的红色即可(解决方法是排除法 ...
- Deep Learning for Information Retrieval
最近关注了一些Deep Learning在Information Retrieval领域的应用,得益于Deep Model在对文本的表达上展现的优势(比如RNN和CNN),我相信在IR的领域引入Dee ...
- 【推荐系统】Netflix 推荐系统:第二部分
原文链接:http://techblog.netflix.com/2012/06/netflix-recommendations-beyond-5-stars.htm 在 blog 的第一部分,我们详 ...
随机推荐
- Nginx报Primary script unknown的错误解决
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; 改成红色部分变量 root /usr/local/nginx/h ...
- 【Java】须要配置的三个Java环境变量
我的电脑→属性→高级系统设置→高级→环境变量 1.JAVA_HOME : JDK的安装路径 2.PATH : %JAVA_HOME%\bin;%JAVA_HOME%\jre\bin; 3.CLASSP ...
- How to create .gitignore file in Windows Explorer
How to create .gitignore file I need to add some rules to my .gitignore file, however, I can't find ...
- ICE概述
网络通信引擎(Internet Communications Engine, Ice)是由ZeroC的分布式系统开发专家实现的一种高性能.面向对象的中间件平台.它号称标准统一,开源,跨平台,跨语言,分 ...
- Unity3D实践系列03,使用Visual Studio编写脚本与调试
在Unity3D中,只有把脚本赋予Scene中的GameObject,脚本才会得以执行. 添加Camera类型的GameObject. Unity3D默认使用"MonoDevelop&quo ...
- Android 应用开发特色
Android 系统到底提供了哪些东西,供我们可以开发出优秀的应用程序.1. 四大组件Android 系统四大组件分别是活动(Activity).服务(Service).广播接收器(Broadcast ...
- Java Dictionary 类存储键值
字典(Dictionary) 字典(Dictionary) 类是一个抽象类,它定义了键映射到值的数据结构. 当你想要通过特定的键而不是整数索引来访问数据的时候,这时候应该使用Dictionary. 当 ...
- require.js 简洁入门
原文地址:http://blog.sae.sina.com.cn/archives/4382 前言 提到require.js大多数人会说提到模块化开发,AMD等等,其实require.js并没有这么多 ...
- WebApp分析建模的工具
最近Web工程课在学习分析建模工具的内容.这周作业就写我对WebApp建模工具的认识.Web建模工具有很多,但是专门为分析开发的却相对很少.下面介绍在进行分析时可以用的四类工具. UML工具.使用统一 ...
- Burp Suite扫描器漏洞扫描功能介绍及简单教程
pageuo 2017-07-25 共852828人围观 ,发现 15 个不明物体 工具新手科普 * 本文作者:pageuo,本文属FreeBuf原创奖励计划,未经许可禁止转载 众所周知,burpsu ...