【大数据应用技术】作业九|安装关系型数据库MySQL 安装大数据处理框架Hadoop
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161
1.安装MySql
按ctrl+alt+t打开终端窗口,安装mysql需要输入命令:sudo apt-get install mysql-server
输入命令:service mysql start #启动mysql
输入命令:sudo netstat -tap | grep mysql #查看mysql是否启动成功,mysql结点处于LISTEN状态表明启动成功
如下图所示:

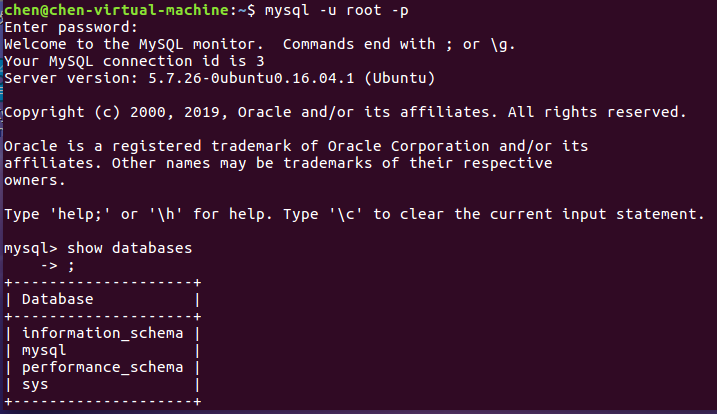
输入命令:mysql -u root -p #进入mysql shell界面
输入命令:show databases; #显示数据库
如下图所示:
2.windows 与 虚拟机互传文件
为了使windows与虚拟机互传文件,所以需要安装vmware tools工具,安装步骤可见后面部分:https://blog.csdn.net/weixin_42305895/article/details/89879220
如图所示,已经成功安装vmware tools工具。
3.安装Hadoop
我已经成功安装了hadoop,伪分布式hadoop的安装教程可见:https://blog.csdn.net/weixin_42305895/article/details/89925119
启动hadoop,如下图所示。
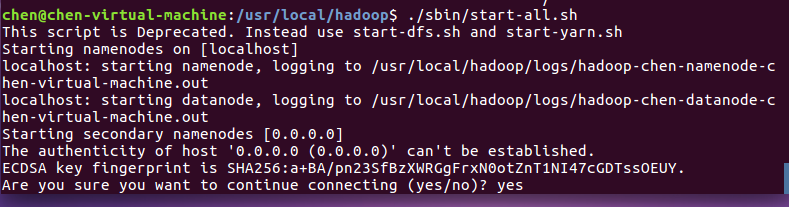
输入jps可查看hadoop是否启动成功,如果启动成功则会出现如下进程:“NameNode”,“DataNode”,“SecondaryNameNode”,如下图所示。

关闭hadoop,如下图所示。

4. 简述Hadoop平台的起源、发展历史与应用现状。
(1)起源
(2)发展历史
(3)应用现状
hadoop的应用现状很广泛,这里我就不一一描述了,大家可以去看国外、国内Hadoop的应用现状,描述的比较详细。
【大数据应用技术】作业九|安装关系型数据库MySQL 安装大数据处理框架Hadoop的更多相关文章
- 安装关系型数据库MySQL和大数据处理框架Hadoop
1. 简述Hadoop平台的起源.发展历史与应用现状.列举发展过程中重要的事件.主要版本.主要厂商:国内外Hadoop应用的典型案例. (1)Hadoop的介绍: Hadoop最早起源于Nutch,N ...
- 【大数据作业九】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 4.简述Hadoop平台的起源.发展历史与应用现状. 列举发展过程中 ...
- 【大数据】安装关系型数据库MySQL安装大数据处理框架Hadoop
作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1. 简述Hadoop平台的起源.发展历史与应用现状. 列举发展过 ...
- 【大数据】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1.安装Mysql 使用命令 sudo apt-get ins ...
- 安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1.Hadoop的介绍 Hadoop最早起源于Nutch.Nut ...
- 作业——09 安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 简述Hadoop平台的起源.发展历史与应用现状. 起源: 2 ...
- AI加持的阿里云飞天大数据平台技术揭秘
摘要:2019云栖大会大数据&AI专场,阿里云智能计算平台事业部研究员关涛.资深专家徐晟来为我们分享<AI加持的阿里云飞天大数据平台技术揭秘>.本文主要讲了三大部分,一是原创技术优 ...
- 中国大数据六大技术变迁记(CSDN)
大会召开前期,特别梳理了历届大会亮点以记录中国大数据技术领域发展历程,并立足当下生态圈现状对即将召开的BDTC 2014进行展望: 追本溯源,悉大数据六大技术变迁 伴随着大数据技术大会的发展,我们亲历 ...
- 大数据 --> 大数据关键技术
大数据关键技术 大数据环境下数据来源非常丰富且数据类型多样,存储和分析挖掘的数据量庞大,对数据展现的要求较高,并且很看重数据处理的高效性和可用性. 传统数据处理方法的不足 传统的数据采集来源单一,且存 ...
随机推荐
- springCloud学习6(Spring Cloud Sleuth 分布式跟踪)
springcloud 总集:https://www.tapme.top/blog/detail/2019-02-28-11-33 前言 在第四篇和第五篇中提到一个叫关联 id的东西,用这个东西来 ...
- printk打印级别
默认级别 # cat /proc/sys/kernel/printk 4 4 1 7 分别是:控制台日志级别.默认的消息日志级别.最低的控制台日志级别和默认的控制台日志级别 举例 # echo 0 & ...
- 笔谈HTTP Multipart POST请求上传文件
公司一做iOS开发的同事用HTTP Multipart POST请求上传语音数据,但是做了两天都没搞定,项目经理找到我去帮忙弄下.以前做项目只用过get.post,对于现在这个跟服务器交互的表单请求我 ...
- centos7 hadoop 2.8安装
安装jdk https://www.cnblogs.com/syscn/p/9975049.html 下载hadoop wget http://mirrors.tuna.tsinghua.edu.cn ...
- 《TensorFlow2深度学习》学习笔记(四)对笔记二中的模型增加正确率展示
全部代码如下:(红色部分为与笔记二不同之处) #1.Import the neccessary libraries needed import numpy as np import tensorflo ...
- 【Calling Circles UVA - 247 】【Floyd + dfs】
用到的东西 Floyd算法(不考虑路径的长度,只关心两点之间是否有通路,可用于求有向图的传递闭包) STL map中的count用法 利用dfs输出同一个圈内的名字 题意 题目中给出 n 的人的名字, ...
- Codeforces D. Little Elephant and Interval(思维找规律数位dp)
题目描述: Little Elephant and Interval time limit per test 2 seconds memory limit per test 256 megabytes ...
- 在markdown中插入github仓库中的图片
右击github中的图片,获得链接: https://github.com/nxf75/ML_Library/blob/master/Hadoop/Haddop%E6%A1%86%E6%9E%B6.p ...
- 关于微信小程序在ios中无法调起摄像头问题
这几天关于微信小程序开发关于wx.chooseVideo组件问题,因为自己一直是安卓手机上测试,可以调取摄像头,但是应用在ios上无法打开摄像头,困扰了好多天,经过反复查看官方文档,今天总算修复了这个 ...
- BZOJ-1085:骑士精神 (迭代加深 + A*搜索)
题意:给定一个5*5的棋盘,上面有白马给妈给12匹,以及一个空格.问是否能在15步内有给定棋盘转移到目标棋盘. 如果可以,输出最小步数. 否则输出-1: 思路:由于步数比较小,我们就直接不记录状态vi ...