MongoDB开发深入之一:文档数据关系模型详解(一对多,多对多)
文档关联模型通常有3种方式:
- 嵌入式(一对一、一对多)
- 后期手动统一ID处理(一对多、多对多)
- References引用(一对一、一对多)
文档树模型通常有3种方式:
- 父引用(Parent References)
- 子引用(Child References)
- 祖先数组(Array of Ancestors )
- 物化路径(Materialized Paths )
- 嵌套_Set,不常用,不详写了
关联模型
1、嵌入式
直接在单独文档中嵌入“子文档”
嵌入一个文档(1对1):
{
_id: "joe",
name: "Joe Bookreader",
address: {
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: ""
}
}
嵌入多个文档(1对n),使用“数组”形式:
{
_id: "joe",
name: "Joe Bookreader",
addresses: [
{
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: ""
},
{
street: "1 Some Other Street",
city: "Boston",
state: "MA",
zip: ""
}
]
}
这个很简单。
2、后期手动统一ID处理
后期统一ID,用于程序中确立关联,可以处理1对多,也可以处理多对多(通过中间关联表来实现),比如一个典型的多对多中间表,用于确定用户的权限:用户ID-权限ID
使用手动ID, 是在另一个文档中包含一个文档 _id字段的做法。然后,应用程序可以发出第二个查询以根据需要的(ID)解析数据。无论是一对一,还是多对多都可用.
original_id = ObjectId()
db.places.insert({
"_id": original_id,
"name": "Broadway Center",
"url": "bc.example.net"
})
db.people.insert({
"name": "Erin",
"places_id": original_id,
"url": "bc.example.net/Erin"
})

3、References引用
出版商和书的一对一、一对多关联(出版商可以出版很多书)
这个是正确的姿势,确保关联键(publisher_id)必须只有一个值:
publisher:
{
_id: "oreilly",
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
books:
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly"
} {
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher_id: "oreilly"
}
错误的引用方式,books的数组持续增长,造成失控,必须使用原子操作来维护数组。
{
name: "O'Reilly Media",
founded: 1980,
location: "CA",
books: [123456789, 234567890, ...]
}
总结正确的姿势:在父子表中的子表中引用父ID,在这里books为子表,publisher为父表,其实和关系数据库的设计模型是一致的。
树结构
1、父引用(Parent References)
以下的树结构,如图:

数据模型:
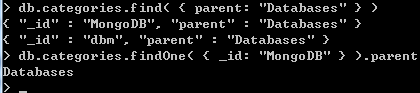
db.categories.insert( { _id: "MongoDB", parent: "Databases" } )
db.categories.insert( { _id: "dbm", parent: "Databases" } )
db.categories.insert( { _id: "Databases", parent: "Programming" } )
db.categories.insert( { _id: "Languages", parent: "Programming" } )
db.categories.insert( { _id: "Programming", parent: "Books" } )
db.categories.insert( { _id: "Books", parent: null } )
父引用的含义,顾名思义就是每个子节点指定自己的父亲。
检索节点的父亲的查询:
db.categories.findOne( { _id: "MongoDB" } ).parent
在字段parent上创建索引以启用 parent 节点的快速搜索:
db.categories.createIndex( { parent: 1 } )
通过parent字段查询以查找其直接的子节点:
db.categories.find( { parent: "Databases" } )
要检索子树,可使用$graphLookup。
2、子引用(Child References)
顾名思义就是父亲要标明自己的儿子(数组),感觉模型有些不大合理。最好别沾。
db.categories.insert( { _id: "MongoDB", children: [] } )
db.categories.insert( { _id: "dbm", children: [] } )
db.categories.insert( { _id: "Databases", children: [ "MongoDB", "dbm" ] } )
db.categories.insert( { _id: "Languages", children: [] } )
db.categories.insert( { _id: "Programming", children: [ "Databases", "Languages" ] } )
db.categories.insert( { _id: "Books", children: [ "Programming" ] } )
检索节点的直接 children 的查询:
db.categories.findOne( { _id: "Databases" } ).children
您可以在字段children上创建索引以启用 child 节点的快速搜索:
db.categories.createIndex( { children: 1 } )
您可以在children字段中查询节点以查找其 parent 节点及其兄弟节点:
db.categories.find( { children: "MongoDB" } )
3、完全祖先数组(Array of Ancestors )
这个比较合理,就是存储父的全路径数组。每个树节点除了父节点,还存储所有的节点的祖先。
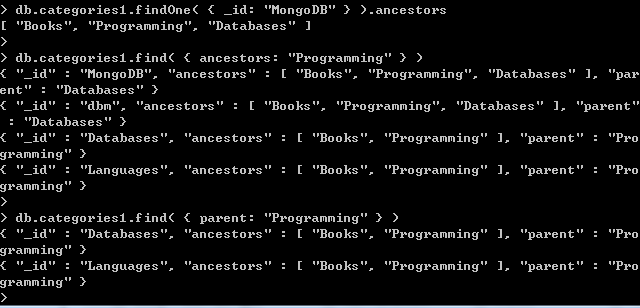
db.categories1.insert( { _id: "MongoDB", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" } )
db.categories1.insert( { _id: "dbm", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" } )
db.categories1.insert( { _id: "Databases", ancestors: [ "Books", "Programming" ], parent: "Programming" } )
db.categories1.insert( { _id: "Languages", ancestors: [ "Books", "Programming" ], parent: "Programming" } )
db.categories1.insert( { _id: "Programming", ancestors: [ "Books" ], parent: "Books" } )
db.categories1.insert( { _id: "Books", ancestors: [ ], parent: null } )
用于检索节点的祖先或路径的查询快速而直接:
db.categories1.findOne( { _id: "MongoDB" } ).ancestors
您可以在字段ancestors上创建索引以启用祖先节点的快速搜索:
db.categories1.createIndex( { ancestors: 1 } )
您可以通过字段ancestors查询以查找其所有后代:
db.categories1.find( { ancestors: "Programming" } )
Array of Ancestors pattern 提供了一种快速有效的解决方案,通过创建祖先字段元素的索引来查找节点的后代和祖先。是开发应用中的好选择。
4、物化路径(Materialized Paths )
和完全祖先数组原理一样,只是在处理路径时提供了更大的灵活性,例如通过 partial paths 查找节点。
db.categories.insert( { _id: "Books", path: null } )
db.categories.insert( { _id: "Programming", path: ",Books," } )
db.categories.insert( { _id: "Databases", path: ",Books,Programming," } )
db.categories.insert( { _id: "Languages", path: ",Books,Programming," } )
db.categories.insert( { _id: "MongoDB", path: ",Books,Programming,Databases," } )
db.categories.insert( { _id: "dbm", path: ",Books,Programming,Databases," } )
您可以查询以检索整个树,按字段path排序:
db.categories.find().sort( { path: 1 } )
您可以在path字段上使用正则表达式来查找Programming的后代:
db.categories.find( { path: /,Programming,/ } )
您还可以检索Books的后代,其中Books也位于层次结构的最顶层 level:
db.categories.find( { path: /^,Books,/ } )
要在字段path上创建索引,请使用以下调用:
db.categories.createIndex( { path: 1 } )
此索引可能会根据查询提高 performance:
对于来自根Books sub-tree(e.g. /^,Books,/或/^,Books,Programming,/)的查询,path字段上的索引可显着改进查询性能。
对于 sub-trees 的查询,其中查询(e.g. /,Databases,/)中未提供根的路径,或者 sub-trees 的类似查询,其中节点可能位于索引 string 的中间,查询必须检查整个索引。
对于这些查询,如果索引明显小于整个集合,则索引可以提供一些性能改进。
MongoDB开发深入之一:文档数据关系模型详解(一对多,多对多)的更多相关文章
- elasticsearch系列三:索引详解(分词器、文档管理、路由详解(集群))
一.分词器 1. 认识分词器 1.1 Analyzer 分析器 在ES中一个Analyzer 由下面三种组件组合而成: character filter :字符过滤器,对文本进行字符过滤处理,如 ...
- 一个完整的WSDL文档及各标签详解
<?xml version="1.0" encoding="UTF8" ?> <wsdl:definitions targetNamespac ...
- 使用vs code编写Markdown文档以及markdown语法详解
首先安装vscode工具,下载地址如下: https://code.visualstudio.com/ 在vs code的扩展中安装: Markdown Preview Enhanced 这款插件,安 ...
- 文档学习 - UILabel - 属性详解
#import "ViewController.h" @implementation ViewController - (void)viewDidLoad { [super vie ...
- 《Java开发学习大纲文档》V7.0
<Java开发学习大纲文档>V7.0简介: 本文档是根据企业开发所需要掌握的知识点大纲进行总结汇编,是Java开发工程师必备知识体系,系统化学习针对性非常强,逻辑分析能力非常清晰;技术方面 ...
- MongoDB,无模式文档型数据库简介
MongoDB的名字源自一个形容词humongous(巨大无比的),在向上扩展和快速处理大数据量方面,它会损失一些精度,在旧金山举行的MondoDB大会上,Merriman说:“你不适宜用它来处理复杂 ...
- MongoDB改动、删除文档的域属性实例
MongoDB改动.删除文档的域属性实例 在站点的开发中,可能最初的设计不合理.或者后期业务的变更,会造成文档结构会有些无用的属性.须要去删除或改动.因为MongoDB 是无 Schema 的,不像关 ...
- Spring Data MongoDB 五:进阶文档查询(分页、Morphia)(二)
Spring Data MongoDB 三:基本文档查询(Query.BasicQuery)(一) 学习MongoDB 六: MongoDB查询(游标操作.游标信息)(三) 一.简单介绍 Spring ...
- Spring Data MongoDB 四:基本文档改动(update)(一)
Spring Data MongoDB 三:基本文档查询(Query.BasicQuery)(一) 学习MongoDB 二:MongoDB加入.删除.改动 一.简单介绍 Spring Data Mo ...
随机推荐
- crontab 定时任务简单备份数据库
备份数据库/usr/local/mysql5.5/bin/mysqldump -uroot -p1234abcd wordpress >~/wordpress_20151206.sql 59 2 ...
- 织梦DedeCms网站内部SEO详细分析
一.确定网站的目标关键词 最为重要的一方面,一般网站首页的目标关键词建议在1-3个.对于目标关键词的选取有几个建议 1.定位:网站的内容和业务相关 2.分析:对用户体验及竞争对手的网站进行分析 3.筛 ...
- python应用-输入三个数,输出其最大值
""" 输入三个数,输出其最大值 Author:罗万财 Date:2017-7-6 """ a=int(input('a=')) b=int ...
- spark——故障排除
故障排除一:控制reduce端缓冲大小以避免OOM 在Shuffle过程,reduce端task并不是等到map端task将其数据全部写入磁盘后再去拉取,而是map端写一点数据,reduce端task ...
- MongoDB Map Reduce(转载)
MongoDB Map Reduce Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE). MongoDB提供的Map ...
- BZOJ 2091: [Poi2010]The Minima Game 博弈dp
十分有趣的问题. 我们发现如果拿的话肯定要先拿一些大的. 所以我们可以先将所有数从小到大排序,令 $f[i]$ 表示拿完前 $i$ 小先手-后手的最大值. 则有转移:$f[i]=max(f[i-1], ...
- 利用python画小猪佩奇
import turtle as t t.pensize(4) t.hideturtle() t.colormode(255) t.color((255,155,192),"pink&quo ...
- linux mustache bash 实现mo 做为docker容器运行动态配置工具数组的处理
前面有说过关于使用mo 工具的简单配置使用,但是实际中我们可能存在比较复杂的数据处理,比如数组,mo 可以进行数组的处理,但是在测试的过程中,一直失败,查看了官方的demo以及帮助命令发现可以通过参数 ...
- ACM数据结构-线段树
1.维护区间最大最小值模板(以维护最小值为例) #include<iostream> #include<stdio.h> #define LEN 11 #define MAX ...
- 了解Vuex状态管理模式的理解强化指南
1 Vuex是什么呢?它是Vue的状态管理模式,在使用vue的时候,需要在vue中各个组件之间传递值是很痛苦的,在vue中我们可以使用vuex来保存我们需要管理的状态值,值一旦被改变,所有引用该值的地 ...