CVAE-GAN论文学习-1
CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training
摘要
我们提出了一个变分生成对抗网络,一个包含了与生成对抗网络结合的变分子编码器,用于合成细粒度类别的图像,比如具体某个人的脸或者某个类别的目标。我们的方法构建一张图片作为概率模型中的一个标签成分和潜在属性。通过调整输入结果生成模型的细粒度类别标签,我们能够通过随机绘制潜在属性向量中的值来生成指定类别的图像。我们方法的创新点在于两个方面:
- 首先是我们提出了在判别器和分类器网络中使用交叉熵损失,对于生成器网络则使用平均差异目标函数。这种不对称损失函数能够使得训练出来的GAN网络更稳定。
- 其次是我们使用了encoder网络去学习潜在空间和真实图片空间中的关系,并使用成对的特性去保持生成图像的结构。
我们使用人脸、花和鸟的自然图片来训练,并说明了提出的模型有能力去生成有着细粒度类别标签的真实且不同的样本。我们进一步将展示我们的模型应用于其他任务的效果,如图像修复、高分辨率以及用于训练更好的人脸识别模型的数据增强。
1. Introduction
构建自然图像的有效的生成模型是计算机视觉中的主要问题。它目标是根据潜在的自然图像分布来调整一些潜在向量来生成不同的真实图片。因此,期望的生成模型是能够捕获钱在的数据分布。这可以说是一个很难的任务,因为图像样本的收集可能会依赖于十分复杂的manifold。然而目前深度卷积网路的进步丰富了深度生成模型系列[14, 12, 8, 31, 29, 34, 15, 4, 33, 6] ,造成了很大的进步,主要是因为深度网络在学习表征上的能力的进步。
通过享用目前研究的成功果实,我们对生成细粒度目标类别的图像有了更进一步的兴趣。比如,我们想要为某个人合成图像,或者为花或鸟的某具体物种生成一张新的图片等,如图1所示:

受CVAE和VAE/GAN的启发,我们提出了一种生成学习框架,一个包含了与生成对抗网络结合的变分子编码器,在条件生成过程中来处理这个问题
但是我们发现这种简单的连接并不足以在实际中使用,VAE的结果通常过于模糊。判别器能简单地将它们分类为“fake”。即使对于一张人脸图像来说它们有时看起来还不错
梯度消失问题仍然存在,所以生成的图像与仅使用VAE的结果是很相似的。在该论文中,我们为生成器提出了一个新的目标函数。替代在判别器网络中使用相同的交叉熵损失,新的目标函数需要生成器能够缩小生成图像和真实图像之间的L2距离。对于多类图像的生成,一种类别的生成样本也需要匹配该类别的真实图像的平均特性。由于特征距离与可分性呈正相关。它解决了在某个范围中梯度消失的问题。除此之外,这种类别的不对称损失函数能部分帮助阻止出现一些崩溃问题,如所有的输出都移到某一个点,其让GAN网络更加稳定。
虽然使用平均特性匹配将减少模型崩溃的机会,但它没有完全解决这个问题。一旦模型崩溃发生了,梯度下降将不能分离相同的输出。为了保证生成样例的多样性,我们利用了VAE和GAN的结合。我们使用encoder网络去映射真实图像到一个潜在向量,然后生成器被用于重构原始像素,将原始图像的特性与给定的潜在向量相匹配。在这种方法中,我们明显地建立了潜在空间和真实图像空间之间的关系。因为这些anchor点的存在,生成器被强迫呈现出不同的样本。而且,像素重构损失函数也能帮助保持结构,如图片中的直线和人脸结构。
如图2(g)所示,我们的框架包含了4部分:
- encoder网络E,用来映射数据样本x到潜在表征z
- 生成器网络G,根据潜在向量生成图像x'
- 判别器网络D,区分真/假图像
- 分类器网络,测量数据的类别概率

将我们的网络命名为CVAE-GAN。这4个部分无缝地级联在一起,整个网络进行端到端地训练
一旦我们的CVAE-GAN被训练,其就能够被使用在不同的应用中,如图像生成、图像修复和属性变形(morphing)。我们的方法建立了一个输入图像的好的表征,因此生成的图像变得更真实。我们展示了其是优于CVAE和CGAN以及其他最好的方法。与GAN相对比,提出的框架训练更容易,收敛更快一个在训练阶段中更稳定。在该实验中,我们进一步展示了我们模型的图像合成能够应用在其他任务中,如用于训练更好的人脸识别模型的数据增强。
2. Related work
传统智慧和生成模型的早期研究,包括Principle Component Analysis (PCA) [40], Independent Component Analysis (ICA) [10], Gaussian Mixture Model (GMM) [46, 27, 37],都假设数据的简单构造。他们很难对不规则分布的复杂模式进行建模。之后的工作有Hidden Markov Model (HMM) [35], Markov Ran- dom Field (MRF) [19], restricted Boltzmann machines (RBMs) [9, 32], discriminatively trained generative mod- els [39],在纹理patches、数字和更好地对齐人脸上对其结果也有所限制,因为其缺少有效的特征表示
最近深度生成模型的发展,[14, 12, 8, 31, 29, 15, 4, 33, 6]引起了很多研究者的注意。当深度层次结构允许它们捕获数据复杂的结构时,所有的这些方法都展示了在生成自然图像上的优秀成果,其比传统生成模型更加地真实。这些模型主要有三大主题:
- 变分子编码器(VAE)[12,31]
- 生成对抗网络(GAN)[8,29,33]
- 子回归器[14]
VAE[12,31]将decoder/生成器网络和encoder配对。VAE的一个缺点是,由于注入噪声和不完善的元素度量,如平方误差,生成的样本往往是模糊的。
生成对抗网络(GAN)[8,29,33]是另一个流行的生成模型。其同时训练两个模型,一个生成模型去合成样本,一个判别模型去区分自然和生成样本。但是GAN模型在训练过程中很难收敛,从GAN中生成的样本往往和真实图相差很大。最近,很多工作尝试去改进生成样本的质量。比如Wasserstein GAN (WGAN) [2] 使用Earth Mover距离作为训练GANs的目标函数,以及McGAN[20]使用平均和协方差特征匹配。但是它们需要限制判别器参数的范围,这将降低判别器的能力。Loss-Sensitive GAN [28] 学习能够提高生成样本质量的损失函数,然后使用该损失函数来生成高质量的图像。也有方法尝试结合VAE和GAN,如VAE/GAN[15]和对抗自编码器[17]。它们与我们的工作密切相关,并在一定程度上启发了我们的工作。
VAEs和GANs能被训练来构造条件生成器,如CVAE[34]和CGAN[18]。通过介绍额外的条件,他能够解决概率一对多的映射问题。最近有很多有趣的基于CVAE和CGAN的研究,包括条件人脸生成[7]、属性-图像[47]和文字-图像生成[30]、静态图像预测[42]和条件图像生成[25]。都得到了很好的结果
生成ConvNet[44]证明了由常用的判别ConvNet可导出一个生成模型。Dosovitskiy et al. [5] 和Nguyen et al. [22] 介绍了从训练的分类模型中抽取的特征生成高质量图像的方法。PPGN[23]通过使用梯度上升法和超前于生成器的潜在空间能生成优质的样本。
自回归[14]方法则提出了不一样的想法。它使用自回归连接对图像逐像素建模。它的两个变体PixelRNN[41]和PixelCNN[26]也产生了很好的样本。
我们的模型与这些模型都不同。如上面图2所示,我们将所提出的CVAE-GAN结构与所有这些模型进行了比较。除了结构上的差异,更重要的是,我们利用了统计和两两匹配的优点,使训练过程收敛得更快、更稳定。
3. Our formulation: the CVAE-GAN
在该部分,我们将介绍CVAE-GAN网络。如图3所示,我们提出的方法包含四部分:
- encoder网络E
- 生成网络G
- 判别网络D
- 分类网络C
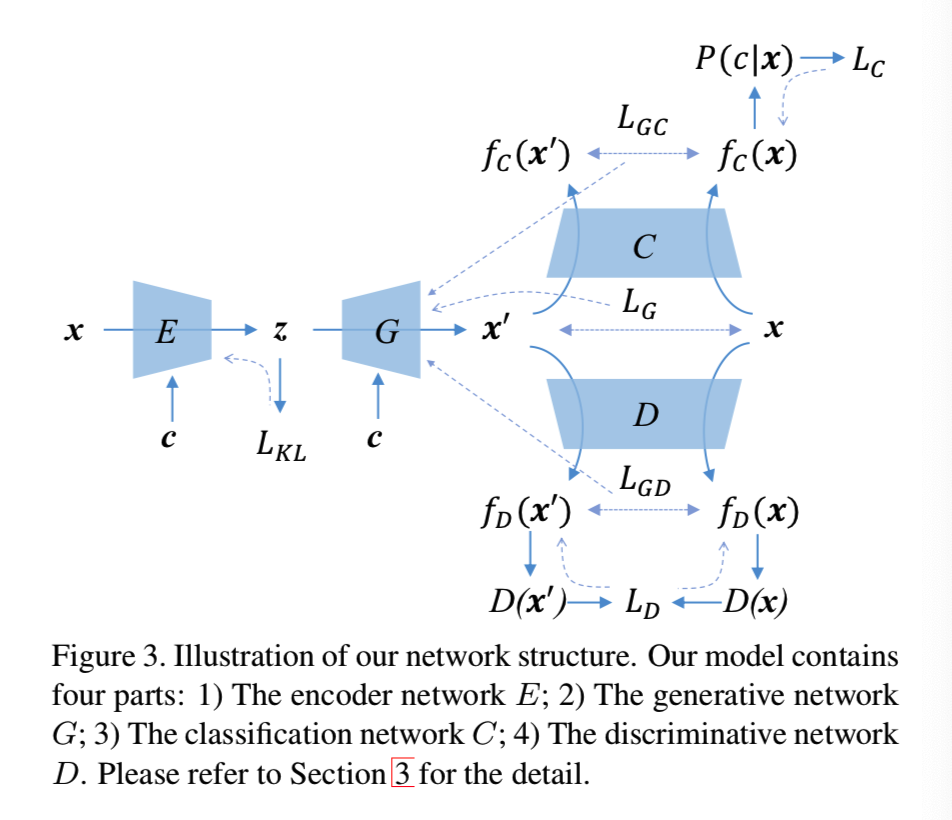
网络E和G的函数与条件变分自编码器(CVAE[34])相同。encoder网络E通过一个可学习分布P(z|x, c)映射数据样本x为一个潜在表征x,c表示数据的类别。生成网络G通过从可学习分布P(x|z, c)中采样生成图像x'。G和D的函数则和生成对抗网络(GAN[8])相同。网络G尝试通过来自能够区分真/假图的判别器网络D的梯度来学习真实数据的分布。C网络的函数则是去测量P(c|x)的后验
可是简单的VAE和GAN的结合是不够的。最近的研究[1]表明了如果采用了原始的KL散度损失,训练GAN时将会出现网络G的梯度消失问题。因为,我们今保持网络E、D和C的训练过程与原始的VAE和GAN相同,然后提出一个新的平均特征匹配目标函数给生成网络G,用来改善原始GAN网络的稳定性
即使使用了平均特征匹配目标函数,这里仍然存在可能导致模型崩溃的发生。所以我们使用encoder网络E和生成网络G去获得一个从真实样本x到合成样本x'的映射,通过使用基于像素的L2损失和基于对的特征匹配,生成器模型将会强迫呈现出不同的样本并生成结构保留的样本
在下面的部分中,我们首先描述基于GAN的平均特征匹配方法(3.1部分)。然后展示平均特征匹配能够被使用在条件图像生成任务中(3.2部分)。接着是介绍通过一个添加的encoder网络实现的基于对的特征匹配(3.3部分)。最后分析提出方法的目标函数,并提供训练管道的实现细节(3.4部分)
3.1. Mean feature matching based GAN
在传统GANs中,生成器G和一个判别器D一个最小最大游戏中竞争。判别器尝试去从合成图像中区分真的训练数据,生成器则尝试去骗过判别器。具体来说就是网络D尝试去最小化下面的损失函数:

而网络G则尝试去最小化:
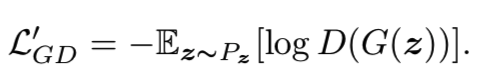
可是在实际中,真实数据的分布和虚假数据可能互不相关,尤其是在早期的训练过程中。判别器网络D能够很完美地区别它们。我们总能得到D(x) -> 1和D(x') -> 0,x'=G(z)即生成的图像。因此,我们将更新网络G,使梯度 ∂L'GD/∂x' -> 0。网络G会可容易陷在局部的最小解中,因为G不是一个凸函数。最近的研究[1,2]也理论上战术了GAN的训练经常遇见网络G的梯度消失问题。
为了解决这个问题,我们建议为生成器使用平均特征匹配目标函数。该目标函数需要合成样本的特征中心去匹配真实样本的特征中心。让fD(x)表示判别器中间层的特征,然后G尝试去最小化损失函数为:
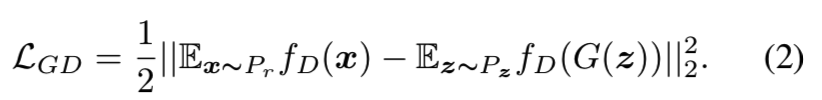
在我们的实验中,为了简化,选择了网络D的最后一个全连接层的输入作为特征fD。结合多层的特征能够稍微改善收敛速度。在训练过程中,我们使用mini-batch的数据估计平均特征。然后我们还使用历史的移动平均来使它更稳定。
因此,在训练阶段,我们使用公式1)更新网络D,使用公式2)去更新网络G。使用这个用于训练GAN的非对称损失有三个优势:
- 当公式2)随着可分性的增加,在特征中心的L2损失就能够解决梯度消失问题。
- 当生成的图像足够好,平均特征匹配损失将为0,这使得训练更稳固
- 与WGAN[2]相比较,我们不需要剪切参数。网络D的判别能力也能够保持
3.2. Mean feature matching for conditional image generation
在这部分,我们将介绍用于条件图像生成的平均特征匹配方法。假设我们有一个属于K类别的数据集,我们使用网络C去测量是否一个图像属于这个特殊的细粒度类别。这里我们使用了分类的标准方法。网络C将x作为输入,然后输出一个K维的向量,然后使用softmax函数将其转为类概率值。输出的每个口都表示了后验概率P(c|x)。在训练阶段,网络C尝试最小化softmax损失:
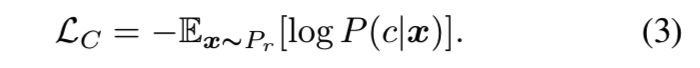
同时对于网络G,如果我们仍然使用相同的softmax损失函数的话,它将会同样导致3.1部分所说的梯度消失问题。
因此我们为生成网络G提出了使用平均特征匹配目标函数。让fC(x)表示分类器的中间层,然后让网络G尝试去最小化:
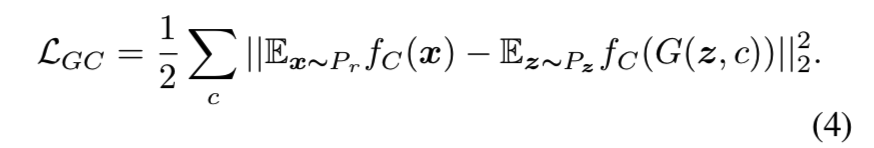
在这里,为了简化,我们选择网络C的最后一个全连接层的的输入作为特征。我们也尝试去合并多层的特征,这仅仅是稍微提高了网络G的身份保持能力。因此在mini-batch中紧紧只有一些样本属于同一类别,有必要对真实样本和生成的样本使用特征的移动平均。
3.3. Pairwise feature matching
虽然使用平均移动匹配方法能够阻止所有输出移动到某个点,但它不能完全解决这个问题。尽管生成样本和真实图像有着相同的特征中心,但是它们可能有着不同的分布。一旦模型奔溃发生,生成网络将会为不同的潜在向量生成相同的图像,因此梯度下降将不能分离出相同的输出
为了生成不同的样本,DCGAN[29]使用Batch Normalization,McGAN[20]同时使用均值和协方差特征统计,Salimans et al.[33]使用mini-batch判别。他们都是基于使用多生成样例。与这些方法的不同在于我们添加了encoder网络E去获得真实图像x到潜在样本空间z的映射。因此,我们直接设置了真实图像和潜在空间的关系
与VAE相同,对于每个样本,encoder网络输出潜在向量的均值和协方差,即μ和ε。使用KL损失减小先验P(z)和推荐分布的边界:
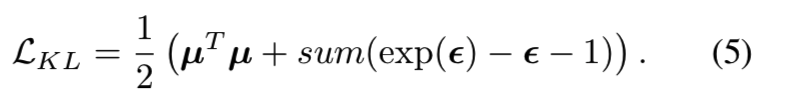
然后我们能够从潜在向量:

这样获得从 x到z的映射后,我们能够使用网络G去获得生成的图像x'。然后,我们能够在x和x'中添加一个L2重构损失和基于对特征匹配损失:
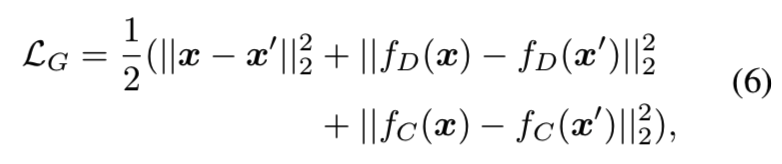
fD和fC分别是判别网络D和分类器C中间层的特征。
3.4. Objective of CVAE-GAN
因此总结一下,我们方法的目标就是去最小化下面的损失函数:
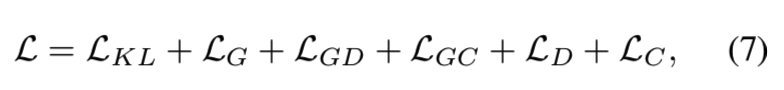
上面的每一部分都是有意义的。LKL仅与encoder网络E相关,表示是否潜在向量的分布是符合期望的。LG、LGD和LGC是与生成器网络G相关的,表示合成图像是否分别和输入训练样本、真实图像和相同类别中的其他样本相同。LC与分类器网络C相关,表示网络用来分类不同类别图像的能力;LD则与判别器网络相关,表示该网络区分真/合成图像的能力有多好。所有这些目标函数都是互相的补充,并最后能够使我们算法获得最优的结果。整个训练过程如算法1所述:

4. Analysis with a toy example
在这个部分,我们使用一个例子来表示和阐述基于GAN的平均特征匹配方法的好处。我们假设有一个真实数据分布如图4(a)的环形所示:
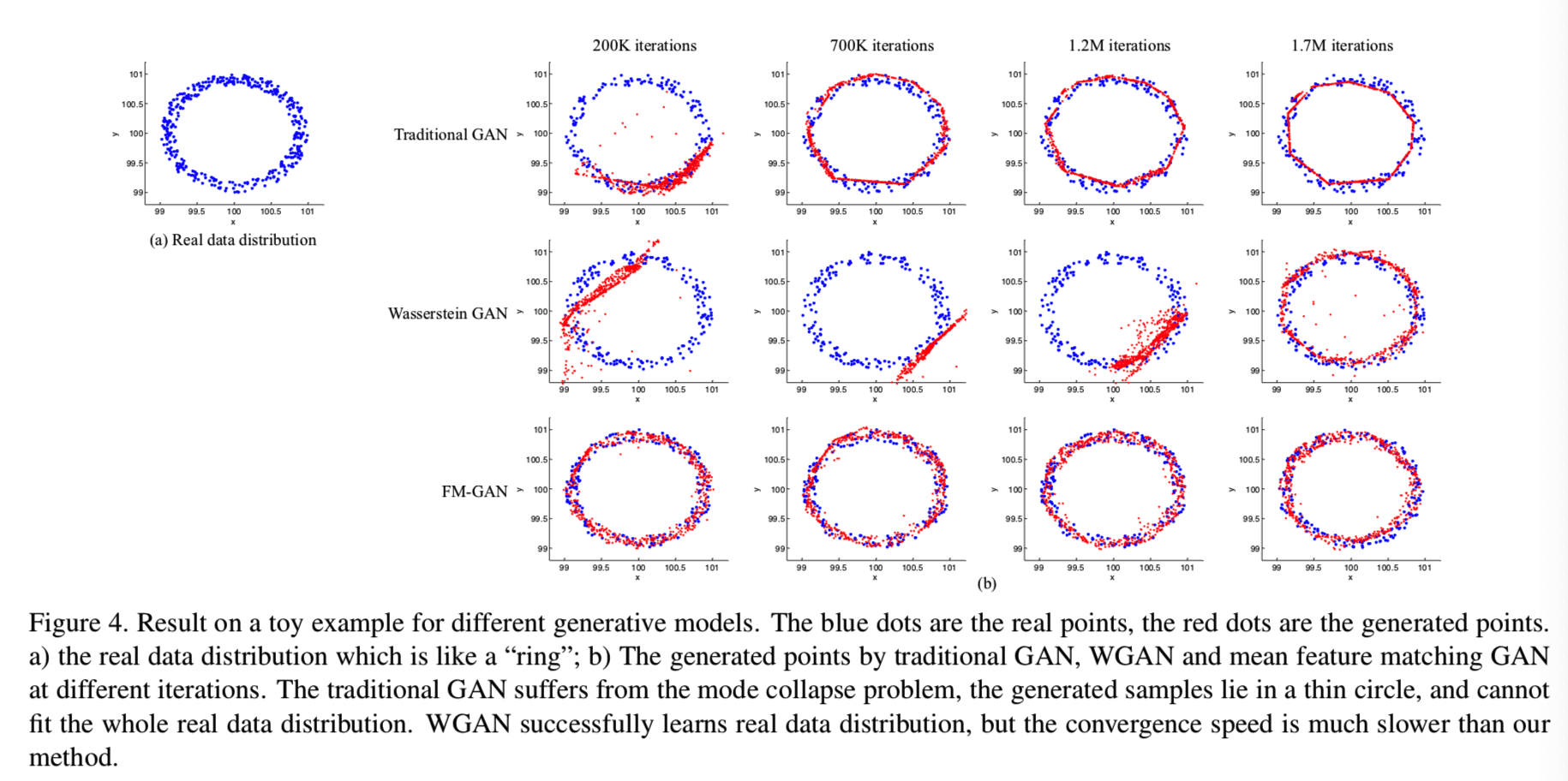
环的中心设置为(100, 100),其一开始与生成的分布离得很远。我们比较传统GAN、WGAN和我们在3.1部分介绍的基于GAN的平均特征匹配方法去学习真实数据分布。
这三个比较的模型共享相同的设置,生成器G为分别有32,64,64个单元的三个隐藏层的MLP。判别器D也是分别有32,64,64个单元的三个隐藏层的MLP。对所有方法都使用RMSProp和固定的学习率0.00005。每个模型都训练2M次迭代,直到都收敛。每个模型在不同迭代的生成样本都如上图4所示,从结果中我们能够观察到:
- 对于传统GAN来说(图4(b)的第一行),生成的样本仅坐落在真实数据分布中的有限区域,这就是一直的模型崩溃问题。
- 对于WGAN来说(图4(b)的第二行),在早期的迭代中不能够学习真正数据的分布,我们认为这个问题是由初始化权重的技巧操作导致的,这影响了D区分真实/虚假图像的能力。我们还尝试改变权重初始化的值来加速训练过程,发现如果取值过小,会导致梯度消失问题。如果取值过大,网络就会分化。
- 第三行展示了推荐的基于GAN的特征匹配方法的结果,他能正确学习真实数据的分布,并且速度最快
5. Experiments
在这个部分,我们将验证提出方法的有效性。在三个数据集中评估我们的模型:the FaceScrub [21], the CUB-200 [43],和102 Category Flower [24] 数据集。
这三个数据集包含三类完全不同的目标,分别是人类、鸟和花,来测试我们模型的生成能力
所有实验输入的大小和合成图像的大小为128*128。对于FaceScrub数据集,我们先使用JDA人脸检测器[3]检测人脸区域,然后使用SDM[45]定位人脸坐标(两个眼睛、鼻子和嘴巴的两个角)。之后就是使用基于人脸坐标的相似性变换将人脸对齐到一个标准位置。最后则是剪切一个以鼻子为中心的128*128的人脸区域。对于CUB-200数据集,我们直接使用该数据集的原始图像。对于102 Category Flower数据集,我们在包含花朵的真实mask的基础上紧紧裁剪出一个矩形区域,然后将其调整为128×128。
在我们的实验中,encoder网络E是一个GoogleNet[36]网络,类型信息和图像在encoder网络E的最后的全连接层合并。生成网络G包含两个全连接层,然后跟着6个反卷积层,实现2-by-2的上采样。卷积层的过滤器大小分别为3*3、3*3、5*5、5*5、5*5、5*5,通道数大小分别为256、256、128、92、64、3。对于判别器网络,我们使用和DCGAN[29]相同的判别器网络。对于分类器网络,我们使用Alexnet[13]结构,更改输入为128*128。固定潜在向量维度为256,且对于生成图像来说该配置就足够了。batch normaliza层[11]在每一个卷积层后面都使用。该模型使用学习框架Torch实现。
5.1. Visualization comparison with other models
在实验中,我们将与基于在3.2部分(FM-CGAN)介绍的CGAN的推荐的特征匹配方法和带有用于生成细粒度图像的其他生成器模型结合的CVAE-GAN相对比
为了公平地对比每个模型,我们为所有方法使用相同的结构。对于CVAE,对encoder网络E和生成器网络G使用相同的卷积结构。对于CGAN,我们使用和CVAE-GAN网络相同的生成器网络G和判别器网络D。所有方法使用相同的训练数据。在测试阶段,网络结构也相同。这三个办法进使用网络G去生成图像。因此,虽然我们的方法在训练阶段有更多的参数,我们相信这个对比是公平的
我们在三个数据集中实行实验:the FaceScrub [21], the CUB-200 [43],和102 Category Flower [24] 数据集。我们为所有方法实现分类条件图像生成任务。对于每个数据集,所有方法都在该数据集的所有数据中训练。在测试阶段,我们首先随机选择一个类别c,然后通过采样潜在样本z~N(0,I)来随机选择该类别的生成样本。为了评估,我们可视化了所有方法的样本生成。
比较结果显示在图5:
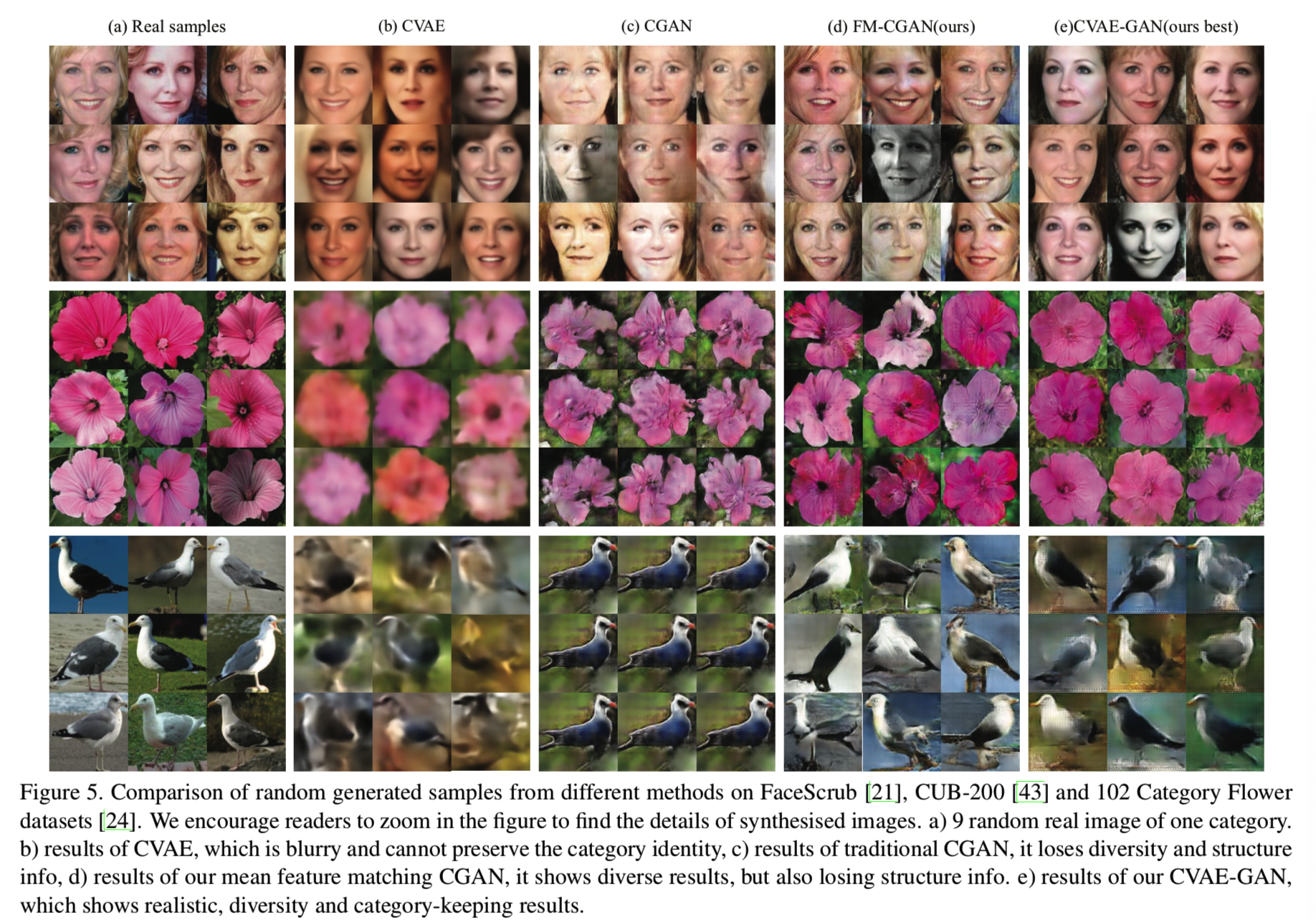
所有图像都是随机选择的,没有任何偏好
我们能够观察到CVAE生成的图像一般都比较模糊。也注意到CVAE不能保持图像的身份信息,一些从CVAE中生成的图像与在FaceScrub数据集中该类别的人看起来并不像。对于传统的CGAN,类别中的方差很小,这将导致模型崩溃。对于FM-CGAN,我们能够观察到保持住身份信息的清楚图像,但是一些图像失去了目标的结构,如脸的形状。
从另一方面来说,通过提出的方法生成的图像看起来更真实和清楚,且互相之间都有这比较大的差异,尤其是在观测点和背景颜色上。我们的模型能够保持身份信息。显示了提出的CVAE-GAN模型的能力。
5.2. Quantitative comparison
评估生成图像的质量是具有很大挑战性的,因为概率标准[38]的不同。我们企图从三方面测量生成模型:判别力、多样性和真实性
我们使用该实验的人脸图。首先,从CVAE、CGAN、FM-CGAN和CVAE-GAN模型中随机生成53k样本(每个类100个)用于评估
为了测量判别力,我们使用在真实数据中预训练的人脸分类网络,在这里使用的是Inception网络[36]。在训练模型中,我们评估从每个方法中生成样本的top-1精确度,结果显示在表1中:
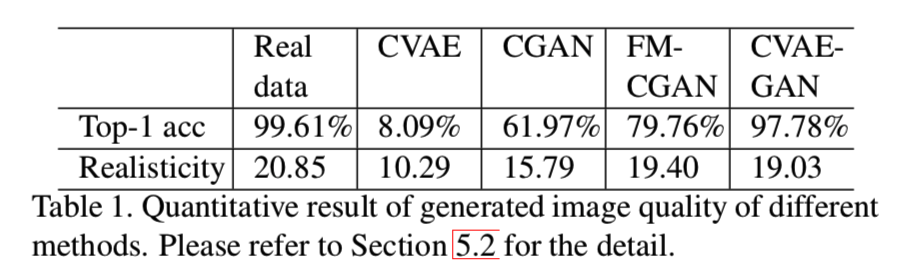
可见,我们模型获得了最好的top-1结果,并远远高于其他生成模型,其表示该推荐方法的有效性。
遵循[33]方法,我们使用Inception分数来评估真实性和生成样本的多样性。我们在CASIA[48]数据集中训练一个分类模型,采用exp(EzKL(p(y|x) || p(y)))作为测量生成模型真实性和多样性的度量标准。p(y|x)表示每个类生成样本的后验概率。包含有意义目标的图像应该有一个带着低熵的条件标签分布p(y|x)。而且如果模型生成多样的图像,其p(y) = ∫p(y|G(z)) dz应该有着高熵。更大的分数意味着生成器能生成更真实和多样的图像。如表1所示,我们的方法和FM-CGAN能够获取更高的分数,并与真实数据的值很接近
5.3. Attributes morphing
在这部分,我们将验证生成图像中的属性会随着潜在向量的变化而不断变化。我们将其称为属性变形。我们将在the FaceScrub [21], the CUB-200 [43],和102 Category Flower [24]三个数据集中测试我们的模型。首先挑选一对相同类型的图x1和x2,然后使用encoder网络E抽取潜在向量z1和z2。最后通过线性插值获得一系列潜在向量z,如z = α*z1 + (1-α)*z2, α属于[0,1]。图6展示了属性变形的结果:

每一行中的属性,如位置、情绪和颜色或花的数量,都从左到右逐渐变化
5.4. Image inpainting
在这部分,展示了我们的模型能够应用在图像修补中。首先随机从原始128*128的图像x中破坏50*50的补丁图像,如图7b:

然后将其输入encoder网络E去获得潜在向量z,然后通过G(z,c)去生成图像x',c是类别标签,然后通过如下的等式来更新图像:


修补结果显示在上图的7(c)。我们应该强调所有的输入图像都是从网上下载的,没有一个属于训练数据。当然,我们能迭代地输入结果图像到模型中去获得更好的结果,如上图7(d,e)所示
5.5. CVAE-GAN for data augmentation
我们进一步展示了我们模型的图像生成能够用于训练更好的人脸识别模型中的数据增强。我们使用FaceScrub数据集为训练数据集,LFW[16]为测试数据集
FaceScrub数据集仅包含530个人,不足以训练一个好的识别模型。因此,我们的目标是验证额外生成训练数据的使用能够改善人脸识别的精确度。一个更大的数据集能用于训练。我们将其留到未来的研究中。我们采用带有softmax损失的GoogleNet,就像我们的网络一样。
我们使用两种数据增强策略:
- 生成更多训练数据集中已有身份的图像
- 通过混合不同的身份来生成新的身份
我们测试这两类数据增强方法:
- 随机为每个人生成200张图像,总共100k张。
- 通过随机混合三个不同的已有身份来创建5k个新身份,然后对每个新生成的身份生成100张图
对于这两个策略,生成的图像将于FaceScrub数据集结合来一起训练一个人脸识别模型
在测试阶段中,我们直接使用cosine特征的相似度来测量两张图之间的相似度。表2中对比了在LFW数据集和没有额外生成数据的人脸识别精度:
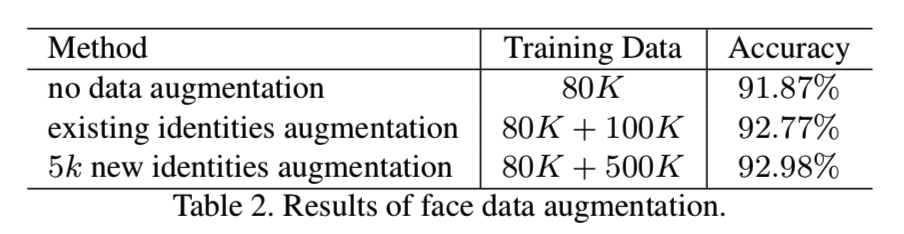
带着新身份的数据增强方法与无增强的方法相比精确度有1.0%的改善。这表示了我们的生成网络有着一些推断能力
6. Conclusion
本文提出了一种用于细粒度分类图像生成的CVAE-GAN模型。在三个不同数据集上的优越性能显示了它生成各种对象的能力。该方法可以支持多种应用,包括图像生成、属性变形、图像修复和数据增强,用于训练更好的人脸识别模型。我们未来的工作将探索如何生成未知类别的样本,例如训练数据集中不存在的人脸图像。
补充材料
S7. Comparing different combination of losses
在该模型中,提出了在图像的像素级别上使用基于对的特征匹配方法,在分类器网络C和判别器网络D的特征级别上更新G网络。为了理解每个loss成分的作用,我们分离下面的损失:
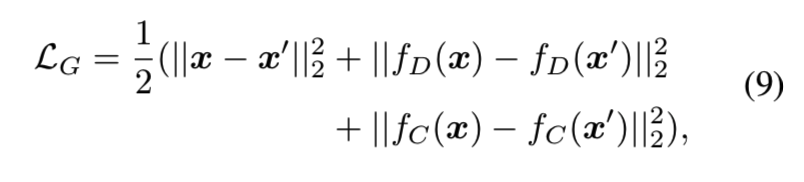
为三部分:
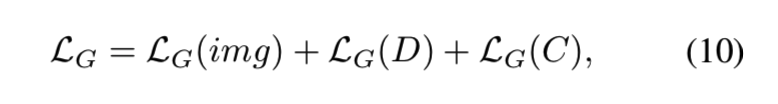
LG(img)是图像像素级别的L2损失, LG(D)是判别器网络D在特征级别上的L2损失,LG(C)是分类器网络C在特征级别上的L2损失
我们重复训练相同设置的CVAE-GAN模型,但使用不同 LG(img)、LG(D)和LG(C)的损失组合,对比它们重构图像的质量。如图S8所示:


我们能发现移除对抗损失LG(D)将导致模型生成模糊图像。移除像素级别的重构损失LG(img)将导致图像失去细节。最后一处特征级别的损失LG(C),生成的样本将失去类别信息
S8. Analysis of the latent vector z
由于网络G只能用潜在向量z和类别标签c重构输入图像。因此期望其能够在潜在向量中轻松地编码所有的属性信息,如位置、颜色、光照、甚至是更复杂的高级风格。我们将介绍关于潜在向量的一些有趣的发现。
相同的潜在向量表示相同的属性。一个重要的发现是虽然我们不在属性上使用任何监督,对于不同标签的相同潜在向量将会生成带有不同类别标签但是有着相同属性的图像。该现象的原因是可能有着相同属性的图像在像素级别上表示某些相似之处。所以网络通过无监督聚类自动将它们放在了一起
为了证实它,我们在人脸数据集FaceScrub中训练了一个模型,然后抽取所有人脸图像的潜在向量。为了清楚地表示分布,我们通过PCA方法将所有的潜在向量投射为二维空间,如图S9所示:
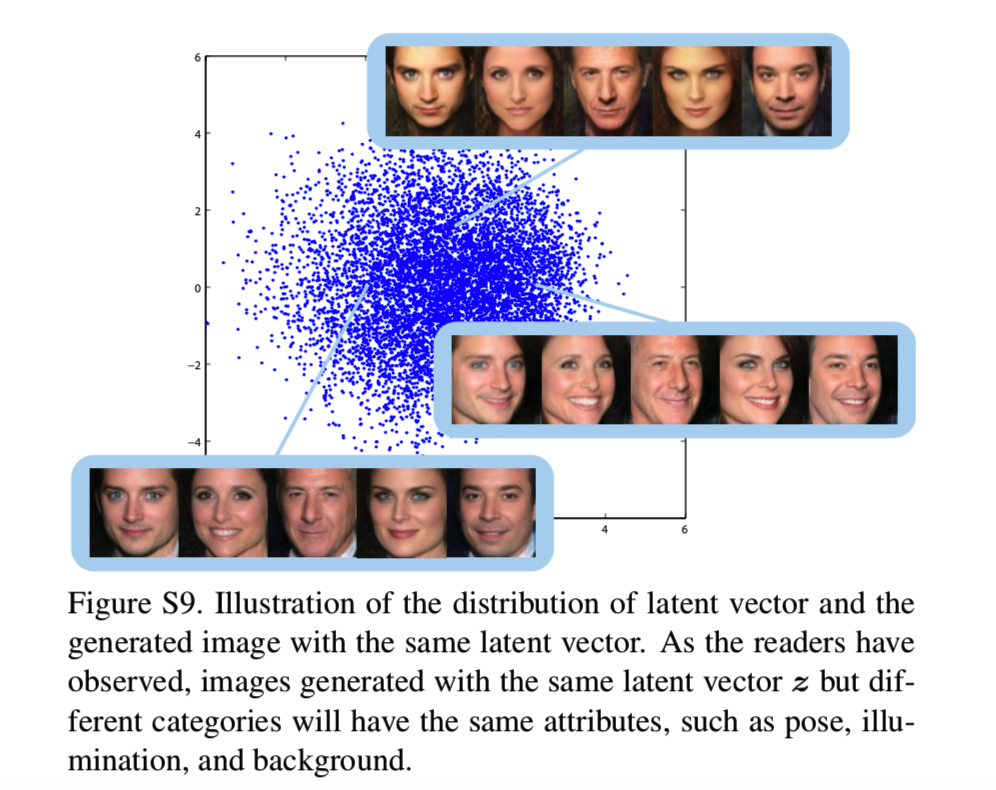
可见潜在向量的分布如期望是一个高斯分布,而图像的属性,如人脸位置、照明和背景对于相同的潜在分布来说都是相同的。
在该特性下,我们的算法能够用在其他应用中,如属性转换,即生成的图像有着不同的类别标签,但是有着相同属性;以及属性搜索,即搜索其他有着相同属性的图像
S8.1. Attributes transformation
在该部分,我们实验证明属性转换的有效性。我们在数据集FaceScrub上进行测试。给定一张源数据,我们首先使用encoder网络E去抽取潜在向量z。然后使用该潜在向量,我们就能够生成具体类别的图像了,如图S10所示:

展示了属性转换的结果。我们生成了某目标类别的图像,其属性和源图像相同。源图像即左边的图像,用来提取潜在向量,得到该图像的属性,如在笑等,然后右边的每一列表示输入的标签c,表示使用的人脸,即要将抽取的属性使用在哪张脸上
S8.2. Attributes retrieval
通过上面对潜在向量的分析,我们提出下面的推断:
相同的潜在向量表示相同的属性。因此我们能够使用我们的encoder模型E去抽取属性特征,然后使用它们去搜索在数据集中有着相同属性的图像。使用数据集FaceScrub进行测试。我们首先通过encoder网络E抽取所有属性特征。然后使用L2距离简单构造一个图像检索任务。如图S11所示:

展示了与左边查询的图像最相似的前5的结果,但是有着不同的类别,即不同的人但是有着相同表情特征。我们发现得到的人脸有着相同的肤色、视角和情绪。
S9. Nearest Neighbors Test
在该部分,我们想要说明我们的模型在训练部分不仅仅只存储了所有的训练样本。我们的模型能够生成不是训练样本的复制体的样本。使用数据集FaceScrub进行实验。首先我们随机从8个类别中生成8个样本。然后我们使用像素级别的L2距离简单地构造一个图像搜索任务,如S12所示:


我们显示了与生成图像最相似的前5个结果,我们发现生成的图像与最近邻比较有着相同的身份,但是不同的属性,如位置、照明和情绪
CVAE-GAN论文学习-1的更多相关文章
- (转) GAN论文整理
本文转自:http://www.jianshu.com/p/2acb804dd811 GAN论文整理 作者 FinlayLiu 已关注 2016.11.09 13:21 字数 1551 阅读 1263 ...
- Faster RCNN论文学习
Faster R-CNN在Fast R-CNN的基础上的改进就是不再使用选择性搜索方法来提取框,效率慢,而是使用RPN网络来取代选择性搜索方法,不仅提高了速度,精确度也更高了 Faster R-CNN ...
- 《Explaining and harnessing adversarial examples》 论文学习报告
<Explaining and harnessing adversarial examples> 论文学习报告 组员:裴建新 赖妍菱 周子玉 2020-03-27 1 背景 Sz ...
- 论文学习笔记 - 高光谱 和 LiDAR 融合分类合集
A³CLNN: Spatial, Spectral and Multiscale Attention ConvLSTM Neural Network for Multisource Remote Se ...
- Apache Calcite 论文学习笔记
特别声明:本文来源于掘金,"预留"发表的[Apache Calcite 论文学习笔记](https://juejin.im/post/5d2ed6a96fb9a07eea32a6f ...
- 深度学习-Wasserstein GAN论文理解笔记
GAN存在问题 训练困难,G和D多次尝试没有稳定性,Loss无法知道能否优化,生成样本单一,改进方案靠暴力尝试 WGAN GAN的Loss函数选择不合适,使模型容易面临梯度消失,梯度不稳定,优化目标不 ...
- 论文学习笔记--无缺陷样本产品表面缺陷检测 A Surface Defect Detection Method Based on Positive Samples
文章下载地址:A Surface Defect Detection Method Based on Positive Samples 第一部分 论文中文翻译 摘要:基于机器视觉的表面缺陷检测和分类可 ...
- 生成式对抗网络(GAN)学习笔记
图像识别和自然语言处理是目前应用极为广泛的AI技术,这些技术不管是速度还是准确度都已经达到了相当的高度,具体应用例如智能手机的人脸解锁.内置的语音助手.这些技术的实现和发展都离不开神经网络,可是传统的 ...
- Generative Adversarial Networks,gan论文的畅想
前天看完Generative Adversarial Networks的论文,不知道有什么用处,总想着机器生成的数据会有机器的局限性,所以百度看了一些别人 的看法和观点,可能我是机器学习小白吧,看完之 ...
随机推荐
- Java内存模型、JVM内存结构和Java对象模型
JVM内存结构 我们都知道,Java代码是要运行在虚拟机上的,而虚拟机在执行Java程序的过程中会把所管理的内存划分为若干个不同的数据区域,这些区域都有各自的用途.其中有些区域随着虚拟机进程的启动而存 ...
- .net框架-队列(Queue)
队列(Queue) 队列代表一个先进先出的集合 队列元素为Object类型 .net框架提供Queue<T>泛型队列类 入队(Enqueue)和出队(Dequeue)是对列的基本操作,入队 ...
- Java编译器的优化
public class Notice { public static void main(String[] args) { // 右侧20是一个int类型,但没有超过左侧数值范围,就是正确的 // ...
- 一.使用LDAP认证
作用:网络用户认证,用户集中管理 网络用户信息:LDAP服务器提供 本地用户信息:/etc/passwd /etc/shadow提供 LDAP服务器:虚拟机classroom LDAP ...
- (尚008)Vue条件渲染
1.test008.html <!DOCTYPE html><html lang="en"><head> <meta charset=&q ...
- 生活 RH阴性血 AB型
这个血型很稀有,外国多些,中国很少. ABO型:A.B.AB.O RH血型系统:阴性,阳性 RH阴性血,被称为熊猫血,估计是稀有吧,阴性血缺抗D,我老婆的血型抗原好像是:ccee,大部分汉族人都有抗D ...
- Matlab中的变量名
在Matlab中使用save和load命令时,可能会出现变量名出错的问题. 如: save('A1.mat', 'A1'); load('A1.mat', 'A1'); 如果程序中还有名为a1的变量名 ...
- 第12组 Alpha冲刺(3/6)
Header 队名:To Be Done 组长博客 作业博客 团队项目进行情况 燃尽图(组内共享) 展示Git当日代码/文档签入记录(组内共享) 注: 由于GitHub的免费范围内对多人开发存在较多限 ...
- python中string、json、bytes的转换
json->string str = json.dumps(jsonobj) bytes->string str = str(bytes,‘utf-8’) string->json ...
- ZR#989
ZR#989 先吐槽一下这个ZZ出题人,卡哈希表. 我就不写那个能过的类高精了,直接写哈希的题解 解法: 判断两个数相加结果是否等于第三个数, 可以直接用 hash判断. #include<io ...