Real-time ‘Actor-Critic’ Tracking
Real-time ‘Actor-Critic’ Tracking
2019-07-15 10:49:16
Code: https://github.com/bychen515/ACT
1. Background and Motivation:
本文提出一种利用 “连续” 动作空间的强化学习算法来进行跟踪。之前的 MDNET 是随机采样,然后进行打分的;而 ADNet 是 “离散”的动作选择,即:通过一系列离散的动作选择,实现 BBox 的移动,来完成跟踪。下图展示了本文方法与这两种方法的不同:

本文的贡献点在于:
1). 该算法是首次探索了连续的动作 (continuous actions) 进行跟踪,仅通过 Actor model 进行一次动作选择,即可完成动作的定位;
2). 该算法也是首次利用 “Actor-Critic” 跟踪框架。
3). 在速度达到实时的同时,精度也比不错。
2. Tracking via the "Actor-Critic" Network:
2.1 Problem Settings:
本文将跟踪问题看做是序列决策问题(Decision-making problem)。基础的马尔科夫决策过程包括如下几个元素:State,Action,State transition functions,Reward。
在本文中,tracker 被当做是 agent,并且来预测每一帧目标物体的准确位置。该智能体与环境进行交互,通过观察 s,执行动作 a,并且得到奖励 r。在第 t 帧中,智能体根据当前的状态 s,给出了连续的动作 a,得到了跟踪结果 s'。动作 a 被定义为:the relative motion of the tracked object,表明在当前帧,应该怎么直接移动 BBOX。与 ADNET 不同的是,该算法仅仅执行一个连续的动作,来定位目标物体,使得该算法更加高效。具体各个元素的定义如下:
State:
在该工作中,作者定义状态 s 为:在BBox内部的观察到的图像块。给定视频帧 F 和 BBox b = [x, y, h, w],作者首先用预处理函数 s 来处理得到该图像块。
Action and State Transition:
为了进行连续的控制,动作空间被假设为连续的,即:如何直接移动该 BBox。此处,作者用 $a = [\Delta x, \Delta y, \Delta s]$ 来描绘跟踪物体的相对运动,$\Delta x, \Delta y$ 表明了物体水平和竖直方向的变换,$\Delta s$ 表明了尺寸的相对变换。考虑到跟踪物体时序上的连续性,作者加了如下的约束来控制 BBox 的变化幅度:$-1 <= \Delta x <= 1, -1 <= \Delta y <= 1, -0.05 <= \Delta s <= 0.05$。通过对上一帧的 BBox 进行这样动作的变换,可以得到一个新的 BBox b' = [x' y' h' w']:
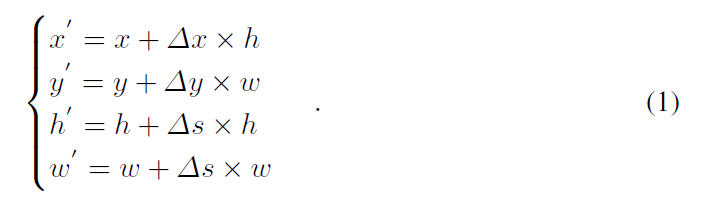
然后,状态转移过程 $s' = f(s, a)$ 可以隐式的通过预处理函数来实现。
Reward:
奖励函数 r(s, a) 描述了定位的准确性,所以,其可以按照重合度的方法进行度量:
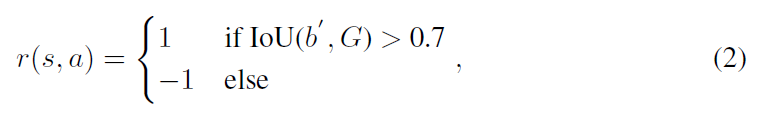
每次执行一个 action,都会产生一个奖励,然后被用于离线训练的深度网络更新 (to update the deep networks in offline learning)。
2.2 Offline Training:
Network Architecture:
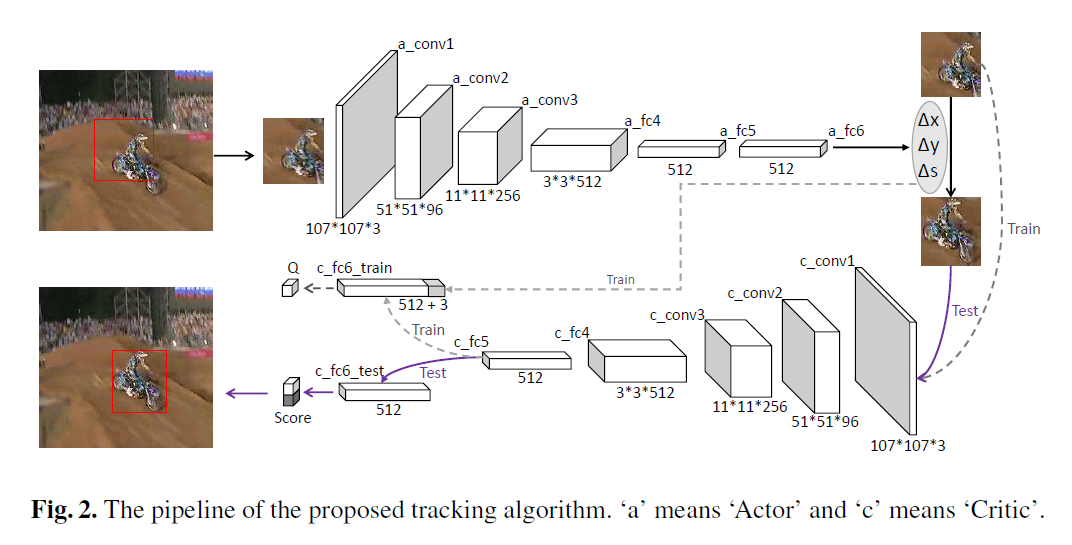
本文的网络结构如上图所示。可以看到 Actor network 是将上一帧的跟踪结果的 image patch 作为输入,输出是三维的数字,即对应了 水平,竖直 和 尺寸上的变换。在 offline training中,还有一个是 Critic network,该网络的结构跟 Actor 类似,但是用途是不同的。该网络要求的输入是:根据当前的状态,将三维 action vector 组合后的结果,以得到 Q-value,并用于动作的评价。
Training via DDPG:
本文采用 DDPG 方法来训练该 “Actor-Critic Network”,核心的思想是:迭代的训练 “Critic” 和 “Actor” 模型。给定 N 个经验 (si, ai, ri, si'),Critic model 可以利用贝尔曼方程来进行学习。通过目标网络,学习可以通过最小化下面的损失来实现:
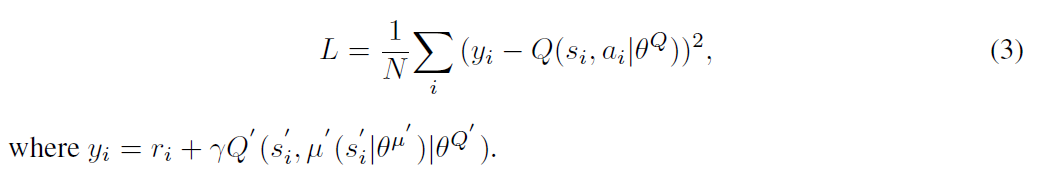
然后,Actor 模型可以通过链式法则进行更新:
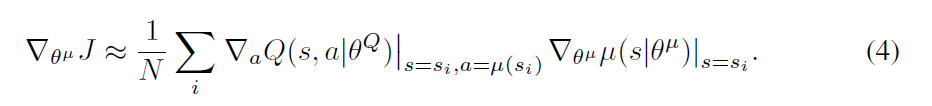
在训练迭代中,作者随机的选择一个训练序列及其 GT。在此之后,作者将跟踪器在选择的序列上得到了训练 pair (st, at, rt, st') 。

Experimental Results:
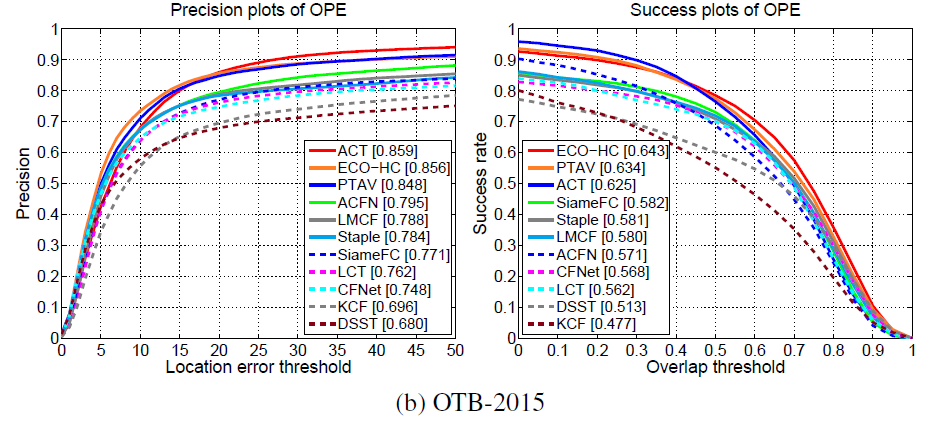
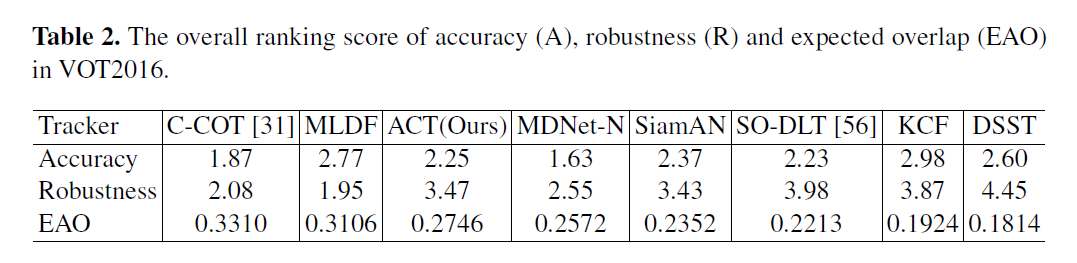
==
Real-time ‘Actor-Critic’ Tracking的更多相关文章
- 深度增强学习--Actor Critic
Actor Critic value-based和policy-based的结合 实例代码 import sys import gym import pylab import numpy as np ...
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor 20 ...
- TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- DRL 教程 | 如何保持运动小车上的旗杆屹立不倒?TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- Awesome TensorFlow
Awesome TensorFlow A curated list of awesome TensorFlow experiments, libraries, and projects. Inspi ...
- (转) Using the latest advancements in AI to predict stock market movements
Using the latest advancements in AI to predict stock market movements 2019-01-13 21:31:18 This blog ...
- 学习笔记TF053:循环神经网络,TensorFlow Model Zoo,强化学习,深度森林,深度学习艺术
循环神经网络.https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/re ...
- David Silver强化学习Lecture1:强化学习简介
课件:Lecture 1: Introduction to Reinforcement Learning 视频:David Silver深度强化学习第1课 - 简介 (中文字幕) 强化学习的特征 作为 ...
- 强化学习--Actor-Critic---tensorflow实现
完整代码:https://github.com/zle1992/Reinforcement_Learning_Game Policy Gradient 可以直接预测出动作,也可以预测连续动作,但是无 ...
- 论文笔记:Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments 2017-10-25 16:38:23 [Proj ...
随机推荐
- XML整形以及改行字符串输出
XML整形 估计如下一样使用XDocument的人比较多,毕竟也是微软推荐使用的. string FormatXml(string Xml) { try { XDocument doc = XDocu ...
- 机器学习 | 聚类分析总结 & 实战解析
聚类分析是没有给定划分类别的情况下,根据样本相似度进行样本分组的一种方法,是一种非监督的学习算法.聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度划分为若干组,划分的原则是组内距离最小化 ...
- ugui用户定义操作按键
界面很简单,只创建了一Image,Image下边有一个Text.基本思路是点击Image,Text清空,进入修改状态,然后用户按下任意键,按下的任意键极为修改后的键 然后下面的脚本是挂在Image下面 ...
- SpringBoot2.x项目初始化
1. 项目初始化说明 使用SpringBoot生成器 修改application.properties为application.yml 启动运行SpringBoot项目 2. 初始化项目 Spring ...
- MySQL AutoIncrement--自增锁模式
自增锁模式 在MYSQL 5.1.22版本前,自增列使用AUTO_INC Locking方式来实现,即采用一种特殊的表锁机制来保证并发插入下自增操作依然是串行操作,为提高插入效率,该锁会在插入语句完成 ...
- openssl获取ssl证书,配置https
- BZOJ2523/LOJ2646 聪明的学生
BZOJ2523/LOJ2646 聪明的学生 第一道CTSC的题. 因为是思维题,所以思路就不写了.直接看代码吧. #include<bits/stdc++.h> #define M 30 ...
- 类型擦除对Java调用Kotlin的影响
@JvmName: 扩展方法相关: 先来定义一个扩展方法: 好,接下来再来定义一个扩展函数: 此时报错了..看一下错误提示: 其中给的提示有点奇怪,第一个是很明显咱们的扩展函数木有接收参数嘛,为啥提示 ...
- Linux UART驱动分析
1. 介绍 8250是IBM PC及兼容机使用的一种串口芯片; 16550是一种带先进先出(FIFO)功能的8250系列串口芯片; 16550A则是16550的升级版本, 修复了FIFO相关BUG, ...
- git上传者姓名修改
只需要两个指令 git config user.name 和 git config –global user.name 在控制台中输入git config user.name获取当前的操作名称 修改名 ...