ThreadLocal源代码3
public class ThreadLocal1<T> {
//当创建了一个 ThreadLocal 的实例后,它的散列值就已经确定了,
//threadLocal实例的hashCode是通过nextHashCode()方法实现的,该方法实际上总是用一个AtomicInteger(初始值为0)加上0x61c88647来实现的。
//0x61c88647这个数是有特殊意义的,它能够保证hash表的每个散列桶能够均匀的分布,这是Fibonacci Hashing,
//0x61c88647 这个就比较神奇了,它可以使 hashcode 均匀的分布在大小为 2 的 N 次方的数组里。下面写个程序测试一下:
//也正是能够均匀分布,所以threadLocal选择使用开放地址法来解决hash冲突的问题。
/*public static void main(String[] args) {
AtomicInteger hashCode = new AtomicInteger(); // 一直在增加
int hash_increment = 0x61c88647;
int size = 16;
List <Integer> list = new ArrayList <> ();
for (int i = 0; i < size; i++) {
list.add(hashCode.getAndAdd(hash_increment) & (size - 1));
}
System.out.println("original:" + list);
Collections.sort(list);
System.out.println("sort: " + list);
}
size=16: [7, 14, 5, 12, 3, 10, 1, 8, 15, 6, 13, 4, 11, 2, 9, 0] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
size=32 [7, 14, 21, 28, 3, 10, 17, 24, 31, 6, 13, 20, 27, 2, 9, 16, 23, 30, 5, 12, 19, 26, 1, 8, 15, 22, 29, 4, 11, 18, 25, 0]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31]
*/
private final int threadLocalHashCode = nextHashCode();//对象的属性,不变化的。
private final static int HASH_INCREMENT = 0x61c88647;//1640531527。类的属性。
//类的属性,对象共享,一直在增加。
private static AtomicInteger nextHashCode = new AtomicInteger();//
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);//nextHashCode自己变成了HASH_INCREMENT=1640531527
}
protected T initialValue() {//用于重写
return null;
}
public static <S> ThreadLocal<S> withInitial(Supplier<? extends S> supplier) {
return new SuppliedThreadLocal<>(supplier);
}
public ThreadLocal() {
}
//有可能第一次调用get不调用set,map为null,setInitialValue-initialValue赋予map=threadLocals初值。
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);//返回调用get()的线程的threadLocals,是一个ThreadLocalMap,这个ThreadLocalMap是ThreadLocal的内部类。
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();//如果map为空,也就是第一次没有调用set直接get(或者调用过set,又调用了remove)时,为其设定初始值
}
private T setInitialValue() {
T value = initialValue();//initialValue方法为第一次调用get方法提供一个初始值。
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
/* ThreadLocal<Integer> x = new ThreadLocal<Integer>();
for (int i = 0; i < 3; i++) {
new Thread(new Runnable() {
public void run() {
x.set(new Random().nextInt());
}
}).start();
}*/
//A,B,C线程通过共享变量ThreadLocal<Integer> x.set(s)。A,B,C线程分别修改的是自己线程的threadLocals=ThreadLocalMap
// 别的线程修改不了这个线程的threadLocals,所以对这个线程的ThreadLocalMap修改时候没有线程安全问题。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;//返回这个线程的threadLocal属性
}
void createMap(Thread t, T firstValue) {//threadLocals是一个ThreadLocalMap,key是调用ThreadLocal方法的这个ThreadLocal。
//ThreadLocal的方法肯定是ThreadLocal对象在调用。
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
static ThreadLocalMap createInheritedMap(ThreadLocalMap parentMap) {
return new ThreadLocalMap(parentMap);
}
T childValue(T parentValue) {
throw new UnsupportedOperationException();
}
static final class SuppliedThreadLocal<T> extends ThreadLocal<T> {
private final Supplier<? extends T> supplier;
SuppliedThreadLocal(Supplier<? extends T> supplier) {
this.supplier = Objects.requireNonNull(supplier);
}
@Override
protected T initialValue() {
return supplier.get();
}
}
static class ThreadLocalMap1 {//ThreadLocalMap里面有一个数组table,table里面的元素是Entry extends WeakReference。
//WeakReference里面属性有value和referent=ThreadLocal。ThreadLocal是被弱引用关联。
//ThreadLocal由强引用变成了弱引用,因为Entry继承了WeakReference,在Entry的构造方法中,调用了super(k)方法就会将threadLocal实例包装成一个WeakReferenece。
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;//value是真正需要存储的Object。
//ThreadLocalMap的Entry本身就是虚引用,
//WeakReference<B> weakReference = new WeakReference<B>(b1, rq); b1=null之后,weakReference就回去排队。
//Entry继承WeakReference,ThreadLocal=k释放了整个Entry就会去排队。
Entry(ThreadLocal<?> k, Object v) {//ThreadLocal放在WeakReference里面。
super(k);//ThreadLocal=null被gc后该 Entry 就会进入到 ReferenceQueue 中
value = v;
}
}
private static final int INITIAL_CAPACITY = 16;
private Entry[] table;
private int size = 0;//实际个数
private int threshold;
private void setThreshold(int len) {//加载因子为2/3,所以哈希表可用大小为:16*2/3=10,即哈希表可用容量为10。
threshold = len * 2 / 3;//threshold是总共容量的2/3。
}
private static int nextIndex(int i, int len) {//i+1对len取余
return ((i + 1 < len) ? i + 1 : 0);
}
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);//循环
}
//ThreadLocalMap是线程的属性,key是一个个的ThreadLocal,value是值。
ThreadLocalMap1(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);//threshold是总共容量的2/3。
}
private ThreadLocalMap1(ThreadLocalMap1 parentMap) {
Entry[] parentTable = parentMap.table;//获取table
int len = parentTable.length;//设置容量大小
setThreshold(len);//设置threshold
table = new Entry[len];
for (int j = 0; j < len; j++) {
Entry e = parentTable[j];//获取每一个Entry
if (e != null) {
@SuppressWarnings("unchecked")
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();//获取key是ThreadLocal
if (key != null) {
Object value = key.childValue(e.value);//e.value获取的是value
Entry c = new Entry(key, value);//构造新的Entry
int h = key.threadLocalHashCode & (len - 1);//计算table的索引
while (table[h] != null)
h = nextIndex(h, len);//索引加一重新计算索引
table[h] = c;//放入table
size++;
}
}
}
}
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else// hash冲突
return getEntryAfterMiss(key, i, e);
}
//ThreadLocalMap 中采用开放定址法,所以当前 key 的散列值和元素在数组中的索引并不一定完全对应。
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
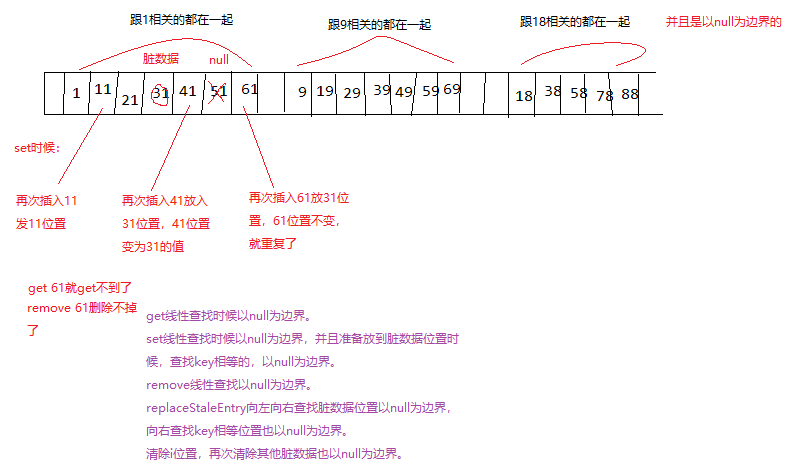
while (e != null) {//e是i位置的值,为null直接退出 ,null后面有key相等也不管了。 null为边界。所以get(61)就get不到了。
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null)//get时候遇到脏数据擦除 。因为强引用的ThreadLocal在外部置位了空。擦除这个位置时候,还会向右以null为边界,擦除其他脏数据。
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
//set也会擦除脏数据。设置时候不一定是新增,有可能是之前已经有了去替换。
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
//哈希表大小总是为2的幂次方,所以相与等同于一个取模的过程,
int i = key.threadLocalHashCode & (len-1);
//如果不考虑remove,所有跟i相关的都在i一起,并且是以null为边界的。考虑remove,所有跟i一样的是在一起并且null为边界,但是中间有可能有null。
//e=null退出说明没有冲突,不为null说明冲突了。 线性探测。 向右移动,null为边界。
for (Entry e = tab[i];e != null;e = tab[i = nextIndex(i, len)]) {//环形查找,不会死循环,因为会扩容。死循环是正常数据占据了全部位置。
ThreadLocal<?> k = e.get();
if (k == key) {//相等就覆盖
e.value = value;
return;
}
//放到脏数据位置,脏数据后面有key相等的也不管了。放脏数据位置时候会向右一直找到null看有没有key相等的,null后面有key相等的也不管了。最后放到脏数据位置。
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
//i个位置e=null,直接放
tab[i] = new Entry(key, value);
int sz = ++size;
//从i位置开始清除,清除掉了就不用hash,没有清除掉就hash。
if (!cleanSomeSlots(i, sz) && sz >= threshold)//size > len * 2 / 3
rehash();
}
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {//null后面有key相等的也不清除了。
if (e.get() == key) {//是根据ThreadLocal=key来判断是否同一个。
e.clear();//置WeakReference里面强引用referent=ThreadLocal=null,WeakReference里面清除引用关联只能clear()。因为是私有的。
expungeStaleEntry(i);//清除i位置,并向右以null为界清除其他脏数据。
return;
}
}
}
//替换到脏数据staleSlot位置:也不是放到脏数据位置,而是从staleSlot开始向右一直到null先找一遍,有key相等就交换 并放到staleSlot并清除这个位置,否则放到脏数据staleSlot位置。
//replaceStaleEntry并不仅仅局限于处理当前已知的脏entry,它认为在出现脏entry的相邻位置也有很大概率出现脏entry,所以为了一次处理到位,就需要向前环形搜索,找到前面的脏entry。
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
Entry[] tab = table;
int len = tab.length;//总长度,不是实际长度。
Entry e;
int slotToExpunge = staleSlot; //slotToExpunge是准备要清理的位置。
//slotToExpunge=null为边界左边最远脏数据位置。e都不为null就是死循环。所以肯定有null的。null在最后几个。remove也会有null。
//循环都是以null作为边界的。null后面有key相等也不要了。
for (int i = prevIndex(staleSlot, len);/*往前移动一个位置,会又走回来 */ (e = tab[i]) != null; i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i; // 清除数据也是以null作为边界的。
// 向右找,null就退出,中间有key相等的就停止。都不为null也没有相等的就死循环。
for (int i = nextIndex(staleSlot, len);/*往右移动一个位置,会又走回来 */ (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == key) {//向右移动,找到key相等的就去覆盖。 key跟i位置相等
e.value = value;
tab[i] = tab[staleSlot];//staleSlot是脏数据位置。i位置是key一样的位置。
tab[staleSlot] = e;//e还是放在了staleSlot位置。i这个key相等的位置直接被脏数据覆盖了。
//slotToExpunge == staleSlot不可能向左找又回来了, 找回来就是全部不是null,就是死循环。
if (slotToExpunge == staleSlot)//向左没有找到脏数据。第一个for循环没有改变slotToExpunge的值。
slotToExpunge = i;//清除的位置为i,否则清除位置是左边的脏数据。肯定要以左边的清除位置为准,因为可以清除的更多。
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);//expungeStaleEntry(slotToExpunge)清除slotToExpunge位置,
//slotToExpunge到返回值位置都已经没有脏数据,cleanSomeSlots(expungeStaleEntry(slotToExpunge), len)是从返回值位置开始清除脏数据。
return;
}
if (k == null && slotToExpunge == staleSlot)//slotToExpunge == staleSlot说明向左找又回来了, 说明e都不为null,会是死循环。
slotToExpunge = i;//左边没有脏数据右边i是脏数据。第一个for循环没有改变slotToExpunge的值。 清除的位置变为i。否则清除位置是左边的脏数据。肯定要以左边的清除位置为准,因为可以清除的更多。
}
//像右走,一直到e=null位置,都没有找到key相等的位置。就放到staleSlot脏数据位置。
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// staleSlot是放数据的位置,不能清除。
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
//清除i位置,并且i向右一直到null清除或者重新找位置
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;//局部变量是为了增强引用,不回收。
int len = tab.length;
// staleSlot位置 置位null。
tab[staleSlot].value = null;//Entry里面的value解除关系,Entry里面的referent已经解除关系了。
tab[staleSlot] = null;//Entry断掉引用关系,
size--;
// staleSlot位置移除可,往后一直在null,Rehash
Entry e;
int i;
//上面把staleSlot位置置为null了。从staleSlot向右一个个看,key为null就清除,不为null就重新算位置。e=null退出循环。
for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();//get()方法返回的是referent=ThreadLocal。
if (k == null) {//e不为null key是null就移除,
e.value = null;
tab[i] = null;//value移除,entyr解除关系,ThreadLocal已经解除关系为null了。
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {//重新找位置h
tab[i] = null;
while (tab[h] != null)
h = nextIndex(h, len);//h有元素,重新找h
tab[h] = e;//放到h的位置上去
}
}
}
return i;//旧i和新i之间全部没有脏数据了。新i是null的位置。
}
//本来只准备i开始移动log2(n)次,移动过程中发现有脏数据,就改变移动次数再次移动log2(len)次。
private boolean cleanSomeSlots(int i, int n) {//新插入的位置i和实际大小n
boolean removed = false;//并没有真正的清除,只是找到了要清除的位置,而真正的清除在 expungeStaleEntry(int staleSlot) 里面
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);//从i开始一个个向后看。循环log2(n)趟i一直加到i+log2(n),可以循环回来。
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;//如果在扫描过程中遇到脏entry的话就会令n为当前hash表的长度(n=len),再扫描log2(n)趟,
//注意此时n增加无非就是多增加了循环次数,增加循环次数就是i向右增加到更大的位置而已。
removed = true;
i = expungeStaleEntry(i);//清除i位置,并且i向右一直到null清除或者重新找位置。旧i到新i之间全部没有脏数据了,下次从新i开始就可以了。
}
//执行 对数次数 数量的扫描,是一种 基于不扫描(快速但保留垃圾)和 所有元素扫描之间的平衡。
} while ( (n >>>= 1) != 0);//n除以2,n用来控制扫描趟数(循环次数),在扫描过程中,如果没有遇到脏entry就整个扫描过程持续log2(n)次,log2(n)的得来是因为n >>>= 1,每次n右移一位相当于n除以2。
//
return removed;
}
private void rehash() {//首先会清理陈旧的 Entry,如果清理完之后元素数量仍然大于 threshold 的 3/4,则进行扩容操作(数组大小变为原来的 2倍)
expungeStaleEntries();
if (size >= threshold - threshold / 4) //size >= 3/4*threshold, size >= 1/2*len
resize();//扩容
}
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {//遍历过程中如果遇到脏entry的话直接另value为null,有助于value能够被回收
e.value = null; // 帮助GC
} else {//重新hash
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
/**
*/
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {//遍历所有的元素
Entry e = tab[j];
if (e != null && e.get() == null)//key为null的有问题元素。
expungeStaleEntry(j);
}
}
}
}
ThreadLocal源代码3的更多相关文章
- Java ThreadLocal 源代码分析
Java ThreadLocal 之前在写SSM项目的时候使用过一个叫PageHelper的插件 可以自动完成分页而不用手动写SQL limit 用起来大概是这样的 最开始的时候觉得很困惑,因为直接使 ...
- 多线程之美2一ThreadLocal源代码分析
目录结构 1.应用场景及作用 2.结构关系 2.1.三者关系类图 2.2.ThreadLocalMap结构图 2.3. 内存引用关系 2.4.存在内存泄漏原因 3.源码分析 3.1.重要代码片段 3. ...
- ThreadLocal源代码2
private static int nextIndex(int i, int len) { return ((i + 1 < len) ? i + 1 : 0); } private stat ...
- ThreadLocal源代码1
public class ThreadLocalTrxt { static ThreadLocal<Object> x1 = new ThreadLocal<Object>() ...
- 另一鲜为人知的单例写法-ThreadLocal
另一鲜为人知的单例写法-ThreadLocal 源代码范例 当我阅读FocusFinder和Choreographer的时候,我发现这两类的单例实现和我们寻经常使用双重检查锁非常不一样.而是用来一个T ...
- java ThreadLocal(应用场景及使用方式及原理)
尽管ThreadLocal与并发问题相关,可是很多程序猿只将它作为一种用于"方便传參"的工具,胖哥觉得这或许并非ThreadLocal设计的目的,它本身是为线程安全和某些特定场景的 ...
- ThreadLocal分析
我们再介绍一个在多线程环境中经常使用的类ThreadLocal,它是java为解决多线程程序的并发问题提供了一种新的方向,使用这个ThreadLocal类可以帮助开发者很简单地编写出简洁的程序,并且是 ...
- ThreadLocal深入理解与内存泄露分析
ThreadLocal 当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本.所以每个线程都能够独立地改变自己的副本.而不会影响其他线程所相应的副本. ...
- 深入理解线程本地变量ThreadLocal
ThreadLocal理解: 假设在多线程并发环境中.一个可变对象涉及到共享与竞争,那么该可变对象就一定会涉及到线程间同步操作,这是多线程并发问题. 否则该可变对象将作为线程私有对象,可通过Threa ...
随机推荐
- node中https请求 | 实现https的请求,获取图片,然后转成base64字节码
get请求 下面实现https的请求,获取图片,然后转成base64字节码 this.checkCodeUrl = 'https://www.test.com/kaptcha.jsp'; var ht ...
- 用Python 打开程序的两中方法
1.ShellExecute函数 import win32api win32api.ShellExecute(0, 'open', 'notepad.exe', '', '', 0) # 后台执行 w ...
- Frightful Formula Gym - 101480F (待定系数法)
Problem F: Frightful Formula \[ Time Limit: 10 s \quad Memory Limit: 512 MiB \] 题意 题意就是存在一个\(n*n\)的矩 ...
- 解读Es6之 promise
单线程: 在同一时间只能有同一任务进行.JavaScript就是一门单线程语言 当有多个任务需要进行时,则需要进行排队,前一个执行完毕才能执行下一个; ...
- EF core 性能调优
Entity Framework Core performance tuning – a worked example Last Updated: February 25, 2019 | Create ...
- [RN] React Native 使用精美图标库react-native-vector-icons
React Native 使用精美图标库react-native-vector-icons 一.安装依赖 npm install --save react-native-vector-icons // ...
- openjudge1.2
目录 1.2.1 1.2.2 1.2.3 1.2.4 1.2.5 1.2.6 1.2.7 1.2.8 1.2.9 1.2.10 1.2.1 描述 分别定义int,short类型的变量各一个,并依次输出 ...
- NOI2019 Day2游记
开场T1是个最短路优化建图,边向二维矩形内所有点连,本来可以写树套树的,但是卡空间(128MB),后来发现其实是不用把边都建出来的,只需要用数据结构模拟dijkstra的过程,支持二维区间对一个值取m ...
- Android编程权威指南笔记3:Android Fragment讲解与Android Studio中的依赖关系,如何添加依赖关系
Android Fragment 当我在学习时,了解了Fragment词汇 Fragment是一种控制器对象,我就把所了解的简单说一下.activity可以派fragment完成一些任务,就是管理用户 ...
- Java动态调用脚本语言Groovy
Java动态调用脚本语言Groovy 2019-05-15 目录 0. pom.xml添加依赖1. 使用GroovyShell计算表达式2. 使用GroovyScriptEngine脚本引擎加载Gro ...