Java常见集合的默认大小及扩容机制
在面试后台开发的过程中,集合是面试的热话题,不仅要知道各集合的区别用法,还要知道集合的扩容机制,今天我们就来谈下ArrayList 和 HashMap的默认大小以及扩容机制。
在 Java 7 中,查看源码可以知道:ArrayList 的默认大小是 10 个元素,HashMap 的默认大小是16个元素(必须是2的幂,为什么呢???下文有解释)。这就是 Java 7 中 ArrayList 和 HashMap 类 的代码片段:
// from ArrayList.java JDK 1.7
private static final int DEFAULT_CAPACITY = 10; //from HashMap.java JDK 7
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
这里要讨论这些常用的默认初始容量和扩容的原因是:
当底层实现涉及到扩容时,容器或重新分配一段更大的连续内存(如果是离散分配则不需要重新分配,离散分配都是插入新元素时动态分配内存),要将容器原来的数据全部复制到新的内存上,
这无疑使效率大大降低。加载因子的系数小于等于1,意指即当元素个数超过容量长度*加载因子的系数时,进行扩容。另外,扩容也是有默认的倍数的,不同的容器扩容情况不同。
List 元素是有序的、可重复
ArrayList、Vector默认初始容量为10
Vector:线程安全,但速度慢
底层数据结构是数组结构
加载因子为1:即当 元素个数 超过 容量长度 时,进行扩容
扩容增量:原容量的 1倍
如 Vector的容量为10,一次扩容后是容量为20
ArrayList:线程不安全,查询速度快
底层数据结构是数组结构
扩容增量:原容量的 0.5倍+1
如 ArrayList的容量为10,一次扩容后是容量为16
Set(集) 元素无序的、不可重复。
HashSet:线程不安全,存取速度快
底层实现是一个HashMap(保存数据),实现Set接口
默认初始容量为16(为何是16,见下方对HashMap的描述)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
Map是一个双列集合
HashMap:默认初始容量为16
(为何是16:16是2^4,可以提高查询效率,另外,32=16<<1)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
接下来我们来谈谈hashMap的数组长度为什么保持2的次幂?
hashMap的数组长度一定保持2的次幂,比如16的二进制表示为 10000,那么length-1就是15,二进制为01111,同理扩容后的数组长度为32,二进制表示为100000,length-1为31,二进制表示为011111。
这样会保证低位全为1,而扩容后只有一位差异,也就是多出了最左位的1,这样在通过 h&(length-1)的时候,只要h对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致(大大减少了
之前已经散列良好的老数组的数据位置重新调换),还有,数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀。
1. static int indexFor(int h, int length) {
2. return h & (length-1);
3. }
首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&)。看上去很简单,其实比较有玄机。比如数组的长度是2的4次方,那么hashcode就会和2的4次方-1做“与”运算。很多人都有这个疑问,
为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高,我以2的4次方举例,来解释一下为什么数组大小为2的幂时hashmap访问的性能最高。
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同
一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的
值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组
长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
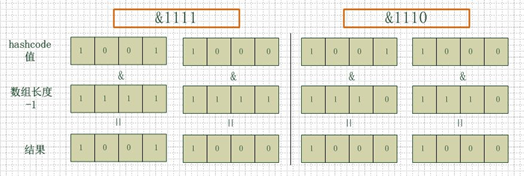
所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
说到这里,我们再回头看一下hashmap中默认的数组大小是多少,查看源代码可以得知是16,为什么是16,而不是15,也不是20呢,看到上面的解释之后我们就清楚了吧,显然是因为16是2的整数次幂的原因,
在小数据量的情况下16比15和20更能减少key之间的碰撞,而加快查询的效率。
Java常见集合的默认大小及扩容机制的更多相关文章
- java集合专题 (ArrayList、HashSet等集合底层结构及扩容机制、HashMap源码)
一.数组与集合比较 数组: 1)长度开始时必须指定,而且一旦指定,不能更改 2)保存的必须为同一类型的元素 3)使用数组进行增加/删除元素-比较麻烦 集合: 1)可以动态保存任意多个对象,使用比较方便 ...
- java常见集合
集合与数组区别 1-从长度来讲: 数组:需要固定长度. 集合:长度可以改变,可以根据保存的数据进行扩容. 2-从存储内容上: 数组:可以存储基本类型数据,还可以存储引用类型的数据(比如:String ...
- 用大白话的方式讲明白Java的StringBuilder、StringBuffer的扩容机制
StringBuffer和StringBuilder,它们的底层char数组value默认的初始化容量是16,扩容只需要修改底层的char数组,两者的扩容最终都会调用到AbstractStringBu ...
- java几种数据的默认扩容机制
当底层实现涉及到扩容时,容器或重新分配一段更大的连续内存(如果是离散分配则不需要重新分配,离散分配都是插入新元素时动态分配内存),要将容器原来的数据全部复制到新的内存上, 这无疑使效率大大降低.加载因 ...
- 浅谈JAVA中HashMap、ArrayList、StringBuilder等的扩容机制
JAVA中的部分需要扩容的内容总结如下:第一部分: HashMap<String, String> hmap=new HashMap<>(); HashSet<Strin ...
- 面试题: Java中各个集合类的扩容机制
个人博客网:https://wushaopei.github.io/ (你想要这里多有) Java 中提供了很多的集合类,包括,collection的子接口list.set,以及map等.由于它 ...
- Java ArrayList源码分析(含扩容机制等重点问题分析)
写在最前面 这个项目是从20年末就立好的 flag,经过几年的学习,回过头再去看很多知识点又有新的理解.所以趁着找实习的准备,结合以前的学习储备,创建一个主要针对应届生和初学者的 Java 开源知识项 ...
- HashMap的扩容机制以及默认大小为何是2次幂
HashMap的Put方法 回顾HashMap的put(Key k, Value v)过程: (1)对 Key求Hash值,对n-1取模计算出Hash表数组下标 (2)如果没有碰撞,直接放入桶中,即H ...
- Java ArrayList自动扩容机制
动态扩容 1.add(E e)方法中 ① ensureCapacityInternal(size+1),确保内部容量,size是添加前数组内元素的数量 ② elementData[size++] ...
随机推荐
- Windows下载安装RabbitMQ教程
原文链接:http://www.studyshare.cn/software/details/1171/0一.下载 1.下载Erlang 官网下载:去下载 百度网盘下载:去下载 提取码:m1q0 2 ...
- windows环境:dos 通过ftp连接到vsftpd 显示乱码解决方法
转载至:https://blog.csdn.net/nydia_xiangxiang/article/details/48627921?utm_source=blogxgwz8 感谢原作者的分享 FT ...
- loj#10078. 新年好(最短路)
题目: loj#10078. 新年好 解析: 亲戚只有五个,可以把它们看成2,3,4,5,6号点,分别跑最短路,记录一下距离,然后DFS一下 这题非常玄学,我开了一个\(12*12\)的数组,没有离散 ...
- JavaScript 之 页面加载事件
一.onload 加载事件 onload 是 window 对象的一个事件,也可以省略 window 直接使用. 常用方式: <head><script> windown.on ...
- 面试题:android的安全机制有哪些
1 uid . gid . gids Android 的权限分离的基础是建立在 Linux 已有的 uid . gid . gids 基础上的 . UID: Android 在 安装一个应用程序,就会 ...
- XenCenter安装VM
XenServer是服务器"虚拟化系统".系统设置为Linux_x86-64即可安装XenServer 和VMware ESX/ESXi有点不同的是,XenServer 不能在Xe ...
- 关于logback日志级别的配置
logback如果需要灵活的配置日志级别,需要结合过滤器,<filter></fiter>这个标签.需要注意的是,过滤器过滤的基础是在root标签的配置基础上进行的. 过滤器可 ...
- Linux more与less命令
1.命令简介 more (more) 该命令一次显示一屏文本,满屏后停下来,并且在屏幕的底部出现一个提示信息,给出至今己显示的该文件的百分比,方便逐页阅读(file perusal filter fo ...
- 海思3519A 开发环境设置相关
设置板卡和虚拟机的网络参数 setenv serverip 192.168.1.107 setenv ipaddr 192.168.1.10 setenv gatewayip 192.168.1.1 ...
- docker(ubuntu)中安装cron运行crontab定时任务
1.安装cron apt-get install cron 设置crontab定时任务 crontab -e */ * * * * /usr/bin/python /python/asch-check ...