2.Netty 与 NIO 之前世今生
2.Netty 与 NIO 之前世今生
本文围绕一下几点阐述:
2.1 Java NIO 三件套
2.1.1 缓冲区 Buffer
1.Buffer 操作基本 API

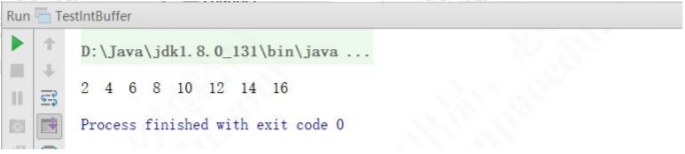
package com.gupaoedu.vip.netty.io.nio.buffer;
import java.nio.IntBuffer;
public class IntBufferDemo {
public static void main(String[] args) {
// 分配新的 int 缓冲区,参数为缓冲区容量
// 新缓冲区的当前位置将为零,其界限(限制位置)将为其容量。它将具有一个底层实现数组,其数组偏移量将为零。
IntBuffer buffer = IntBuffer.allocate(8);
for (int i = 0; i < buffer.capacity(); ++i) {
int j = 2 * (i + 1);
// 将给定整数写入此缓冲区的当前位置,当前位置递增
buffer.put(j);
}
// 重设此缓冲区,将限制设置为当前位置,然后将当前位置设置为 0
buffer.flip();
// 查看在当前位置和限制位置之间是否有元素
while (buffer.hasRemaining()) {
// 读取此缓冲区当前位置的整数,然后当前位置递增
int j = buffer.get();
System.out.print(j + " ");
}
}
}
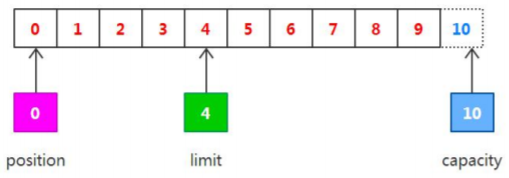
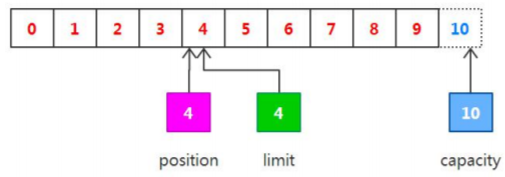
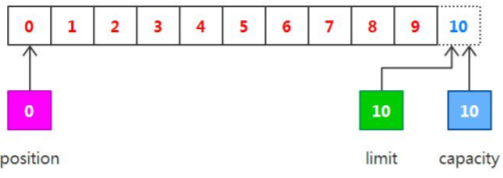
2.Buffer 的基本的原理
hel.
package com.gupaoedu.vip.netty.io.nio.buffer;
import java.io.FileInputStream;
import java.nio.*;
import java.nio.channels.*;
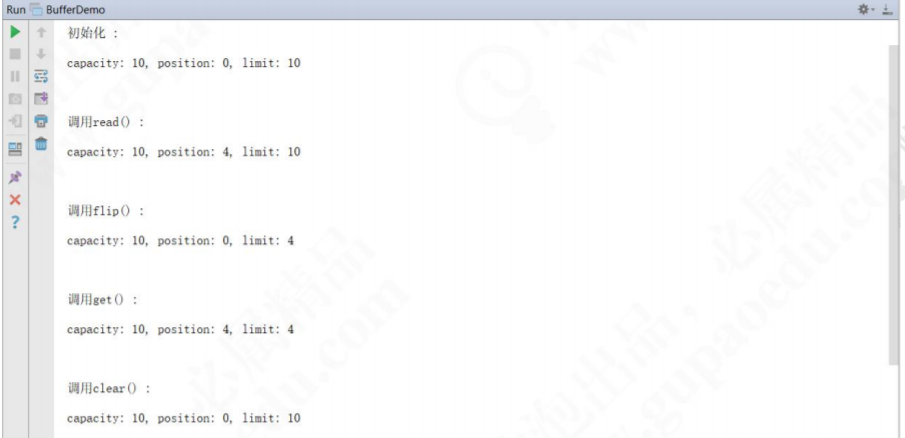
public class BufferDemo {
public static void main(String args[]) throws Exception {
//这用用的是文件 IO 处理
FileInputStream fin = new FileInputStream("E://test.txt");
//创建文件的操作管道
FileChannel fc = fin.getChannel();
//分配一个 10 个大小缓冲区,说白了就是分配一个 10 个大小的 byte 数组
ByteBuffer buffer = ByteBuffer.allocate(10);
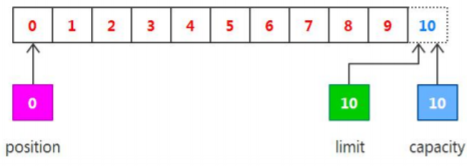
output("初始化", buffer);
//先读一下
fc.read(buffer);
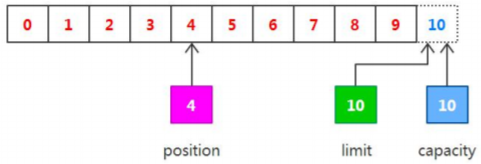
output("调用 read()", buffer);
//准备操作之前,先锁定操作范围
buffer.flip();
output("调用 flip()", buffer);
//判断有没有可读数据
while (buffer.remaining() > 0) {
byte b = buffer.get();
// System.out.print(((char)b));
}
output("调用 get()", buffer);
//可以理解为解锁
buffer.clear();
output("调用 clear()", buffer);
//最后把管道关闭
fin.close();
}
//把这个缓冲里面实时状态给答应出来
public static void output(String step, Buffer buffer) {
System.out.println(step + " : ");
//容量,数组大小
System.out.print("capacity: " + buffer.capacity() + ", ");
//当前操作数据所在的位置,也可以叫做游标
System.out.print("position: " + buffer.position() + ", ");
//锁定值,flip,数据操作范围索引只能在 position - limit 之间
System.out.println("limit: " + buffer.limit());
System.out.println();
}
}
3.缓冲区的分配
package com.gupaoedu.vip.netty.io.nio.buffer;
import java.nio.ByteBuffer;
/** 手动分配缓冲区 */
public class BufferWrap {
public void myMethod() {
// 分配指定大小的缓冲区
ByteBuffer buffer1 = ByteBuffer.allocate(10);
// 包装一个现有的数组
byte array[] = new byte[10];
ByteBuffer buffer2 = ByteBuffer.wrap( array );
}
}
4.缓冲区分片
package com.gupaoedu.vip.netty.io.nio.buffer;
import java.nio.ByteBuffer;
/**
* 缓冲区分片
*/
public class BufferSlice {
static public void main( String args[] ) throws Exception {
ByteBuffer buffer = ByteBuffer.allocate( 10 );
// 缓冲区中的数据 0-9
for (int i=0; i<buffer.capacity(); ++i) {
buffer.put( (byte)i );
}
// 创建子缓冲区
buffer.position( 3 );
buffer.limit( 7 );
ByteBuffer slice = buffer.slice();
// 改变子缓冲区的内容
for (int i=0; i<slice.capacity(); ++i) {
byte b = slice.get( i );
b *= 10;
slice.put( i, b );
}
buffer.position( 0 );
buffer.limit( buffer.capacity() );
while (buffer.remaining()>0) {
System.out.println( buffer.get() );
}
}
}

5.只读缓冲区
package com.gupaoedu.vip.netty.io.nio.buffer;
import java.nio.*;
/** 只读缓冲区 */
public class ReadOnlyBuffer {
static public void main( String args[] ) throws Exception {
ByteBuffer buffer = ByteBuffer.allocate( 10 );
// 缓冲区中的数据 0-9
for (int i=0; i<buffer.capacity(); ++i) {
buffer.put( (byte)i );
}
// 创建只读缓冲区
ByteBuffer readonly = buffer.asReadOnlyBuffer();
// 改变原缓冲区的内容
for (int i=0; i<buffer.capacity(); ++i) {
byte b = buffer.get( i );
b *= 10;
buffer.put( i, b );
}
readonly.position(0);
readonly.limit(buffer.capacity());
// 只读缓冲区的内容也随之改变
while (readonly.remaining()>0) {
System.out.println( readonly.get());
}
}
}
6.直接缓冲区
package com.gupaoedu.vip.netty.io.nio.buffer;
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
/**
* 直接缓冲区
*/
public class DirectBuffer {
static public void main( String args[] ) throws Exception {
//首先我们从磁盘上读取刚才我们写出的文件内容
String infile = "E://test.txt";
FileInputStream fin = new FileInputStream( infile );
FileChannel fcin = fin.getChannel();
//把刚刚读取的内容写入到一个新的文件中
String outfile = String.format("E://testcopy.txt");
FileOutputStream fout = new FileOutputStream( outfile );
FileChannel fcout = fout.getChannel();
// 使用 allocateDirect,而不是 allocate
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
buffer.clear();
int r = fcin.read(buffer);
if (r==-1) {
break;
}
buffer.flip();
fcout.write(buffer);
}
}
}
7.内存映射
package com.gupaoedu.vip.netty.io.nio.buffer;
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
/**
* IO 映射缓冲区
*/
public class MappedBuffer {
static private final int start = 0;
static private final int size = 1024;
static public void main( String args[] ) throws Exception {
RandomAccessFile raf = new RandomAccessFile( "E://test.txt", "rw" );
FileChannel fc = raf.getChannel();
//把缓冲区跟文件系统进行一个映射关联
//只要操作缓冲区里面的内容,文件内容也会跟着改变
MappedByteBuffer mbb = fc.map( FileChannel.MapMode.READ_WRITE,start, size );
mbb.put( 0, (byte)97 );
mbb.put( 1023, (byte)122 );
raf.close();
}
}
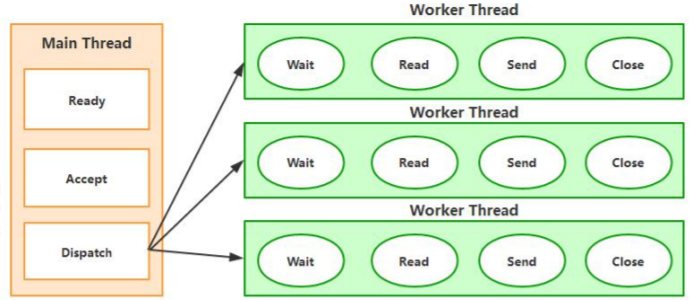
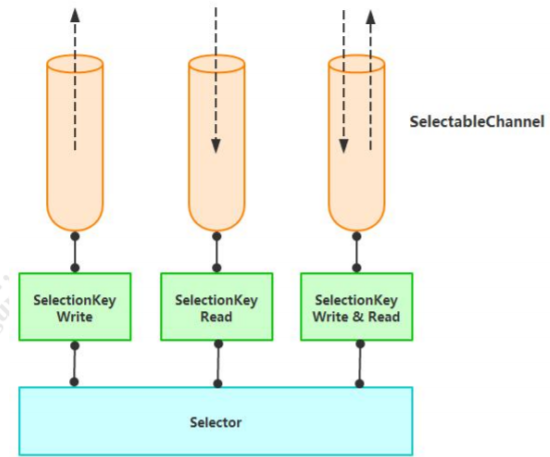
2.1.2 选择器 Selector
/*
* 注册事件
*/
private Selector getSelector() throws IOException {
// 创建 Selector 对象
Selector sel = Selector.open();
// 创建可选择通道,并配置为非阻塞模式
ServerSocketChannel server = ServerSocketChannel.open();
server.configureBlocking(false);
// 绑定通道到指定端口
ServerSocket socket = server.socket();
InetSocketAddress address = new InetSocketAddress(port);
socket.bind(address);
// 向 Selector 中注册感兴趣的事件
server.register(sel, SelectionKey.OP_ACCEPT);
return sel;
}
/*
* 开始监听
*/
public void listen() {
System.out.println("listen on " + port);
try {
while(true) {
// 该调用会阻塞,直到至少有一个事件发生
selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = (SelectionKey) iter.next();
iter.remove();
process(key);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
/*
* 根据不同的事件做处理
*/
private void process(SelectionKey key) throws IOException{
// 接收请求
if (key.isAcceptable()) {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel channel = server.accept();
channel.configureBlocking(false);
channel.register(selector, SelectionKey.OP_READ);
}
// 读信息
else if (key.isReadable()) {
SocketChannel channel = (SocketChannel) key.channel();
int len = channel.read(buffer);
if (len > 0) {
buffer.flip();
content = new String(buffer.array(),0,len);
SelectionKey sKey = channel.register(selector, SelectionKey.OP_WRITE);
sKey.attach(content);
} else {
channel.close();
}
buffer.clear();
}
// 写事件
else if (key.isWritable()) {
SocketChannel channel = (SocketChannel) key.channel();
String content = (String) key.attachment();
ByteBuffer block = ByteBuffer.wrap(("输出内容:" + content).getBytes());
if(block != null){
channel.write(block);
}else{
channel.close();
}
}
}
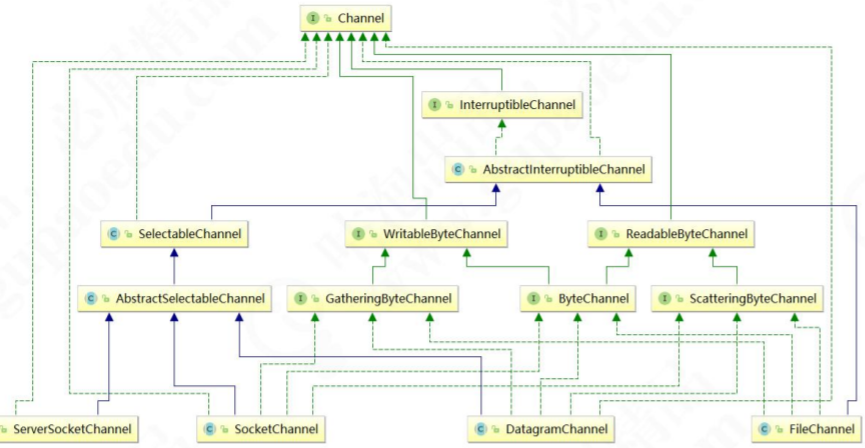
2.3.3 通道 Channel
package com.gupaoedu.vip.netty.io.nio.channel;
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
public class FileInputDemo {
static public void main( String args[] ) throws Exception {
FileInputStream fin = new FileInputStream("E://test.txt");
// 获取通道
FileChannel fc = fin.getChannel();
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 读取数据到缓冲区
fc.read(buffer);
buffer.flip();
while (buffer.remaining() > 0) {
byte b = buffer.get();
System.out.print(((char)b));
}
fin.close();
}
}
package com.gupaoedu.vip.netty.io.nio.channel;
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
public class FileOutputDemo {
static private final byte message[] = { 83, 111, 109, 101, 32,98, 121, 116, 101, 115, 46 };
static public void main( String args[] ) throws Exception {
FileOutputStream fout = new FileOutputStream( "E://test.txt" );
FileChannel fc = fout.getChannel();
ByteBuffer buffer = ByteBuffer.allocate( 1024 );
for (int i=0; i<message.length; ++i) {
buffer.put( message[i] );
}
buffer.flip();
fc.write( buffer );
fout.close();
}
}
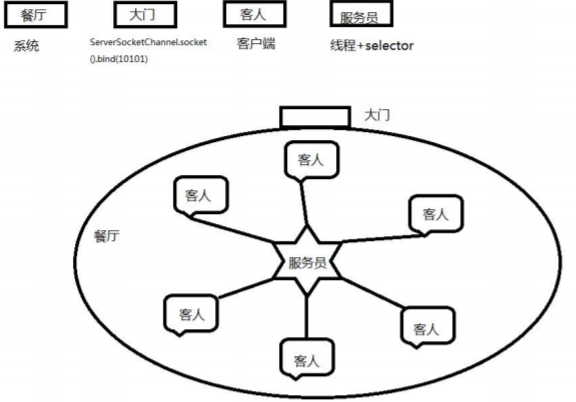
3.IO 多路复用
| IO模型 | 相对性能 | 关键思路 | 操作系统 | JAVA支持 |
| select | 较高 | Reactor | windows/Linux |
支持,Reactor 模式(反应器设计模式)。Linux 操作
系统的 kernels 2.4 内核版本之前,默认使用
select;而目前 windows 下对同步 IO 的支持,都
是 select 模型
|
| poll | 较高 | Reactor | Linux |
Linux 下的 JAVA NIO 框架,Linux kernels 2.6 内
核版本之前使用 poll 进行支持。也是使用的
Reactor 模式。
|
| epoll | 高 | Reactor/Proactor | Linux |
Linux kernels 2.6 内核版本及以后使用 epoll 进行
支持;Linux kernels 2.6 内核版本之前使用 poll
进行支持;另外一定注意,由于 Linux 下没有
Windows 下的 IOCP 技术提供真正的 异步 IO 支
持,所以 Linux 下使用 epoll 模拟异步 IO。
|
| kqueue | 高 | Proactor | Linux | 目前 JAVA 的版本不支持。 |
2.4 NIO 源码初探
public static Selector open() throws IOException {
return SelectorProvider.provider().openSelector();
}
public static SelectorProvider provider() {
synchronized (lock) {
if (provider != null)
return provider;
return AccessController.doPrivileged(
new PrivilegedAction<SelectorProvider>() {
public SelectorProvider run() {
if (loadProviderFromProperty())
return provider;
if (loadProviderAsService())
return provider;
provider = sun.nio.ch.DefaultSelectorProvider.create();
return provider;
}
});
}
}
public AbstractSelector openSelector() throws IOException {
return new WindowsSelectorImpl(this);
}
WindowsSelectorImpl(SelectorProvider sp) throws IOException {
super(sp);
pollWrapper = new PollArrayWrapper(INIT_CAP);
wakeupPipe = Pipe.open();
wakeupSourceFd = ((SelChImpl)wakeupPipe.source()).getFDVal();
// Disable the Nagle algorithm so that the wakeup is more immediate
SinkChannelImpl sink = (SinkChannelImpl)wakeupPipe.sink();
(sink.sc).socket().setTcpNoDelay(true);
wakeupSinkFd = ((SelChImpl)sink).getFDVal();
pollWrapper.addWakeupSocket(wakeupSourceFd, 0);
}
public static Pipe open() throws IOException {
return SelectorProvider.provider().openPipe();
}
public Pipe openPipe() throws IOException {
return new PipeImpl(this);
}
PipeImpl(SelectorProvider sp) {
long pipeFds = IOUtil.makePipe(true);
int readFd = (int) (pipeFds >>> 32);
int writeFd = (int) pipeFds;
FileDescriptor sourcefd = new FileDescriptor();
IOUtil.setfdVal(sourcefd, readFd);
source = new SourceChannelImpl(sp, sourcefd);
FileDescriptor sinkfd = new FileDescriptor();
IOUtil.setfdVal(sinkfd, writeFd);
sink = new SinkChannelImpl(sp, sinkfd);
}
/**
* Returns two file descriptors for a pipe encoded in a long.
* The read end of the pipe is returned in the high 32 bits,
* while the write end is returned in the low 32 bits.
*/
static native long makePipe(boolean blocking);
JNIEXPORT jlong JNICALL
Java_sun_nio_ch_IOUtil_makePipe(JNIEnv *env, jobject this, jboolean blocking)
{
int fd[];
if (pipe(fd) < ) {
JNU_ThrowIOExceptionWithLastError(env, "Pipe failed");
return ;
}
if (blocking == JNI_FALSE) {
if ((configureBlocking(fd[], JNI_FALSE) < )
|| (configureBlocking(fd[], JNI_FALSE) < )) {
JNU_ThrowIOExceptionWithLastError(env, "Configure blocking failed");
close(fd[]);
close(fd[]);
return ;
}
}
return ((jlong) fd[] << ) | (jlong) fd[];
}
static int
configureBlocking(int fd, jboolean blocking)
{
int flags = fcntl(fd, F_GETFL);
int newflags = blocking ? (flags & ~O_NONBLOCK) : (flags | O_NONBLOCK);
return (flags == newflags) ? : fcntl(fd, F_SETFL, newflags);
}
/**
* Returns two file descriptors for a pipe encoded in a long.
* The read end of the pipe is returned in the high 32 bits,
* while the write end is returned in the low 32 bits.
*/
pollWrapper.addWakeupSocket(wakeupSourceFd, 0);
public static ServerSocketChannel open() throws IOException {
return SelectorProvider.provider().openServerSocketChannel();
}
public ServerSocketChannel openServerSocketChannel() throws IOException {
return new ServerSocketChannelImpl(this);
}
public ServerSocketChannelImpl(SelectorProvider sp) throws IOException {
super(sp);
this.fd = Net.serverSocket(true);
this.fdVal = IOUtil.fdVal(fd);
this.state = ST_INUSE;
}
protected int doSelect(long timeout) throws IOException {
if (channelArray == null)
throw new ClosedSelectorException();
this.timeout = timeout; // set selector timeout
processDeregisterQueue();
if (interruptTriggered) {
resetWakeupSocket();
return 0;
}
// Calculate number of helper threads needed for poll. If necessary
// threads are created here and start waiting on startLock
adjustThreadsCount();
finishLock.reset(); // reset finishLock
// Wakeup helper threads, waiting on startLock, so they start polling.
// Redundant threads will exit here after wakeup.
startLock.startThreads();
// do polling in the main thread. Main thread is responsible for
// first MAX_SELECTABLE_FDS entries in pollArray.
try {
begin();
try {
subSelector.poll();
} catch (IOException e) {
finishLock.setException(e); // Save this exception
}
// Main thread is out of poll(). Wakeup others and wait for them
if (threads.size() > 0)
finishLock.waitForHelperThreads();
} finally {
end();
}
// Done with poll(). Set wakeupSocket to nonsignaled for the next run.
finishLock.checkForException();
processDeregisterQueue();
int updated = updateSelectedKeys();
// Done with poll(). Set wakeupSocket to nonsignaled for the next run.
resetWakeupSocket();
return updated;
}
private int poll() throws IOException{ // poll for the main thread
return poll0(pollWrapper.pollArrayAddress,
Math.min(totalChannels, MAX_SELECTABLE_FDS),
readFds, writeFds, exceptFds, timeout);
}
private native int poll0(long pollAddress, int numfds,
int[] readFds, int[] writeFds, int[] exceptFds, long timeout);
// These arrays will hold result of native select().
// The first element of each array is the number of selected sockets.
// Other elements are file descriptors of selected sockets.
private final int[] readFds = new int [MAX_SELECTABLE_FDS + 1];//保存发生 read 的 FD
private final int[] writeFds = new int [MAX_SELECTABLE_FDS + 1]; //保存发生 write 的 FD
private final int[] exceptFds = new int [MAX_SELECTABLE_FDS + 1]; //保存发生 except 的 FD
public Selector wakeup() {
synchronized (interruptLock) {
if (!interruptTriggered) {
setWakeupSocket();
interruptTriggered = true;
}
}
return this;
}
// Sets Windows wakeup socket to a signaled state.
private void setWakeupSocket() {
setWakeupSocket0(wakeupSinkFd);
}
private native void setWakeupSocket0(int wakeupSinkFd);
JNIEXPORT void JNICALL
Java_sun_nio_ch_WindowsSelectorImpl_setWakeupSocket0(JNIEnv *env, jclass this,jint scoutFd)
{
/* Write one byte into the pipe */
const char byte = 1;
send(scoutFd, &byte, 1, 0);
}
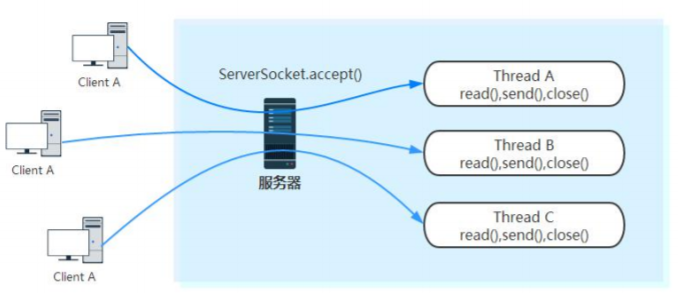
2.5 反应堆 Reactor
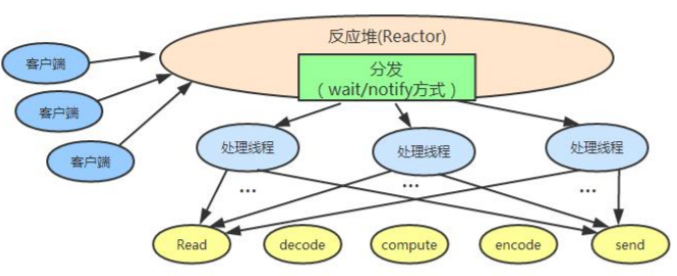
2.6 Netty 与 NIO
2.6.1 Netty 支持的功能与特性
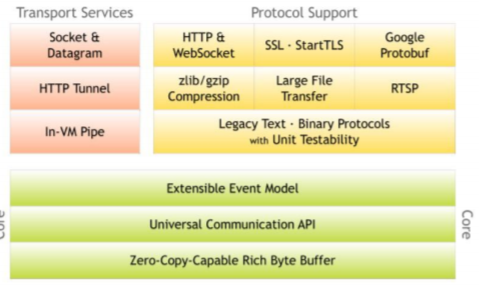
2.6.2 Netty 采用 NIO 而非 AIO 的理由
2.Netty 与 NIO 之前世今生的更多相关文章
- Netty(二)Netty 与 NIO 之前世今生
2.1 Java NIO 三件套 在 NIO 中有几个核心对象需要掌握:缓冲区(Buffer).选择器(Selector).通道(Channel). 2.1.1 缓冲区 Buffer 1.Buffer ...
- android netty5.0 编译时 java.lang.NoClassDefFoundError: io.netty.channel.nio.NioEventLoopGroup
android netty5.0 编译时 java.lang.NoClassDefFoundError: io.netty.channel.nio.NioEventLoopGroup 复制netty包 ...
- 漫谈Java IO之 Netty与NIO服务器
前面介绍了基本的网络模型以及IO与NIO,那么有了NIO来开发非阻塞服务器,大家就满足了吗?有了技术支持,就回去追求效率,因此就产生了很多NIO的框架对NIO进行封装--这就是大名鼎鼎的Netty. ...
- Netty、NIO、多线程
一:Netty.NIO.多线程? 时隔很久终于又更新了!之前一直迟迟未动也是因为积累不够,后面比较难下手.过年期间@李林锋hw发布了一个Netty5.0架构剖析和源码解读,看完也是收获不少.前面的文章 ...
- [netty4][netty-transport]netty之nio传输层
[netty4][netty-transport]netty之nio传输层 nio基本处理逻辑 查看这里 Selector的处理 Selector实例构建 NioEventLoop.openSelec ...
- netty简单NIO模型
首先是使用java原生nio类库编写的例子,开发一套nio框架不简单,所以选择了netty,该例完成后,是netty举例. package com.smkj.netty; public class T ...
- 【Netty】NIO框架Netty入门
Netty介绍 Netty是由JBOSS提供的一个java开源框架.Netty提供异步的.事件驱动的网络应用程序框架和工具,用以快速开发高性能.高可靠性的网络服务器和客户端程序. 也就是说,Netty ...
- Netty与NIO
初识Netty Netty是由JBoss提供的一个Java的开源框架,是GitHub上的独立项目. Netty是一个异步的,基于事件驱动的网络应用框架,用于快速开发高性能.高可靠的网络IO程序. Ne ...
- 基于Netty的NIO优化实践
1. 浅谈React模型 2. Netty TCP 3. Netty UTP
随机推荐
- Node.js是什么?提供了哪些内容?
什么是Node.js? Node.js是基于Chrome V8 引擎的 JavaScript运行时(运行环境). Node.js提供了哪些内容? Node.js运行时,JavaScript代码运行时的 ...
- K-Nearest Neighbors Algorithm
K近邻算法. KNN算法非常简单,非常有效.KNN算法适合样本较少典型性较好的样本集. KNN的模型表示是整个训练数据集.也可以说是:KNN的特点是完全跟着数据走,没有数学模型可言. 对一个新的数据点 ...
- S1_搭建分布式OpenStack集群_09 cinder 控制节点配置
一.创建数据库创建数据库以及用户:# mysql -uroot -p12345678MariaDB [(none)]> CREATE DATABASE cinder;MariaDB [(none ...
- JavaScript的入门篇
快速认识JavaScript 熟悉JavaScript基本语法 窗口交互方法 通过DOM进行网页元素的操作 学会如何编写JS代码 运用JavaScript去操作HTML元素和CSS样式 <!DO ...
- 第12组 Beta冲刺(2/5)
Header 队名:To Be Done 组长博客 作业博客 团队项目进行情况 燃尽图(组内共享) 由于这两天在修严重Bug,故项目没有新的进展,燃尽图没有变化 展示Git当日代码/文档签入记录(组内 ...
- shell 杀死80端口的所有进程
netstat -lnp|grep |grep -v grep |awk
- ELK:使用docker搭建elk平台
1.安装ElasticSearch 1.docker pull elasticsearch //拉取镜像 2.find /var/lib/docker/overlay2/ -name jvm.opti ...
- Http项目转Https项目
Https证书准备 开发环境下,可直接用JDK自带的keytool工具生成一个证书,正式环境可购买一个,配置过程是一样的: 打开cmd命令行,输入以下命令: 命令解释: -alias 证书别名 -ke ...
- Nginx简单配置几个基于端口的虚拟主机
nginx.conf中,一个server段对应一个虚拟主机,如果要增加多个虚拟主机,增加多个server段即可. server { listen ; access_log logs/.log; loc ...
- python开发笔记-字典按值排序取前n个key值
场景举例: 假如我们有某个班级的语文成绩数据,格式为字典,其中字典key为学生姓名,value为学生成绩: 那么,如何获得单科成绩排名前3的学生姓名? 代码如下:--数据样例,方便测试 def dic ...