zzTensorflow技术内幕:
性能优势
TensorFlow在大规模分布式系统上的并行效率相当高,如下图所示:
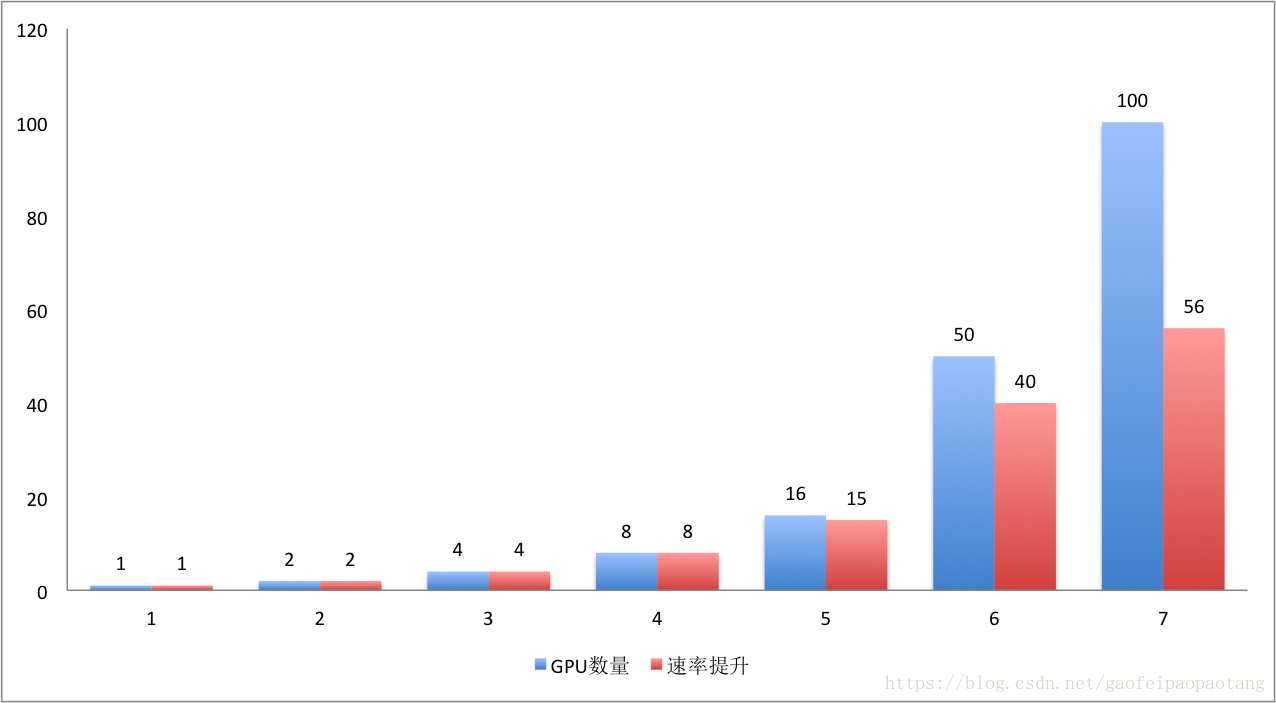
图5:TensorFlow并发效率
在GPU数量小于16时,基本没有性能损耗,在50块的时候,可以获得80%的效率,也就是40倍 的单GPU提速。100块的时候,获得56块的提速。
为了达到这种高效并发性能,tensorflow做了很多优化,包括单不限于以下几点:
子图消重: 在Tensorflow中有很多高层的运算操作,这些运算操作可能是有很多复杂的底层计算组合而成的,当有很多个高层运算存在时,它们的前几层的运算可能是重复计算的(输入何运算内容都一样)。tf会自动识别出这些重复的计算,然后通过改写计算图,共享计算结果,消除重复计算量。
计算顺序优化: 通过调整节点的执行顺序,改善数据传输何内存占用问题。例如错开某些节点的计算时机,避免某些数据同时存在于内存,这对于先显存有限的GPU设备来说至关重要。
复用高效的第三方计算库: 包括线性代数计算库Eigen, 矩阵计算库BLAS,cuBLAS,深度学习计算库cuda-convnet,cuDNN
节点分配设备策略的持续优化: 持续优化节点执行设备的分配策略,未来计划用一个强化学习的网络辅助分配策略。
XLA编译优化: 通过编译优化加速Graph的计算。
多重并行计算模式: TensorFlow提供三种不同的加速神经网络训练的并行计算模式,分别是数据并行,模型并行,流水线并行:
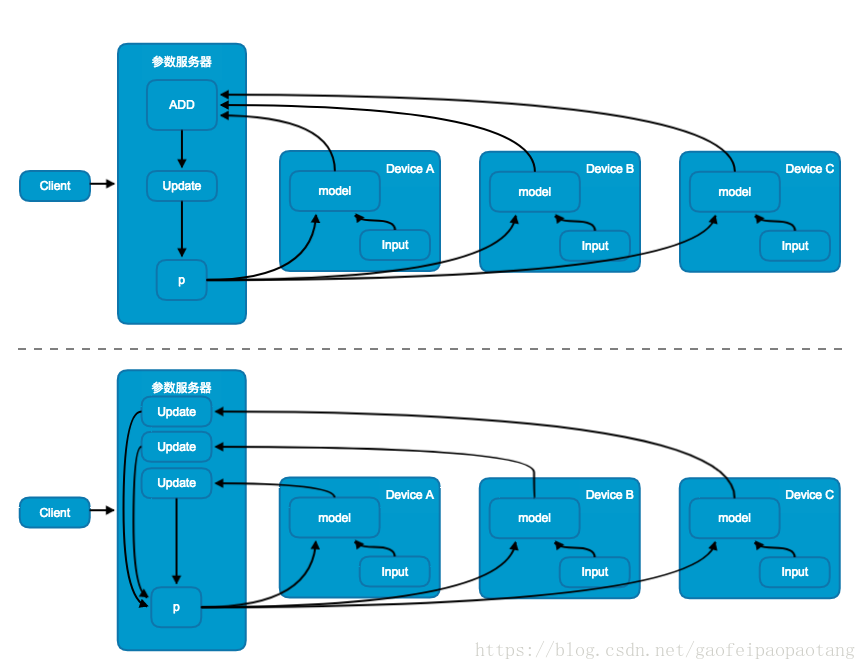
图6:数据并行模式中的同步更新模式(上)与异步模式更新(下)
数据并行模式中,模型在不同的设备上存在相同多份拷贝,共享相同的参数,采用不同的训练数据并行训练。
根据共享参数的更新方式,又分为同步更新模式与异步更新模式;同步更新模式中(图6上),参数的更新值需要进行汇总,然后更新共享参数,这就意味着,需要等待所有的设备当前训练批次训练完成后才能更新共享参数;而异步更新模式中(图6下),不用进行更新值的汇总,每台设备当前批次训练完成后分别更新共享参数,避免了等待的问题。
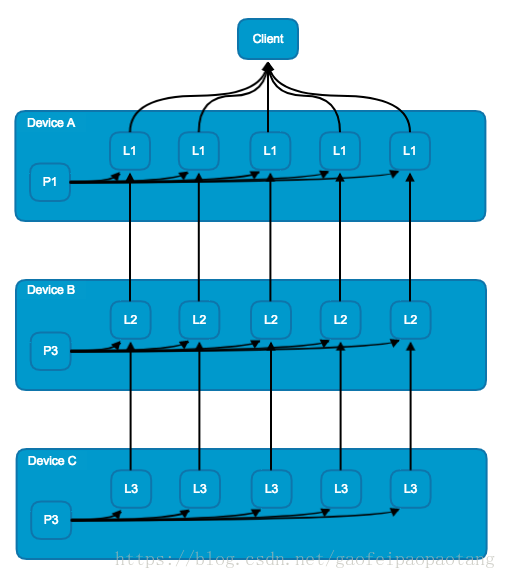
图7:模型并行模式
模型并行模式中,是将模型的不同部分别放在不同的机器上进行训练。模型并行需要模型本身有大量的可以并行的,互相不依赖的或则依赖程度不高的子图。
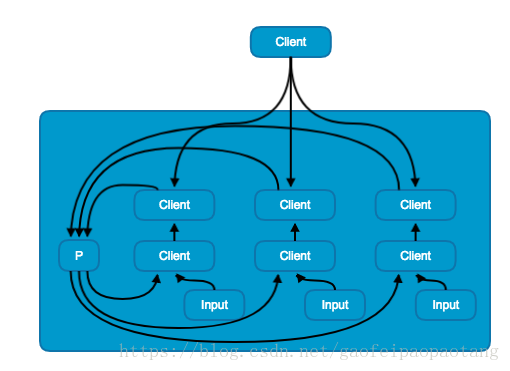
图8:流水线并行模式
流水线并行模式与数据并行模式类似,区别在于流水线并行模式是在单机上训练的。
每个目录的功能:
目录 功能
tensorflow/c C API代码
tensorflow/cc C++ API代码
tensorflow/compiler XLA,JIT等编译优化相关
tensorflow/contrib contributor贡献的代码,这个目录并不是官方支持的, 很有可能在高级 API 完善后被官方迁移到核心的 TensorFlow 目录中或去掉
tensorflow/core tf核心代码
tensorflow/docs_src 文档相关文件
tensorflow/examples 例子相关代码
tensorflow/g3doc TF文档
tensorflow/go go API相关代码
tensorflow/java java API相关代码
tensorflow/python Python API相关代码
tensorflow/stream_executor 并行计算框架代码
tensorflow/tools 各种辅助工具工程代码,例如第二章中生成Python安装包的代码就在这里
tensorflow/user_ops tf插件代码
third_party/ 依赖的第三方代码
tools 工程编译配置相关
util 工程编译相关
表1:TF根目录
其中tensorflow/core是tf的核心模块
————————————————
TF Core目录
目录功能如下:
目录 功能
tensorflow/core/common_runtime 公共运行库
tensorflow/core/debug 调试相关
tensorflow/core/distributed_runtime 分布式执行模块
tensorflow/core/example 例子代码
tensorflow/core/framework 基础功能模块
tensorflow/core/graph 计算图相关
tensorflow/core/grappler 模型优化模块
tensorflow/core/kernels 操作核心的实现代码,包括CPU和GPU上的实现
tensorflow/core/lib 公共基础库
tensorflow/core/ops 操作代码
tensorflow/core/platform 平台实现相关代码
tensorflow/core/protobuf .proto定义文件
tensorflow/core/public API头文件
tensorflow/core/user_ops
tensorflow/core/util
表2:TF Core目录
————————————————
4
本章中,我们通过工具bazel query,找到了混合编程中链接两个世界的模块pywrap_tensorflow_internal,实际上它就是Python的一个扩展,python的代码通过这个扩展就可以调用底层的C/C++代码了。然后分析此工程的过程中,引入了SWIG工具,它使得C/C++代码很方便的导出到各种其他的脚本语言。
————————————————
5
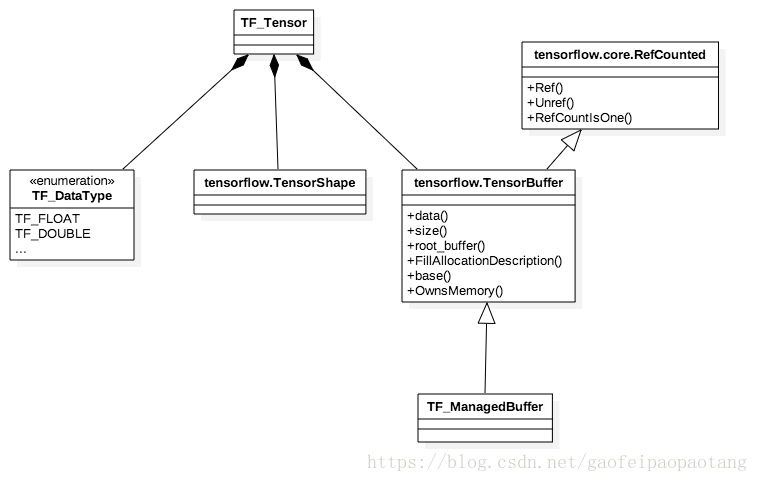
图1:TF_Tensor
图1是C API中对Tensor的封装,Tensor的纬度、数据类型、数据内容都有对应的成员表示。数据内容存放在TensorBuffer中,这个类支持引用计数,在引用数为0的时候则自动释放内存。
以上是接口层对Tensor的封装,比较简单直接,适合接口中传递参数使用,但是在tf的内核中,Tensor的封装是tensorflow.Tensor,它的设计目标之一是为了能方便的使用线性代数运算库Eigen,另外TensorBuffer的具体实现类也不一样:
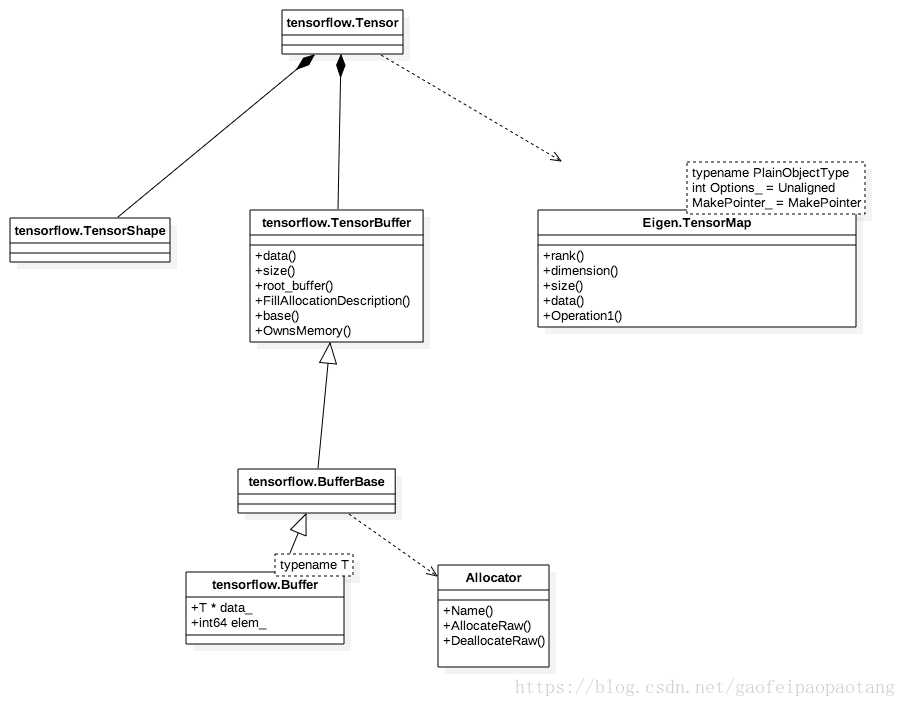
图2:
|
在 UML 模型中,模板参数是一些形参,一旦将它们与实际值(称为模板自变量)进行绑定,就会使模板成为可用的模型元素。
可以使用模板参数来创建特殊类型的模板的常规定义。例如,当对类添加模板参数时,该类就会变成模板类,有时称为参数化类。通过将模板类用作常规模式,可以创建一组使用模板参数来定义更具体行为的类。 每个模板参数都必须具有一个名称和类型。参数的名称在模板参数列表中必须是唯一的。类型是对模型元素(例如,类、接口或属性)或者基本数据类型(例如,Integer 或 String)的引用。如果您在将参数绑定至模板时不指定模板自变量,那么模板参数会采用缺省值。 当您将模型元素绑定至模板时,就对模板参数指定值(称为模板自变量)。在绑定至模板的模型元素中,模板自变量将替换模板参数。此操作将创建一个新的模型元素,该模型元素具有模板的结构并且使用它的模板自变量的值。 模板参数的语法为 name : type。 在图编辑器中,模板参数通过位于类元形状右上角的带虚线边框的一个框来表示。项目资源管理器视图将模板参数列示在定义了这些模板参数的类元下。下表说明了这两种表示法。
|
|||||


Op(运算)
TensorFlow中Op代表一个基本运算,比如矩阵或则标量的四则运算。
运算类型 运算名称
标量运算 Add,Sub,Mul,Div,Exp,Log,Greater,Less,Equal
向量运算 Concat,Slice,Split,Constant,Rank,Shape,Shuffle
矩阵运算 MatMul,MatrixInverse,MatrixDeterminant
带状态的运算 Variable,Assign,AssignAdd
神经网络组件 SoftMax,Sigmoid,ReLU,Convolution2D,MaxPooling
存储、恢复 Save,Restore
队列和同步 Enqueue,Dequeue,MutexAcquire,MutexRelease
控制流 Merge,Switch,Enter,Leave,NextIteration
————————————————
版权声明:本文为CSDN博主「jony0917」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/gaofeipaopaotang/article/details/80598840
表1:TF内建的运算操作

在tf的设计中,运算和运算实现是两个分开的概念,通过引入的运算核(OpKernel)的概念来表示运算的具体实现。这么设计的原因是,运算的语义是平台不相关的,是不变的,而运算的实现运算核是跟具体的平台(CPU、GPU、TPU)相关的。这样,就可以很方便的对语义不变的运算提供不同平台的实现了。tf中的运算核也有注册机制,为一个运算提供多平台的实现:
/* tensorflow/core/kernels/conscat_op.cc */
...
REGISTER_KERNEL_BUILDER(Name("Concat") \
.Device(DEVICE_CPU) \
.TypeConstraint<type>("T") \
.HostMemory("concat_dim"), \
ConcatOp<CPUDevice, type>)
...
REGISTER_KERNEL_BUILDER(Name("Concat")
.Device(DEVICE_GPU)
.TypeConstraint<int32>("T")
.HostMemory("concat_dim")
.HostMemory("values")
.HostMemory("output"),
ConcatOp<CPUDevice, int32>);
...以上的这段代码,就为Concat运算注册了两个运算核,分别对应DEVICE_CPU和DEVICE_GPU,运算核的实现代码就在模板类ConcatOp中。
Node的定义中,包括名称,输入来源,运算名,设备以及属性。另外,在执行Node的运算前,需要通过设备类型和运算名找到相应的运算核(OpKenel)。
背后实现:
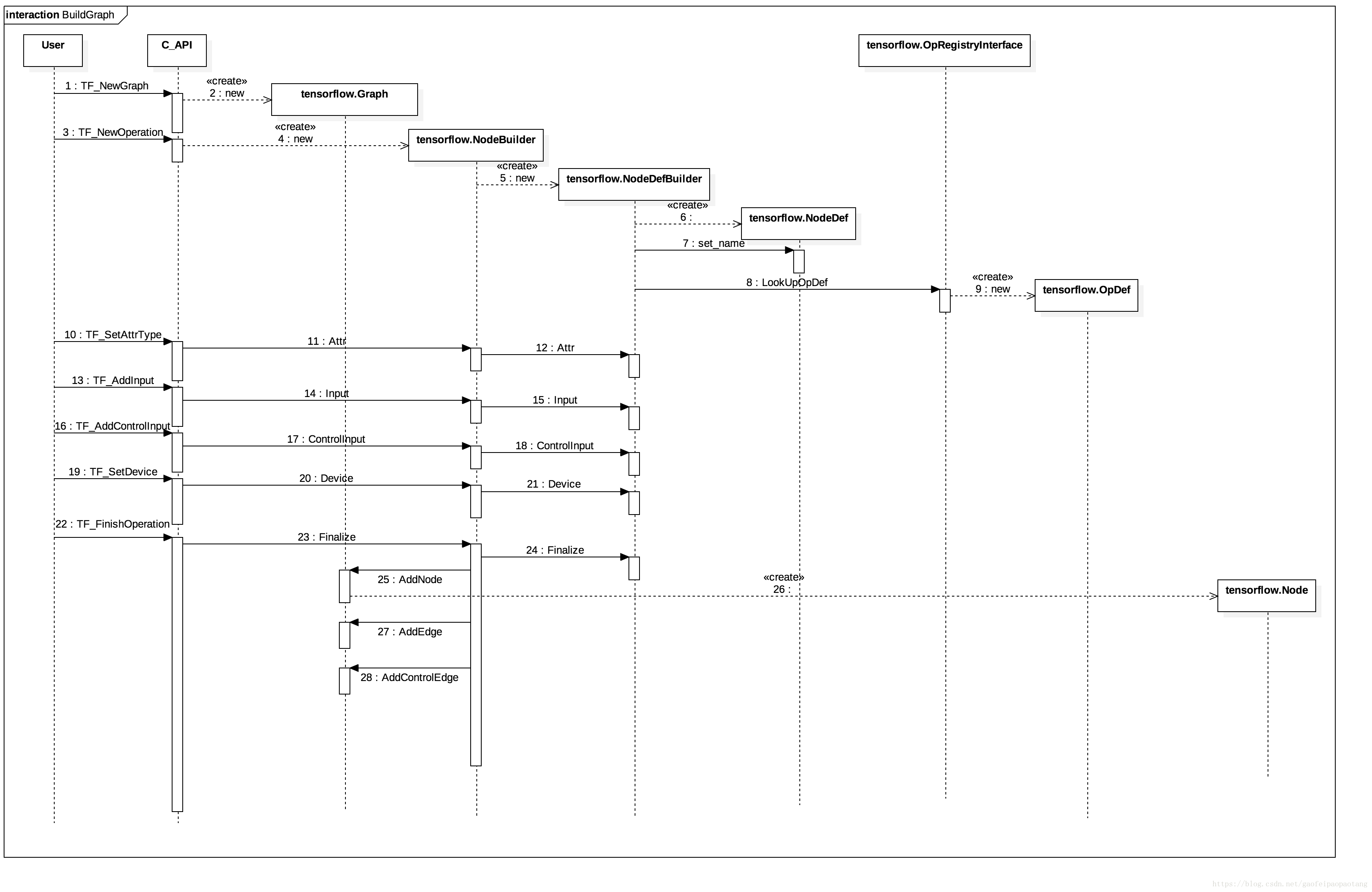
图3:计算图的构建
第一步、 TF_NewGraph会创建一个tensorflow.Graph对象,这就是计算图在TF内核中的表示;TF_NewGraph返回的结果是TF_Graph的指针,这个结构体是C API层对tensorflow.Graph的封装对象。
第二步、 TF_NewOperation创建Graph中的Node,这一步中涉及的类比较多,tensorflow.NodeBuilder,tensorflow.NodeDefBuilder是为了构建tensorflow.NodeDef的工具类;为了最终构建Node对象,还需要通过tensorflow.OpRegistryInterface来找到Node绑定的OpDef。就像前面说的,Op是通过注册来提供给tf使用的。
细心的用户发现,其实这步并没有创建Node对象,为什么呢?我们先往后看。
第三步、设置Node的输入,设备以及属性,如图1中调用10到22。
**最后,**TF_FinishOperation创建Node对象,并添加到Graph中。我们看到,实际的Node对象的创建是到这一步才发生的(调用26),并且根据节点的输入和控制输入,添加所需的数据边和流控制边。这也是为什么Node对象的创建放在最后一步的原因。
————————————————
版权声明:本文为CSDN博主「jony0917」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/gaofeipaopaotang/article/details/80598840
Session 本地执行:
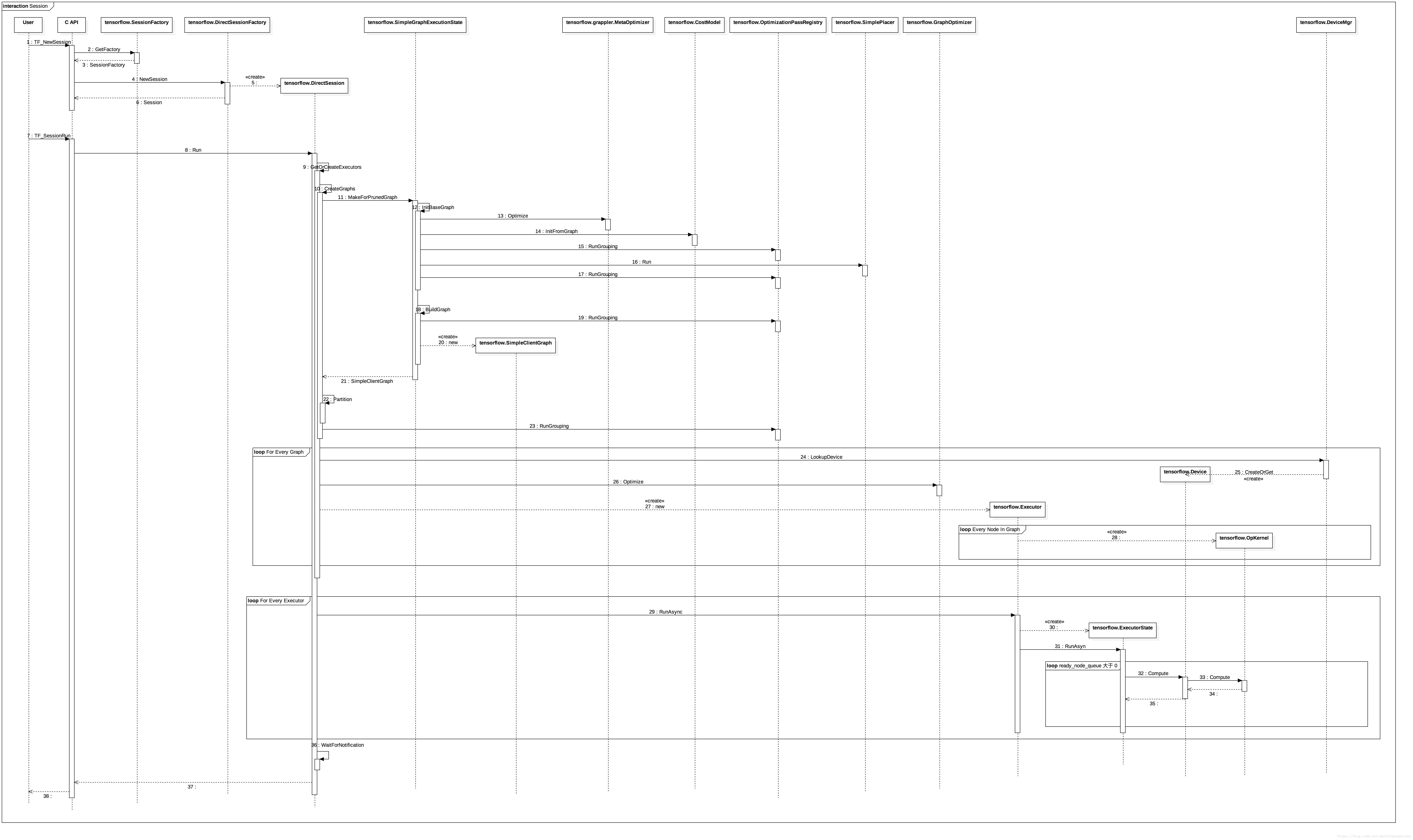
图4:本地执行
本地执行的步骤如下:
第一步、图4中的1-6,创建session对象;根据Option的设置,返回具体的session实现类,设置本地执行后,返回的session对象的实现类是tensorflow.DirectSession.
第二步、执行计算图;这个过程比较关键,tf很多的优化技术都在这里。TF_SessionRun直接调用tensorflow.DirectSession.Run,此函数大致可以分为两个阶段:准备执行阶段和执行阶段。
1,准备执行阶段逻辑主要在函数tensorflow.DirectSession.GetOrCreateExecutor内,函数首先会调用函数tensorflow.DirectSession.CreateGraphs,然后为新生成的多张计算图分别创建各自的Executor(图4中的Loop for every graph)。
那么问题来了,创建session的时候,已经关联了一个graph,为什么要重新创建?甚至,重新创建的了多张图,这是为什么?简而言之,目的是为了分配设备和优化执行效率。这里的逻辑在tensorflow.DirectSession.CreateGraphs中。创建session时候关联的graph不适合直接进行计算,需要做的准备还很多,包括设备分配,裁剪,各种优化。
设备分配相关的类是tensorflow.CostModel和tensorflow.SimplePlacer,具体调用tensorflow.SimplePlacer.Run进行设备分配(图4中的16)。这里会根据一些启发式的经验规则加上一些通过实际运算收集的数据进行设备分配。(>>> 需要具体看)
tf中的各种效率优化是分阶段多次执行的,在设备分配前、设备分配之后、计算图执行之前、计算图分区之前等,都有优化逻辑存在,涉及tensorflow.grappler.MetaOptimizer,tensorflow.OptimizationPassRegitry,tensorflow.GraphOptimizer等类,相关的类如下:(>>> 需要具体看)
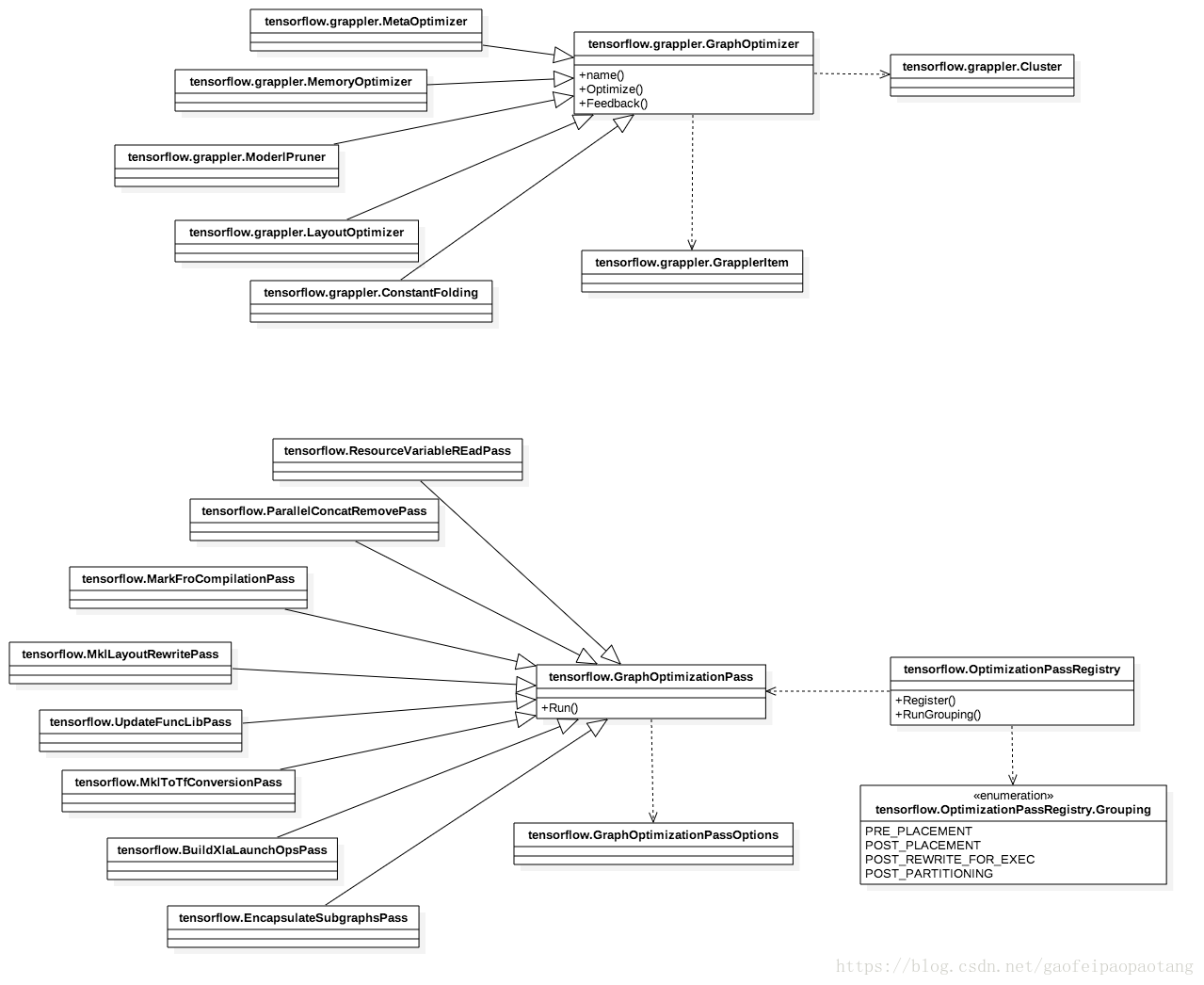
图5:tf中的优化类
优化是个比较大主题,篇幅限制,本章中暂不展开介绍了,后面章节再讨论。
回归我们的讨论,在这些处理之后,调用Parition的进行计算图的分区操作,将重建的已经分配过设备和优化过的计算图进行分区。所谓分区的主要依据就是执行设备,同一个设备上的节点在一个分区。
在准备阶段的后半部分,需要为每一个分区的计算图创建独立的Executor(图4 Loop for every graph),目的是为了提高并发效率; 这部分逻辑还负责为分区计算图创建设备对象;另外,细心的用户还会发现,分区计算图中的每个节点的运算核也是在这时候创建的(图4 loop for evey node in graph)。
到此,每个分区计算图已经准备完毕,可以执行了。
2,执行阶段,并发调用每个Executor的异步执行方法tensorflow.Executor.RunAsync方法。RunAsync将当前计算图中输入依赖为0的节点放入ready_node_queue中,每次从ready_node_queue中取下一个待执行的节点执行,并在执行完成后,将它的下游节点的输入依赖减一,如此循环,直到ready_node_queue空为止(图4 loop ready_node_queue大于0)。
这里还需要提醒一点的是,每张分区计算图的执行并非完全独立的,也会发生等待的事件,因为分区间也存在输入依赖的问题。tf中通过在分区图间引入send/recv节点的方式解决这个问题。第一章中我们已经介绍过这个设计。
最后调用WaitForNotification等待计算图执行完成,提出执行结果。

图6:服务端执行
相比本地执行,服务端执行流程看起来比较简单,这是因为我们隐去了服务端的逻辑,只画了客户端的逻辑。我会在后面单独的章节中介绍tf的分布式执行架构,这里暂不展开讨论服务端的情况。
在配置了服务端执行后,创建的session对象的具体实现类是GrpcSession,它通过一个gprc的通信类与服务端通信。
总结
本章中介绍了tf核心概念在内核中的实现,包括Tensor,Op,Node,Graph。然后介绍了session驱动计算的内核实现。
6.
TensorFlow技术内幕(六):模型优化之Grappler
本章中分析TensorFlow的Grappler模块的实现。代码位于tensorflow/core/grappler。
上一章中分析session类的时候,已经介绍过了grappler模块的调用时机。
Grappler
Grappler是TensorFlow的优化模块。模块中的主要包括这些类:
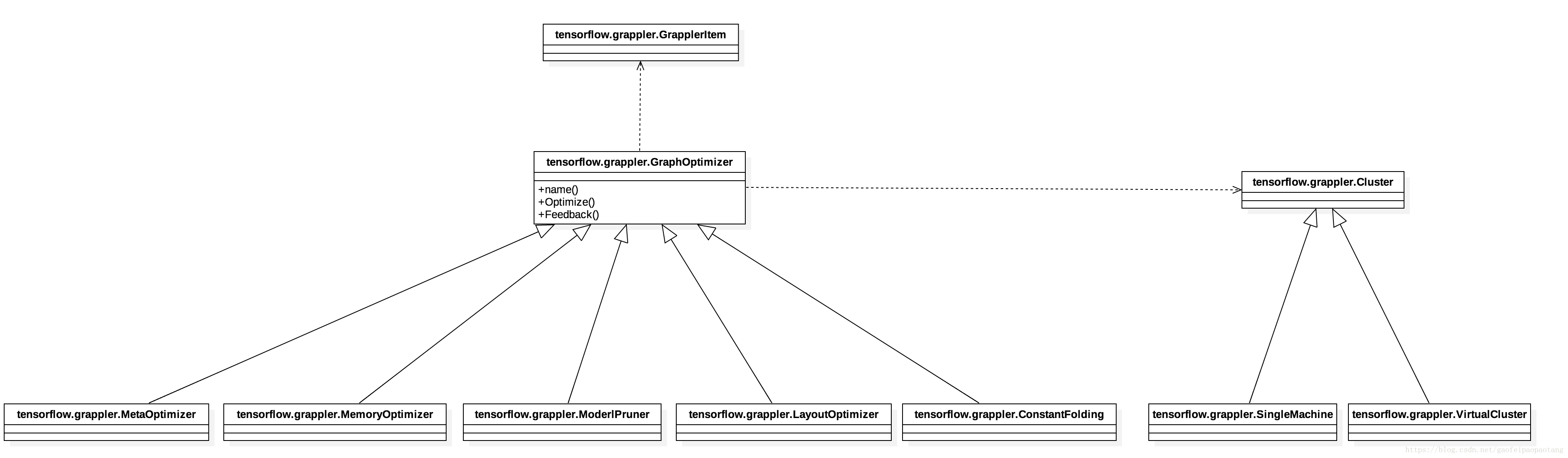
图1:Grappler模块主要类
tensorflow.grappler.GrapplerItem表示待优化的TensforFlow模型,主要包括计算图、fetch节点、feed节点。
tensorflow.grappler.Cluster表示可以运行TensorFlow模型的硬件资源集合。一个进程同一时间只能创建一个Cluster.
tensorflow.grappler.GraphOptimizer是grappler中所有优化类的父类。
grappler模块的调用方式如下:

图2:grappler模块调用过程
tensorflow.grappler.MetaOptimizer.Optimize()作为所有优化实现类是入口,根据优化的配置决定是否调用之后的每个优化类。
ModelPruner
tensorflow.gappler.ModelPruner类的主要优化逻辑是裁剪计算图,剔除不需要的节点。
目前版本的实现中, 主要剔除符合一定条件的"StopGradient"和"Identity"节点:
以上的定义中可以看出两个操作都是直接输出节点的输入。这两类节点也不是完全没有用处的,所以ModelPruner剔除前还要检查一些规则条件,比如明确绑定设备的这类节点不能剔除,有参与计算图流控制的节点不能提出,等等。
来看一个ModelPruner优化的例子:
图3:ModelPruner优化前模型
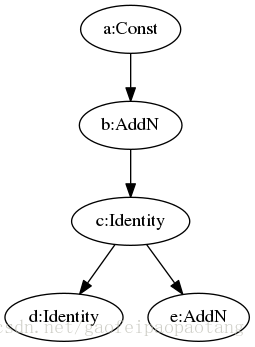
图4:ModelPruner优化前模型
ConstantFolding
tensorflow.grappler.ConstantFolding类的主要优化逻辑是做常量的折叠,所谓的常量折叠是将计算图中可以预先可以确定输出值的节点替换成常量,并对计算图进行一些结构简化的操作。
tensorflow.grappler.ConstantFolding.Optimize函数主要调用了三个方法:MaterializeShapes,FoldGraph 和 SimplifyGraph。
目前版本中,MaterializeShapes函数处理"Shape", “Size”, "Rank"三类运算节点:
三类节点的输出都取决与输入Tensor的形状,而与具体的输入取值没关系,所以输出可能是可以提前计算出来的。
MaterializeShapes函数将可以提前计算出输出值的这三类节点全部替换成 Const 节点。
FoldGraph函数中做折叠计算图的操作。如果一个节点的输入都是常量,那么它的输出也是可以提前计算的,基于这个原理不断地用常量节点替换计算图中的此类节点,直到没有任何可以替换的节点为止。
目前版本中,SimplifyGraph函数主要处理Sum,Prod,Min,Max,Mean,Any,All这几类运算节点。这几类节点的共同点是都沿着输入Tensor的一定维度做一定的运算,或是求和或是求平均,等等。SimplifyGraph将符合一定条件的这几类节点替换为Identity节点。
来看一个ConstantFolding的例子:
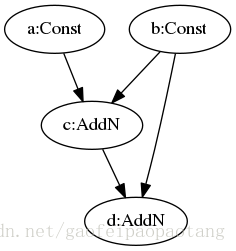
图5:ConstantFolding优化前模型
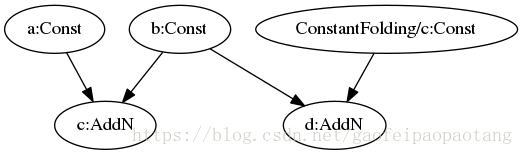
图6:ConstantFolding优化前模型
LayoutOptimizer
tensorflow.grappler.LayoutOptimizer类的主要优化逻辑是改变一些运算节点的输入数据格式来提高运算效率,这些运算节点包括:
“AvgPool”,“AvgPoolGrad”,“Conv2D”,“Conv2DBackpropFilter”,“Conv2DBackpropInput”,
“BiasAdd”,“BiasAddGrad”,“FusedBatchNorm”,“FusedBatchNormGrad”,
“MaxPool”,“MaxPoolGrad”。
这几类节点的输入数据支持NHWC和NCHW两种格式,但是在GPU的上的运算核实现上,采用NNCHW格式运算效率要高,LayoutOptimizer的优化就是将GPU设备上的这几类节点的输入格式从NHWC转换为NCHW。
说明:
1, 这类操作的输入一般是一批图片数据,NHWC表示输入格式为
[batch,height,width,channel],NCHW表示输入格式为
[batch,height,width,channel]。
2,之所以有两类格式的存在,是因为在CPU和GPU上两类OpKernel,
要求的最优格式不一样;也因为这个,tf中默认采用的格式是NHWC.
LayoutOptimizer 采用的优化方法是在适当的位置插入Transpose运算节点:最后看一个LayoutOptimizer优化的例子:
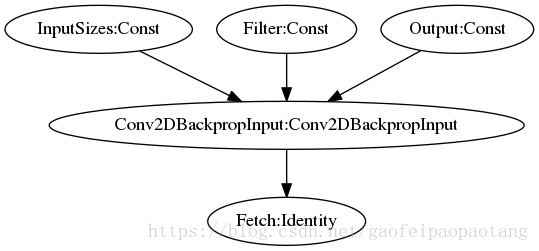
图7:LayoutOptimizer优化前模型
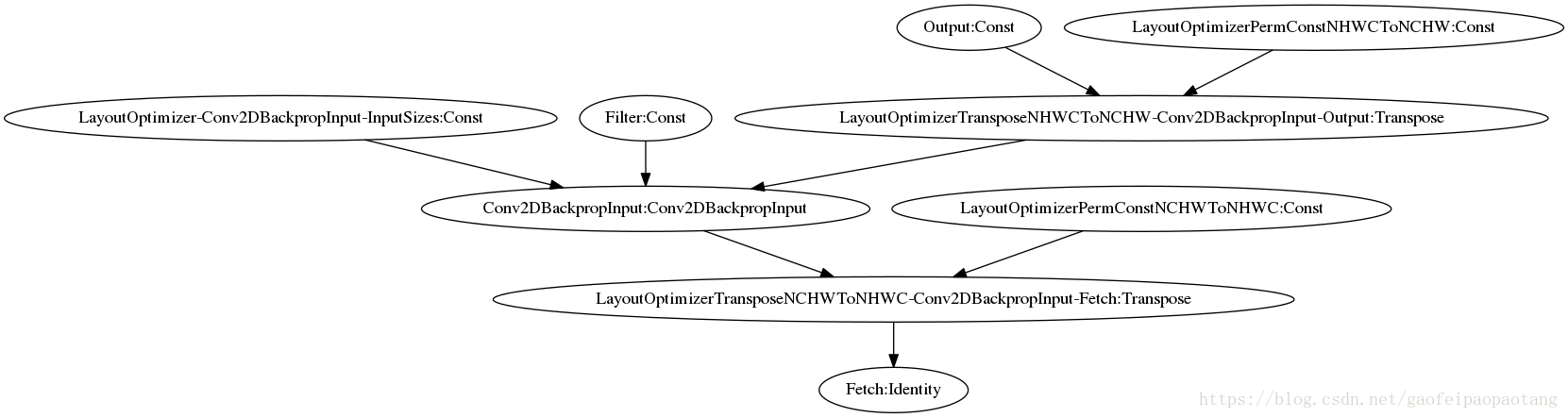
图8:LayoutOptimizer优化前模型
MemoryOptimizer
tensorflow.grappler.MemoryOptimizer的优化逻辑是降低设备的内存的占用。
在模型的调用计算过程中,计算产生的中间结果是不需要保存的,我们的目标是得出fetch的结果。
但是在模型训练过程中,节点运算产生的中间结果可能是需要保留的,因为在计算梯度的时候需要用,这就造成了设备内存的占用问题,而且模型越大,占用的内存就越多,而如GPU之类是设备内存是很稀缺和宝贵的资源。MemoryOptimizer就是为了解决这个问题的。
MemoryOptimizer采用的方法就是把一些中间结果交换到host主机的CPU内存中,等到需要用的时候,再交换进设备内存。
具体的实现是在计算图中适当的位置插入一对相连的Identity节点,一个分配到HOST CPU设备,另一个分配到如GPU的设备中,并设置好合适的上下游依赖。这样上游的中间计算结果就会被传出到HOST CPU中,然后在下游节点需要的时候通过这对节点交换回设备内存中。这个逻辑比较简单,就不做过多解释了,来看一个优化的例子:
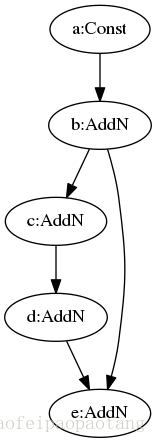
图9:MemoryOptimizer优化前模型
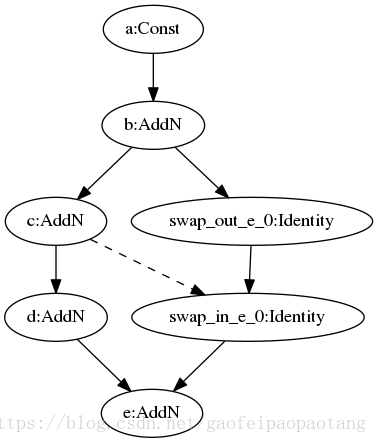
图10:MemoryOptimizer优化后模型
AutoParallel
tensorflow.grappler.AutoParallel的优化逻辑是通过重构原来的计算图,使得模型的训练过程实现数据并行,准确的说是多个batch的数据能并行训练,而不用等前一个batch训练完成。
实际上,tensorflow的分布式模式,已经支持多个batch同时训练,目的一样,与AutoParallel的实现方式不一样。
分布式的数据并发模式中,存在多份一样的模型,共享一份待训练的参数,而AutoParallel的优化中,只存在一个模型,AutoParallel通过过修改模型的结构来实现的并发。
下面通过一个例子来学习AutoParaller的优化逻辑:
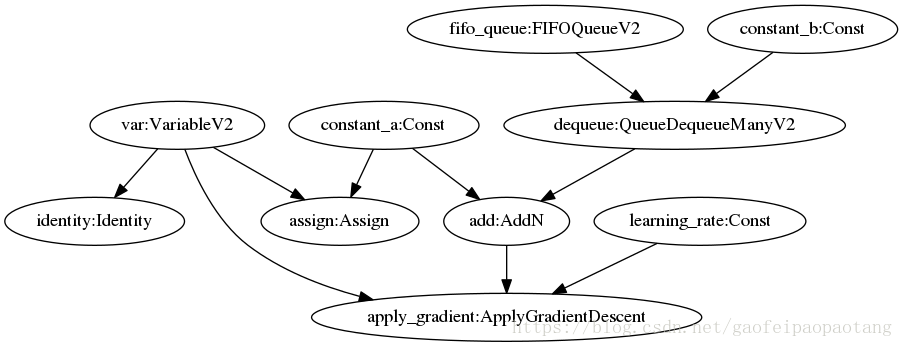
图11:AutoParaller优化前的模型
图3是AutoParaller优化前的模型,分号前的是节点的名称,分号后面的部分是节点的运算名称。
dequeue节点会每次从fifo节点中取出一定数量的数据,与constant_a相加后最后作为apply_gradient节点的输入之一。apply_gradient节点的运算是:
var−=add∗learning_rate.
这个模型简单模拟的一下模型训练的过程,add节点代表梯度的计算,不过真实训练中,计算梯度的子网络比这里的要复杂。
先面我们把这个模型输入到AutoParaller中,并设置并发度为2:
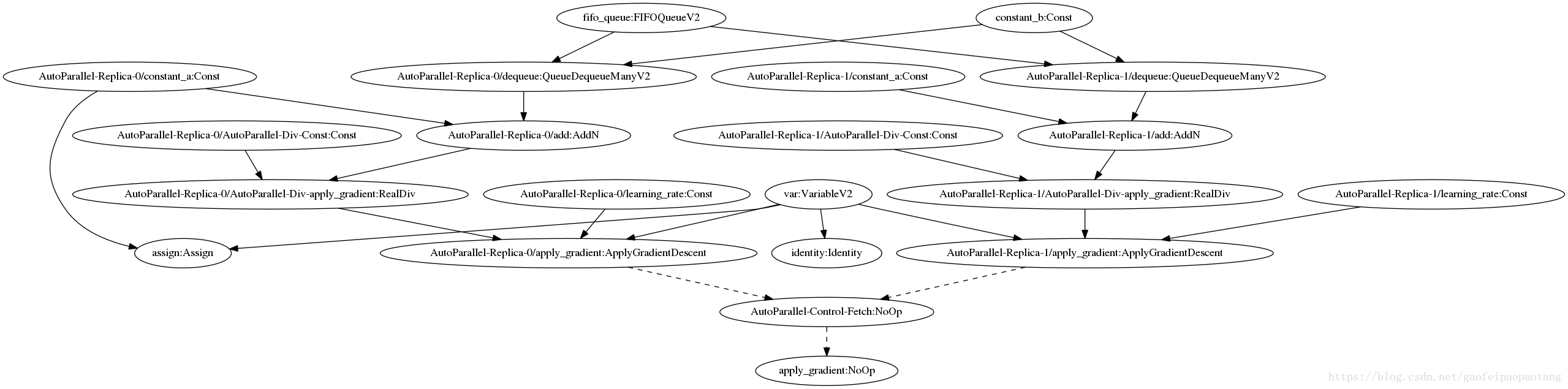
图12:AutoParaller优化后的模型
图4为经过AutoParaller优化后的模型。图中的虚线代表控制输入依赖,实现代表数据输入依赖。
可以看出,原始模型中的一些节点保留了下来,例如fifo,constant_b等等,一些节点被复制了一份,例如add, learning_rate,最后新添加了一些节点,例如AutoParaller-Div-apply_gradient, AutoParallerl-Contol-Fetch.
可以看出,两份ApplyGradientDescent节点可以并发运行。分别执行运算:
var−=2add(autoparallel−replica−0)∗learning_rate(autoparallel−replica−0)
var−=2add(autoparallel−replica−1)∗learning_rate(autoparallel−replica−1)
TensorFlow技术内幕(七):模型优化之XLA(上)
本章中我们分析一下TensorFlow的XLA(Accelerated Linear Algebra 加速线性代数)的内核实现。代码位置在tensorflow/compiler.
XLA
在XLA技术之前,TensorFlow中计算图的执行是由runtime(运行时)代码驱动的:runtime负责加载计算图定义、创建计算图、计算图分区、计算图优化、分配设备、管理节点间的依赖并调度节点kernel的执行;计算图是数据部分,runtime是代码部分。在第五章session类的实现分析中,我们已经比较详细的分析了这个过程。在XLA出现之后,我们有了另一个选择,计算图现在可以直接被编译成目标平台的可执行代码,可以直接执行,不需要runtime代码的参与了。
本章我就来分析一下XLA是如何将tensorflow.GraphDef编译成可执行代码的。
目前XLA提供了AOT(提前编译)和JIT(即时编译)两种方式。
AOT
在编译技术里,AOT(提前编译)方式就是在代码执行阶段之前全部编译成目标指令,进入执行阶段后,不再有编译过程发生。
tensorflow的官网已经介绍了一个AOT的使用例子,这里引用一下这个例子,代码位于tensorflow/compiler/aot/tests/make_test_graphs.py,函数tfmatmul构建了一个简单的网络如下:
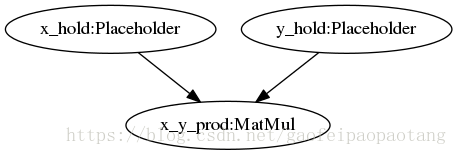
图1:matmul网络
例子中,我们将使用XLA的AOT方式将这计算图编译成可执行文件,需要四步:
步骤1:编写配置
配置网络的输入和输出节点,对应生成函数的输入输出参数。
/* tensorflow/compiler/aot/tests/test_graph_tfmatmul.config.pbtxt */
# Each feed is a positional input argument for the generated function. The order
# of each entry matches the order of each input argument. Here “x_hold” and “y_hold”
# refer to the names of placeholder nodes defined in the graph.
feed {
id { node_name: "x_hold" }
shape {
dim { size: 2 }
dim { size: 3 }
}
}
feed {
id { node_name: "y_hold" }
shape {
dim { size: 3 }
dim { size: 2 }
}
}
# Each fetch is a positional output argument for the generated function. The order
# of each entry matches the order of each output argument. Here “x_y_prod”
# refers to the name of a matmul node defined in the graph.
fetch {
id { node_name: "x_y_prod" }
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
步骤2:使用tf_library构建宏来编译子图为静态链接库
load("//third_party/tensorflow/compiler/aot:tfcompile.bzl", "tf_library")
# Use the tf_library macro to compile your graph into executable code.
tf_library(
# name is used to generate the following underlying build rules:
# <name> : cc_library packaging the generated header and object files
# <name>_test : cc_test containing a simple test and benchmark
# <name>_benchmark : cc_binary containing a stand-alone benchmark with minimal deps;
# can be run on a mobile device
name = "test_graph_tfmatmul",
# cpp_class specifies the name of the generated C++ class, with namespaces allowed.
# The class will be generated in the given namespace(s), or if no namespaces are
# given, within the global namespace.
cpp_class = "foo::bar::MatMulComp",
# graph is the input GraphDef proto, by default expected in binary format. To
# use the text format instead, just use the ‘.pbtxt’ suffix. A subgraph will be
# created from this input graph, with feeds as inputs and fetches as outputs.
# No Placeholder or Variable ops may exist in this subgraph.
graph = "test_graph_tfmatmul.pb",
# config is the input Config proto, by default expected in binary format. To
# use the text format instead, use the ‘.pbtxt’ suffix. This is where the
# feeds and fetches were specified above, in the previous step.
config = "test_graph_tfmatmul.config.pbtxt",
)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
步骤3:编写代码以调用子图
第二步会生成一个头文件和Object文件,头文件test_graph_tfmatmul.h的内容如下:
/* test_graph_tfmatmul.h */
namespace foo {
namespace bar {
// MatMulComp represents a computation previously specified in a
// TensorFlow graph, now compiled into executable code.
class MatMulComp {
public:
// AllocMode controls the buffer allocation mode.
enum class AllocMode {
ARGS_RESULTS_AND_TEMPS, // Allocate arg, result and temp buffers
RESULTS_AND_TEMPS_ONLY, // Only allocate result and temp buffers
};
MatMulComp(AllocMode mode = AllocMode::ARGS_RESULTS_AND_TEMPS);
~MatMulComp();
// Runs the computation, with inputs read from arg buffers, and outputs
// written to result buffers. Returns true on success and false on failure.
bool Run();
// Arg methods for managing input buffers. Buffers are in row-major order.
// There is a set of methods for each positional argument.
void** args();
void set_arg0_data(float* data);
float* arg0_data();
float& arg0(size_t dim0, size_t dim1);
void set_arg1_data(float* data);
float* arg1_data();
float& arg1(size_t dim0, size_t dim1);
// Result methods for managing output buffers. Buffers are in row-major order.
// Must only be called after a successful Run call. There is a set of methods
// for each positional result.
void** results();
float* result0_data();
float& result0(size_t dim0, size_t dim1);
};
} // end namespace bar
} // end namespace foo - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
引用头文件,编写使用端代码:
#define EIGEN_USE_THREADS
#define EIGEN_USE_CUSTOM_THREAD_POOL
#include <iostream>
#include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor"
#include "tensorflow/compiler/aot/tests/test_graph_tfmatmul.h" // generated
int main(int argc, char** argv) {
Eigen::ThreadPool tp(2); // Size the thread pool as appropriate.
Eigen::ThreadPoolDevice device(&tp, tp.NumThreads());
foo::bar::MatMulComp matmul;
matmul.set_thread_pool(&device);
// Set up args and run the computation.
const float args[12] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
std::copy(args + 0, args + 6, matmul.arg0_data());
std::copy(args + 6, args + 12, matmul.arg1_data());
matmul.Run();
// Check result
if (matmul.result0(0, 0) == 58) {
std::cout << "Success" << std::endl;
} else {
std::cout << "Failed. Expected value 58 at 0,0. Got:"
<< matmul.result0(0, 0) << std::endl;
}
return 0;
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
步骤4:使用cc_binary创建最终的可执行二进制文件
# Example of linking your binary
# Also see //third_party/tensorflow/compiler/aot/tests/BUILD
load("//third_party/tensorflow/compiler/aot:tfcompile.bzl", "tf_library")
# The same tf_library call from step 2 above.
tf_library(
name = "test_graph_tfmatmul",
...
)
# The executable code generated by tf_library can then be linked into your code.
cc_binary(
name = "my_binary",
srcs = [
"my_code.cc", # include test_graph_tfmatmul.h to access the generated header
],
deps = [
":test_graph_tfmatmul", # link in the generated object file
"//third_party/eigen3",
],
linkopts = [
"-lpthread",
]
) - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
四步编译出了可执行的文件,但是其实第二步中,tf_library宏的输出就是计算图对应的可执行文件了,包含一个头文件和Object文件。 所以计算图的编译工作主要在tf_library完成的,我们来分析一下tf_library的实现, tf_library定义在文件tensorflow/compiler/aot/tfcompile.bzl中:
/* tensorflow/compiler/aot/tfcompile.bzl */
...
def tf_library(name, graph, config,
freeze_checkpoint=None, freeze_saver=None,
cpp_class=None, gen_test=True, gen_benchmark=True,
visibility=None, testonly=None,
tfcompile_flags=None,
tfcompile_tool="//tensorflow/compiler/aot:tfcompile",
deps=None, tags=None):
...
# Rule that runs tfcompile to produce the header and object file.
header_file = name + ".h"
object_file = name + ".o"
ep = ("__" + PACKAGE_NAME + "__" + name).replace("/", "_")
native.genrule(
name=("gen_" + name),
srcs=[
tfcompile_graph,
config,
],
outs=[
header_file,
object_file,
],
cmd=("$(location " + tfcompile_tool + ")" +
" --graph=$(location " + tfcompile_graph + ")" +
" --config=$(location " + config + ")" +
" --entry_point=" + ep +
" --cpp_class=" + cpp_class +
" --target_triple=" + target_llvm_triple() +
" --out_header=$(@D)/" + header_file +
" --out_object=$(@D)/" + object_file +
" " + (tfcompile_flags or "")),
tools=[tfcompile_tool],
visibility=visibility,
testonly=testonly,
# Run tfcompile on the build host since it's typically faster on the local
# machine.
#
# Note that setting the local=1 attribute on a *test target* causes the
# test infrastructure to skip that test. However this is a genrule, not a
# test target, and runs with --genrule_strategy=forced_forge, meaning the
# local=1 attribute is ignored, and the genrule is still run.
#
# https://www.bazel.io/versions/master/docs/be/general.html#genrule
local=1,
tags=tags,
)
...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
上面我节选了tf_library代码中关键的一步,这步调用tfcompile_tool命令行工具,生成头文件和二进制问题。可以看到调用tfcompile_tool的命令行包括–graph,–config等等。
tfcompile_tool的入口main函数定义在tensorflow/compiler/aot/tfcompile_main.cc中,编译过程主要分为四步:
1、由GraphDef构建tensorflow.Graph。
2、调用xla.XlaCompiler.CompileGraph,将tensorflow.Graph编译为xla.Computation。
3、调用xla.CompileOnlyClient.CompileAheadOfTime函数,将xla.Computation编译为可执行代码。
4、保存编译结果到头文件和object文件
TensorFlow目前支持的AOT编译的平台有x86-64和ARM.
JIT
JIT全称Just In Time(即时).在即时编译中,计算图在不会在运行阶段前被编译成可执行代码,而是在进入运行阶段后的适当的时机才会被编译成可执行代码,并且可以被直接调用了。
关于JIT编译与AOT编译优缺点的对比,不是本章的主题,限于篇幅这里不做过多的分析了。我们直接来看TensorFlow中JIT的实现。
Python API中打开JIT支持的方式有一下几种:
方式一、通过Session设置:
这种方式的影响是Session范围的,内核会编译尽可能多的节点。
# Config to turn on JIT compilation
config = tf.ConfigProto()
config.graph_options.optimizer_options.global_jit_level = tf.OptimizerOptions.ON_1
sess = tf.Session(config=config)- 1
- 2
- 3
- 4
- 5
方式二、通过tf.contrib.compiler.jit.experimental_jit_scope():
这种方式影响scope内的所有节点,这种方式会对Scope内的所有节点添加一个属性并设置为true: _XlaCompile=true.
jit_scope = tf.contrib.compiler.jit.experimental_jit_scope
x = tf.placeholder(np.float32)
with jit_scope():
y = tf.add(x, x) # The "add" will be compiled with XLA.
- 1
- 2
- 3
- 4
- 5
- 6
方式三、通过设置device:
通过设置运行的Device来启动JIT支持。
with tf.device("/job:localhost/replica:0/task:0/device:XLA_GPU:0"):
output = tf.add(input1, input2)- 1
- 2
接下来我们来分析一下这个问题:上面的这些接口层的设置,最终是如何影响内核中计算图的计算的呢?
首先来回忆一下 TensorFlow技术内幕(五):核心概念的实现分析 的图4,session的本地执行这一节:graph在运行前,需要经过一系列优化和重构(包括前一章中分析的grappler模块的优化)。其中一步涉及到类:tensorflow.OptimizationPassRegistry,通过此类我们可以运行其中注册的tensorflow.GraphOptimizationPass的子类,每一个子类都是实现了一种graph的优化和重构的逻辑。XLA JIT 相关的Graph优化和重构,也是通过这个入口来执行的。
JIT相关的tensorflow.GraphOptimizationPass注册代码在:
/* tensorflow/compiler/jit/jit_compilation_pass_registration.cc */
...
namespace tensorflow {
REGISTER_OPTIMIZATION(OptimizationPassRegistry::POST_REWRITE_FOR_EXEC, 10,
MarkForCompilationPass);
// The EncapsulateSubgraphs pass must run after the MarkForCompilationPass. We
// also need to run it after the graph been rewritten to have _Send nodes added
// for fetches. Before the _Send nodes are added, fetch nodes are identified by
// name, and encapsulation might remove that node from the graph.
REGISTER_OPTIMIZATION(OptimizationPassRegistry::POST_REWRITE_FOR_EXEC, 20,
EncapsulateSubgraphsPass);
// Must run after EncapsulateSubgraphsPass.
REGISTER_OPTIMIZATION(OptimizationPassRegistry::POST_REWRITE_FOR_EXEC, 30,
BuildXlaLaunchOpsPass);
} // namespace tensorflow
...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
可以看到JIT编译相关的tensorflow.GraphOptimizationPass有三个:
1、tensorflow.MarkForCompilationPass:
上面提到的开启JIT的三种设置方式,就是在此类中进行检查的。通过检查这些设置,此类首先会挑选出所有开启JIT并且目前版本支持JIT编译的节点,并且运行聚类分析,将这些等待JIT编译的节点分到若干个Cluster中,看一下下面的例子:

图2:MarkForCompilationPass优化前

图3:MarkForCompilationPass优化后
B,C节点被标记到cluster 1,E,F节点被标记到cluster 0. A,E应为不支持编译所以没有被分配cluster.
2、tensorflow.EncapsulateSubgraphsPass:
这一步优化分三步,
第一步 :为上一个优化类MarkForCompilationPass mark形成的cluster分别创建对应的SubGraph对象。
第二步:为每个SubGraph对象创建对应的FunctionDef,并将创建的FunctionDef添加到FunctionLibrary中。
这里补充一下TensorFlow中Funtion的概念,FucntionDef的定义如下:
/* tensorflow/core/framework/function.proto */
message FunctionDef {
// The definition of the function's name, arguments, return values,
// attrs etc.
OpDef signature = 1;
map<string, AttrValue> attr = 5;
repeated NodeDef node_def = 3;
map<string, string> ret = 4;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Function可以看做一个独立的计算图,node_def就是这个子图包含的所有节点。Function可以被实例化和调用,方式是向调用方的计算图中插入一个Call节点,这类节点的运算核(OpKernel)是CallOp:
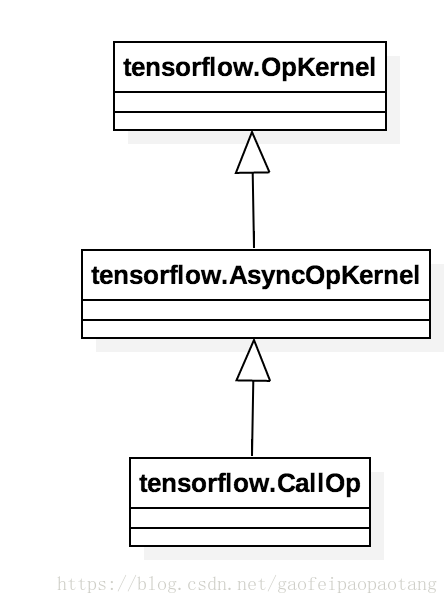
图4:类CallOp
我们知道计算图的计算最终是由Executor对象驱动的,CallOp是连接调用方计算图的Executor和Function内计算图的桥梁:CallOp对外响应Executor的调用,对内会为每次调用创建一个独立的Executor来驱动Function内部计算图的运算。
第三步:重新创建一张新的计算图,首先将原计算图中没有被mark的节点直接拷贝过来,然后为每个SubGraph对应的Function创建CallOp节点,最后创建计算图中数据和控制依赖关系。
下面的例子中,就将C和c节点一起,替换成了F1节点,调用了Function F1:
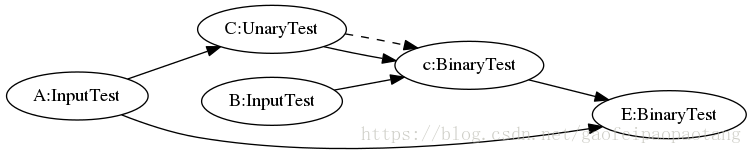
图5:EncapsulateSubgraphsPass优化前
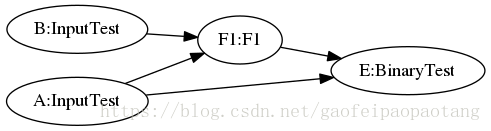
图6:EncapsulateSubgraphsPass优化后
3、tensorflow.BuildXlaLaunchOpsPass:
经过EncapsulateSubgraphsPass优化的计算图中的function call节点全部替换成xlalaunch节点。
JIT的关键就是这个xlalaunch节点。xlalaunch节点节点的运算名为”_XlaLaunch”,运算核是XlaLocalLaunchOp,按照运算核的要求它的父类也是OpKernel。
XlaLocalLaunchOp对外响应Executor的调用请求,对内调用JIT相关API类编译和执行FunctionDef。当然对编译结果会有缓存操作,没必要每次调用都走一次编译过程:
步骤一:调用XlaCompilationCache的将FunctionDef编译为xla.LocalExecutable。在cache没命中的情况下,会调用xla.LocalClient执行真正的编译
步骤二:调用xla.LocalExecutable.Run
JIT方式目前支持的平台有X86-64, NVIDIA GPU。
小结
以上分析的是XLA在TensorFlow中的调用方式:AOT方式和JIT方式。
两种方式下都会将整个计算图或则计算图的一部分直接编译成可执行代码。两则的区别也是比较明显的,除了编译时机不一样外,还有就是runtime(运行时)的参与程度。AOT中彻底不需要运行时的参与了,而JIT中还是需要运行时参与的,但是JIT会优化融合原计算图中的节点,加入XlaLaunch节点,来加速计算图的执行。
后面我们会详细分析一下XLA这个编译器的内部实现。
TensorFlow技术内幕(八):模型优化之XLA(下)
上一章我们分析了XLA在TensofFlow中的两种调用方式AOT和JIT,本章分析XLA编译器的实现。
LLVM
提到编译器就不得不提大名鼎鼎的LLVM。LLVM是一个编译器框架,由C++语言编写而成,包括一系列分模块、可重用的编译工具。
LLVM框架的主要组成部分有:
前端:负责将源代码转换为一种中间表示
优化器:负责优化中间代码
后端:生成可执行机器码的模块
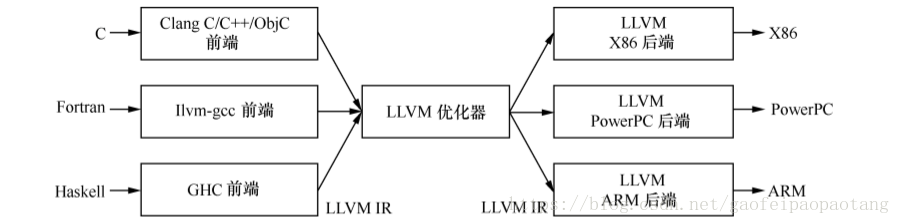
图1:LLVM框架结构
LLVM为不同的语言提供了同一种中间表示LLVM IR,这样子如果我们需要开发一种新的语言的时候,我们只需要实现对应的前端模块,如果我们想要支持一种新的硬件,我们只需要实现对应的后端模块,其他部分可以复用。
XLA目录结构
XLA的实现目录是tensorflow/compiler,目录结构如下:
XLA编译
XLA也是基于LLVM框架开发的,前端的输入是Graph,前端没有将Graph直接转化为LLVM IR,而是转化为了XLA的自定义的中间表示HLO IR.并且为HLO IR设计了一系列的优化器。经过优化的HLO IR接下来会被转化为LLVM IR。
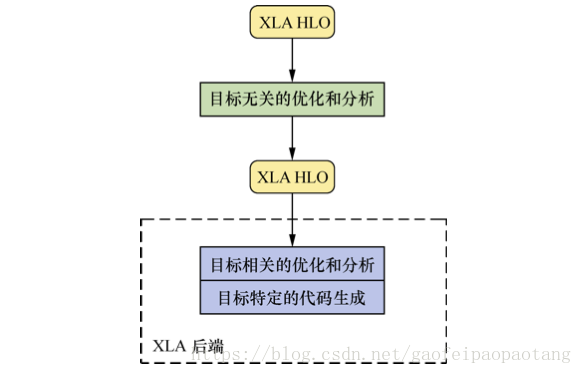
图2:XLA框架结构
具体来说包含了下列几步:
步骤一:由GraphDef创建Graph
步骤二:由tensorflow.Graph编译为HLO IR
步骤三:分析与优化HLO IR
步骤四:由HLO IR转化为llvm IR
步骤五:分析与优化llvm IR
步骤六:生成特定平台的二进制文件
AOT
AOT编译流程图:
图3:AOT编译流程
对照图2来分析一下AOT编译流程:
tensorflow.XlaCompiler.CompilerGraph函数将Graph编译成XLA的中间表示xla.UserComputation.
tensorflow.XlaCompiler.CompilerGraph会创建Executor来执行待编译的Graph,通过绑定设备,为所有节点的创建运算核都是专门设计用来编译的,基类是tensorflow.XlaOpKernel.
tensorflow.XlaOpKernel的子类需要实现Compile接口,通过调用xla.ComputeBuilder接口,将本节点的运算转化为Xla指令(instruction).
xla.ComputeBuilder是对xla.Client的调用封装,通过本接口创建的xla指令(instruction)的操作,最终都会通过xla.Client传输到xla.Service.
xla.Client 和 xla.Service 支持单机模式和分布式模式,实际的编译过程发生在Service端.
AOT编译中,用到的是 xla.CompileOnlyClient 和 xla.CompileOnlyService,分别是xla.Client和xla.Service的实现类.
可以看到,图2中的第一个循环(loop for every node)会为每个node生成一系列xla指令(instruction),这些指令最终会被加入xla.UserComputation的指令队列里。
接下来xla.CompileOnlyClient.CompileAheadOfTime会将xla.UserComputation编译为可执行代码.
xla.ComputationTracker.BuildHloModule函数会将所有的xla.UserComputation转化为xla.HloComputation,并为之创建xla.HloModule.
至此,Graph 到 HLO IR 的转化阶段完成。
HLO IR进入后续的编译过程,根据平台调用不同平台的具体编译器实现类,这里我们以xla.CpuComiler为例来分析.
xla.CpuComiler的输入是xla.HloModule,首先会调用RunHloPasses创建HloPassPipeline,添加并运行一系列的HloPass.
每一个HloPass都实现了一类HLO指令优化逻辑。通常也是我们比较关心的逻辑所在,包含单不限于图中列举出来的
xla.AlebraicSimplifier(代数简化),xla.HloConstantFolding(常量折叠),xla.HloCSE(公共表达式消除)等。HloPassPipeline优化HLO IR之后,将创建xla.cpu.IrEmitter,进入图2中的第三个循环处理逻辑(loop for every computation of module):将xla.HloModule中的每个xla.HloComputation转化为llvm IR表示,并创建对应的llvm.Module.
至此,Hlo IR 到 llvm IR的转化阶段完成,后面进入llvm IR的处理阶段。
创建xla.cpu.CompilerFunctor将llvm IR转化为最终的可执行机器代码llvm.object.ObjectFile.中间会调用一系列的llvm ir pass对llvm ir进行优化处理。
至此,llvm ir到可执行机器码的转化阶段完成。
JIT
JIT编译流程图:
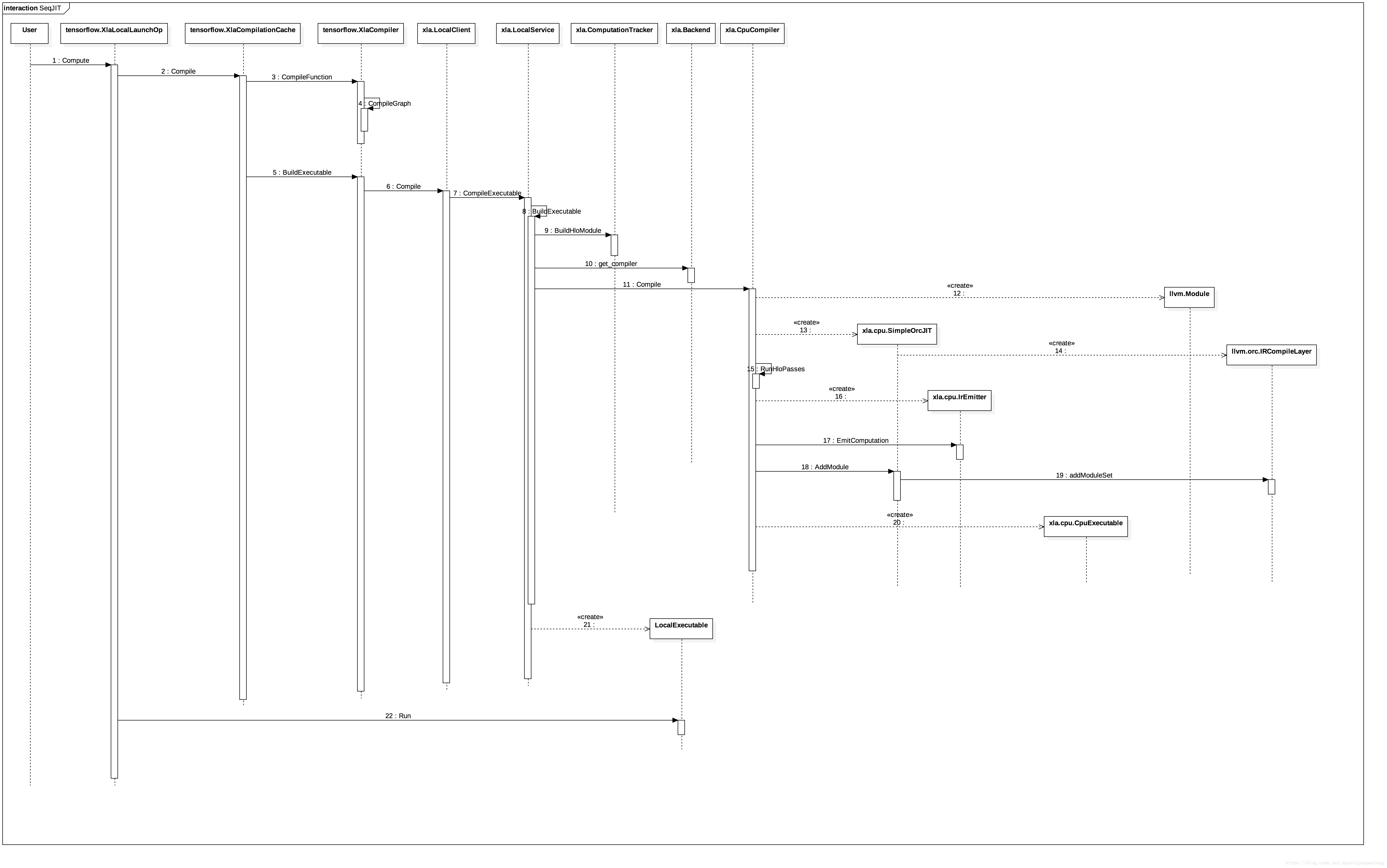
图4:JIT编译流程
JIT对比AOT来说,过程比较类似,略过共同的部分,我们来分析一下:
JIT调用方式的入口在运算核tensorflow.XlaLocalLaunchOp.Compute,tensorflow.XlaLocalLaunchOp是连接外部Graph的Executor和内部JIT调用的桥梁。
如果被调用的计算图缓存不命中,则会调用xla.XlaCompile进行实际的编译。
编译过程类似AOT,不同之处主要在于:首先这次调用的Client和Service的实现类是xla.LocalClient和xla.LocalService;其次,llvm ir到机器码的编译过程,这次是通过xla.cpu.SimpleOrcJIT完成的,它将llvm ir编译为可执行代码,并可被立即调用。
可执行机器码后续会被封装为xla.LocalExecutale
调用xla.LocalExecutable的如后函数Run.
TensorFlow技术内幕(九):模型优化之分布式执行
随着模型和数据规模的不断增大,单机的计算资源已经无法满足算法的需求,本章分析一下TensorFlow内核中的对分布式执行支持。
GrpcSession
在第五章中,分析Graph的执行过程的时候,提到Graph的执行可以选择本地执行,对应的Session实现类是DirectSession,还可以选择服务端执行,对应的Session实现类就是GrpcSession.

图1:GrpcSession
第五章中我们只分析了这种分布式执行的客户端代码(见图1),但是并没有分析服务端的代码,本章来补上服务端的代码分析。
Master vs Worker
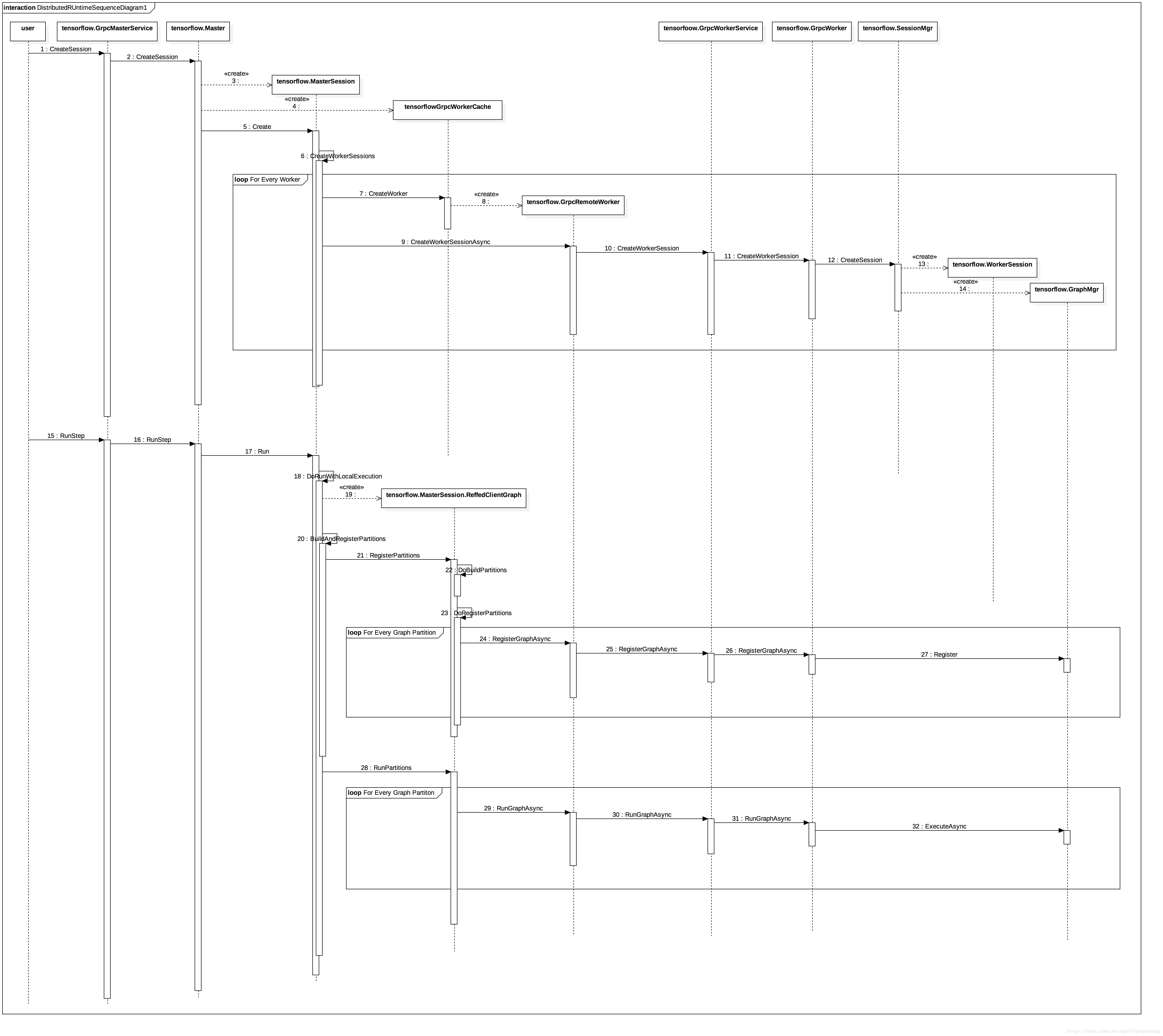
图2:TensorFlow的分布式执行流程
流程图见图2:
MasterService 和 WorkerSevice可以在同一个进程,也可以在不同的进程。所以图中的调用,部分是本地的直接调用,部分是RPC调用(例如User到GrpcMasterService的调用,GrpcRemoteWorker到GrpcWorkerService的调用,都是RPC调用)。
tensorflow.Master 与 tensorflow.GrpcMasterService 驻留在同一进程,后者会将来自RPC的调用全部交给前者处理。
tensorflow.GrpcWorker 与 tensorflow.GrpcWorkerService驻留在同一进程,类似地,后者也会将来自RPC的调用全部交给前者处理。
函数tensorflow.Master.CreateSession 根据配置选项创建一个MasterSession和一个或多个WorkerSession。
MasterSession负责调度和任务分配,WorkerSession绑定特定的设备,负责真正的执行。分别驻留在Master和Worker进程内。
GrpcWoker与WorkerSession驻留在同一进程。并通过SessionMgr管理所有的WorkerSession.
执行阶段MasterSession会负责将计算图分区(这部分逻辑在第五章中分析过),然后分别注册到不同的WorkerSession中去执行。
WorkerSession最终通过创建Executor来驱动注册过的计算图的执行。
TensorFlow技术内幕(十三):模型保存与恢复
模型训练过程中,我们希望在训练一段时间或一定次数之后,保存模型的当前状态,用于实验分析,或故障恢复,又或则是提供给线上服务使用。
Tensorflow中模型的状态包括两个方面,首先是模型的结构,其次是参数和参数的当前值。
本文介绍一下tensoflow中模型的这两类信息是如何保存和恢复的。
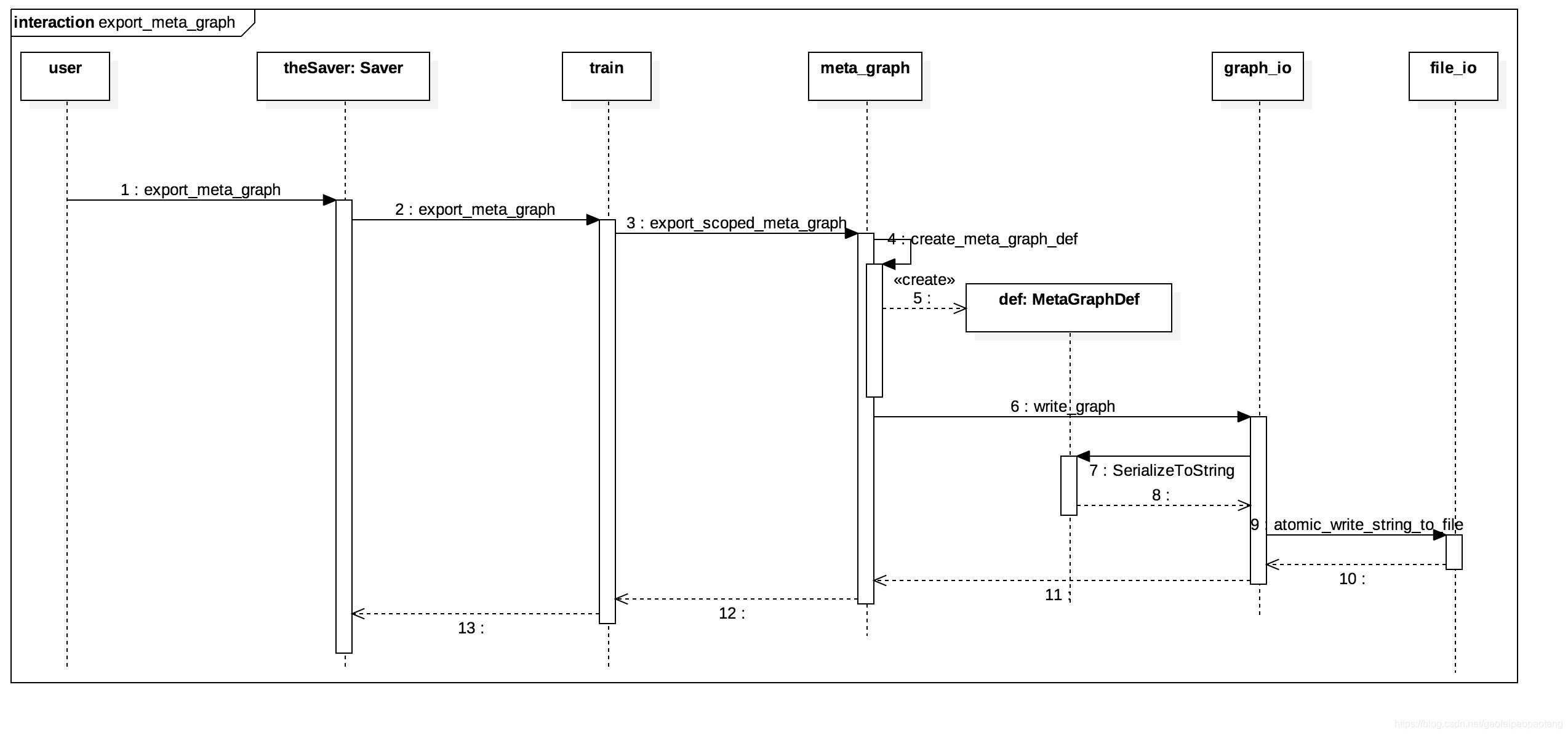
模型结构
模型的结构信息是静态信息,在构建完成后一般不会再变化,保存的过程比较简单直接,首先将结构信息收集并写到MetaGraphDef对象中,然后将MetaGraphDef对象序列化后存储到外部存储.
MetaGraphDef是protobuf定义的message, 囊括了恢复模型结构的所有必要信息,简单介绍下面几类信息:
下面是结构信息保存过程的时序图:
模型参数
参数的个数一般是固定的,参数的值是随着训练的过程不断变化的。那么如果保存参数信息呢?
一般来说,一个比较朴素直接的方法就是遍历所有待保存的参数,获取参数的值并存储到外部存储中去。那么这个朴素版本的方案有没有什么问题呢?
其实,在设计方案的时候有一个原则,就是数据规模决定实现的方法。在数据量不大的情况下,这个保存参数值方法并没什么问题。但是当数据规模大了以后,这个方法就有很严重的效率问题,并且在超大规模的训练中,这个方法实际上是不可行的。
为什呢?我们知道,在tensoflow集群方式训练的过程中,集群会由若干个worker节点和若干个ps(parameter server)节点组成, worker节点承担主要的运算量,ps节点共同负责存储和更新所有的参数。
上述的参数保存方法中,保存过程的执行者是worker节点,它会将所有参数的参数值从ps节点拉取到本地,然后从本地写到外部存储中去,这样一来,如果参数的纬度比较大,参数的传输就会占用很大的带宽,造成性能问题,并且如果参数纬度更大,超过单机内存容量,那么这个方法就会耗尽worker的内存。
显然这个方法不是一个很好的方案,那么tensorflow是如何保存参数的呢?
tensorflow参数保存的功能,同样也实现在tf.train.Saver类里,通过两个步骤来实现:
- 第一步:在模型Graph中添加Save Node,并将所有需要保存值的Node(一般来说也就是Variable Node)作为Save Node的输入节点。
- 第二步:在需要保存参数值的时刻,运行Save Node,Save Node调用Save Op,将输入全部写到外部存储中。
这样的设计就避免了参数从ps到worker的传输,因为Save Node一般会分配到参数所在的ps上。
下面分析一下参数保存的具体过程,其中Save Node的添加发生在tf.train.Saver的构造函数内:
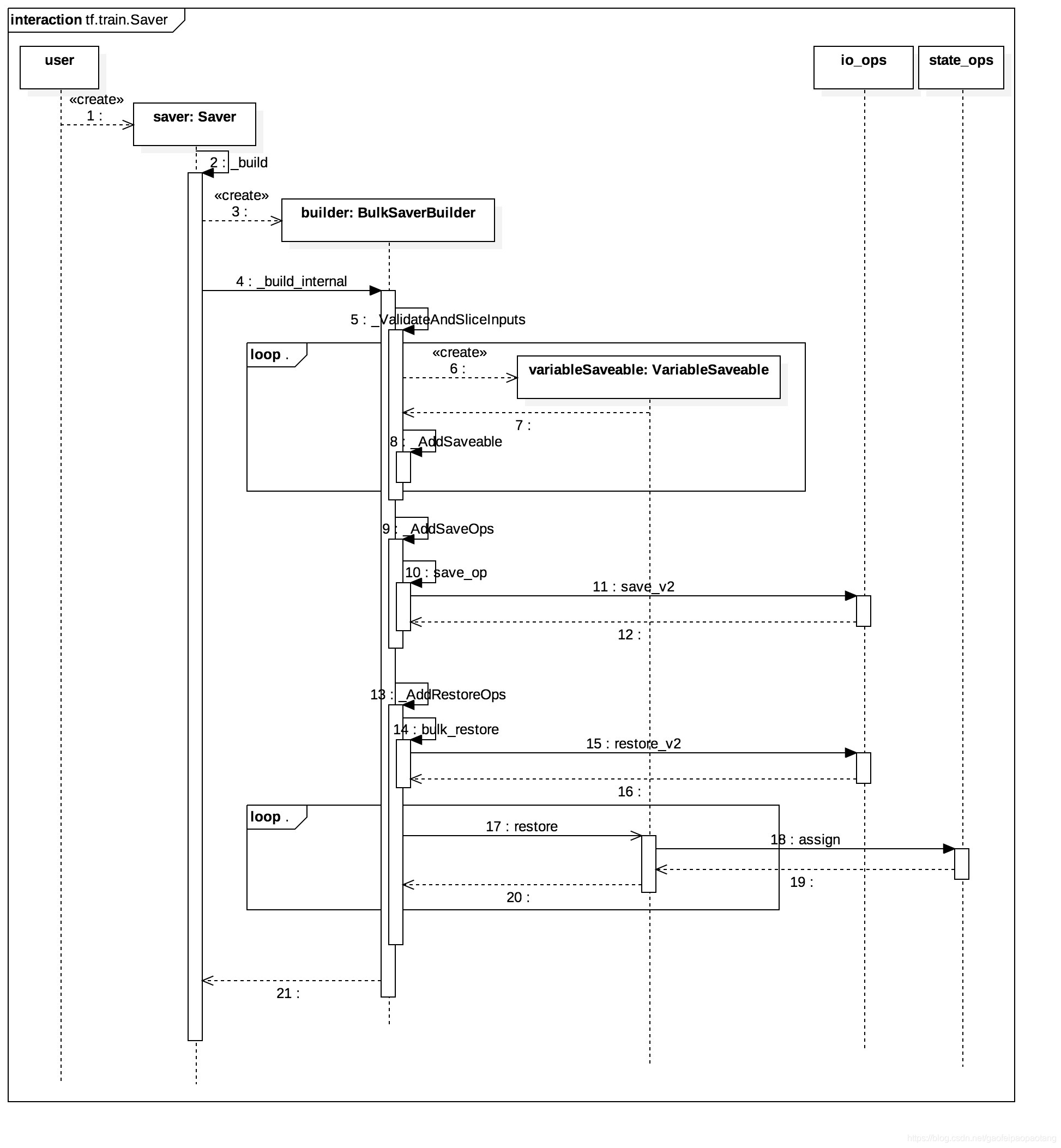
注意,上面的时序图中包括了Restore Node的添加过程,实际上也是这样的,Save和Restore都是在Saver的构造函数里添加的。
完成第一步之后,第二步就是在需要保存参数的时刻,调用Saver的Save方法,运行Save Node,时序图如下:
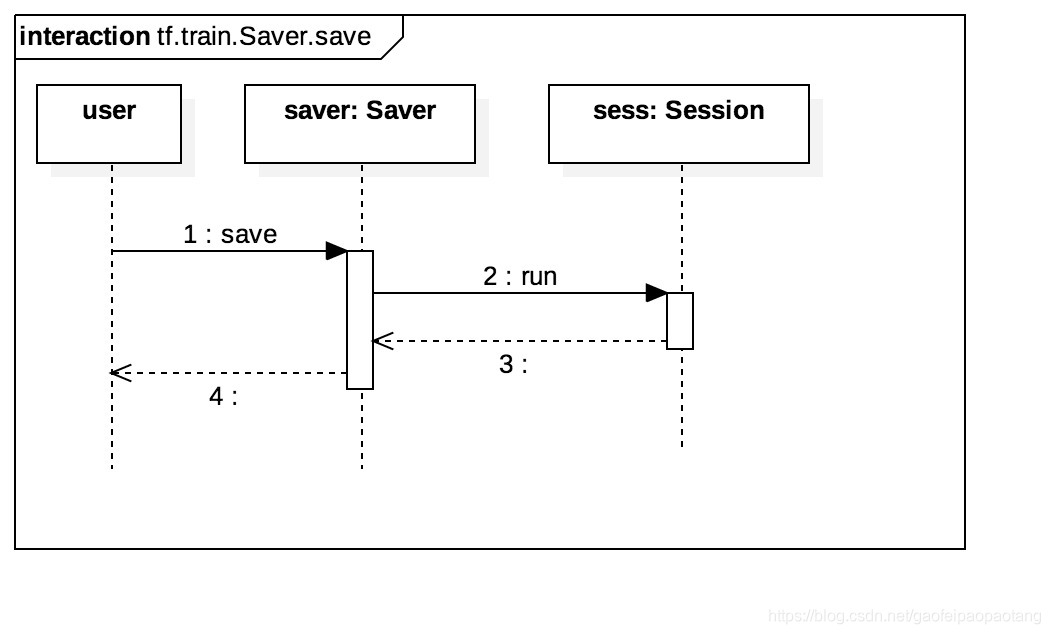
我们可能还比较关心的是,上面Saver构造函数里添加的Save Node和Restore Node的实现。我们以Saver Node为例介绍一下
SaveOp
Saver Node调用的是Save操作, Save操作在CPU上的操作核是SaveV2, 它继承自OpKnernel, 保存参数的功能在函数Compute中,保存的时序图如下: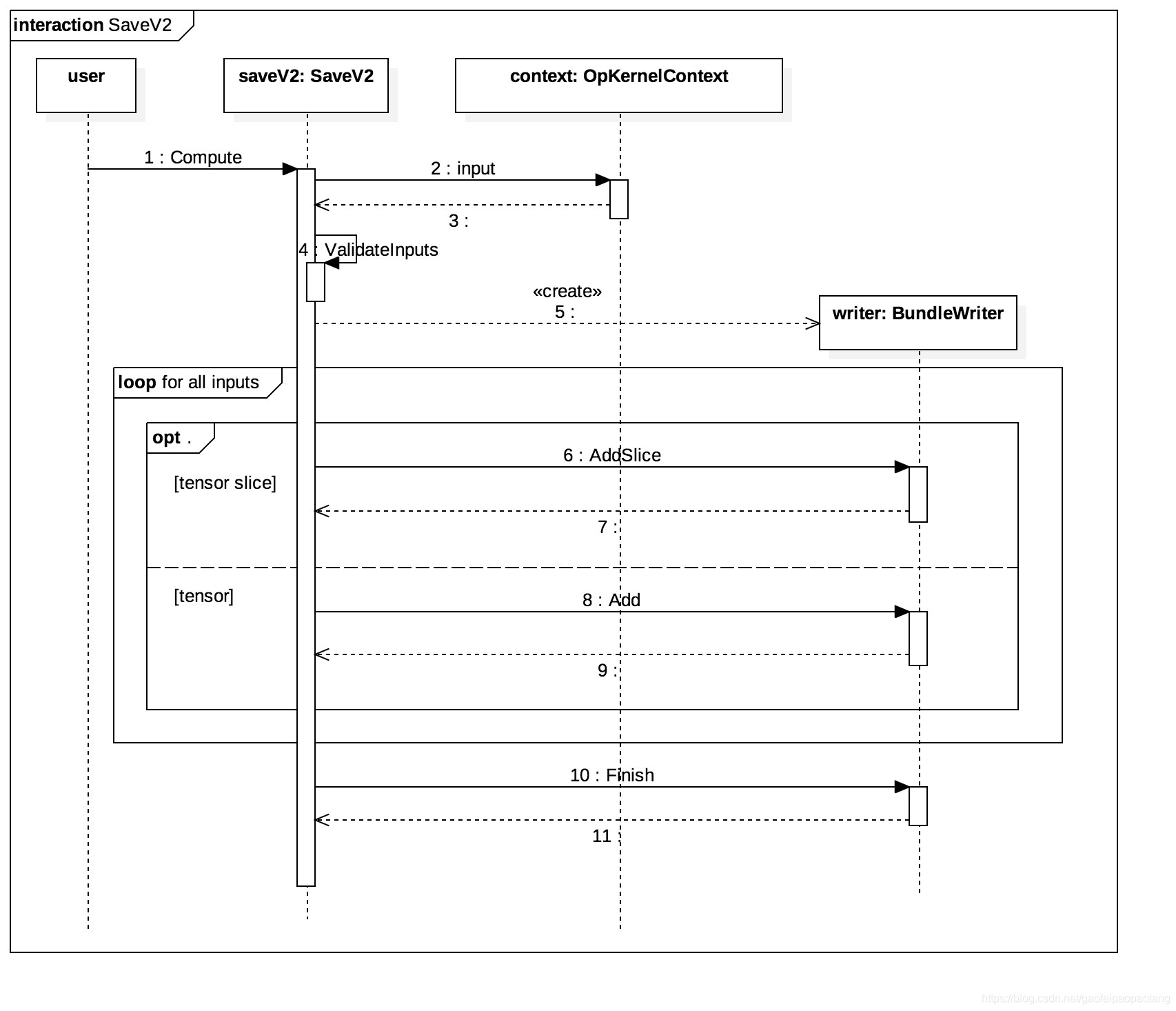
SaveV2有三个固定的输入,分别是prefix, tensor_names和shape_and_sclices, 分别表示保存目录、tensor名、tensor形状和切片信息;剩下的若干个输入都是需要保存的tensor的值,数量等于tensor_names数组的长度。
tensor形状和切片信息存在的原因是,作为SaveV2输入的tensor,可能是原始tensor的一部分,也就是所谓的原始tensor的一个分片,SaveV2支持tensor分片单独存储。例如当我们声明Partion Variable的时候,就会出现tensor分片的情况。
总结
上面我们详细分析了模型的保存过程,模型恢复的过程就是存储过程的逆向过程,了解了存储了过程之后,掌握恢复过程就比较简单了,这里就不再展开介绍了。
TensorFlow技术内幕(十四):在线学习
本文准备介绍tensorflow对在线学习的支持。所谓在线学习也就是模型一边训练一边服务,与之相对的则是离线学习(或称为批量学习):

在工程实现上,一般采用架构如下:
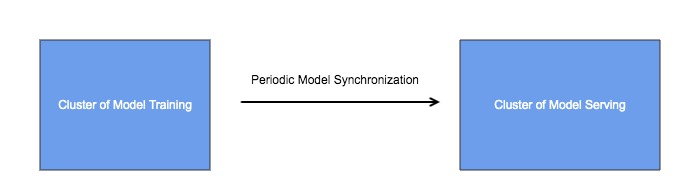
通过周期性的模型同步,将训练集群和服务集群相互隔离,这样做是有必要的,因为两个集群的业务场景不一样,对他们的要求也不一样:
- 模型服务集群承载着线上的真实流量,所以所有后端服务的常用指标都适用于服务模型服务集群,高可用性、高效率、高扩展性等等。
- 模型训练集群重在训练的效率,不要求有很高的热扩展性,可以停机添加机器或剔除机器,对可用性要求也不是很苛刻。
tensorflow体系中,模型训练集群采用tensorflow,模型服务集群一般采用tensorflow serving,模型以文件的形式存储,模型同步是通过文件系统完成的,比如HDFS。tensorflow serving是模型服务方面的高性能开源库,支持模型的版本管理和检查,以及自动更新。
这种结构能满足大多数情况下的业务场景的需求,但是在一些极端场景下,这些还不够。比如作者就曾遇到这样的常见,模型的体积超出了单机内存的上限,如何处理呢?
具体来说,在模型训练的时候,可以采用PS结构,将超大的模型分散到多台参数服务器上;但是到了模型服务的时候,tensorflow serving并不支持PS结构,模型必须单机完整加载模型。
也许你会想到,直接用tensorflow做模型服务,并且也同样采用PS结构呢?
这个架构的问题在于tensorflow ps集群不支持热扩展,当需要添加机器的时候,需要全部重启。
回到我们模型超大的问题,解决这个问题的关键在于tensorflow的一个很好的特征,那就是可以自定义OP。
这里提供一个解决的思路,具体实现的方式可以有很多种方式,就不在这里详述了:
- 有了自定义的OP的机制,模型训练集群可以将模型以我们自定义的格式存储到任何载体里,比如为了方便检索可以放到数据库,并且模型服务集群可以实现模型的按需查询,如此则服务集群不需要将完整的模型全部加载到单机内存里。
结构如下:

zzTensorflow技术内幕:的更多相关文章
- SQL Server技术内幕笔记合集
SQL Server技术内幕笔记合集 发这一篇文章主要是方便大家找到我的笔记入口,方便大家o(∩_∩)o Microsoft SQL Server 6.5 技术内幕 笔记http://www.cnbl ...
- 《MSSQL2008技术内幕:T-SQL语言基础》读书笔记(下)
索引: 一.SQL Server的体系结构 二.查询 三.表表达式 四.集合运算 五.透视.逆透视及分组 六.数据修改 七.事务和并发 八.可编程对象 五.透视.逆透视及分组 5.1 透视 所谓透视( ...
- 《MSSQL2008技术内幕:T-SQL语言基础》读书笔记(上)
索引: 一.SQL Server的体系结构 二.查询 三.表表达式 四.集合运算 五.透视.逆透视及分组 六.数据修改 七.事务和并发 八.可编程对象 一.SQL Server体系结构 1.1 数据库 ...
- Mysql技术内幕(第四版)读书笔记(一)
题记:写代码已经有2年了,学到了很多知识,但是没有一个好习惯去记录,去分享,好多知识点都会忘记,所以从今天开始学着像大牛一样去记录自己经历项目的点点滴滴,先从最近读<Mysql技术内幕>开 ...
- 【转】COM技术内幕(笔记)
COM技术内幕(笔记) COM--到底是什么?--COM标准的要点介绍,它被设计用来解决什么问题?基本元素的定义--COM术语以及这些术语的含义.使用和处理COM对象--如何创建.使用和销毁COM对象 ...
- 深入分析Java Web技术内幕(修订版)
阿里巴巴集团技术丛书 深入分析Java Web技术内幕(修订版)(阿里巴巴集团技术丛书.技术大牛范禹.玉伯.毕玄联合力荐!大型互联网公司开发应用实践!) 许令波 著 ISBN 978-7-121- ...
- WebKit技术内幕
WebKit技术内幕(浏览器内核|渲染引擎| HTML5| Chromium项目Committer重磅作品) 朱永盛 著 ISBN 978-7-121-22964-0 2014年6月出版 定价:7 ...
- 从Paxos到ZooKeeper-四、ZooKeeper技术内幕
本文将从系统模型.序列化与协议.客户端工作原理.会话.服务端工作原理以及数据存储等方面来揭示ZooKeeper的技术内幕. 一.系统模型 1.1 数据模型 ZooKeeper的视图结构使用了其特有的& ...
- Spark技术内幕:Stage划分及提交源码分析
http://blog.csdn.net/anzhsoft/article/details/39859463 当触发一个RDD的action后,以count为例,调用关系如下: org.apache. ...
随机推荐
- 用scanf清空缓冲区 对比fflush
fflush会将缓冲数据打印到屏幕或者输出磁盘,scanf将丢弃. 如上图.
- PyCharm工具配置和快捷键使用
PyCharm是一款高效开发Python程序的IDE,包含有自动联想.语法高亮.代码调试.管理多个版本Python解释器等功能.本文主要描述Python界面个性化定制方法(字体.颜色配置).常用配置和 ...
- Linux应试技巧
前言:此文是为了CSP-S第二轮认证所用系统NOI-Linux的写的,但其他的Linux系统也可以按照相同或类似的方法进行配置. 配置NOI-Linux 我大约是一个月以前由于比赛的原因才开始接触NO ...
- 解惑:如何使用SecureCRT上传和下载文件、SecureFX乱码问题
解惑:如何使用SecureCRT上传和下载文件.SecureFX乱码问题 一.前言 很多时候在windows平台上访问Linux系统的比较好用的工具之一就是SecureCRT了,下面介绍一下这个软件的 ...
- DDR基础知识
1.前言 DDR的全称为Double Data Rate SDRAM,也就是双倍速率的SDRAM,SDRAM在一个CLK周期传输一次数据,而DDR在一个CLK周期传输两次数据,分别在上升沿和下降沿各传 ...
- 阿里云CentOS7.x安装nodejs及pm2
对之前文章的修订 您将了解 CentOS下如何安装nodejs CentOS下如何安装NVM CentOS下如何安装git CentOS下如何安装pm2 适用对象 本文档介绍如何在阿里云CentOS系 ...
- 【前端开发环境】前端使用GIT管理代码仓库需要掌握的几个必备技巧和知识点总结
1. Git的三种状态 已提交 committed 已暂存 staged 已修改 modified 2. Git的三个区域 Git仓库 是 Git 用来保存项目的元数据和对象数据库的地方. 这是 Gi ...
- [Flutter] 转一个Flutter学习思维导图
本文的思维导图均转自QQ群,感谢原作者(是谁?) 表单 按钮 视图 Sliver 路由 (Routes) 输入控件 对话框 MDC (Material Design Component) 状态管理 R ...
- WPF-如何添加用户控件(同一个程序集与非同一个程序集)
在WPF中,假如十个按钮与十个文本框需要在窗体中多次使用,每次都都要重新添加这二十个按钮,显然是不可取的.这时,可以把这二十个按钮封装成一个UserControl,然后多次引用. 一.新建一个用户控件 ...
- WPF两个按钮来回切换样式
<!-- 两个按钮来回切换样式 --> <Style x:Key="SwicthFunctionMetroToggleButton" TargetType=&qu ...