requests模块 简单使用
requests模块 简单使用
Anaconda简单了解
- Anaconda是一个集成环境(基于机器学习和数据分析的开发环境)
- 基于浏览器的一种可视化开发工具:jupyter notebook
- 可以在指定目录的终端中录入jupyter notebook指令,然后启动服务。
- cell是分为不同模式的:
- Code:编写python代码
- markDown:编写笔记
- 快捷键:
- 添加cell:a,b
- 删除cell:x
- 执行:shift+enter
- tab:缩进4个空格
- 切换cell的模式:
- m
- y
- 打开帮助文档:shift+tab
简单了解 requests模块
- 什么是requests模块?
- Python中封装好的一个基于网络请求的模块。
- requests模块的作用?
- 用来模拟浏览器发请求
- requests模块的环境安装:
- pip install requests
- requests模块的编码流程:
- 1.指定url
- 2.发起请求
- 3.获取响应数据
- 4.持久化存储
使用requests模块 爬取搜狗首页源码数据
#爬取搜狗首页的页面源码数据
import requests
#1.指定url
url = 'https://www.sogou.com/'
#2.请求发送get:get返回值是一个响应对象
response = requests.get(url=url)
#3.获取响应数据
page_text = response.text #返回的是字符串形式的响应数据
#4.持久化存储
with open('sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
实现一个简易的网页采集器
#实现一个简易的网页采集器 爬取搜狗搜索结果
#需要让url携带的参数动态化
import requests
url = 'https://www.sogou.com/web'
#实现参数动态化
wd = input('enter a key:')
params = {
'query':wd
}
#在请求中需要将请求参数对应的字典作用到params这个get方法的参数中
response = requests.get(url=url,params=params)
page_text = response.text
fileName = wd+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
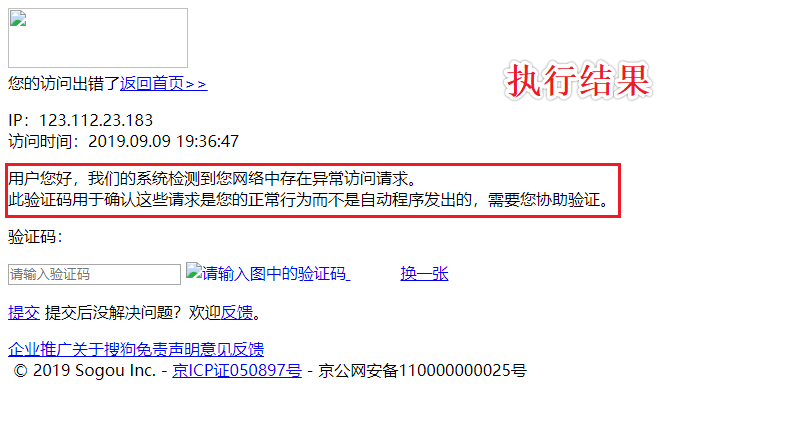
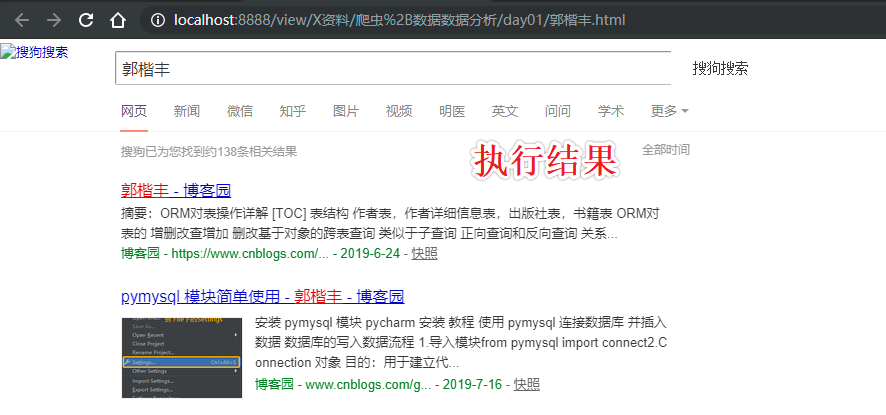
#执行结果
#输入 enter a key:郭楷丰
上述代码执行后发现:
1.出现了乱码
2.数据量级不对
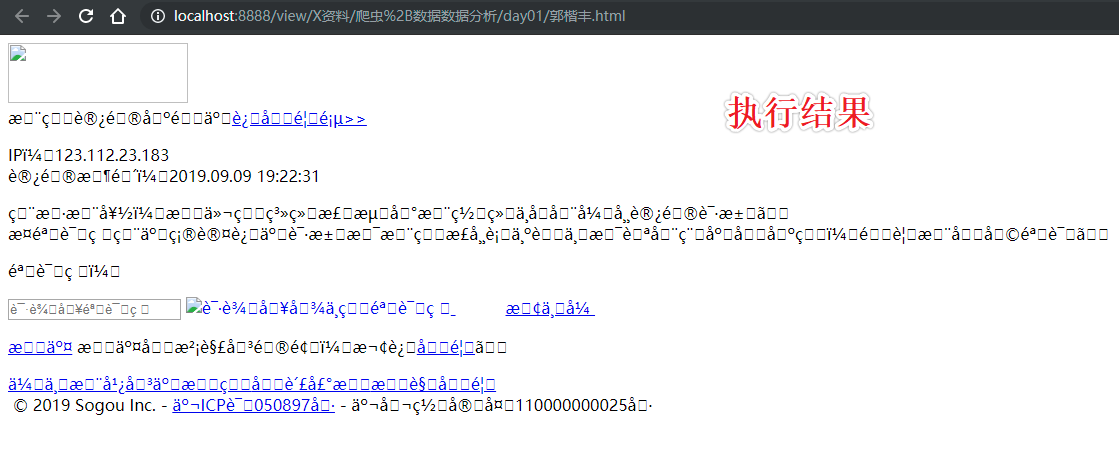
解决乱码问题
import requests
url = 'https://www.sogou.com/web'
#实现参数动态化
wd = input('enter a key:')
params = {
'query':wd
}
#在请求中需要将请求参数对应的字典作用到params这个get方法的参数中
response = requests.get(url=url,params=params)
response.encoding = 'utf-8' #修改响应数据的编码格式
page_text = response.text
fileName = wd+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
#执行结果
enter a key:jay
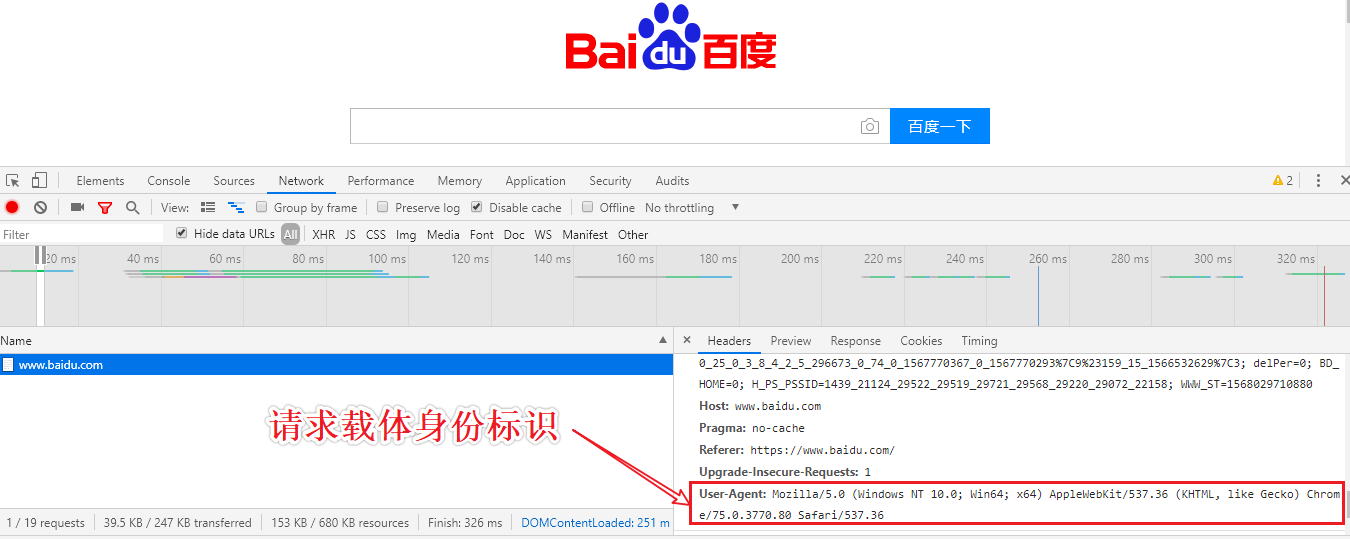
UA检测:门户网站通过检测请求载体的身份标识判定改请求是否为爬虫发起的请求
UA伪装:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36
解决UA检测问题
import requests
url = 'https://www.sogou.com/web'
#实现参数动态化
wd = input('enter a key:')
params = {
'query':wd
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
#在请求中需要将请求参数对应的字典作用到params这个get方法的参数中
response = requests.get(url=url,params=params,headers=headers)
response.encoding = 'utf-8' #修改响应数据的编码格式
page_text = response.text
fileName = wd+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
UA检测 是一种反爬机制,判断访问是否合法
requests模块 爬取豆瓣电影的详情数据
#爬取的是豆瓣电影中电影的详情数据
https://movie.douban.com/typerank?type_name=%E7%88%B1%E6%83%85&type=13&interval_id=100:90&action=
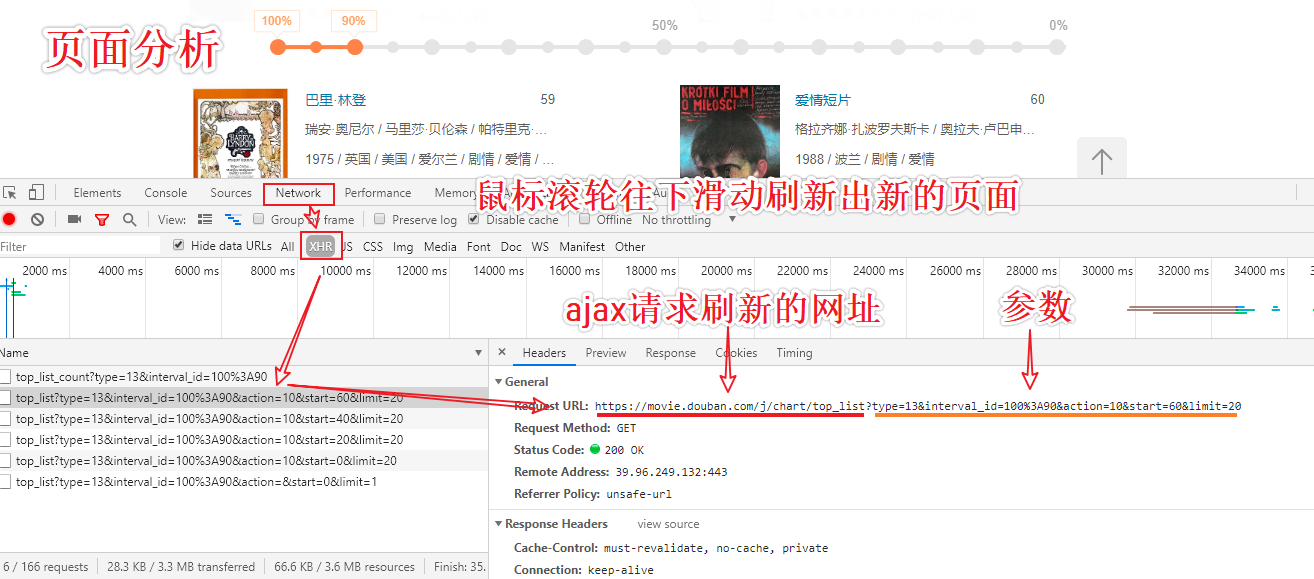
#分析:当滚动条被滑动到页面底部的时候,当前页面发生了局部刷新(ajax的请求)
动态加载的页面数据
- 是通过另一个单独的请求请求到的数据
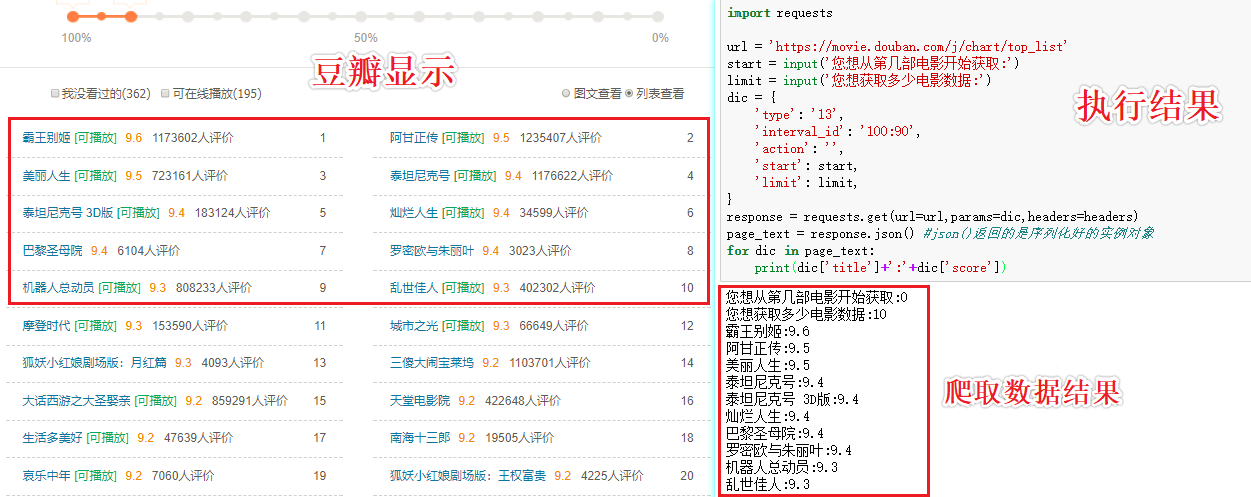
import requests
url = 'https://movie.douban.com/j/chart/top_list'
start = input('您想从第几部电影开始获取:')
limit = input('您想获取多少电影数据:')
dic = {
'type': '13',
'interval_id': '100:90',
'action': '',
'start': start,
'limit': limit,
}
response = requests.get(url=url,params=dic,headers=headers)
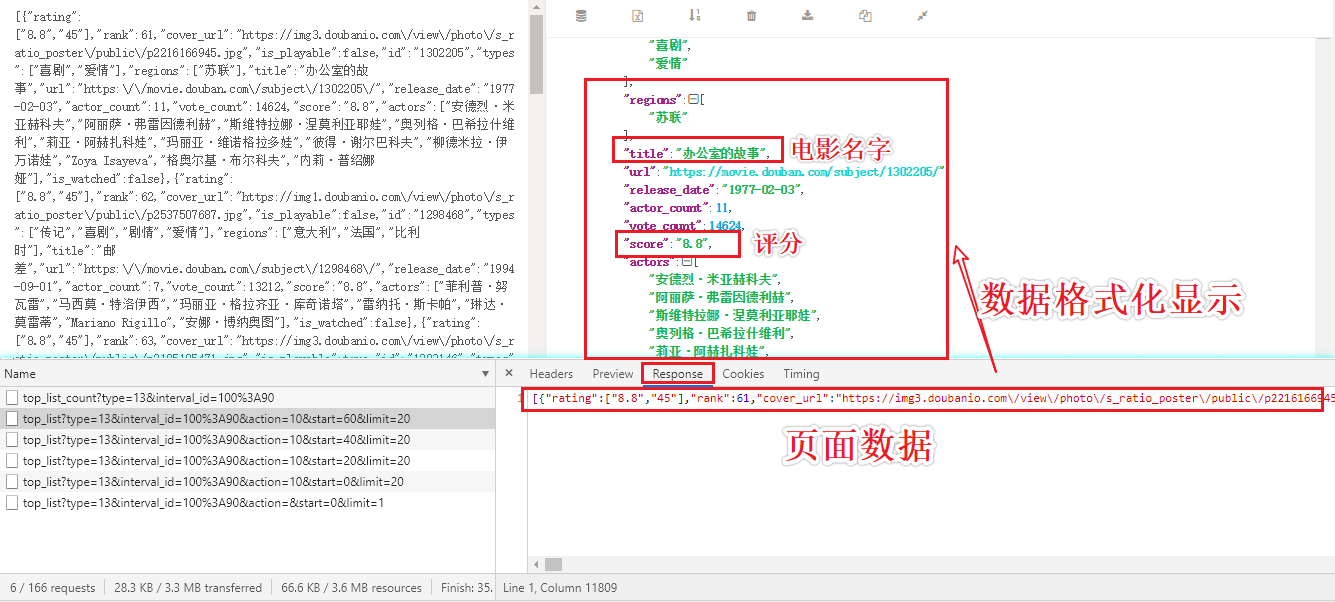
page_text = response.json() #json()返回的是序列化好的实例对象
for dic in page_text:
print(dic['title']+':'+dic['score'])
页面分析流程
requests模块 爬取肯德基餐厅查询结果
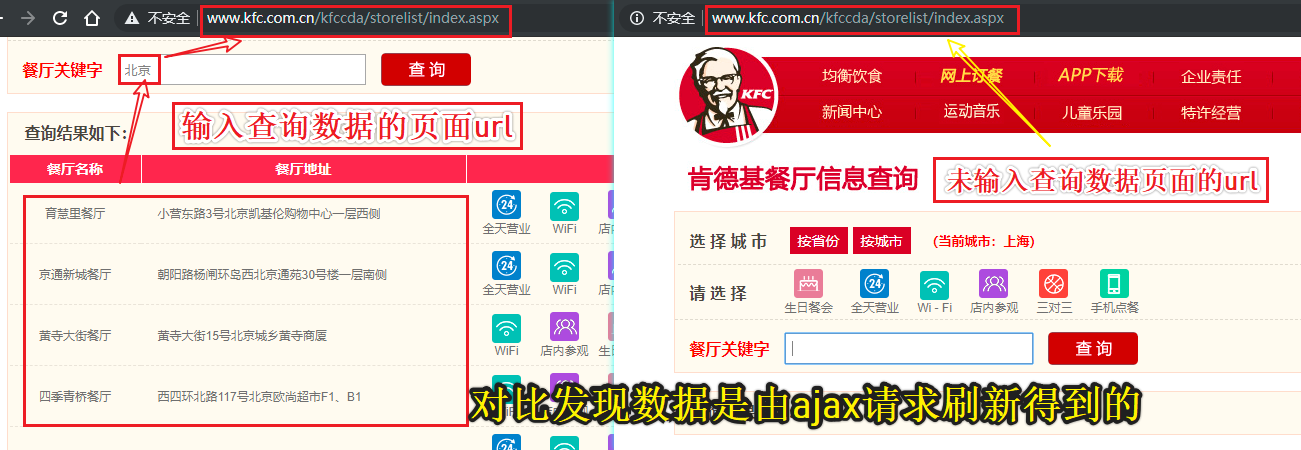
#肯德基餐厅查询http://www.kfc.com.cn/kfccda/storelist/index.aspx
import requests
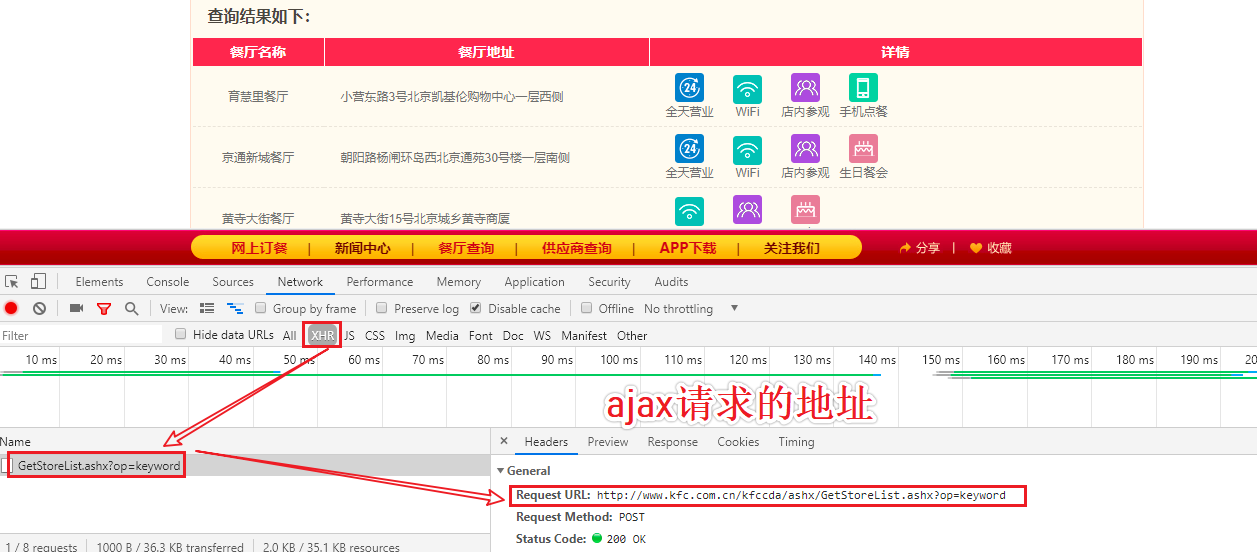
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
for page in range(1,2):
data = {
'cname': '',
'pid': '',
'keyword': '西安',
'pageIndex': str(page),
'pageSize': '5',
}
response = requests.post(url=url,headers=headers,data=data)
print(response.json())
分析页面
爬取数据
{
'Table': [{
'rowcount': 33
}],
'Table1': [{
'rownum': 1,
'storeName': '东大街(西安)',
'addressDetail': '东大街53号',
'pro': '24小时,Wi-Fi,点唱机,礼品卡',
'provinceName': '青海省',
'cityName': '西宁市'
}, {
'rownum': 2,
'storeName': '同安',
'addressDetail': '同安区西安路西安广场一层二层',
'pro': '24小时,Wi-Fi,点唱机,礼品卡,生日餐会',
'provinceName': '福建省',
'cityName': '厦门市'
}, {
'rownum': 3,
'storeName': '成义',
'addressDetail': '西安路60号民勇大厦一楼',
'pro': '24小时,Wi-Fi,点唱机,店内参观,礼品卡',
'provinceName': '辽宁省',
'cityName': '大连市'
}, {
'rownum': 4,
'storeName': '罗斯福',
'addressDetail': '西安路139号1号',
'pro': 'Wi-Fi,点唱机,店内参观,礼品卡',
'provinceName': '辽宁省',
'cityName': '大连市'
}, {
'rownum': 5,
'storeName': '贺兰山(西安)',
'addressDetail': '游艺东街6号一层',
'pro': '24小时,Wi-Fi,店内参观,礼品卡,生日餐会',
'provinceName': '宁夏',
'cityName': '石嘴山市'
}]
}
#可以根据自己需求,获取想要的数据
爬取药监总局中相关企业的详情信息
需求
- 爬取药监总局中相关企业的详情信息http://125.35.6.84:81/xk/ 获取企业名和法人
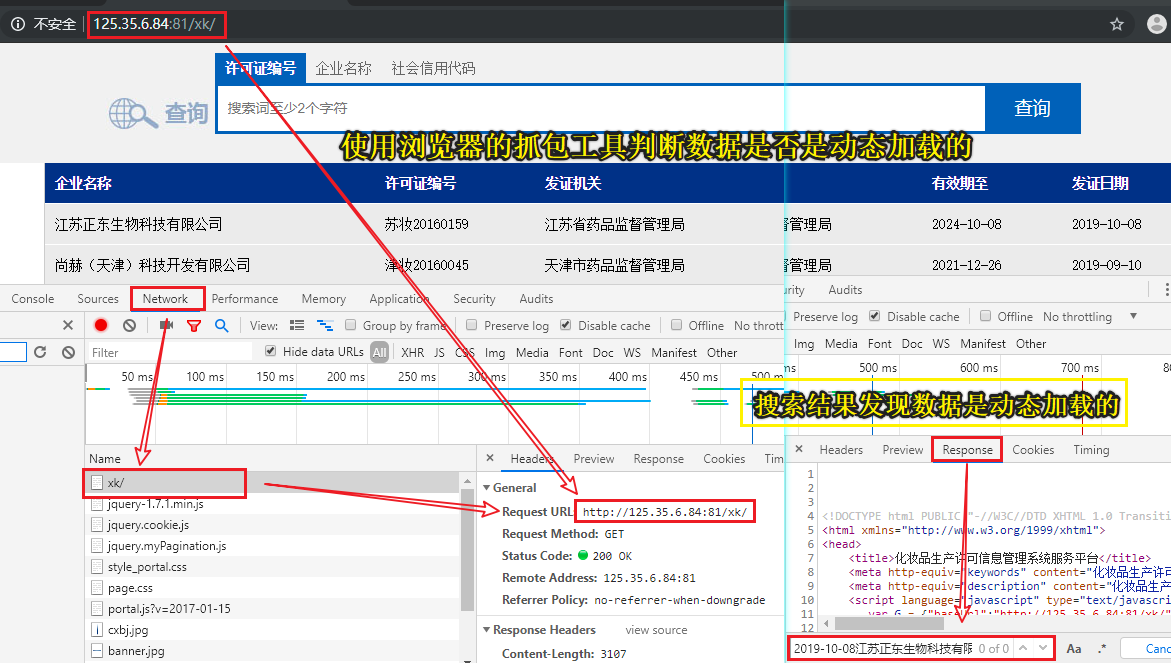
- 需求分析
- 确定页面中企业相关数据是否为动态加载?
- 相关的企业信息是动态加载出来的
- 通过抓包工具实现全局搜索,定位动态加载数据对应的数据包!
- post:http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList
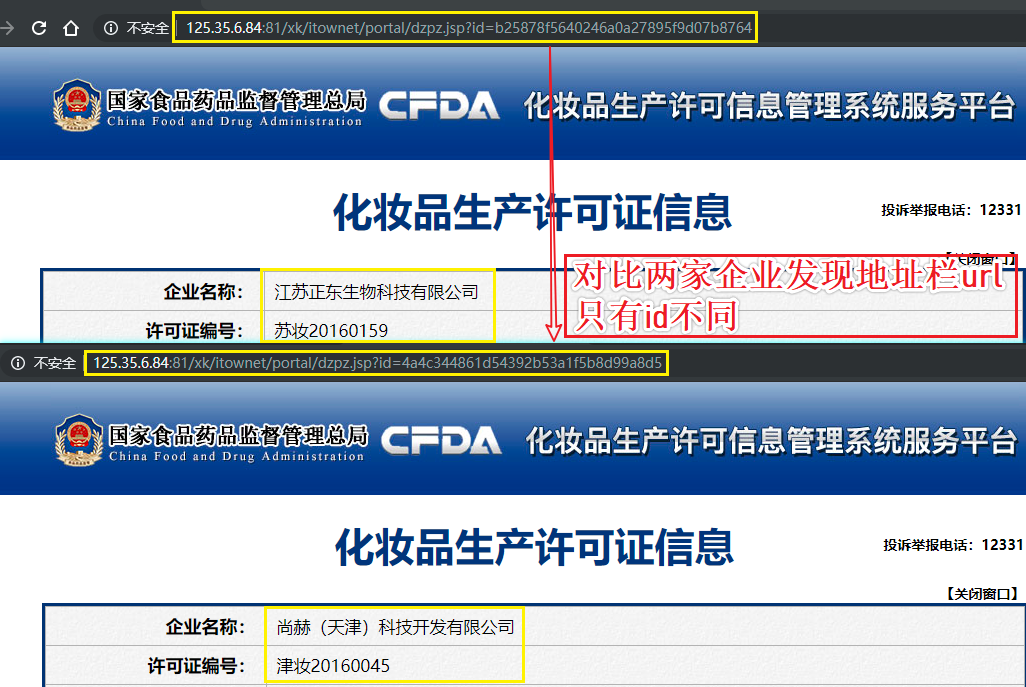
- 该请求返回的响应数据是一组json串,通过对json串的一个简单分析,没有找到企业详情页的url,但是找到个每一家企业的id
- 每一家企业详情页的url,域名都是一样的,只有请求参数id值不同
- 可以使用同一个域名结合着不同企业的id值拼接成一家完整企业详情页url
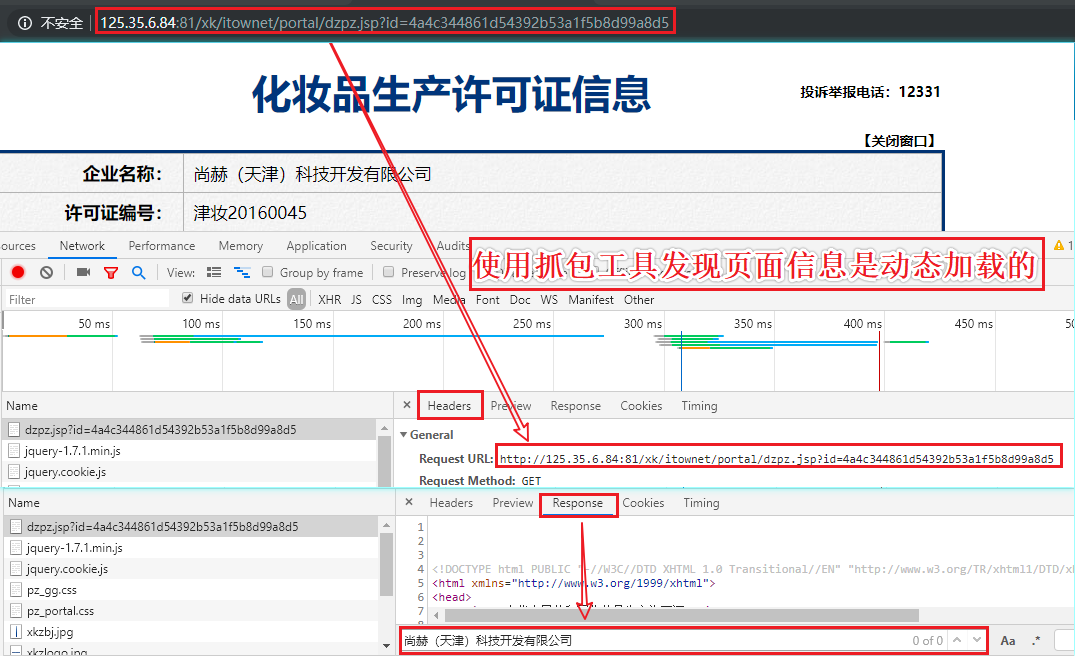
- 判断企业详情页中的数据是否为动态加载?
- 通过抓包工具检测,发现企业详情信息在详情页中为动态加载的数据
- 通过抓包工具实现全局搜索定位动态加载数据对应的数据包
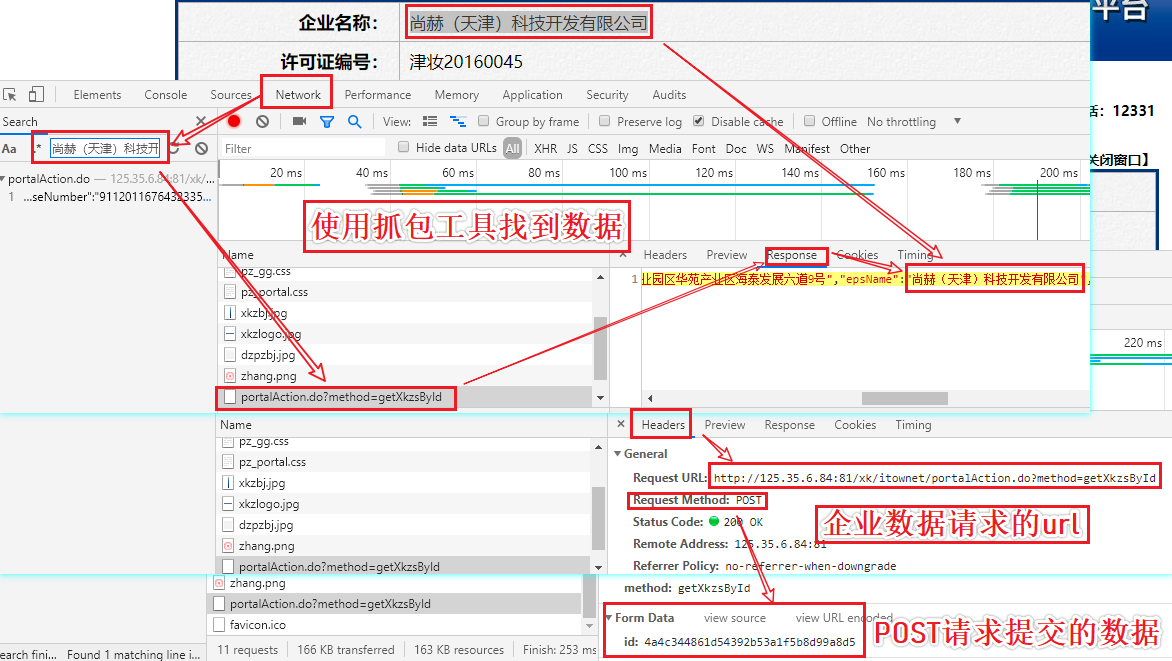
- post-url:http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById
- 请求参数:id=xxxxx
- 请求到的json串就是我们最终想要的企业详情信息数据
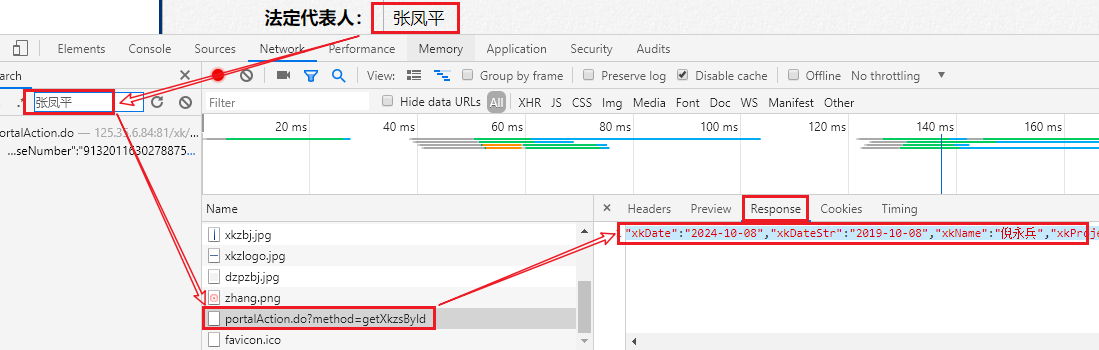
#数据格式化显示
{
"businessLicenseNumber": "91320116302788753R",
"businessPerson": "张凤平",
"certStr": "一般液态单元(啫喱类、护发清洁类、护肤水类);膏霜乳液单元(护发类、护肤清洁类);粉单元(浴盐类)",
"cityCode": "",
"countyCode": "",
"creatUser": "",
"createTime": "",
"endTime": "",
"epsAddress": "南京市江北新区中山科技园科创大道9号B3栋一层",
"epsName": "江苏正东生物科技有限公司",
"epsProductAddress": "南京市江北新区中山科技园科创大道9号B3栋一层",
"id": "",
"isimport": "N",
"legalPerson": "张凤平",
"offDate": "",
"offReason": "",
"parentid": "",
"preid": "",
"processid": "20190620105304202w1ugs",
"productSn": "苏妆20160159",
"provinceCode": "",
"qfDate": "",
"qfManagerName": "江苏省药品监督管理局",
"qualityPerson": "高光辉",
"rcManagerDepartName": "江苏省药品监督管理局南京检查分局",
"rcManagerUser": "史祖如、杨敏",
"startTime": "",
"xkCompleteDate": null,
"xkDate": "2024-10-08",
"xkDateStr": "2019-10-08",
"xkName": "倪永兵",
"xkProject": "",
"xkRemark": "",
"xkType": "202"
}
代码
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36"
}
#获取每一家企业的id
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
for page in range(1,3):
print('正在爬取第{}页的数据......'.format(page))
data = {
'on': 'true',
'page': str(page),
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn':'',
}
company_data = requests.post(url,headers=headers,data=data).json()
for dic in company_data['list']:
_id = dic['ID']
detail_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById'
data = {
'id':_id
}
detail_data = requests.post(url=detail_url,data=data,headers=headers).json()
print(detail_data['epsName'],detail_data['legalPerson'])
#爬取结果
正在爬取第1页的数据......
江苏正东生物科技有限公司 张凤平
尚赫(天津)科技开发有限公司 陈旻君
天津施文化妆品有限公司 Tomas Espinosa Braniff Cespedes
天津天狮生物工程有限公司 李宝娥
江苏西宏生物医药有限公司 张新明
广州唯妍汇生物科技有限公司 谢梅宣
广州医美堂生物技术有限公司 李海燕
佰草世家生物科技(佛山)有限公司 唐其建
广州市白云区大荣精细化工有限公司 胡志标
佛山市南海区丹喜露日用护理品有限公司 黄彦淳
广州市碧莹化妆品有限公司 郭正梅
广州市阿西娜化妆品制造有限公司 廖翠琴
扬州扬大联环药业基因工程有限公司 吴文格
江苏易佳洁化妆品有限公司 陈飞
广东审美生物科技有限公司 温武泉
正在爬取第2页的数据......
东莞市至纯生物科技有限公司 罗仁华
恩平安益日化有限公司 张维新
中万恩(佛山)科技有限公司 杨军
福建绿植源生化科技有限公司 陈祥斌
帆艳华(广州)生物科技有限公司 白石华
广东省佛山市顺德区仙渡化妆品有限公司 贺丽
佛山市顺德信元生物科技有限公司 毛昭庆
广州柏灡化妆品有限公司 彭凤兰
广州中品生物科技有限公司 丁琳凤
广州中草集化妆品有限公司 许明良
广州市佳桐化妆品有限公司 吴辉军
新疆西法伊欧丝玛环保科技有限公司 热洋古丽·卡得
襄阳市杨四郎生物科技有限公司 杨华傲
广西湾昊生物科技有限公司 黄祖源
广州婵妍生物科技有限公司 王旭光
requests 与 urllib 简单爬取图片
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
#如何爬取图片
url = 'http://pic.netbian.com/uploads/allimg/180222/231102-151931226201f1.jpg'
img_data = requests.get(url,headers=headers).content #byte类型数据
with open('mv.jpg','wb') as fp:
fp.write(img_data)
#代码较多

from urllib import request
url = 'http://pic.netbian.com/uploads/allimg/190902/204822-156742850260f4.jpg'
request.urlretrieve(url,filename='mv2.jpg')
#代码少,但不能使用UA伪装

分析+总结
#如何根据需求分析
- 如何检测页面中是否存在动态加载的数据?
- 基于抓包工具实现
- 先捕获网站请求后所有的数据包
- 在数据包中定位到地址栏所对应请求的数据包,在response选项卡对应的数据中进行局部搜索(页面中的某一组内容)
- 可以搜索到:爬取的数据不是动态加载的
- 没有搜索到:爬取的数据是动态加载的
- 如何定位动态加载的数据在哪个数据包中呢?
- 进行全局搜索
#总结补充:
- requests作用:模拟浏览器发起请求
- urllib:requests的前身
- requests模块的编码流程:
- 指定url
- 发起请求:
- get(url,params,headers)
- post(url,data,headers)
- 获取响应数据
- 持久化存储
- 参数动态化:
- 有些情况下我们是需要将请求参数进行更改。将get或者post请求对应的请求参数封装到一个字典(键值对==请求参数)中,
然后将改字典作用到get方法的params参数中或者作用到psot方法的data参数中
- UA检测(反爬机制):
- 什么是UA:请求载体的身份标识。服务器端会检测请求的UA来鉴定其身份。
- 反反爬策略:UA伪装。通过抓包工具捕获某一款浏览器的UA值,封装到字典中,且将该字典作用到headers参数中
- 动态加载的数据
- 通过另一个单独的请求请求到的数据
- 如果我们要对一个陌生的网站进行指定数据的爬取?
- 首先要确定爬取的数据在改网站中是否为动态加载的
- 是:通过抓包工具实现全局搜索,定位动态加载数据对应的数据包,从数据包中提取请求的url和请求参数。
- 不是:就可以直接将浏览器地址栏中的网址作为我们requests请求的url
requests模块 简单使用的更多相关文章
- Python requests模块学习笔记
目录 Requests模块说明 Requests模块安装 Requests模块简单入门 Requests示例 参考文档 1.Requests模块说明 Requests 是使用 Apache2 Li ...
- Python高手之路【八】python基础之requests模块
1.Requests模块说明 Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 ...
- 进程、requests模块的简单使用
一.进程 1.进程间数据不共享 import multiprocessing data_list = [] def task(arg): data_list.append(arg) print(dat ...
- python爬虫:爬虫的简单介绍及requests模块的简单使用
python爬虫:爬虫的简单介绍及requests模块的简单使用 一点点的建议: (学习爬虫前建议先去了解一下前端的知识,不要求很熟悉,差不多入门即可学习爬虫,如果有不了解的,我也会补充个一些小知识. ...
- 超级简单的requests模块教程
在web后台开发过程中,会遇到需要向第三方发送http请求的场景,python中的requests库可以很好的满足这一要求,这里简要记录一下requests模块的使用! 说明: 这里主要记录一下req ...
- 爬虫requests模块 1
让我们从一些简单的示例开始吧. 发送请求¶ 使用 Requests 发送网络请求非常简单. 一开始要导入 Requests 模块: >>> import requests 然后,尝试 ...
- requests 模块
发送请求 使用Requests发送网络请求非常简单. 一开始要导入Requests模块: >>> import requests 然后,尝试获取某个网页.本例子中,我们来获取Gith ...
- [实战演练]python3使用requests模块爬取页面内容
本文摘要: 1.安装pip 2.安装requests模块 3.安装beautifulsoup4 4.requests模块浅析 + 发送请求 + 传递URL参数 + 响应内容 + 获取网页编码 + 获取 ...
- 爬虫之requests模块
requests模块 什么是requests模块 requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求.功能强大,用法简洁高效.在爬虫领域中占据着半壁江山的 ...
随机推荐
- 错误: -source 1.6 中不支持 diamond 运算符
问题 错误: -source 1.6 中不支持 diamond 运算符 解决步骤 1.检查ide的默认编译环境 ,快捷键ctrl + alt +s 找Java Compiler ,发现设置是 Targ ...
- 使用create-react-app遇到问题解决方案汇总
使用create-react-app时遇到Module not found问题 转 https://blog.csdn.net/wkq_1212/article/details/90291558 本来 ...
- 几个支持 FreeSWITCH 的网络电话的安装与使用(linphone、MicroSIP、Sipdroid)
Ubuntu 安装 Linphone 安装命令 apt-get install linphone 安装完成后,在应用程序 --> 互联网 下就能看到 linphone,打开后注册 注意:linp ...
- node 报错 env: node\r: No such file or directory
最近在编写一个命令行工具.使用 npm link 时可以正常运行.但是 ctrl+s 保存后, 再运行则报错 env: node\r: No such file or directory ,需要再 n ...
- 映美FP-530K+打印发票的各种经验
本人虽然写了很多lodop博文,但是程序开发一般都是用虚拟打印机测试,实际打印机打印中还可能存在各种问题,毕竟理论都不如实践能获得更多的打印经验.当个人使用过的打印机不多,只有映美FP-530K+,用 ...
- [LeetCode] 203. Remove Linked List Elements 移除链表元素
Remove all elements from a linked list of integers that have value val. ExampleGiven: 1 --> 2 --& ...
- OpenJudge 4120 硬币
总时间限制: 1000ms 内存限制: 262144kB 描述 宇航员Bob有一天来到火星上,他有收集硬币的习惯.于是他将火星上所有面值的硬币都收集起来了,一共有n种,每种只有一个:面值分别为a1,a ...
- ztree取消之前选中状态并设置新的选中
var zTreeObject = $.fn.zTree.getZTreeObj("treeId"); var node = zTreeObject.getNodeByParam( ...
- 前端HTML学习心得
学习最好的效果就是理论加实践--Hanks!!!(给大家打鸡血的哈哈哈) 前面的学习我教大家怎么搭建简单的前端开发环境,现在我教大家怎么使用工具学习(从入门到放弃哈哈,不不不,这是以前的我,现在我下了 ...
- R统计数据框的行数
如下三种方法可以实现 使用dim函数 dim(dataframe)[0] 使用nrow函数 nrow(dataframe) 使用length函数统计 length(dataframe[,1])