MySQL分组查询每组最新的一条数据(通俗易懂)
开发中经常会遇到,分组查询最新数据的问题,比如下面这张表(查询每个地址最新的一条记录):

sql如下:
-- ----------------------------
-- Table structure for test
-- ----------------------------
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`address` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`create_time` timestamp(0) NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 13 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ----------------------------
-- Records of test
-- ----------------------------
INSERT INTO `test` VALUES (1, '张三1', '北京', '2019-09-10 11:22:23');
INSERT INTO `test` VALUES (2, '张三2', '北京', '2019-09-10 12:22:23');
INSERT INTO `test` VALUES (3, '张三3', '北京', '2019-09-05 12:22:23');
INSERT INTO `test` VALUES (4, '张三4', '北京', '2019-09-06 12:22:23');
INSERT INTO `test` VALUES (5, '李四1', '上海', '2019-09-06 12:22:23');
INSERT INTO `test` VALUES (6, '李四2', '上海', '2019-09-07 12:22:23');
INSERT INTO `test` VALUES (7, '李四3', '上海', '2019-09-11 12:22:23');
INSERT INTO `test` VALUES (8, '李四4', '上海', '2019-09-12 12:22:23');
INSERT INTO `test` VALUES (9, '王二1', '广州', '2019-09-03 12:22:23');
INSERT INTO `test` VALUES (10, '王二2', '广州', '2019-09-04 12:22:23');
INSERT INTO `test` VALUES (11, '王二3', '广州', '2019-09-05 12:22:23');
平常我们会进行按照时间倒叙排列然后进行分组,获取每个地址的最新记录,sql如下:
SELECT * FROM(SELECT * FROM test ORDER BY create_time DESC) a GROUP BY address
但是查询结果却不是我们想要的:

执行时间按倒叙排列结果为:
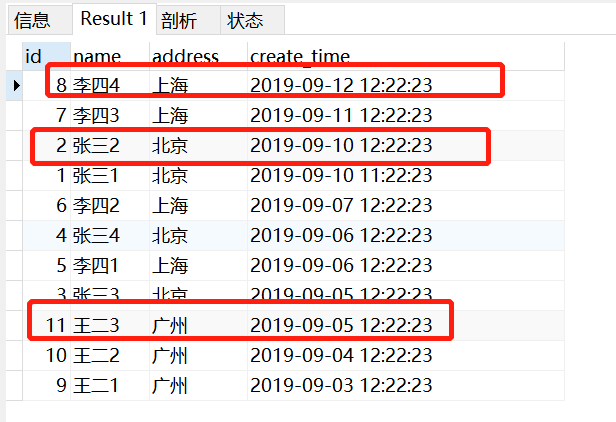
所以真正想要得到的结果是id为2/8/11的记录,上面的查询得到的却是1/5/9,这是为什么呢?
因为在mysql5.7的时候,子查询的排序已经变为无效了,可能是因为子查询大多数是作为一个结果给主查询使用,所以子查询不需要排序的原因。
那么我们应该怎么查呢,有两种方式:
第一种:
SELECT * FROM(SELECT * FROM test ORDER BY create_time DESC LIMIT 10000) a GROUP BY address
结果为:
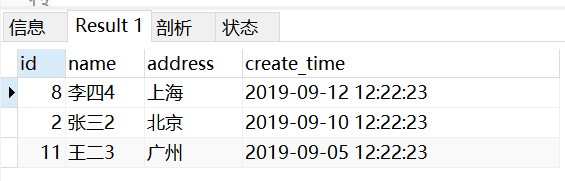
对子查询的排序进行limit限制,此时子查询就不光是排序,所以此时排序会生效,但是限制条数却只能尽可能的设置大些
第二种:
SELECT t.* FROM (SELECT address,max(create_time) as create_time FROM test GROUP BY address) a LEFT JOIN test t ON t.address=a.address and t.create_time=a.create_time
通过MAX函数获取最新的时间和地址(因为需要按照地址分组),然后作为一张表和原来的数据进行联查,
条件就是地址和时间要和获取的最大时间和地址相等,此时结果为:

这两种方式的查询效率差不太多,第二种比第一种查询稍微快一点,可能是由于第二种方式的子查询只有两个字段(时间,被分组字段)的缘故吧!
感兴趣的可以照一张字段多的数据量大的表查询一下比较比较。
PS:第二种方式中最新的记录,不能同时地点和时间都相同,如果出现这种情况,第二种方式会查出把这两条记录都查出来,而第一条不会。
所以根据业务和数据情况来选择其中一种方式,毕竟效率差不太多。
MySQL分组查询每组最新的一条数据(通俗易懂)的更多相关文章
- mysql分组查询获取组内某字段最大的记录
id sid cid 1 1 12 1 23 2 1 以sid分组,最后取cid最大的那一条,以上要取第2.3条 1 方法一: select * from (select * from table o ...
- MySQL分组查询获取每个学生前n条分数记录(分组查询前n条记录)
CREATE TABLE `t_test` ( `id` ) NOT NULL AUTO_INCREMENT, `stuid` ) NOT NULL, `score` ) DEFAULT NULL, ...
- mysql 分组查询
mysql 分组查询 获取id最大的一条 (1)分组查询获取最大id SELECT MAX(id) as maxId FROM `d_table` GROUP BY `parent_id` ; (2) ...
- Oracle和MySQL分组查询GROUP BY
Oracle和MySQL分组查询GROUP BY 真题1.Oracle和MySQL中的分组(GROUP BY)有什么区别? 答案:Oracle对于GROUP BY是严格的,所有要SELECT出来的字段 ...
- sql 分组取每组的前n条或每组的n%(百分之n)的数据
sql 分组取每组的前n条或每组的n%(百分之n)的数据 sql keyword: SELECT * ,ROW_NUMBER() OVER(partition by b.UserID order by ...
- 转: 从Mysql某一表中随机读取n条数据的SQL查询语句
若要在i ≤ R ≤ j 这个范围得到一个随机整数R ,需要用到表达式 FLOOR(i + RAND() * (j – i + 1)).例如, 若要在7 到 12 的范围(包括7和12)内得到一个随机 ...
- Mysql 保留最新的10条数据
Mysql每天执行计划,保留最新的10条数据,其余的删除 1.Mysql 保留最新的10条数据 sql语句: DELETE tb FROM tbname AS tb,( SELECT id FROM ...
- sql 查询某个条件多条数据中最新的一条数据或最老的一条数据
sql 查询某个条件下多条数据中最新的一条数据或最老的一条数据 test_user表结构如下: 需求:查询李四.王五.李二创建的最初时间或者最新时间 1:查询最初的创建时间: SELECT * FRO ...
- 从Mysql某一表中随机读取n条数据的SQL查询语句
若要在i ≤ R ≤ j 这个范围得到一个随机整数R ,需要用到表达式 FLOOR(i + RAND() * (j – i + 1)).例如, 若要在7 到 12 的范围(包括7和12)内得到一个随机 ...
随机推荐
- SoapUI: 设置case的属性变量
琐碎的东西也想一点一滴的记下来
- ES6 - 函数扩展(函数参数默认值)
函数参数默认值 ES6 之前,不能直接为函数的参数指定默认值,只能采用变通的方法. function log(x, y) { y = y || 'World'; console.log(x, y); ...
- postgre with递归查询组织路径
with递归查询组织路径 SELECT r.id, (array_to_string( array( select name from ( with recursive rec as( select ...
- fiddler抓包详解
image.png 前言 fiddler是一个很好的抓包工具,默认是抓http请求的,对于pc上的https请求,会提示网页不安全,这时候需要在浏览器上安装证书. 一.网页不安全 1.用fiddler ...
- Spring Cloud(一)简单的微服务集成Eureka
1 Spring Cloud简介 1.1 简介 Spring Cloud项目的官方网址:https://projects.spring.io/spring-clo ...
- LeetCode 559. Maximum Depth of N-ary Tree(N-Tree的深度)
Given a n-ary tree, find its maximum depth. The maximum depth is the number of nodes along the longe ...
- Java中遍历ConcurrentHashMap的四种方式
//方式一:在for-each循环中使用entries来遍历 System.out.println("方式一:在for-each循环中使用entries来遍历"); for(Map ...
- .net for TCP服务端 && 客户端
关键代码 详细代码请看示例代码 Service //创建套接字 IPEndPoint ipe = new IPEndPoint(IPAddress.Parse(ipaddress), port); / ...
- PAt 1099
1099 Build A Binary Search Tree (30 分) A Binary Search Tree (BST) is recursively defined as a bina ...
- poj1458公共子序列 C语言
/*Common SubsequenceTime Limit: 1000MS Memory Limit: 10000KTotal Submissions: 56416 Accepted: 23516D ...