【RS】Wide & Deep Learning for Recommender Systems - 广泛和深度学习的推荐系统
【论文标题】Wide & Deep Learning for Recommender Systems (DLRS'16)
【论文作者】
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra,
Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil,
Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, Hemal Shah
—— Google Inc.
【论文链接】Paper(4-pages // Double column)
(FY内容待check)
【摘要】
线性模型被广泛地应用于回归和分类问题,具有简单、快速和可解释性等优点,但是线性模型的表达能力有限,经常需要人工选择特征和交叉特征才能取得一个良好的效果,但是实际工程中的特征数量会很多,并且还会有大量的稀疏特征,人工筛选特征和交叉特征会很困难,尤其是交叉高阶特征时,人工很难实现。DNN模型可以很容易的学习到高阶特征之间的作用,并且具有很好的泛化能力。同时,DNN增加embedding层可以很容易的解决稀疏特征的问题。文章将传统的LR和DNN组合构成一个wide&deep模型,既保留了LR的拟合能力,又具有DNN的泛化能力,并且不需要单独训练模型,可以方便模型的迭代。
【关键词】
广泛和深度学习,推荐系统
【1 介绍】
1、Wide&Deep解决什么问题
在推荐系统(包括推荐、计算广告)中,当用户来到平台时,需要向用户展示适合用户的物品(商品、广告等),通常的做法是先从海量的物品库(通常是上亿数量)中,筛选出一些跟用户兴趣最相关的物品(通常是千级规模),这个过程叫做召回,召回可以是机器学习模型或者规则;然后再对这上千的物品进行排序,从而展示给用户。因此推荐系统也经常被叫做搜索排序系统。整个系统流程如图:
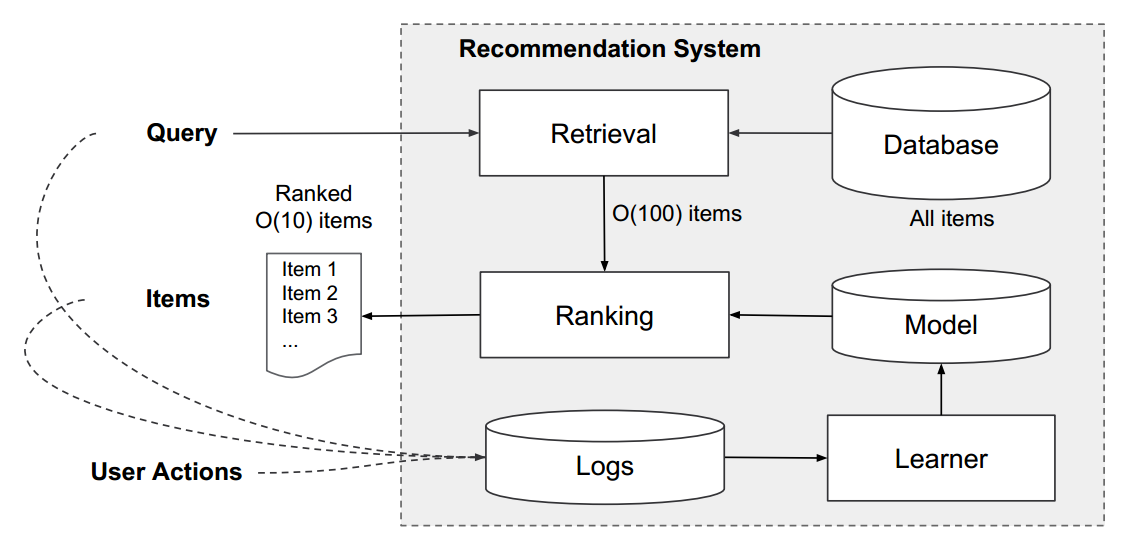
排序的规则有很多,主要是依据业务的目标而言,例如点击、购买等。wide&deep可以应用到此类目标的排序问题中,最经典的就是CTR预估。
2、现有模型的问题
提到CTR预估,最经典的应该是LR模型了,LR模型简单、快速并且模型具有可解释,有着很好的拟合能力,但是LR模型是线性模型,表达能力有限,泛化能力较弱,需要做好特征工程,尤其需要交叉特征,才能取得一个良好的效果,然后工业中,特征的数量会很多,可能达到成千上万,甚至数十万,这时特征工程就很难做,并且特征工程是一项很枯燥乏味的工作,搞得算法工程师晕头转向,还不一定能取得更好的效果。 DNN模型不需要做太精细的特征工程,就可以取得很好的效果,已经在很多领域开始应用了,DNN可以自动交叉特征,学习到特征之间的相互作用,尤其是可以学到高阶特征交互,具有很好的泛化能力。另外,DNN通过增加embedding层,可以有效的解决稀疏数据特征的问题,防止特征爆炸。推荐系统中的泛化能力是很重要的,可以提高推荐物品的多样性,但是DNN在拟合数据上相比较LR会较弱。 为了提高推荐系统的拟合性和泛化性,可以将LR和DNN结合起来,同时增强拟合能力和泛化能力,wide&deep就是将LR和DNN结合起来,wide部分就是LR,deep部分就是DNN,将两者的结果组合进行输出。
【3 Wide&Deep学习(模型)】
wide&deep模型主要分成两部分,wide部分就是传统的LR模型,deep部分就是DNN,整个模型的结构如下图:
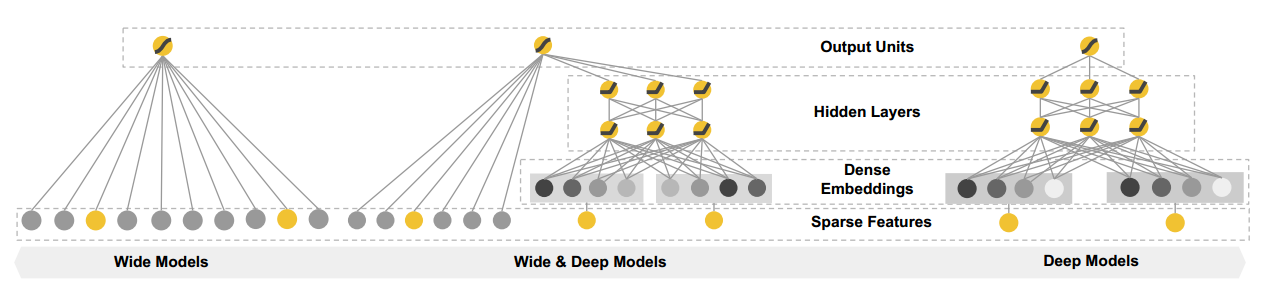
上图中最左边是传统的LR模型,最右边是DNN模型,中间的是将LR和DNN结合起来的wide&deep模型。
【3.1 Wide 部分】
wide部分就是LR模型,传统的LR模型:
用 X=[x1,x2,x3,...,xd] 表示一个有d个特征的样本,W=[w1,w2,w3,...,wd] 表示模型的参数,b表示bia,y表示预测值,有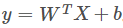
在实际中往往需要交叉特征,对于这部分定义如下: 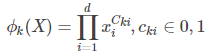
用 ϕk 表示第 k 个交叉特征,Cki 表示是第 k 个交叉特征的一部分。
最终的wide部分为:
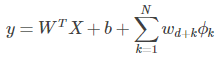
【3.2 Deep 部分】
deep部分就是一个普通的神经网络结构,只不过在这个网络中增加embedding层用来将稀疏、高维的特征转换为低维、密集的实数向量,可以有效地解决维度爆炸。先将原始特征经过embedding层转化后,再送入DNN的隐藏层,隐藏层之间的关系定义为:
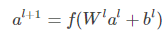
上面 l 表示隐藏层数,f 表示激活函数,可以是sigmoid、Relu、than等,目前最常用的是Relu函数。
【3.3 Wide & Deep 模型的融合训练】
wide&deep模型中,wide部分和deep部分是同时训练的,不需要单独训练任何一部分。GBDT+LR模型中GBDT需要先训练,然后再训练LR,两部分具有依赖关系,这种架构不利于模型的迭代。
Join training和ensemble training的区别:(1)ensemble中每个模型需要单独训练,并且各个模型之间是相互独立的,模型之间互相不感知,当预测样本时,每个模型的结果用于投票,最后选择得票最多的结果。而join train这种方式模型之间不是独立的,是相互影响的,可以同时优化模型的参数。(2)ensemble的方式中往往要求存在很多模型,这样就需要更多的数据集和数据特征,才能取得比较好的效果,模型的增多导致难以训练,不利于迭代。而在wide&deep中,只需要两个模型,训练简单,可以很快的迭代模型。
【4 系统实现】
目前Tensorflow中已经提供了wide&deep模型的API,参见 https://www.tensorflow.org/tutorials/wide_and_deep,并且官方提供了一个Demo,工程上可以很快的搭建起wide&deep模型。
【Reference】
1、https://blog.csdn.net/guozhenqiang19921021/article/details/80871641
2、GitHub的源码实现:https://github.com/tensorflow/models/tree/master/official/wide_deep
【RS】Wide & Deep Learning for Recommender Systems - 广泛和深度学习的推荐系统的更多相关文章
- Wide & Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems
- 【RS】A review on deep learning for recommender systems: challenges and remedies- 推荐系统深度学习研究综述:挑战和补救措施
[论文标题]A review on deep learning for recommender systems: challenges and remedies (Artificial Intell ...
- 【RS】Deep Learning based Recommender System: A Survey and New Perspectives - 基于深度学习的推荐系统:调查与新视角
[论文标题]Deep Learning based Recommender System: A Survey and New Perspectives ( ACM Computing Surveys ...
- 读《Deep Learning Tutorial》(台湾大学 李宏毅 深度学习教学ppt)后杂记
原ppt下载:pan.baidu.com/s/1nv54p9R,密码:3mty 需深入实践并理解的重要概念: Deep Learning: SoftMax Fuction(输出层归一化函数,与sigm ...
- Deep Learning Tutorial 李宏毅(一)深度学习介绍
大纲 深度学习介绍 深度学习训练的技巧 神经网络的变体 展望 深度学习介绍 深度学习介绍 深度学习属于机器学习的一种.介绍深度学习之前,我们先大致了解一下机器学习. 机器学习,拿监督学习为例,其本质上 ...
- Deep Learning系统实训之一:深度学习基础知识
K-近邻与交叉验证 1 选取超参数的正确方法是:将原始训练集分为训练集和验证集,我们在验证集上尝试不同的超参数,最后保留表现最好的那个. 2 如果训练数据量不够,使用交叉验证法,它能帮助我们在选取最优 ...
- [转]-[携程]-A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems
原文链接:推荐系统中基于深度学习的混合协同过滤模型 近些年,深度学习在语音识别.图像处理.自然语言处理等领域都取得了很大的突破与成就.相对来说,深度学习在推荐系统领域的研究与应用还处于早期阶段. 携程 ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- Wide & Deep Learning Model
Generalized linear models with nonlinear feature transformations (特征工程 + 线性模型) are widely used for l ...
随机推荐
- dotnet学习系列
这里整理下之前关于dotnet方面的文章索引. 一.dotnet core 系列 dotnet core 微服务教程 asp.net core 系列之并发冲突 asp.net core 系列之中间件进 ...
- C# 文件操作总结
一.需求分析 1.将信息记录到本地记事本中. 2.将记录的信息读取出来. 3.计算出某个文件夹下所有后缀名为txt的数量和dll的数量. 4.从网络上下载文件. 二.二话不说上代码 using Sys ...
- topshelf注册服务
1.需要从nutget上获取toshelf配置 2.代码 using Common.Logging; using Quartz; using Quartz.Impl; using System; us ...
- 架构师小跟班:教你从零开始申请和配置七牛云免费OSS对象存储(不能再详细了)
背景 之前为了练习Linux系统使用,在阿里云上低价买了一台服务器(网站首页有活动链接,传送门),心里想反正闲着也是闲着,就放了一个网站上去.现在随着数据越来越多,服务器空间越来越吃紧,我就考虑使用七 ...
- elementUI,设置日期,只能选择今天和今天以后的, :picker-options="pickerOptions"
1. html 加 :picker-options="pickerOptions" <el-date-picker v-model="shop.receive_ti ...
- Python 的版本控制
版本控制工具的差异 这里介绍几个工具:pyenv.pyvenv. venv.virtualenv.pyenv-virtualenv virtualenv 是针对python的包的多版本管理,通过将py ...
- Jupyter notebook 添加或删除内核
1.切换到要添加的虚拟环境,确认是否安装 ipykernel python -m ipykernel --version 如果没有安装,则安装: python -m pip install ipyke ...
- django模板中的extends和include使用方法
一.extends使用方法 首先extends也就是继承,子类继承父类的一些特性.在django模板中通过继承可以减少重复代码. 首先我们建立一个app,名字叫做hello.别忘了在settings. ...
- vs2008 新建win32控制台程序提示:脚本错误
解决方案: 1.根据错误信息中的url,找到对应文件夹下的htm文件 2.使用notepad++打开default.htm文件,找到错误提示的434行,注释掉433和434行 然后保存文件,重新新建w ...
- Linux使用rz命令上传文件
1.安装 yum -y install lrzsz 2.rz -be命令,选择需要上传的本地文件