第2章 K近邻算法
numpy中的tile函数:
遇到numpy.tile(A,(b,c))函数,重复复制A,按照行方向b次,列方向c次。
>>> import numpy
>>> numpy.tile([0,0],5)#在列方向上重复[0,0]5次,默认行1次
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
>>> numpy.tile([0,0],(1,1))#在列方向上重复[0,0]1次,行1次
array([[0, 0]])
>>> numpy.tile([0,0],(2,1))#在列方向上重复[0,0]1次,行2次
array([[0, 0],
[0, 0]])
>>> numpy.tile([0,0],(3,1))
array([[0, 0],
[0, 0],
[0, 0]])
>>> numpy.tile([0,0],(1,3))#在列方向上重复[0,0]3次,行1次
array([[0, 0, 0, 0, 0, 0]])
>>> numpy.tile([0,0],(2,3))<span style="font-family: Arial, Helvetica, sans-serif;">#在列方向上重复[0,0]3次,行2次</span>
array([[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]])
python中的sum函数.sum(axis=1)
当加入axis=1以后就是将一个矩阵的每一行向量相加
a = np.array([[0, 2, 1]]) print a.sum()
print a.sum(axis=0)
print a.sum(axis=1) 结果分别是:3, [0 1 2], [3] b = np.array([0, 2, 1]) print b.sum()
print b.sum(axis=0)
print b.sum(axis=1) 结果分别是:3, 3, 运行错误:'axis' entry is out of bounds 可知:对一维数组,只有第0轴,没有第1轴 c = np.array([[0, 2, 1], [3, 5, 6], [0, 1, 1]]) print c.sum()
print c.sum(axis=0)
print c.sum(axis=1) 结果分别是:19, [3 8 8], [ 3 14 2]
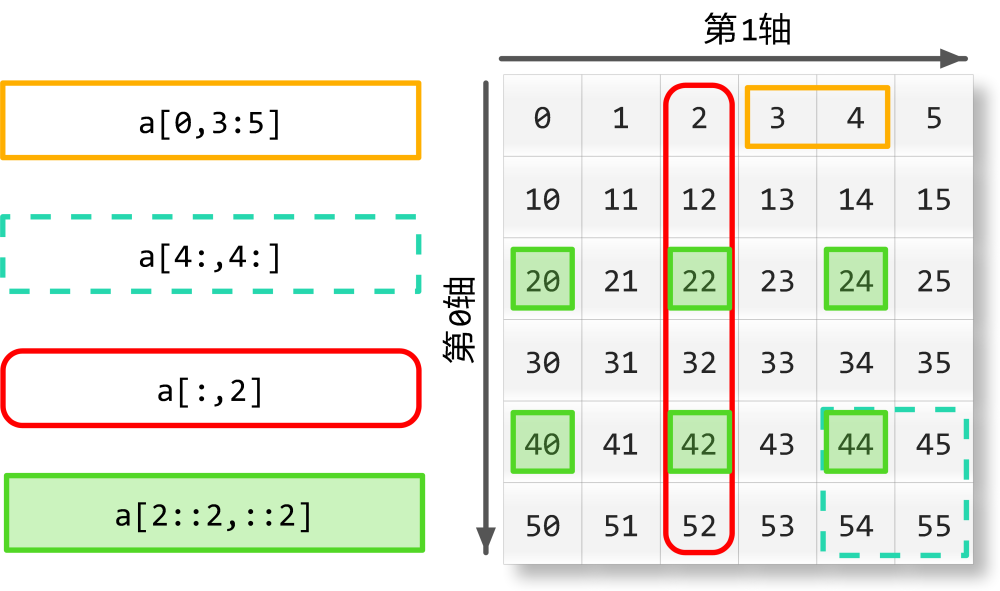
浅述python中argsort()函数的用法
1.先定义一个array数据
1 import numpy as np
2 x=np.array([1,4,3,-1,6,9])
2.现在我们可以看看argsort()函数的具体功能是什么:
x.argsort()
输出定义为y=array([3,0,2,1,4,5])。
我们发现argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y。例如:x[3]=-1最小,所以y[0]=3,x[5]=9最大,所以y[5]=5。
Python 字典(Dictionary) get()方法
描述
Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。
语法
get()方法语法:
dict.get(key, default=None)
参数
- key -- 字典中要查找的键。
- default -- 如果指定键的值不存在时,返回该默认值值。
返回值
返回指定键的值,如果值不在字典中返回默认值None。
items()和iteritems()区别:


核心代码解读:
# inX:用于分类的输入向量
# dataSet:输入的训练样本集
# labels:标签向量
# k:用于选择最近邻的数量
def classify0(inX, dataSet, labels, k):
# 距离计算
dataSetSize = dataSet.shape[0] #数据的条目数 #c.shape[1] 为列的数量,c.shape[0] 为行的数量。
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1) #将每一列相加
distances = sqDistances**0.5 # 将距离值按照从小到大排序
sortedDistIndicies = distances.argsort()
classCount={} # 取出前k个元素
for i in rangs(k):
# 取出对应的label
voteIlabel = labels[sortedDistIndicies[i]]
#计算当前取出的label的数量
#对标签A、B分别进行统计计数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 # 逆序排列label对应总数的列表 返回对应的label
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1), reverse=True)
#iteritems()是把字典里面的元素,返回一个迭代器
#key=operator.itemgetter(1),按照第1个值(即第二个统计到的个树值)进行排序
#reverse=True,True时将按降序排列 return sortedClassCount[0][0]
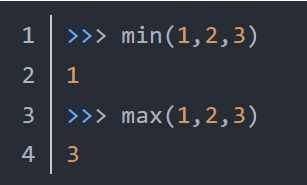
python: min 和 max 函数:
对于元组
max(tuple)
返回元组中元素最大值。
min(tuple)
返回元组中元素最小值。
cmp(tuple1,tuple2)
比较两个元组元素。
tuple(seq)
将列表转换为元组。

第2章 K近邻算法的更多相关文章
- 《机实战》第2章 K近邻算法实战(KNN)
1.准备:使用Python导入数据 1.创建kNN.py文件,并在其中增加下面的代码: from numpy import * #导入科学计算包 import operator #运算符模块,k近邻算 ...
- 《机器学习实战》---第二章 k近邻算法 kNN
下面的代码是在python3中运行, # -*- coding: utf-8 -*- """ Created on Tue Jul 3 17:29:27 2018 @au ...
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- AI小记-K近邻算法
K近邻算法和其他机器学习模型比,有个特点:即非参数化的局部模型. 其他机器学习模型一般都是基于训练数据,得出一般性知识,这些知识的表现是一个全局性模型的结构和参数.模型你和好了后,不再依赖训练数据,直 ...
随机推荐
- 原生canvas写的飞机游戏
一个原生canvas写的飞机游戏,实用性不大,主要用于熟悉canvas的一些熟悉用法. 项目地址:https://github.com/BothEyes1993/canvas_game
- SpringBoot整合mybatis踩坑
springboot整合mybaits过程中,调用接口时报错:org.apache.ibatis.binding.BindingException: Invalid bound statement ( ...
- win10命令控制符
IP:ipconfigIP地址侦测器:Nslookup显卡:dxdiag控制面板:control电话拨号:dialer木马捆绑工具,系统自带:iexpress本地用户和组:lusrmgr.msc鼠标属 ...
- Python中的基础数据类型
Python中基础数据类型 1.数字 整型a=12或者a=int(2),本质上各种数据类型都可看成是类,声明一个变量时候则是在实例化一个类. 整型具备的功能: class int(object): & ...
- /etc/vsftpd.conf详解
#################匿名权限控制############### anonymous_enable=YES #是否启用匿名用户no_anon_password=YES #匿名用户logi ...
- Oralce 序列
序列: 是oacle提供的用于产生一系列唯一数字的数据库对象. l 自动提供唯一的数值 l 共享对象 l 主要用于提供主键值 l 将序列值装入内存可以提高访问效率 创建序列: 1. 要有创建 ...
- golang开发不错的参考资料
https://golangbot.com/learn-golang-series/ https://gist.github.com/ivangabriele/1c552aadc247c0a2f256 ...
- ssh key生成步骤
1. 安装git,从程序目录打开 "Git Bash" ,或者直接用git shell,github自带的工具 2. 键入命令:ssh-keygen -t rsa -C " ...
- 关于Angular中时间戳的计算
前言 使用的是Moment.js 插件,插件的安装详情请参考官方网址(https://momentjs.com/) 正文 步骤一:引用import * as moment from 'moment'; ...
- 同时对view延时执行两个动画时候的现象
同时对view延时执行两个动画时候的现象 对于view延时执行了两个动画后,会将第一个动画效果终止了,直接在第一个动画的view的最后的状态上接执行后续的动画效果,也就是说,我们可以利用这个特性来写分 ...