LevelDB Cache机制
【LevelDB Cache机制】
对于levelDb来说,读取操作如果没有在内存的memtable中找到记录,要多次进行磁盘访问操作。假设最优情况,即第一次就在level 0中最新的文件中找到了这个key,那么也需要读取2次磁盘,一次是将SSTable的文件中的index部分读入内存,这样根据这个index可以确定key是在哪个block中存储;第二次是读入这个block的内容,然后在内存中查找key对应的value。
levelDb中引入了两个不同的Cache:Table Cache和Block Cache。其中Block Cache是配置可选的,即在配置文件中指定是否打开这个功能。
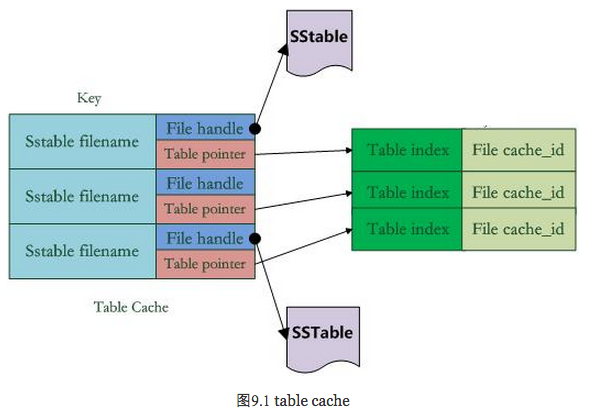
图9.1是table cache的结构。在Cache中,key值是SSTable的文件名称,Value部分包含两部分,一个是指向磁盘打开的SSTable文件的文件指针,这是为了方便读取内容;另外一个是指向内存中这个SSTable文件对应的Table结构指针,table结构在内存中,保存了SSTable的index内容以及用来指示block cache用的cache_id ,当然除此外还有其它一些内容。
比如在get(key)读取操作中,如果levelDb确定了key在某个level下某个文件A的key range范围内,那么需要判断是不是文件A真的包含这个KV。此时,levelDb会首先查找Table Cache,看这个文件是否在缓存里,如果找到了,那么根据index部分就可以查找是哪个block包含这个key。如果没有在缓存中找到文件,那么打开SSTable文件,将其index部分读入内存,然后插入Cache里面,去index里面定位哪个block包含这个Key 。如果确定了文件哪个block包含这个key,那么需要读入block内容,这是第二次读取。
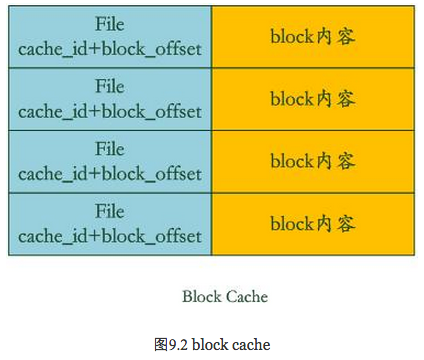
Block Cache是为了加快这个过程的,图9.2是其结构示意图。其中的key是文件的cache_id加上这个block在文件中的起始位置block_offset。而value则是这个Block的内容。
如果levelDb发现这个block在block cache中,那么可以避免读取数据,直接在cache里的block内容里面查找key的value就行,如果没找到呢?那么读入block内容并把它插入block cache中。levelDb就是这样通过两个cache来加快读取速度的。从这里可以看出,如果读取的数据局部性比较好,也就是说要读的数据大部分在cache里面都能读到,那么读取效率应该还是很高的,而如果是对key进行顺序读取效率也应该不错,因为一次读入后可以多次被复用。但是如果是随机读取,您可以推断下其效率如何。
参考:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
LevelDB Cache机制的更多相关文章
- LevelDB Cache实现机制分析
几天前淘宝量子恒道在博客上分析了HBase的Cache机制,本篇文章,结合LevelDB 1.7.0版本的源码,分析下LevelDB的Cache机制. 概述 LevelDB是Google开源的持久化K ...
- jQuery的XX如何实现?——3.data与cache机制
往期回顾: jQuery的XX如何实现?——1.框架 jQuery的XX如何实现?——2.show与链式调用 -------------------------- 源码链接:内附实例代码 jQuery ...
- 受教了,memcache比较全面点的介绍,受益匪浅,适用memcached的业务场景有哪些?memcached的cache机制是怎样的?在设计应用时,可以通过Memcached缓存那些内容?
基本问题 1.memcached的基本设置 1)启动Memcache的服务器端 # /usr/local/bin/memcached -d -m 10 -u root -l 192.168.0.200 ...
- [转帖]CPU Cache 机制以及 Cache miss
CPU Cache 机制以及 Cache miss https://www.cnblogs.com/jokerjason/p/10711022.html CPU体系结构之cache小结 1.What ...
- 艺多不压身 -- 常用缓存Cache机制的实现
常用缓存Cache机制的实现 缓存,就是将程序或系统经常要调用的对象存在内存中,以便其使用时可以快速调用,不必再去创建新的重复的实例. 这样做可以减少系统开销,提高系统效率. 缓存主要可分为二大类: ...
- Java中各类Cache机制实现解决方案[来自CSDN]
摘要:在Java中,不同的类都有自己单独的Cache机制,实现的方法也可能有所不同,文章列举了Java中常见的各类Cache机制的实现方法,同时进行了综合的比较. 在Java中,不同的类都有自己单独的 ...
- Linux内存管理Swap和Buffer Cache机制
Linux内存管理Swap和Buffer Cache机制 一个完整的Linux系统主要有存储管理,内存管理,文件系统和进程管理等几方面组成,贴出一些以前学习过的一个很好的文章.与大家共享!以下主要说明 ...
- LevelDB Cache
[LevelDB Cache] The contents of the database are stored in a set of files in the filesystem and each ...
- docker build 的 cache 机制
cache 机制注意事项 可以说,cache 机制很大程度上做到了镜像的复用,降低存储空间的同时,还大大缩短了构建时间.然而,不得不说的是,想要用好 cache 机制,那就必须了解利用 cache 机 ...
随机推荐
- CSS用法
body, table{font-family: 微软雅黑; font-size: 10pt} table{border-collapse: collapse; border: solid gray; ...
- java- Collection Set集合
首先HashSet类创建集合对象和遍历对象 package set; import java.util.HashSet; import java.util.Iterator; //hashset储存字 ...
- 征信接口调用,解析(xml)
数据传输格式报文格式:xml public CisReportRoot queryCisReport(PyQueryBean pyQueryBean) throws Exception { CisRe ...
- Http协议——Header说明
下图是我用IE的开发人员工具截取的一个Http Request请求的Header. 下图是我用IE的开发人员工具截取的一个Http Response的Header. header常用指令 header ...
- nginx: [emerg] "fastcgi_pass" directive is duplicate in /etc/nginx/sites-enabled/default:57
/************************************************************************************************ * ...
- [QT]QPixmap图片缩放和QLabel 的图片自适应效果对比
图片大小为600x600 效果图: ui->label->setScaledContents(true); ...
- CF1082G:G. Petya and Graph(裸的最大闭合权图)
Petya has a simple graph (that is, a graph without loops or multiple edges) consisting of n n vertic ...
- 在Linux中批量修改字符串的命令
昨天一个朋友忽然问我,在Linux下如何批量修改字符串,当时瞬间懵逼了,完全想不起来....... 今天特意的重温了一下Linux下的一些常用命令,并将这个遗忘的批量修改字符串的命令记录下来(资料来自 ...
- Cocos2d-x调用Java 代码
Java代码: package com.dishu; import com.dishu.org.R; import android.app.Activity; import android.app.A ...
- Mac 使用ab性能测试工具
Mac 使用ab命令进行压测 1.在Mac中配置Apache ①启动Apache,打开终端 sudo apachectl -v 如下显示Apache的版本 sudo apachectl start 这 ...