数据结构(三)--- B树(B-Tree)
文章图片代码来自邓俊辉老师的课件
概述
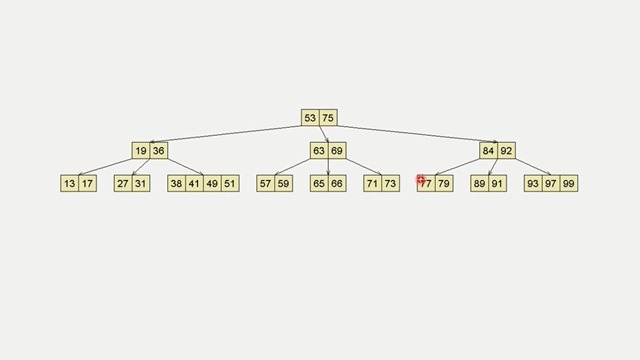
上图就是 B-Tree 的结构,可以看到这棵树和二叉树有点不同---“又矮又肥”。同时子节点可以有若干个小的子节点构成。那么这样一棵树又有什么作用呢?
动机
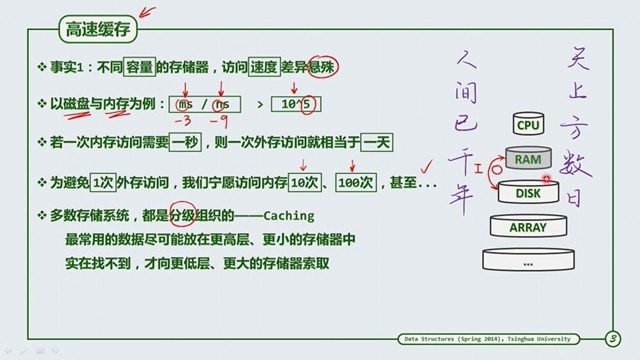
我们知道电脑的访问内存比访问外的存I/O操作快了,但是内存的容量大小又只有那么一点点(相对于外存),所以计算机访问的过程常常使用高速缓存。使用高速缓存也是在以下两个事实想出的策略。
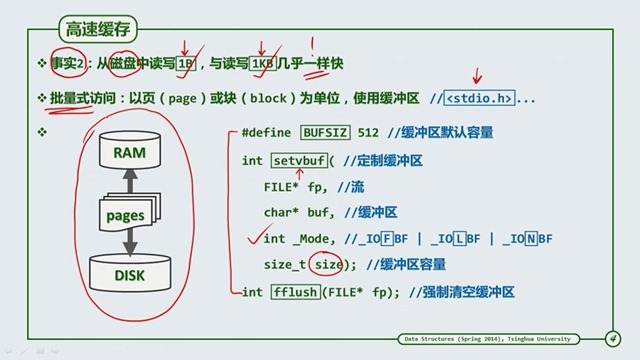
而B-Tree这种结构就是根据这种情况被发掘出来的。下图 m 指的是每次的数据块数量
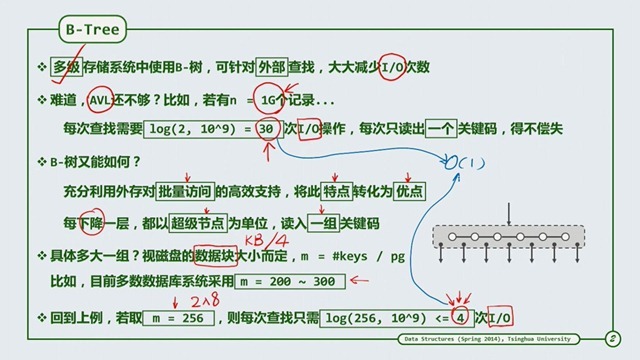
B-Tree 介绍
多路平衡
关键码指的是一个超级节点包含的子节点。
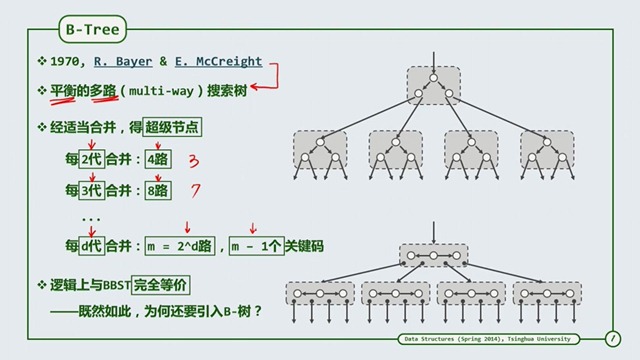
B-Tree定义
m阶指的是m路,一个超级节点最大可以分出多少路。二叉树分出两边,左边和右边,就是两路,二阶。

下面是几个定义为不同阶的B-树。

分支数
B-Tree的分支数有个上下限,例如6阶的B-Tree(m=6),又被称为 “(3,6)-树”,类似的还有 “(3,5)-树”,“(2,4)-树”,而(2,4)树就是我们后面要学的红黑树。
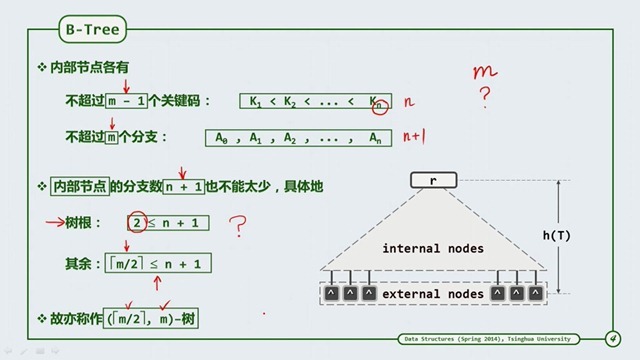
最大树高和最小数高
可以看到对于“含N个关键码的m阶B-树”的最大树高和最小树高之间的波动并不大。
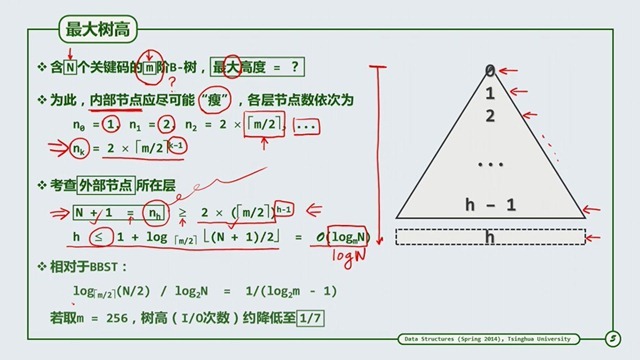

代码实现
代码实现主要的两个方法为插入和删除。其中插入的时候需要注意查看某个节点是否超出了阶数,若超出了,需要分裂,最坏的情况就是分裂到根部,而删除操作需要注意查看是否会产生下溢,处理下溢,我们常用的方法就是旋转和合并。
插入
下图分别是分裂和再分裂的图示。 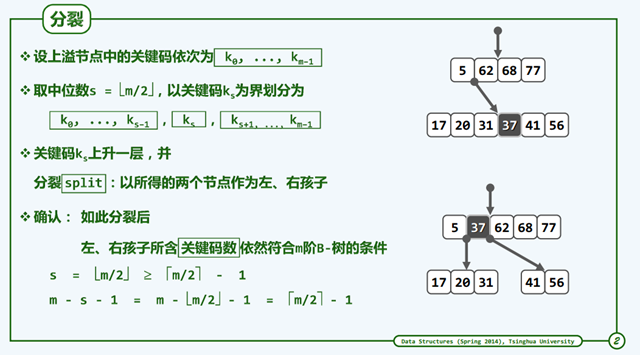
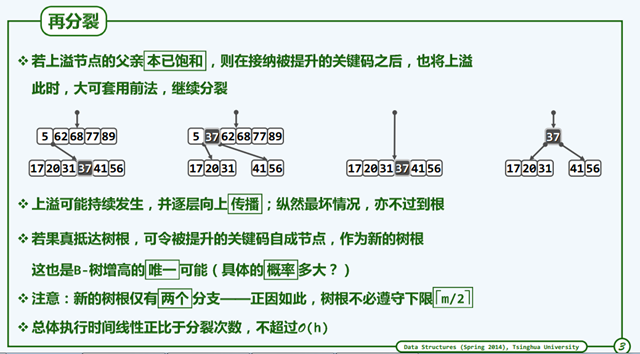
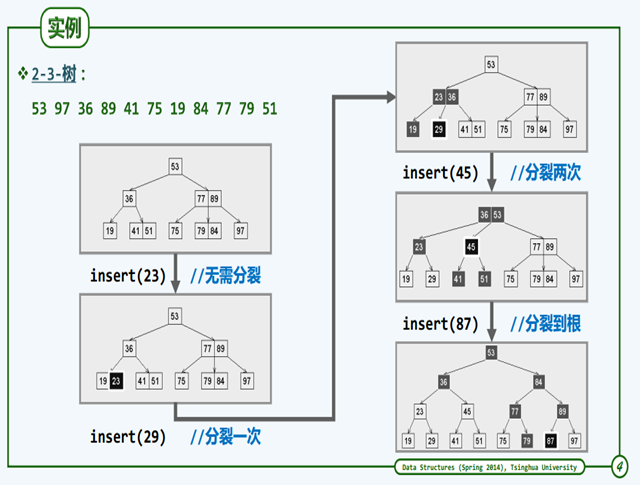
删除
删除操作的旋转和合并。
旋转可以理解为左右兄弟有足够的节点,向左右兄弟节点借来补充的操作。
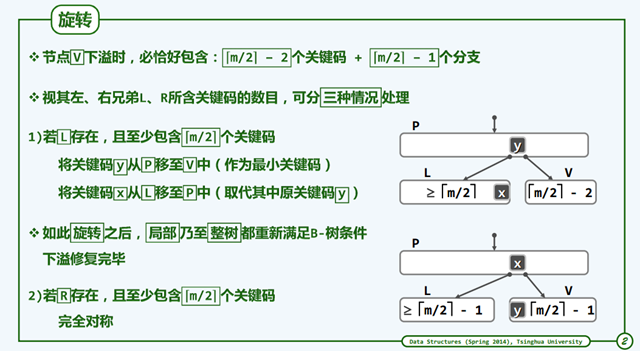
假如向兄弟们借都不成功,那就拿父节点的一个元素一起合并,代码实现中有分左合并和右合并。
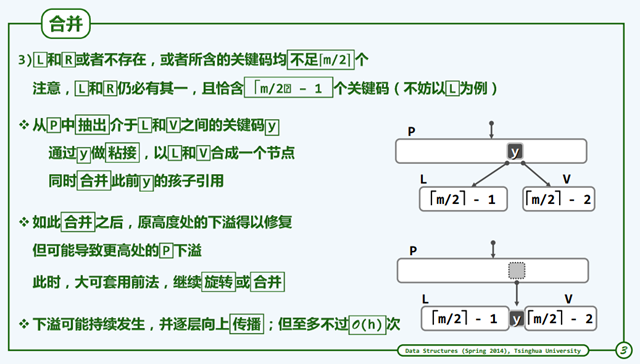
java版本代码
B-树节点类
package BTree; import java.util.Vector; /**
* B-树的节点Bean
* 包含一个有序向量 value 和 指向子节点的 child 向量
*
*/
public class BTreeNode {
BTreeNode parent;
Vector<BTreeNode> child;
Vector<Integer> value; public BTreeNode(int value, BTreeNode left, BTreeNode right) {
if (this.value == null) {
this.value = new Vector<>();
this.value.sort(new VectorComparable());
}
if (child == null) {
child = new Vector<>();
}
this.value.add(value);
this.child.add(0, left);
this.child.add(1, right);
if (left != null) {
left.parent = this;
}
if (right != null) {
right.parent = this;
}
} public BTreeNode() {
parent = null;
if (this.value == null) {
this.value = new Vector<>();
this.value.sort(new VectorComparable());
}
if (child == null) {
child = new Vector<>();
}
} /**
* 一个关键块内的查找 查找到与否都返回一个index
* 返回最靠近的值的原因是为了下面的节点继续查找
*
* @param value 查找的值
* @return 不存在的情况返回最靠近的index 值 , -1
*/
public int search(int value) {
int hot = -1;
for (int i = 0; i < this.value.size(); i++) {
if (this.value.get(i) > value) {
return hot;
} else if (this.value.get(i) < value) {
hot = i;
} else { // 相等
return i;
}
}
return this.value.size() - 1;
} public int getIndexInValue(int compare) {
for (int i = 0; i < this.value.size(); i++) {
if (compare == value.get(i)) {
return i;
}
}
return -1;
} /**
* 查找当前node在父节点中的index
*
* @return -1 为父类不存在或是父类为null ,其他为当前节点在父节点为位置
*/
public int getIndexFromParent() {
if (parent == null) {
return -1;
}
for (int i = 0; i < parent.child.size(); i++) {
if (parent.child.get(i) == this) {
return i;
}
}
return -1;
} public void addValue(int index, int val) {
value.add(index, val);
value.sort(new VectorComparable());
} public void addValue(int val) {
value.add(val);
value.sort(new VectorComparable());
} }
B-树数据结构方法。
package BTree;
public class BTree {
private BTreeNode root;
private int degree; // m阶B-树 ,阶树至少为3
/*
* 私有方法
*/
/**
* 查找在哪个BTreeNode ,假如到了外部节点,返回该外部节点 返回的结果只有两种 :
* - 存在,返回该节点
* - 不存在,返回值应该插入的节点
*
* @param val 查找的值
* @return 返回搜索结果,假如该关键块不存在(到达了外部节点)就返回该关键快
*/
private BTreeNode searchSurroundNode(int val) {
BTreeNode node, hot = null;
int rank;
node = root;
while (node != null) {
rank = node.search(val);
if (rank != -1 && node.value.get(rank) == val) { // 找到对应的值
return node;
} else {
hot = node;
if (node.child.get(rank + 1) == null) {
return hot;
}
node = node.child.get(rank + 1);
}
}
// 到了外部节点
return hot;
}
private void addNodeForBtNode(BTreeNode node, int rank, int val) {
node.addValue(val);
if (rank != -1) {
node.child.add(rank + 2, null);
} else {
node.child.add(0, null);
}
}
/*
* 下面为可调用的方法
*/
public BTree(int degree) {
this.degree = degree;
}
/**
* 返回值所在的节点
*
* @param val 插入的值
* @return 找到的话返回节点,找不到返回 null
*/
public BTreeNode search(int val) {
BTreeNode node = searchSurroundNode(val);
if (node.value.get(node.search(val)) == val) { // 该节点存在该值
return node;
}
return null;
}
/**
*
* 插入的值都会进入到底部节点
* @param val 插入的值
* @return 是否插入成功
*/
public boolean insert(int val) {
if (root == null) {
root = new BTreeNode(val, null, null);
return true;
}
//root 已经创建,插入的值最终会到达底部,然后插进去
BTreeNode node = searchSurroundNode(val);
int rank = node.search(val);
if (rank != -1 && node.value.get(rank) == val) { // 该节点存在该值,返回插入失败
return false;
} else { // 值将会插入该关键码
addNodeForBtNode(node, rank, val);
split(node);
return true;
}
}
private void split(BTreeNode node) {
while (node.value.size() >= degree) {
// 1.取中数
int midIndex = node.value.size() / 2;
BTreeNode rightNode = new BTreeNode();
for (int i = midIndex + 1; i < node.value.size(); i++) {
rightNode.addValue(node.value.remove(i));
if (i == midIndex + 1) {
rightNode.child.add(node.child.remove(i));
}
rightNode.child.add(node.child.remove(i));
}
for (BTreeNode rn : rightNode.child) {
if (rn != null) {
rn.parent = rightNode;
}
}
// 移除原节点记得移除对应它的子节点
int insertValue = node.value.remove(midIndex);
if (node.parent != null) { // 存在父节点,把分裂点添加在父节点上
node.parent.addValue(insertValue);
/*
* 对插入的节点的子节点进行处理
* 1.得出插入点的index
* 2.左边子节点连接原node,右节点连接 rightNode
*/
int indexInValue = node.parent.getIndexInValue(insertValue);
node.parent.child.add(indexInValue + 1, rightNode);
rightNode.parent = node.parent;
node = node.parent;
} else { // 不存在父节点,并且当前节点溢出
root = new BTreeNode(insertValue, node, rightNode);
break;
}
}
}
public boolean delete(int val) {
//node 为要删除的val所在的节点
BTreeNode node = search(val);
if (node != null) {
int rank = node.getIndexInValue(val);
// 找到继承结点并代替
if (node.child.get(0) != null) { //非底部节点
BTreeNode bottom = node.child.get(rank + 1);
while (bottom.child.get(0) != null) {
bottom = bottom.child.get(0);
}
node.value.set(rank, bottom.value.get(0));
bottom.value.set(0, val);
node = bottom;
rank = 0;
}
// 此时 node 一定是外部节点了(最底层)
node.value.remove(rank);
node.child.remove(rank + 1);
// 由于删除了某个值,所以需要从兄弟中借一个来拼凑(旋转)
// 当兄弟自己已到达下限,与父类合并成更大的节点,原来父节点所在的节点有可能-1后
// 导致又达到了下限,然后循环
solveUnderflow(node);
return true;
}
return false;
}
/**
* 下溢的节点 :
* - 外部节点
* - 非外部节点
*
* @param node 下溢的节点
*/
public void solveUnderflow(BTreeNode node) {
//没有达到下溢的条件
int condition = (degree + 1) / 2;
if (node.child.size() >= condition) {
return;
}
BTreeNode parent = node.parent;
if (parent == null) { //到了根节点
if (node.value.size() == 0 && node.child.get(0) != null) {
root = node.child.get(0);
root.parent = null;
node.child.set(0, null);
}
return;
}
int rank = node.getIndexFromParent();
//旋转
if (rank > 0 && parent.child.get(rank - 1).child.size() > condition) { //左旋转,从左兄弟拿一个
BTreeNode ls = parent.child.get(rank - 1);
node.addValue(0, parent.value.remove(rank - 1));
parent.addValue(rank - 1, ls.value.remove(ls.value.size() - 1));
/*
* 被取走的节点可能存在子节点,需要放在新的位置
* 有可能上一次进行合并操作中,父节点的关键码为空了,
* 但是父节点还存在子节点(不为null)
*/
node.child.add(0, ls.child.remove(ls.child.size() - 1));
if (node.child.get(0) != null) {
node.child.get(0).parent = node;
}
return;
} else if (rank < parent.child.size() - 1 && parent.child.get(rank + 1).child.size() > condition) { //右旋转,从右兄弟拿一个
BTreeNode rs = parent.child.get(rank + 1);
node.addValue(parent.value.remove(rank));
parent.addValue(rs.value.remove(0));
node.child.add(node.child.size(), rs.child.remove(0));
if (node.child.lastElement() != null) {
node.child.lastElement().parent = node;
}
return;
}
// 合并
if (rank > 0) { // 左合并
BTreeNode ls = parent.child.get(rank - 1);
//父类节点转入到左节点
ls.addValue(ls.value.size(), parent.value.remove(rank - 1));
parent.child.remove(rank);
//当前节点转入到左节点
ls.child.add(ls.child.size(), node.child.remove(0));
if (ls.child.get(ls.child.size() - 1) != null) {
ls.child.get(ls.child.size() - 1).parent = ls;
}
// 当前节点有可能value为空,但是child不为空。
// value 为空不移动,不为空移动
while (node.value.size() != 0) {
ls.addValue(node.value.remove(0));
ls.child.add(ls.child.size(), node.child.remove(0));
if (ls.child.get(ls.child.size() - 1) != null) {
ls.child.get(ls.child.size() - 1).parent = ls;
}
}
} else { //右合并,有可能 rank = 0
BTreeNode rs = parent.child.get(rank + 1);
//父类节点转入到右节点
rs.addValue(0, parent.value.remove(rank));
//父类节点断开与当前节点的连接
parent.child.remove(rank);
//当前节点转入到右节点
rs.child.add(0, node.child.remove(0));
if (rs.child.get(0) != null) {
rs.child.get(0).parent = rs;
}
while (node.value.size() != 0) {
rs.addValue(0, node.value.remove(0));
rs.child.add(0, node.child.remove(0));
if (rs.child.get(0) != null) {
rs.child.get(0).parent = rs;
}
}
}
solveUnderflow(parent);
}
public int height() {
int h = 1;
BTreeNode node = root;
while (node != null) {
if (node.child.get(0) != null) {
h++;
node = node.child.get(0);
} else {
break;
}
}
return h;
}
}
最后是一个测试的方法。
package BTree;
public class BTreeTest {
public static void main(String[] args) {
BTree tree = new BTree(3);
tree.insert(53);
tree.insert(97);
tree.insert(36);
tree.insert(89);
tree.insert(41);
tree.insert(75);
tree.insert(19);
tree.insert(84);
tree.insert(77);
tree.insert(79);
tree.insert(51);
// System.out.println(tree.height());
// tree.insert(23);
// tree.insert(29);
// tree.insert(45);
// tree.insert(87);
// System.out.println("-------------");
System.out.println("插入节点以后的树的高度 : "+tree.height());
System.out.println("-------------");
// tree.delete(41);
// tree.delete(75);
// tree.delete(84);
// tree.delete(51);
tree.delete(36);
tree.delete(41);
System.out.println("删除节点以后的树的高度 : "+tree.height());
}
}
参考资料
- 邓俊辉老师的数据结构课程
数据结构(三)--- B树(B-Tree)的更多相关文章
- Linux 内核中的数据结构:基数树(radix tree)
转自:https://www.cnblogs.com/wuchanming/p/3824990.html 基数(radix)树 Linux基数树(radix tree)是将指针与long整数键值相 ...
- 数据结构之树(Tree)(一) :树
ps:好久没用动手写blog了,要在这条路上不断发展,就需要不停的学习,不停的思考与总结,当把写blog作为一种习惯,就是自我成长的证明,Fighting!. 一.简介 树是一种重要的非线性数据结构, ...
- SDUT 3375 数据结构实验之查找三:树的种类统计
数据结构实验之查找三:树的种类统计 Time Limit: 400MS Memory Limit: 65536KB Submit Statistic Problem Description 随着卫星成 ...
- Python入门篇-数据结构树(tree)的遍历
Python入门篇-数据结构树(tree)的遍历 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.遍历 迭代所有元素一遍. 二.树的遍历 对树中所有元素不重复地访问一遍,也称作扫 ...
- Python入门篇-数据结构树(tree)篇
Python入门篇-数据结构树(tree)篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.树概述 1>.树的概念 非线性结构,每个元素可以有多个前躯和后继 树是n(n& ...
- 数据结构(三) 树和二叉树,以及Huffman树
三.树和二叉树 1.树 2.二叉树 3.遍历二叉树和线索二叉树 4.赫夫曼树及应用 树和二叉树 树状结构是一种常用的非线性结构,元素之间有分支和层次关系,除了树根元素无前驱外,其它元素都有唯一前驱. ...
- SDUT-3375_数据结构实验之查找三:树的种类统计
数据结构实验之查找三:树的种类统计 Time Limit: 400 ms Memory Limit: 65536 KiB Problem Description 随着卫星成像技术的应用,自然资源研究机 ...
- 线段树 Interval Tree
一.线段树 线段树既是线段也是树,并且是一棵二叉树,每个结点是一条线段,每条线段的左右儿子线段分别是该线段的左半和右半区间,递归定义之后就是一棵线段树. 例题:给定N条线段,{[2, 5], [4, ...
- 数据结构与算法->树->2-3-4树的查找,添加,删除(Java)
代码: 兵马未动,粮草先行 作者: 传说中的汽水枪 如有错误,请留言指正,欢迎一起探讨. 转载请注明出处. 目录 一. 2-3-4树的定义 二. 2-3-4树数据结构定义 三. 2-3-4树的可以得到 ...
- 『线段树 Segment Tree』
更新了基础部分 更新了\(lazytag\)标记的讲解 线段树 Segment Tree 今天来讲一下经典的线段树. 线段树是一种二叉搜索树,与区间树相似,它将一个区间划分成一些单元区间,每个单元区间 ...
随机推荐
- C/C++,python,java,C#月经贴问题
在刚开始的时候,一直纠结于语言之争,什么什么有前途,什么什么没前途.对于什么的支持不好啦,个人信仰问题啦.什么都有. 首先最主要的一个个人观点:“语言不是老婆,不是一夫一妻制”.你可以同时拥有许多的女 ...
- Problem H: 小姐姐的QQ号(DFS)
Contest - 河南省多校连萌(四) Problem H: 小姐姐的QQ号 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 297 Solved: ...
- 【Oracle 12c】CUUG OCP认证071考试原题解析(29)
29.choose the best answer Evaluate the following query: SQL> SELECT promo_name || q'{'s start dat ...
- 了解eslint
1.简介:eslint检查我们写的 JavaScript 代码是否满足指定规则的静态代码检查工具. JSHint 和 JSLint 也是静态代码检查工具,但伴随着发展,他们已经无法满足需求,于是ESl ...
- java后台简单从阿里云上传下载文件并通知前端以附件的形式保存
一. 首先开通阿里的OSS 服务 创建一个存储空间在新建一个Bucket 在你新建的bucket有所需的id和key 获取外网访问地址或者是内网 看个人需求 我使用的是外网(内网没用过 估计是部署到阿 ...
- day00 -----博客作业1
问题1.使用while循环输入 1 2 3 4 5 6 8 9 10 i = 0 while i<10: i+=1 if i ==7: continue print(i) 问题2 求1- ...
- session_destroy()和session_unset()的理解
session_destroy 是注销所有的session变量,并且结束session会话目前是删除当前用户对应的session文件以及释放session id值 ,但是但是 内存中的$_SESSIO ...
- [转] Scala 的集合类型与数组操作
[From] https://blog.csdn.net/gongxifacai_believe/article/details/81916659 版权声明:本文为博主原创文章,转载请注明出处. ht ...
- 20190416 OSX系统使用VMware Fusion安装CentOS7踩的那些坑
一.创建虚拟机 (1)在虚拟机资源库中点击[+添加]按钮,选择“新建...”选项 (2)选择创建自定义虚拟机 (3)选择系统类型为CentOS (4)选择虚拟磁盘类型 (5)选择虚拟机存储位置:点击[ ...
- Flask 数据库迁移
在开发过程中,需要修改数据库模型,而且还要在修改之后更新数据库.最直接的方式就是删除旧表,但这样会丢失数据. 更好的解决办法是使用数据库迁移框架,它可以追踪数据库模式的变化,然后把变动应用到数据库中. ...