阿里巴巴分布式数据库服务DRDS研发历程
淘宝TDDL研发历史和背景
分布式关系型数据库服务(Distribute Relational Database Service,简称DRDS)是一种水平拆分、可平滑扩缩容、读写分离的在线分布式数据库服务。前身为淘宝TDDL。
淘宝DRDS/TDDL是阿里巴巴自主研发的分布式数据库服务。DRDS脱胎于阿里巴巴开源的Cobar分布式数据库引擎,吸收了Cobar核心的Cobar-Proxy源码,实现了一套独立的类似MySQL-Proxy协议的解析端,能够对传入的SQL进行解析和处理,对应用程序屏蔽各种复杂的底层DB拓扑结构,获得单机数据库一样的使用体验,同时借鉴了淘宝TDDL丰富的分布式数据库实践经验,实现了对分布式Join支持,SUM、MAX、COUNT、AVG等聚合函数支持以及排序等函数支持,通过异构索引、小表广播等解决分布式数据库使用场景下衍生出的一系列问题,最终形成了完整的分布式数据库方案。
使用场景
分布式数据库核心诉求在于解决单机数据库的瓶颈,单机数据库在使用过程中不可避免会遇到数据库容量、连接数、事务数、读性能瓶颈,突破这些瓶颈的两种通用的解决模型是单机垂直扩展scale up模型和水平扩展scale out模型。
单机扩展模型和硬件资源强绑定,普遍采用升级单机硬件能力的方式,实现数据库服务能力扩展,比如原来采用MySQL单机数据库,遇到访问瓶颈时更换磁盘,访问量更高时就需要考虑使用Oracle的商用解决方案、高端的存储设备、高端小型机,也就是IOE架构,甚至升级IOE设备,以换取更高的扩展和服务能力,这个过程就会存在设备升级和数据迁移的成本。
多机器用水平扩展模型使用大量廉价的PC-Server,通过阵列的方式来实现数据库的水平扩容,优势在于成本更低,因为不需要淘汰老设备和系统,不需要频繁迁移数据,需要时,只需扩容服务集群规模。
使用分布式多机模型也需要付出一定成本,分布式数据库的架构与单机数据库的逻辑和物理分布存在比较大差异,因此需要将单机数据库的数据迁移到分布式架构模型之下,也就是Sharding的数据分片过程,这个过程涉及数据的分布式逻辑设计、数据库迁移和SQL的优化改造,当然这个迁移一次性的,当架构迁移完成之后,就无需再关心数据库扩容和数据迁移问题,因为分布式数据库的服务层已经集成了扩容功能,架构上支持水平能力扩展。
2006年之前我们的核心应用普遍采用Oracle数据库,但随着业务快速发展,淘宝的数据量和访问量急剧增加,数据库出现严重访问性能问题,导致数据库频繁宕机、业务停滞,即使当时已经使用Oracle亚洲最大的RAC集群,单机数据库的扩展能力已经达到极限,且需要付出巨大的资金和运维成本,因此我们基于自己的实际情况,逐步开始去IOE,研发分布式关系型数据库服务,实现数据库的高扩展和成本可控,目前DRDS已经成为我们内部分布式数据库的标准,并且对外服务于金融、制造、政府机构、电商、社交等各行业。
DRDS的整体架构
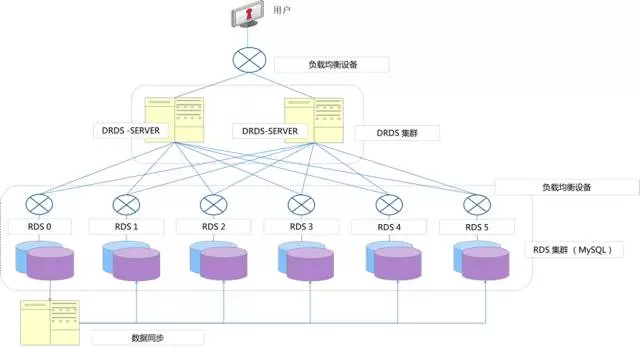
DRDS/TDDL是典型的水平扩展分布式数据库模型,区别于传统单机数据库share anything架构,DRDS/TDDL采用share nothing架构,share nothing架构核心思路利用普通的服务器,将单机数据拆分到底层的多个数据库实例上,通过统一的Proxy集群进行SQL解析优化、路由和结果聚合,对外暴露简单唯一的数据库链接。整体架构如图1所示,包含DRDS服务模块、DRDS管控模块、配置中心、监控运维、数据库服务集群、域名服务模块。
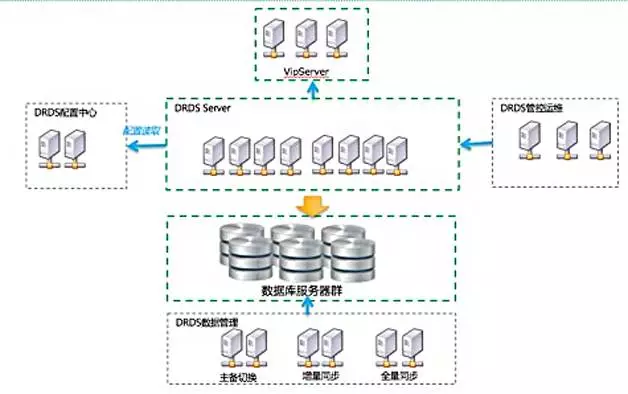
通过分布式集群管理模块实现对集群节点的管控。在数据安全和服务可用性方面,通过高效的数据同步系统,实现数据库的扩容和数据库实例的主备数据同步。同时依赖实例监控模块和HA模块实现主备的监控和自动化容灾切换。作为成熟的分布式数据库产品,TDDL也具备完善的运维管控系统,能够实现分布式数据库多实例之间的配置管理、变更,以及各种数据同步、扩容等任务管理,降低运维成本。
DRDS/TDDL的功能特性
数据分片
DRDS的基础原理就是Sharding,也就是数据分片。将单机数据库的数据拆分到多个单机数据库上,对外保持逻辑的一致性。后端拆分的数据库为分库,对应的表称为分表,每个分库负责一份数据的读写操作,分散整体访问压力。在系统扩容时,只需水平增加分库数量,并迁移相关数据,即可提高DRDS系统总体容量。
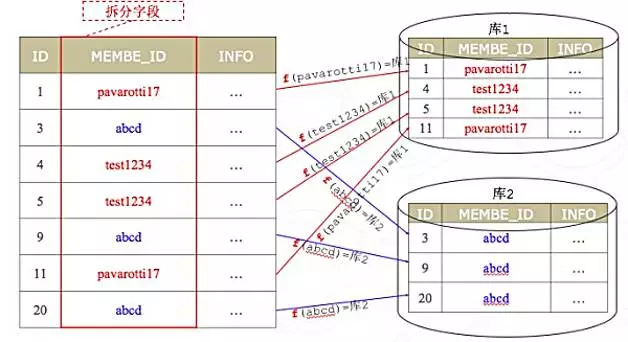
数据分片需要选择一个分片的拆分纬度,也就是数据分布的依据。比如一个用户订单信息表,如果按照订单ID做数据拆分,那么相同订单ID的数据就会被拆分到同一个数据库存储节点,如果按照用户ID做数据拆分,那么同一个用户的订单就会分布到同一个数据库存储实例的存储节点。
拆分纬度的选择非常重要,一般来说要根据实际业务的场景选择拆分键,总体指导原则是尽量保证每一个数据库节点的数据量和负载更均衡,单条SQL操作尽量落到单个数据库节点执行,不同SQL的查询落到不同的数据库节点。这样可以减少多个节点之间的网络传输,保持分布式查询的效率,均衡负载的同时也便于扩展。
平滑扩容
数据库的扩容是数据库运维的常见操作,当数据库的数据存储容量不足时,传统的单机数据库需要提升单机的存储空间来支持更大的数据写入量,而随着数据量膨胀,同样的SQL查询语句,查询的基础数据量增加必然会降低查询效率;同时随着数据量增加,数据库的访问压力通常也会成倍提升,造成单机数据库连接数到达极限,此时单机数据库就需要通过升级硬件规格,使用磁盘阵列,使用高端的存储介质设备和更高端的小型机服务器来承载数据量和访问量的增加,这个过程会伴随大量的数据迁移,为了保证数据的一致性通常需要停机数据迁移,对业务影响较大。
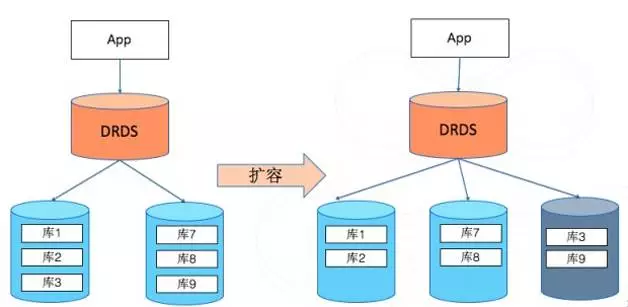
DRDS的分布式架构采用平滑扩容的方式来解决上述问题,通过增加更多的底层数据库实例来完成整体集群扩容。
平滑扩容的前提是用户需要按照前述的分库分表逻辑,将逻辑数据库拆分为多个物理分库,不同的分库落在不同的底层物理数据库机器上。分库分表的数量通常建议用户预估未来3-5年的数据量增长情况,按照这个数据量计算总体数据应该拆分为多少个分库,因为单个分库的数据量通常会有一个建议值,超过这个阈值就会造成单个节点性能下降。有了具体的分库数量后,就可以按照分库的逻辑将数据拆分到不同的存储实例节点上,当承载分库的物理数据库机器出现容量和连接数不足等瓶颈问题时,就可以新增物理数据库节点,将原有的分库迁移到新的物理数据库节点上,实现整体逻辑数据库的扩容。
扩容过程实际是物理数据迁移的过程,引擎层按照分库迁移后的逻辑先在物理节点上建立新的分库,然后保留一个时间点进行全量的数据迁移。完成全量迁移后,开始基于先前保留的时间点进行增量的数据追赶。当增量数据追赶到两边的数据几乎一致时,对数据库进行瞬时停写,将最后的数据追平,引擎层进行分库逻辑的路由切换,路由规则切换完成后就完成了核心的扩容逻辑,整个切换过程在毫秒级别完成。
为了保证数据本身的安全,便于扩容回滚,在路由规格切换完成后,迁移前后的逻辑分库数据还会进行实时同步,直到业务确认后,才可清理原有分库数据。
整个扩容过程对上层的业务访问几乎无感知,是完全平滑的扩容,但仍需注意扩容的操作尽量选择在数据库访问,尤其是写入的低谷期进行,避免切换时过多的数据追赶时间。
分布式MySQL执行引擎
分布式数据库的数据有规律地存储在多个底层存储实例上,数据物理存储的变化会造成与原生的数据库引擎不兼容,单机数据库所有的数据读取、写入、计算都在单一的物理机上执行,数据状态维持在单机上,主要的性能消耗在于磁盘的数据读取;而分布式架构下,数据和状态需要在多个数据库实例之间以及底层实例和Proxy之间进行传输,这会造成网络I/O消耗,而网络I/O对性能造成消耗相较于本地磁盘I/O和本地计算的性能开销而言要大得多。
因此分布式SQL引擎主要目标是实现与单机数据库SQL引擎的完全兼容,实现SQL的智能下推。能够智能分析SQL,解析出哪些SQL可以直接下发,哪些SQL需要进行优化改造,优化成什么样,以及路由到哪些实例节点上执行,充分发挥数据库实例的全部能力,减少网络之间的数据传输量,最终对不同实例处理后的少量结果数据进行聚合计算返回给应用调用方。这就是分布式SQL引擎的智能下推功能。
分布式引擎的职责包含SQL解析、优化、执行和合并四个流程,如图4所示。
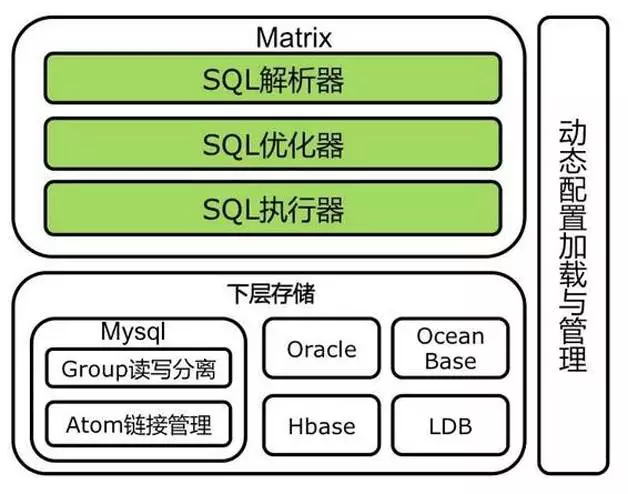
智能下核心原则有如下几个:
- 减少网络传输;
- 减少计算量,尽量将计算下推到下层的数据节点上,让计算在数据所在的机器上执行;
- 充分发挥下层存储的全部能力。
基于以上原则实现的SQL引擎,就可以做到服务能力线性扩展。比如一个简单的AVG操作,对于一些比较初级的分布式数据库模型而言,常见做法是把AVG直接下发到所有的存储节点,这样造成的结果就是语法兼容,语意不兼容,最终拿到的是错误结果。而DRDS的智能下推引擎,对SQL的语法做充分的语意兼容性适配,针对AVG操作,只能由引擎将逻辑AVG SQL解析优化为SUM和COUNT的SQL然后进行下推,由底层的数据库实例节点完成SUM和COUNT计算,充分利用底层节点的计算能力,在引擎层将各个存储节点的SUM和COUNT结果聚合计算,最终计算出AVG。这只是一个非常典型的案例,在分布式数据库模型下,多数据表的Join操作,归并排序的兼容性非常复杂,下文会针对典型的场景解析TDDL/DRDS如何解决分布式场景下的具体问题。
弹性扩展
TDDL/DRDS采用服务和存储分离的架构,DRDS实例服务层通过集群方式部署,由多个服务节点构成一个服务实例,通过负载均衡以及域名服务对外提供服务,多个服务节点之间无状态同步,平均负载处理用户请求。服务集群处理能力不足时,可随时扩充服务节点,增加服务处理能力。同样,业务低谷期也可适当降低集群规模,做到弹性的服务能力扩展。
对于一些大数据量OLAP的场景,对于单个Server节点的内存资源需求高时,也可通过提升单个Server节点的规格,做到垂直的能力扩展。
分布式Join和小表广播
分布式场景下的Join操作和单机不同,单机数据的Jion操作发生在单机上,不存在内部网络数据传输。
在分布式架构下的多个数据表Jion,如果参与Join的多表数据切分纬度不同,数据则按照不同的拆分纬度分散在不同的数据库实例上,Join操作可能产生跨多个物理分库的Join,就需要进行多个底层实例的大量数据传输,SQL的执行效率就得不到保证,因此要参与Join操作的数据表要尽量保持拆分纬度统一,让Join操作尽量发生在单机上,减少跨库Join。如果不能保持拆分纬度的统一,存在跨库Join操作,那么原则就是尽量减少Join操作的输出传输。
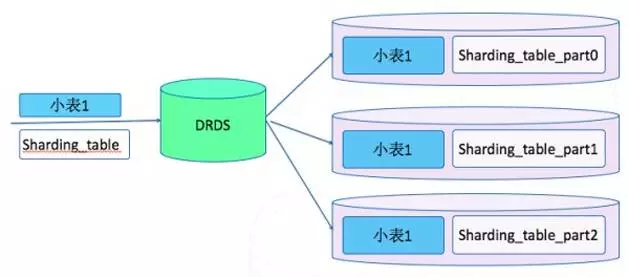
DRDS通常使用的Join算法基于Nested Loop,对于Join的左右两个表,首先从Join的左表(驱动表)取出数据,然后将所取出数据中Join列的值放到右表并进行IN查询,从而完成Join过程。因此,Join的左表数据量越少,DRDS对右表做IN查询就次数就越少,如果右表的数据量也很少或建有索引,则Join的速度更快。故而在DRDS中,Join驱动表的选择对于Join的优化非常重要。
而在实际数据库场景中,经常有一些源信息表,数据量较小,更新频度也很低,这些表无需拆分,类似这些源信息表通常采用单表模式,单表模式下一个逻辑表的数据统一存储在一个分库中,通常存储在“0”库,将这些表定义为“小表”,而其他业务数据量大、更新频率高的表仍旧采用分库分表的拆分模式。那这些“小表”和分库分表进行Join时,基于Nested Loop算法的原则,小表作为Join的驱动表会大大减少右表的IN查询次数,同时DRDS提供的小表广播功能,通过数据实时复制,将“小表”的全量数据和增量变更实时复制到分库分表上,将跨库的Join转化为单机Join操作,减少Server节点的计算,降低数据在多个底层实例之间的传输,Jion的效率提升会非常明显。
异构索引
异构索引是DRDS提升分布式查询效率的解决方案之一,能够解决分布式场景下数据拆分纬度和数据查询使用纬度不一致导致的低效问题。
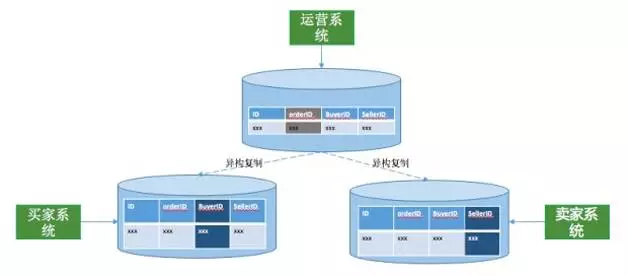
当数据表被拆分为多个分库分表时,数据在分库分表的分布规则就固定了。但是通常数据的业务使用场景非常复杂,如果数据的查询纬度和数据拆分分布的规则一致,单条SQL会在一个分库分表上执行;如果数据的查询使用纬度和数据拆分分布的规格不一致,单条SQL就很有可能在多个分库分表上执行,出现跨库查询,跨库查询会增加网络I/O的成本,查询效率必然下降。
解决这个问题的思路还是分布式数据库的一贯原则,让SQL执行在单库上完成,实际采用的方式就是用“空间换效率”的方案,也就是将同一份数据表,冗余存储多份,按照不同的业务使用场景进行拆分,保持拆分纬度和使用纬度统一,而多份数据之间会实时数据复制以解决数据一致性问题,这就是“异构索引”方案。当然异构索引表不能无限制滥用,过多的异构索引表会影响同步效率,对源数据表造成同步压力。
最佳实践
分布式SQL优化
SQL优化是数据库使用和运维的日常操作,分布式数据库针对SQL的优化不仅要考虑磁盘I/O的开销,更要关注网络I/O开销。为了优化SQL执行,其核心的优化思想就是减少网络I/O。为此,DRDS会尽量将原本DRDS这一层的工作均衡下发到其底层的各个分库(如RDS 等)来做。这样就可以将原本需要走网络的I/O开销转换为单机的磁盘I/O开销,从而提升查询执行效率。因此,我们在使用DRDS时若遇到了慢SQL,则需针对DRDS的特点将适当改写SQL。
首先是条件查询优化,DRDS的数据按拆分键进行水平切分,查询中若带上拆分键对于减少SQL在DRDS的执行时间很有意义。查询条件尽量带分库键,就可以让DRDS根据分库键的值将查询直接路由到特定的分库,这有助于避免DRDS做全库扫描。含分库键的条件精度越高,越有助于提高查询速度,也只有这样的优化才能充分发挥分布式架构查询的优势,便于后续查询能力的扩展。
其次针对Join的优化,选择条件查询数据量少的Join表作为左表(驱动表),降低右表IN查询的次数;在数据量少且变更量少的“广播表”参与的Jion操作,将“广播表”作为驱动表。
针对LIMIT OFFSET、COUNT语句,DRDS实际SQL执行是依次将OFFSET之前的记录数据读取出来,并丢弃,只保留OFFSET之后的数据,这样当OFFSET非常大时,读取的数据记录数很少,效率也很低,因为OFFSET之前的数据读取需要执行大量的磁盘I/O读取操作。优化方式是将SQL优化为对key的OFFSET读取和IN操作两个步骤,先读取OFFSET之后的记录key,内存中缓存这些key,然后再通过IN查询获取完整的记录信息,这样会大大减少磁盘I/O,效率提升非常明显。
分布式事务优化
分布式数据库的事务和SQL查询优化的逻辑是一样的原则,尽量让事务在单库中执行,只有在单库中执行,才可以在保持事务ACID特性的同时,还能线性地扩展事务能力。这种单库事务通常称为“强事务”。
实际业务也经常会面临分布式数据库架构下,数据库事务不可避免出现跨库执行。跨库事务必然涉及到一个事务在多个分库上进行事务分支的执行和状态同步,相比单机事务,分布式跨库事务的吞吐量和延迟会大大增加。而事务涉及的分库越多,事务边界越大,事务的延迟也会相应增加,性能就会出现线性衰减。
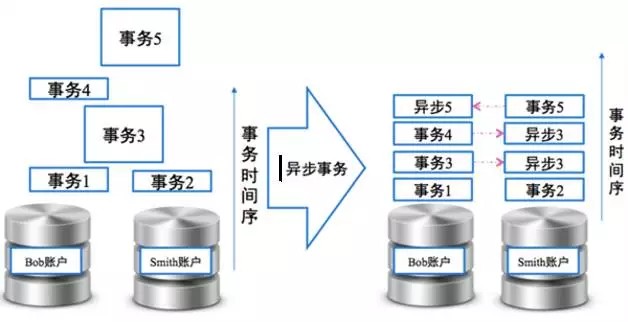
遇到跨库事务,通常的实践优化方式是通过“最终一致”事务保证事务执行的吞吐量。“最终一致”事务的原理是优先保证核心事务分支的正向执行,然后保存事务中间状态,其他事务分支异步执行,执行完成后达到最终的事务一致,避免跨库事务时间序列执行阻塞,提升事务吞吐量。如图8所示,事务3和事务5是跨库事务,事务分支先在左边库进行,异步的事务分支在右边分库执行,分别在自己所在的分库顺序执行,最终达到事务一致性。
单机数据库迁移到DRDS的流程
单机数据库迁移到分布式数据库要保证的就是业务正常运转、平滑过渡、减少运维,整个迁移分为三个步骤。
第一步,读写保持在原有的数据库上,数据通过复制机制写入分布式数据库,前提是分布式目标库表已经建好;
第二步,验证云上数据是否正确,切部分读取流量到目标的分布式数据库上读取线上压力验证(测试环境提前验证也可保证);
第三步,业务听写几分钟,读写的流量切换到目标库,数据反向复制到源单机数据库,保证随时可切换回单机数据库,同时也可做云下数据备份。
未来的发展
DRDS作为分布式数据体系中的数据库服务中间层,未来会适配更多底层存储引擎,在充分利用底存储节点的计算能力的同时,优化本身服务的计算能力,解决OLAP场景,成为能够完整覆盖OLTP和OLAP以及其他一些数据库服务场景的完备的分布式数据库服务体系。同时完备分布式数据库逻辑层的运维支持和分布式强一致事务的支持。
阿里巴巴分布式数据库服务DRDS研发历程的更多相关文章
- 云时代的分布式数据库:阿里分布式数据库服务DRDS
发表于2015-07-15 21:47| 10943次阅读| 来源<程序员>杂志| 27 条评论| 作者王晶昱 <程序员>杂志数据库DRDS分布式沈询 摘要:伴随着系统性能.成 ...
- 什么是分布式关系型数据库服务 DRDS
DRDS 产品简介 DRDS 是一款基于 MySQL 存储.采用分库分表技术进行水平扩展的分布式 OLTP 数据库服务产品,支持 RDS for MySQL 以及 POLARDB for MySQL, ...
- 阿里云DRDS:分布式数据库服务
最近在做阿里云相关的项目,用到阿里的很多接口服务的API,于是想把这段项目做个总结,顺便梳理下阿里云的云计算的相关知识点. DRDS:分布式数据库服务. 1.相关术语 DRDS(Distribute ...
- Cobar_基于MySQL的分布式数据库服务中间件
Cobar是阿里巴巴研发的关系型数据的分布式处理系统,是提供关系型数据库(MySQL)分布式服务的中间件,该产品成功替代了原先基于Oracle的数据存储方案,它可以让传统的数据库得到良好的线性扩展,并 ...
- 阿里巴巴分布式服务框架 Dubbo 介绍
Dubbo是阿里巴巴内部的SOA服务化治理方案的核心框架,每天为2000+ 个服务提供3,000,000,000+ 次访问量支持,并被广泛应用于阿里巴巴集团的各成员站点.Dubbo自2011年开源后, ...
- 【转】阿里巴巴分布式服务框架 Dubbo 团队成员梁飞专访
原文链接:http://www.iteye.com/magazines/103 Dubbo是阿里巴巴内部的SOA服务化治理方案的核心框架,每天为2000+ 个服务提供3,000,000,000+ ...
- 阿里巴巴分布式服务框架HSF
HSF称之为高速服务框架HSF(High-speed Service Framework),是在阿里巴巴广泛使用的分布式RPC服务框架. HSF连通不同的业务系统,解耦系统间的实现依赖.HSF从分布式 ...
- 阿里巴巴分布式服务框架dubbo学习笔记
Dubbo是什么? Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案.简单的说,dubbo就是个服务框架,如果没有分布式的需求,其实是不需要用的 ...
- 阿里巴巴分布式服务框架Dubbo介绍(1)主要特色
引言 互联网服务和BS架构的传统企业软件相比,系统规模上产生了量级的差距.例如 传统BS企业内部门户只需要考虑数百人以及几千人的访问压力,而大型互联网服务有时需要考虑的是千万甚至上亿的用户: 传统企业 ...
随机推荐
- Ajax的跨域请求——JSONP的使用
一.什么叫跨域 域当然是别的服务器 (说白点就是去别服务器上取东西) 只要协议.域名.端口有任何一个不同,都被当作是不同的域. 总而言之,同源策略规定,浏览器的ajax只能访问跟它的HTML页面同源( ...
- 20155311 实验三 敏捷开发与XP实践 实验报告
20155311 实验三 敏捷开发与XP实践 实验报告 实验内容 XP基础 xp核心工具 相关工具 实验要求 没有Linux基础的同学建议先学习<Linux基础入门(新版)><Vim ...
- CH03 课下作业
CH03 课下作业 缓冲区溢出漏洞实验 缓冲区溢出攻击:通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,造成程序崩溃或使程序转而执行其它指令,以达到攻击的目的. 缓冲区溢出 ...
- 20145226夏艺华 《Java程序设计》第9周学习总结
教材学习内容总结 学习目标 了解JDBC架构 掌握JDBC架构 掌握反射与ClassLoader 了解自定义泛型和自定义枚举 会使用标准注解 第16章 整合数据库 16.1 JDBC入门 (一)JDB ...
- 记一次SpringBoot使用WebUploader的坑
问题: B/S通常都会涉及到文件的上传,普通文件上传使用文件框,后台接收文件即可 我遇到的问题是要开发一个大文件上传的功能,那就肯定要支持文件的分片 分析: 1.参考网上的资料后,通常的多文件和大文件 ...
- .net core 无法获取本地变量或参数的值,因为它在此指令指针中不可用,可能是因为它已经被优化掉了
使用vs 发布.net CORE 项目,调试遇到了“无法获取本地变量或参数的值,因为它在此指令指针中不可用,可能是因为它已经被优化掉了”这个问题,弄了半天才发现是发布的时候没有设置为debug,做个总 ...
- Drupal8 新建第一个模块
参考: https://www.drupal.org/developing/modules/8 https://www.drupal.org/node/1915030 https://www.drup ...
- 如何在存储过程的IN操作中传递字符串变量
原始SQL如下: SELECT MONTH(OrderTime) AS datetype, SUM(DeliveryCount) AS decount, Region FROM (SELECT dbo ...
- javaweb总结(四十)——编写自己的JDBC框架
一.元数据介绍 元数据指的是"数据库"."表"."列"的定义信息. 1.1.DataBaseMetaData元数据 Connection.g ...
- python编码和小数据池
python_day_6 一. 回顾上周所有内容一. python基础 Python是一门解释型. 弱类型语言 print("内容", "内容", end=&q ...