Lucene原理之概念
概念:
数据分两种:
1、结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
2、非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。(半结构化数据:如XML,HTML等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理)
非结构化数据又一种叫法叫全文数据。因此:全文索引就是非结构化的数据索引。Lucene就是全文索引库。
全文检索大体分两个过程,索引创建 (Indexing) 和搜索索引 (Search) 。
索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
于是全文检索就存在三个重要问题:
1. 索引里面究竟存些什么?(Index)
2. 如何创建索引?(Indexing)
3. 如何对索引进行搜索?(Search)
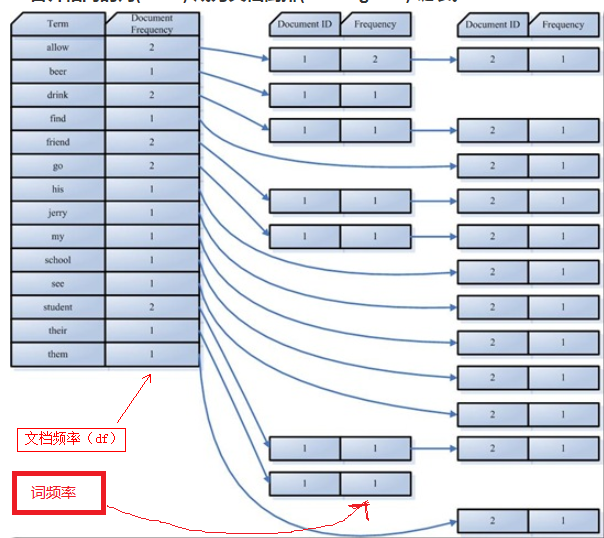
一、索引结构:
索引由字典+倒排表组成。
字典:就是我们需要搜索的词。
倒排表:建立了字典和文档的映射。(每个字符串都指向包含本身的文档链表)
图:
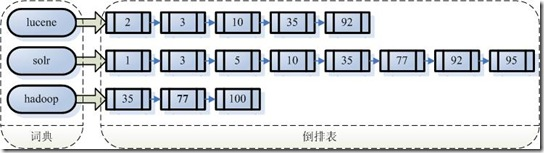
排序(平分):
df:Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
tf:Term Frequency 即词频率,表示此文件中包含了几个此词(Term)。
二、创建索引:
创建索引的步骤:
1、需要索引的文档。
2、将文档分词(Tokenizer)
分词的需要做的事情:
1)、去除标点。
2)、去除停词(所谓停词就是一种语言中最普通的一些单词,由于没有特别的意义,因而大多数情况下不能成为搜索的关键词,因而创建索引时,这种词会被去掉而减少索引的大小)。
3)、分词得到词元(字典)。
3、将词元(Token)传递给语言处理组件(Linguistic Processor)。
对于英语,语言处理组件(Linguistic Processor) 一般做以下几点:
1)、变为小写(Lowercase) 。
2)、将单词缩减为词根形式,如“cars ”到“car ”等。这种操作称为:stemming 。
3)、将单词转变为词根形式,如“drove ”到“drive ”等。这种操作称为:lemmatization(词型还原) 。
4、将得到的词(Term)传给索引组件(Indexer)。
索引组件(Indexer)主要做以下几件事情:
1)、利用得到的词(Term)创建一个字典。
2)、对字典按字母顺序进行排序。
3)、合并相同的词(Term) 成为文档倒排(Posting List) 链表。
三、搜索索引:
搜索的步骤:
1、用户输入查询语句。举个例子,用户输入语句:lucene AND learned NOT hadoop。
2、对查询语句进行词法分析,语法分析,及语言处理。
1)、词法分析主要用来识别单词和关键字。
2)、语法分析主要是根据查询语句的语法规则来形成一棵语法树。
3)、语言处理同索引过程中的语言处理几乎相同。
3、搜索索引,得到符合语法树的文档。
此步骤有分几小步:
1)、首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
2)、其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
3)、然后,将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,从而得到既包含lucene又包含learn而且不包含hadoop的文档链表。
4)、最后,此文档链表就是我们要找的文档。
4、根据得到的文档和查询语句的相关性,对结果进行排序。
Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
ref:
https://www.cnblogs.com/forfuture1978/category/300665.html
Lucene原理之概念的更多相关文章
- Atitit WebDriver技术规范原理与概念
Atitit WebDriver技术规范原理与概念 1. Book haosyo ma1 2. WebDriver是W3C的一个标准,由Selenium主持.1 3. WebDriver如何工作 (z ...
- 免费的Lucene 原理与代码分析完整版下载
Lucene是一个基于Java的高效的全文检索库.那么什么是全文检索,为什么需要全文检索?目前人们生活中出现的数据总的来说分为两类:结构化数据和非结构化数据.很容易理解,结构化数据是有固定格式和结构的 ...
- Lucene的基本概念----转载yufenfei的文章
Lucene的基本概念 Lucene是什么? Lucene是一款高性能.可扩展的信息检索工具库.信息检索是指文档搜索.文档内信息搜索或者文档相关的元数据搜索等操作. 信息检索流程如下: 1. 将即将检 ...
- Lucene解析 - 基本概念
Elasticsearch 权威指南中文版 https://www.elastic.co/guide/cn/elasticsearch/guide/cn/index.html 对于跳跃表,我们看 ...
- lucene原理及源码解析--核心类
马云说:大家还没搞清PC时代的时候,移动互联网来了,还没搞清移动互联网的时候,大数据时代来了. 然而,我看到的是:在PC时代搞PC的,移动互联网时代搞移动互联网的,大数据时代搞大数据的,都是同一伙儿人 ...
- lucene原理
lucene查找原理: https://yq.aliyun.com/articles/581877
- springAOP原理以及概念
需求:1.拦截所有业务方法2.判断用户是否有权限,有权限就让他执行业务方法,没有权限就不允许执行.(是否有权限是根据user是否为null作为判断依据) 思考: 我们该如何实现? 思路1: 我们在每个 ...
- 《lucene原理与代码分析》笔记
1.全文索引相对于顺序扫描的优势:一次索引,多次使用 2.创建索引的步骤:(1)要索引的原文档 (2)将原文档传给分词组件(Tokenizer)分词组件会做如下事情:(此过程称为Tokenize)a. ...
- Spring框架IOC和AOP的实现原理(概念)
IoC(Inversion of Control) (1). IoC(Inversion of Control)是指容器控制程序对象之间的关系,而不是传统实现中,由程序代码直接操控.控制权由应用代码中 ...
随机推荐
- MYSQL处理高并发,防止库存超卖(图解)
抢购场景完全靠数据库来扛,压力是非常大的,我们在最近的一次抢购活动改版中,采用了redis队列+mysql事务控制的方案,画了个简单的流程图: 先来就库存超卖的问题作描述:一般电子商务网站都会遇到如团 ...
- placeholder插件详解
placeholder插件是用来实现input或者textarea文本框显示默认文字的功能,当获得焦点时,默认文字消失.用户按删除键,把输入的字符删除掉,并失去焦点时,默认文字又出现等功能.使用此插件 ...
- mybatis pagehelper多数据源配置的坑
我用spring boot配置了2个数据源的工程用来同步不同库的数据,发现如果配置成如下格式报错 #分页配置pagehelper: helper-dialect: mysql reasonable: ...
- byte转文件流 下载到本地
此方法将byte类型文件转为文件流保存到本地 byte 经过BASE64Decoder 进行编码之后的类型 所以需要解码 防止出现乱码及文件损毁 /** * byte 转文件 下载到本地 * @par ...
- iOS几个功能:1.摇一摇;2.震动;3.简单的摇动动画;4.生成二维码图片;5.发送短信;6.播放网络音频等
有一个开锁的功能,具体的需求就类似于微信的“摇一摇”功能:摇动手机,手机震动,手机上的锁的图片摇动一下,然后发送开锁指令.需求简单,但用到了许多方面的知识. 1.摇一摇 相对这是最简单的功能了. 在v ...
- #.NET# DataGrid显示大量数据——DataGridView虚模式
要解决的目标:如何让 Datagridview 快速平滑显示大量数据 通常,Winform 下的表格控件是很"低效"的,如 DataGrid 和 DataGridView.造成低效 ...
- 拖进Xshell终端窗口文件上传
XShell已经内置rz 直接从Windows拖文件进去终端 http://www.jb51.net/LINUXjishu/163820.html 借助securtCRT,使用linux命令sz可以很 ...
- media(适配)
媒体类型 1.all 所有媒体 2.braille 盲文触觉设备 3.embossed 盲文打印机 4.print 手持设备 5.projection 打印预览 ...
- java几个经典的算法题目----------查询子串和等于已知数字
给出一个排序好的数组和一个数,求数组中连续元素的和等于所给数的子数组 public class testClockwiseOutput { public static void main(String ...
- Spring @Transactional踩坑记
@Transactional踩坑记 总述 Spring在1.2引入@Transactional注解, 该注解的引入使得我们可以简单地通过在方法或者类上添加@Transactional注解,实现事务 ...