Float类型出现舍入误差的原因(round 取位)
在练习时,输入如下代码:
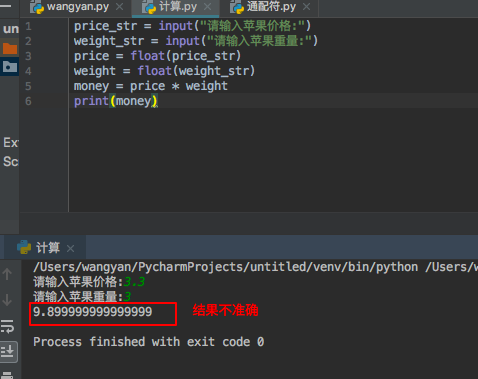
结果不准确。
原因:https://blog.csdn.net/bitcarmanlee/article/details/51179572
浮点数一个普遍的问题就是在计算机的世界中,浮点数并不能准确地表示十进制。并且,即便是最简单的数学运算,也会带来不可控制的后果。因为,在计算机的世界中只认识0与1

python中的decimal模块可以解决上面的烦恼
decimal模块中,可以通过整数,字符串或原则构建decimal.Decimal对象。如果是浮点数,特别注意因为浮点数本身存在误差,需要先将浮点数转化为字符串。

当然精度提升的同时,肯定带来的是性能的损失。在对数据要求特别精确的场合(例如财务结算),这些性能的损失是值得的。但是如果是大规模的科学计算,就需要考虑运行效率了。毕竟原生的float比Decimal对象肯定是要快很多的。
使用上述办法解决后:
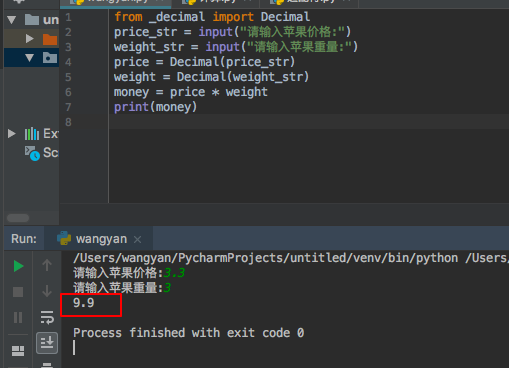
知识点总结:
1. decimal模块:
Python提供了decimal模块用于十进制数学计算,它具有以下特点:
- 提供十进制数据类型,并且存储为十进制数序列;
- 有界精度:用于存储数字的位数是固定的,可以通过decimal.getcontext().prec=x 来设定,不同的数字可以有不同的精度
- 浮点:十进制小数点的位置不固定(但位数是固定的)
首先是float累加产生误差的原因,该部分转自:http://blog.csdn.net/zhrh0096/article/details/38589067
1. 浮点数IEEE 754表示方法
要搞清楚float累加为什么会产生误差,必须先大致理解float在机器里怎么存储的,具体的表示参考[1] 和 [2], 这里只介绍一下组成
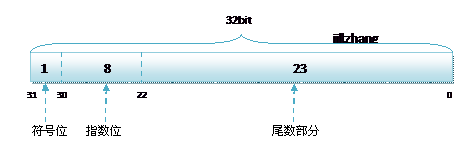
由上图可知(摘在[2]), 浮点数由: 符号位 + 指数位 + 尾数部分, 三部分组成。由于机器中都是由二进制存储的,那么一个10进制的小数如何表示成二进制。例如: 8.25转成二进制为1000.01, 这是因为 1000.01 = 1*2^3 + 0*2^2 + 0*2^1 + 0*2^0 + 0*2^-1 + 2*2^-2 = 1000.01.
(2)float的有效位数是6-7位,这是为什么呢?因为位数部分只有23位,所以最小的精度为1*2^-23 在10^-6和10^-7之间,接近10^-7,[3]中也有解释
那么为什么float累加会产生误差呢,主要原因在于两个浮点数累加的过程。
2. 两个浮点数相加的过程
两浮点数X,Y进行加减运算时,必须按以下几步执行(可参考 [4] 中插图):
(1)对阶,使两数的小数点位置对齐,小的阶码向大的阶码看齐。
(2)尾数求和,将对阶后的两尾数按定点加减运算规则求和(差)。
(3)规格化,为增加有效数字的位数,提高运算精度,必须将求和(差)后的尾数规格化。
(4)舍入,为提高精度,要考虑尾数右移时丢失的数值位。
(5)判断结果,即判断结果是否溢出。
关键就在与对阶这一步骤,由于float的有效位数只有7位有效数字,如果一个大数和一个小数相加时,会产生很大的误差,因为尾数得截掉好多位。例如:
123 + 0.00023456 = 1.23*10^2 + 0.000002 * 10^2 = 123.0002
那么此时就会产生0.00003456的误差,如果累加多次,则误差就会进一步加大。
解决方式有几种,但都不是最佳方式,参考:http://bbs.csdn.net/topics/390549664
3.解决方法
方法一
Kahan summation算法
https://en.wikipedia.org/wiki/Kahan_summation_algorithm
- function KahanSum(input)
- var sum = 0.0
- var c = 0.0 // A running compensation for lost low-order bits.
- for i = 1 to input.length do
- var y = input[i] - c // So far, so good: c is zero.
- var t = sum + y // Alas, sum is big, y small, so low-order digits of y are lost.
- c = (t - sum) - y // (t - sum) cancels the high-order part of y; subtracting y recovers negative (low part of y)
- sum = t // Algebraically, c should always be zero. Beware overly-aggressive optimizing compilers!
- next i // Next time around, the lost low part will be added to y in a fresh attempt.
- return sum
- 1
伪代码如上
解决方法就是把多余的误差部分算出来(c),再在下一次循环减去这个误差
方法二
- int main()
- {
- float f = 0.1;
- float sum = 0;
- sum+=add(f,4000000);
- cout<<sum<<endl;
- return 0;
- }
- float add(float f,int count)
- {
- if(count==1)
- return f;
- else
- return add(f,count/2)+add(f,count-count/2);
- }
- 1
二分法递归计算加法,这样会没有误差,但是函数调用消耗大(尤其是多次)
方法三
使用double,精度更高,但是本来是没有必要用这么高精度的
方法四
ieee浮点数,为了规格化,精度每超过2的整数次幂,精度要下降一位,
你的f是0.1,float位数是23,当sum足够大的时候,会出现 sum+f==sum 的情况,这个是ieee标准,
和C++没关系,事实上编译器应该已经做了浮点精度调整了,你这结果误差算小的了.
避免这种误差的方法就是浮点数,永远不要让一个很大的数去加上一个很小的数.不知你这段代码的目的是
什么,但如果你改成这样,误差会小很多:
- float f = 0.1;
- float sum = 0;
- for( i=0; i<100; i++)
- {
- int sumEachBig=0;
- for(....k<400....)
- {
- int sumEachSmall=0;
- for(....j<100.....)
- sumEachSmall += f;
- sumEachBig+=sumEachSmall;
- }
- sum += sumEachBig;
- }
Float类型出现舍入误差的原因(round 取位)的更多相关文章
- 当向计算机中存入一个float类型的数值2.2 后,在从计算机中读出输出,这时2.2 的值已经发生了变化(转)
problom : 'f1' value hava been changed when output. reason : the binary repersentation of 2.2f is : ...
- Java中为什么long能自动转换成float类型
刷题时候看到一个float和long相互转换的问题,float向long转换的时候不会报错,一个4个字节一个8个字节,通过baidu找到了答案. 下面转载自http://blog.csdn.net/s ...
- 【转】float类型在内存中的表示
http://www.cnblogs.com/onedime/archive/2012/11/19/2778130.html http://blog.csdn.net/adream307/articl ...
- 为什么Java中Long类型的比float类型的范围小?
为什么Long类型的比float类型的范围小? 2015-09-15 22:36 680人阅读 评论(0) 收藏 举报 版权声明:本文为博主原创文章,未经博主允许不得转载. 作为一个常识,我们都知道浮 ...
- mysql下float类型使用一些误差详解
单精度浮点数用4字节(32bit)表示浮点数采用IEEE754标准的计算机浮点数,在内部是用二进制表示的如:7.22用32位二进制是表示不下的.所以就不精确了. mysql中float数据类型的问题总 ...
- SQL 对float类型列进行排序引发的异常
车祸现场 要求:根据学分和完成时间获取前200名学员,当学分相同时,完成时间较早的排在前面 可以明显看到,完成时间为4.1号的记录排在了3.27号前面. 事故原因 float 表示近似数值,存在精度损 ...
- float类型进行计算精度丢失的问题
今天一个案子,用户反映数量差异明明是 2.0-1.8,显示的结果却为0.20000005,就自己写了段方法测试了一下:package test1;public class Test2 {/*** @p ...
- JAVA 没有重载运算符,那么 String 类型的加法是怎么实现的,以及String类型不可变的原因和好处
1, JAVA 不具备 C++ 和 C# 一样的重载运算符 来实现类与类之间相互计算 的功能 这其实一定程度上让编程失去了代码的灵活性, 但是个人认为,这在一定程度上减少了代码异常的概率 ...
- 转:Mysql float类型where 语句判断相等问题
原文地址:https://www.2cto.com/database/201111/111983.html 原文内容如下: Mysql where 语句中有float 类型数据判断相等时,检索不出记录 ...
随机推荐
- APP的缓存文件放在哪里?
只要是需要进行联网获取数据的APP,都会在本地产生缓存文件.那么,这些缓存文件到底放在什地方合适呢?系统有没有给我们提供建议的缓存位置呢?不同的缓存位置有什么不同呢? 考虑到卸载APP必须删除缓存 在 ...
- 如何在单片机上使用printf函数(printf)(avr)(stm)(lpc)(单片机)(转)
摘要: 当我们在调试代码时,通常需要将程序中的某个变量打印至PC机上,来判断我们的程序是否按预期的运行,printf函数很好的做到了这一点,它能直接以字符的方式输出变量名和变量的值,printf ...
- struts2基础---->第一个Struts2程序
学习struts2的第一个程序,这里只会涉及到简单的代码编写.有一个夜晚我烧毁了所有的记忆,从此我的梦就透明了:有一个早晨我扔掉了所有的昨天,从此我的脚步就轻盈了. Struts的项目
- 谈谈java中的构造函数
from 本篇博文主要是为新手.对java语言感兴趣的人和那些没有系统学习过java基础知识的人进行一个总结,在文章中对构造函数进行了较为详细的说明和讨论,也包含了我个人对于java面向对象中构造函数 ...
- MyBatis——Java API
Java API 既然你已经知道如何配置 MyBatis 和创建映射文件,你就已经准备好来提升技能了. MyBatis 的 Java API 就是你收获你所做的努力的地方.正如你即将看到的,和 JDB ...
- apt-get install的默认安装路径
apt-get 命令 sudo apt-get update sudo apt-get install tree sudo apt-get -y install tree //跳过系统提示,直接安装. ...
- linux下php安装
nginx中配置php: http://www.111cn.net/sys/nginx/64044.htm
- javascript飞机大战-----001分析
1.游戏引擎 首先要做飞机大战要考虑的是这个游戏被分成了哪几大部分?这样我们一块一块去做,特别清晰明了.那么接下来我们就简单的分析下飞机大战分成了哪几大部分 1.游戏引擎 2.英雄机 3.敌机 4.子 ...
- SaltStack配置管理-jinja模板
上一篇:SaltStack配置管理-状态间关系 需求:需要apache配置文件里面监听的端口是每个minion本地的地址 saltstack默认的模板是jinjia模板 参考文档:http://doc ...
- 使用pidstat查看进程资源使用情况
简介 pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存.设备IO.任务切换.线程等.pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上 ...