沉淀再出发:mongodb的使用
沉淀再出发:mongodb的使用
一、前言
这是一篇很早就想写却一直到了现在才写的文章。作为NoSQL(not only sql)中出色的一种数据库,MongoDB的作用是非常大的,这种文档型数据库,其实本质上的增删改查操作,封装的都和sql差不多了,最重要的确实其中代表的理念和设计的初衷,可以说NoSQL是对sql的一种有益的补充,同时也提升了我们对于一次写入多次读取的数据的查询能力,这种能力在大数据时代是非常有用的,可以说我们每天操作的应用程序之中,有百分之九十多的都是读的操作,而剩下的才是写操作,因此,读操作的读取速度直接影响了客户的体验,非常的重要和有意义。
二、MongoDB的简单介绍
2.1、MongoDB的简介
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
MongoDB安装简单。
2.2、MongoDB的下载和安装
首先我们从MongoDB的官网上下载该软件,之后我们进行安装,另外关于MongoDB的各种语言的驱动,我们可以从这里找到。
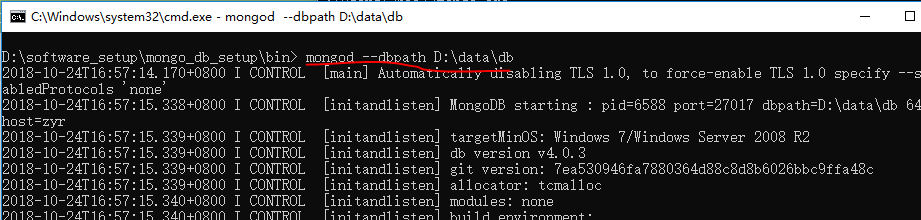
在下载之后,我们开始安装,自定义安装目录,然后进行一些配置并且启动:
创建数据目录:MongoDB将数据目录存储在 db 目录下。但是这个数据目录不会主动创建,我们在安装完成后需要创建它。请注意,数据目录应该放在根目录下。比如D:\data\db。
命令行下运行 MongoDB 服务器:为了从命令提示符下运行 MongoDB 服务器,必须从 MongoDB 目录的 bin 目录中执行 mongod.exe 文件。
mongod --dbpath D:\data\db
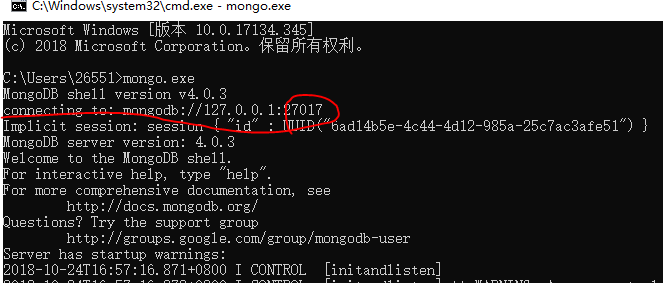
连接MongoDB:我们可以在命令窗口中运行 mongo.exe 命令即可连接上 MongoDB,执行如下命令:
mongo.exe
或者我们将MongoDB做成服务并启动:
配置 MongoDB 服务
1、管理员模式打开命令行窗口,创建目录,执行下面的语句来创建数据库和日志文件的目录
mkdir D:\data\db
mkdir D:\data\log
2、创建配置文件:该文件必须设置 systemLog.path 参数,包括一些附加的配置选项更好。
例如,创建一个配置文件位于 D:\mongodb\mongod.cfg,其中指定 systemLog.path 和 storage.dbPath。具体配置内容如下:
systemLog:
destination: file
path: D:\data\log\mongod.log
storage:
dbPath: D:\data\db
3、安装 MongoDB服务:通过执行mongod.exe,使用--install选项来安装服务,使用--config选项来指定之前创建的配置文件。
mongod.exe --config "D:\mongodb\mongod.cfg" --install
4、启动MongoDB服务
net start MongoDB
5、关闭MongoDB服务
net stop MongoDB
6、移除 MongoDB 服务
D:\mongodb\bin\mongod.exe --remove
命令行下运行MongoDB服务器和配置 MongoDB 服务任选一个方式启动就可以。
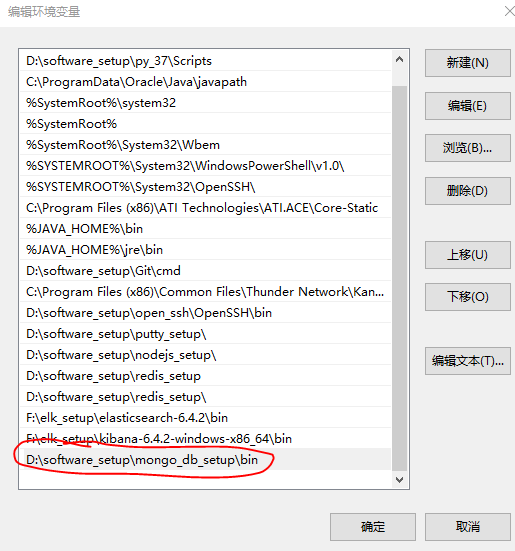
同时我们可以设置环境变量:
2.3、MongoDB的本质
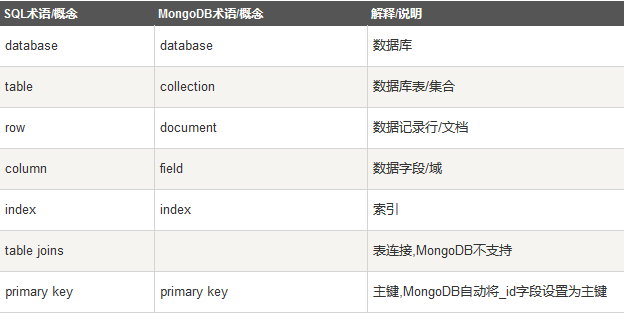
最重要的是我们要理解MongoDB的本质,让我们对比一下sql和MongoDB的术语的区别:
数据库:
一个mongodb中可以建立多个数据库。MongoDB的默认数据库为"db",该数据库存储在data目录中。MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。"show dbs" 命令可以显示所有数据的列表。执行 "db" 命令可以显示当前数据库对象或集合。运行"use"命令,可以连接到一个指定的数据库。数据库名可以是满足以下条件的任意UTF-8字符串。
不能是空字符串("")。
不得含有' '(空格)、.、$、/、\和\ (空字符)。
应全部小写。
最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,
比如列出所有的数据库或者关闭服务器。
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
文档:
文档是一组键值(key-value)对(即BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。需要注意的是:
文档中的键/值对是有序的。
文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
MongoDB区分类型和大小写。
MongoDB的文档不能有重复的键。
文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
键不能含有\ (空字符)。这个字符用来表示键的结尾。
.和$有特别的意义,只有在特定环境下才能使用。
以下划线"_"开头的键是保留的(不是严格要求的)。
集合:
集合就是 MongoDB 文档组,类似于 RDBMS 中的表格。集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。当第一个文档插入时,集合就会被创建。合法的集合名:
集合名不能是空字符串""。
集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
集合名不能以"system."开头,这是为系统集合保留的前缀。
用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非要访问这种系统创建的集合,
否则千万不要在名字里出现$。
capped collections:
Capped collections 就是固定大小的collection。它有很高的性能以及队列过期的特性(过期按照插入的顺序)。有点和 "RRD" 概念类似。Capped collections是高性能自动的维护对象的插入顺序。它非常适合类似记录日志的功能,和标准的collection不同,必须要显式的创建一个capped collection,指定一个collection的大小,单位是字节。
collection的数据存储空间值提前分配的。要注意的是指定的存储大小包含了数据库的头信息。
比如:db.createCollection("mycoll", {capped:true, size:})
在capped collection中,能添加新的对象。
能进行更新,然而,对象不会增加存储空间。如果增加,更新就会失败 。
数据库不允许进行删除。使用drop()方法删除collection所有的行。
注意: 删除之后,必须显式的重新创建这个collection。
在32bit机器中,capped collection最大存储为1e9( 1X109)个字节。
元数据:
数据库的信息是存储在集合中。它们使用了系统的命名空间:dbname.system.*
在MongoDB数据库中名字空间 <dbname>.system.* 是包含多种系统信息的特殊集合(Collection),对于修改系统集合中的对象有如下限制。在{{system.indexes}}插入数据,可以创建索引。但除此之外该表信息是不可变的(特殊的drop index命令将自动更新相关信息)。{{system.users}}是可修改的。 {{system.profile}}是可删除的。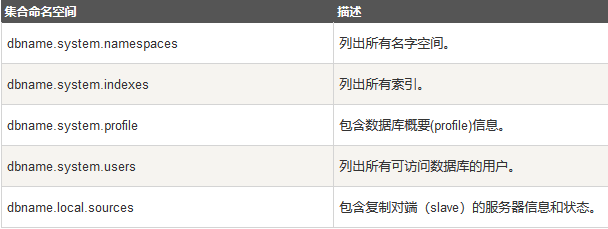
MongoDB 数据类型:
String 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF- 编码的字符串才是合法的。
Integer 整型数值。用于存储数值。根据你所采用的服务器,可分为 位或 位。
Boolean 布尔值。用于存储布尔值(真/假)。
Double 双精度浮点值。用于存储浮点值。
Min/Max keys 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。
Array 用于将数组或列表或多个值存储为一个键。
Timestamp 时间戳。记录文档修改或添加的具体时间。
Object 用于内嵌文档。
Null 用于创建空值。
Symbol 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。
Date 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。
Object ID 对象 ID。用于创建文档的 ID。
Binary Data 二进制数据。用于存储二进制数据。
Code 代码类型。用于在文档中存储 JavaScript 代码。
Regular expression 正则表达式类型。用于存储正则表达式。
比如ObjectId:ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
前 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 个小时
接下来的 个字节是机器标识码
紧接的两个字节由进程 id 组成 PID
最后三个字节是随机数

三、MongoDB的使用
3.1、连接MongoDB服务器
标准 URI 连接语法:
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
mongodb:// 这是固定的格式,必须要指定。
username:password@ 可选项,如果设置,在连接数据库服务器之后,驱动都会尝试登陆这个数据库
host1 必须的指定至少一个host, host1 是这个URI唯一要填写的。它指定了要连接服务器的地址。如果要连接复制集,请指定多个主机地址。
portX 可选的指定端口,如果不填,默认为27017
/database 如果指定username:password@,连接并验证登陆指定数据库。若不指定,默认打开 test 数据库。
?options 是连接选项。如果不使用/database,则前面需要加上/。所有连接选项都是键值对name=value,键值对之间通过&或;(分号)隔开
3.2、数据库的创建、查看、删除等操作
MongoDB 创建数据库的语法格式如下:
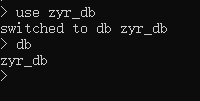
use DATABASE_NAME
如果数据库不存在,则创建数据库,否则切换到指定数据库。
如果想查看所有数据库,可以使用 show dbs 命令:
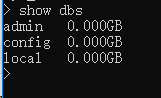
可以看到,我们刚创建的数据库 zyr_db 并不在数据库的列表中, 要显示它,我们需要向 zyr_db 数据库插入一些数据。
db.zyr_db.insert({"name":"朱彦荣"})})
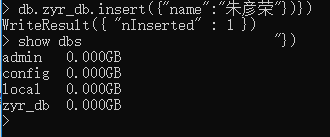
同样的,在MongoDB中,集合只有在内容插入后才会创建!,也就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
删除数据库:
db.dropDatabase()

3.3、集合的相关操作
创建集合:
db.createCollection(name, options)
options 可以是如下参数(在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段):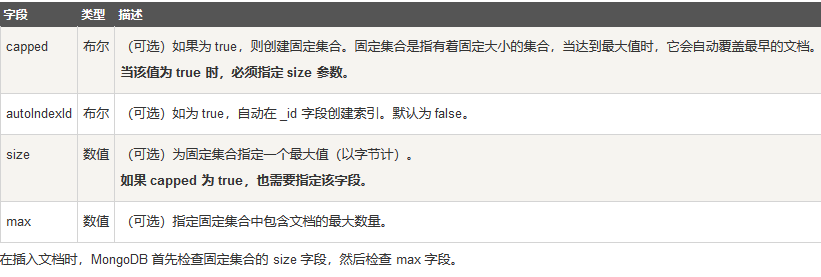
比如:
db.createCollection("zyr_col")
db.createCollection("zyrcol", { capped : true, autoIndexId : true, size : , max : } )
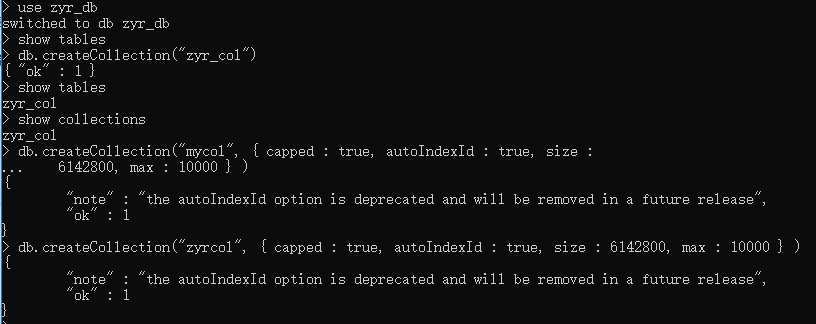
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
db.mycol2.insert({"name" : "zyr,lsx"})
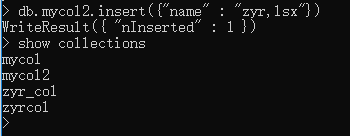
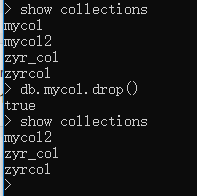
删除集合使用:
db.collection.drop()
比如:
3.4、文档操作
插入文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
db.col.insert({title: '插入文档',
description: 'MongoDB 是一个 Nosql 数据库',
by: 'zyr',
url: 'http://www.cnblogs.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes:
})
以上实例中 col 是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
db.col.find()
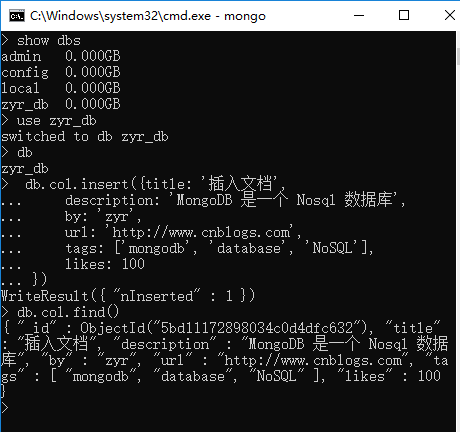
插入文档也可以使用 db.col.save(document) 命令。如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
MongoDB 更新文档
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。
update() 方法
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
db.col.update({'title':'插入文档'},{$set:{'title':'更新文档'}})
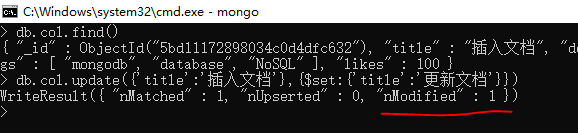
save() 方法
save() 方法通过传入的文档来替换已有文档。语法格式如下:
db.collection.save(
<document>,
{
writeConcern: <document>
}
)
document : 文档数据。
writeConcern :可选,抛出异常的级别。
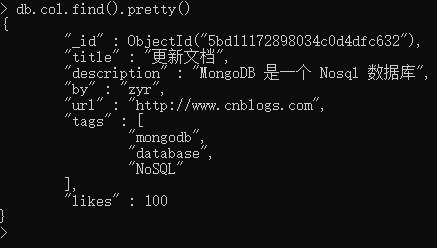
db.col.save({
"_id" : ObjectId("5bd11172898034c0d4dfc632"),
"title" : "朱彦荣",
"description" : "朱彦荣是一个学生",
"by" : "zyr",
"url" : "http://www.cnblogs.com",
"tags" : [
"mongodb",
"NoSQL"
],
"likes" :
})

MongoDB 删除文档
MongoDB remove()函数是用来移除集合中的数据。MongoDB数据更新可以使用update()函数。在执行remove()函数前先执行find()命令来判断执行的条件是否正确,这是一个比较好的习惯。
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 ,则只删除一个文档。
writeConcern :(可选)抛出异常的级别。
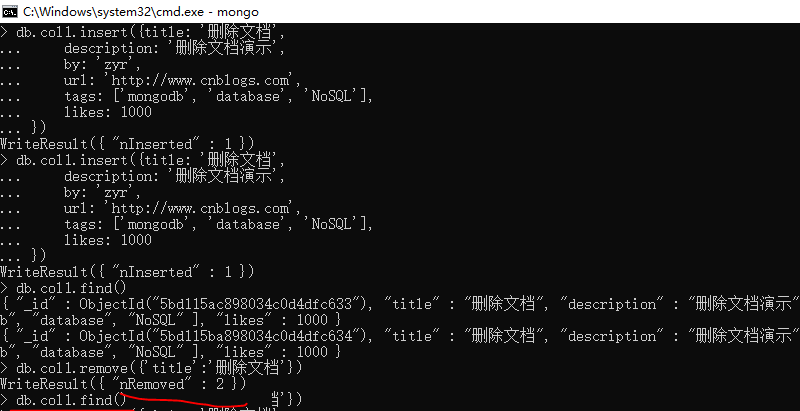
db.col1.insert({title: '删除文档',
description: '删除文档演示',
by: 'zyr',
url: 'http://www.cnblogs.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes:
})
db.col1.remove({'title':'删除文档'})
如果只想删除第一条找到的记录可以设置 justOne 为 1,如下所示:
db.COLLECTION_NAME.remove(DELETION_CRITERIA,)
db.col1.remove({'title':'删除文档'},)

如果想删除所有数据,可以使用以下方式(类似常规 SQL 的 truncate 命令):
db.col1.remove({})

MongoDB 查询文档
MongoDB 查询文档使用 find() 方法。
find() 方法以非结构化的方式来显示所有文档。
db.collection.find(query, projection)
query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
projection 参数的使用方法:
db.collection.find(query, projection)
若不指定 projection,则默认返回所有键,指定 projection 格式如下,有两种模式
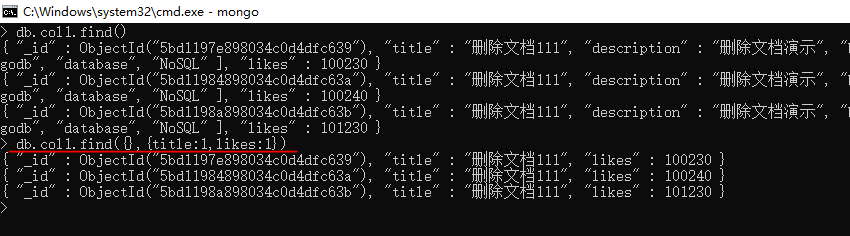
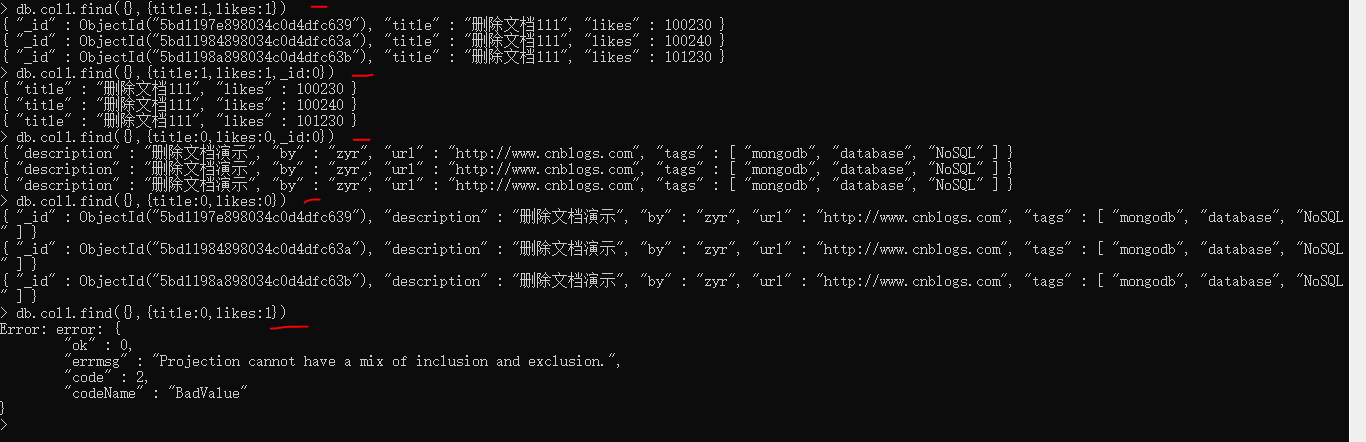
db.collection.find(query, {title: , by: }) // inclusion模式 指定返回的键,不返回其他键
db.collection.find(query, {title: , by: }) // exclusion模式 指定不返回的键,返回其他键
_id 键默认返回,需要主动指定 _id: 才会隐藏
两种模式不可混用(因为这样的话无法推断其他键是否应返回)
比如:db.collection.find(query, {title: , by: }) // 错误
只能全1或全0,除了在inclusion模式时可以指定_id为0
db.collection.find(query, {_id:, title: , by: }) // 正确
若不想指定查询条件参数 query 可以 用 {} 代替,但是需要指定 projection 参数:
db.collection.find({}, {title: })
如果需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
db.col.find().pretty()
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
语法格式如下:
db.col1.find({key1:value1, key2:value2}).pretty()
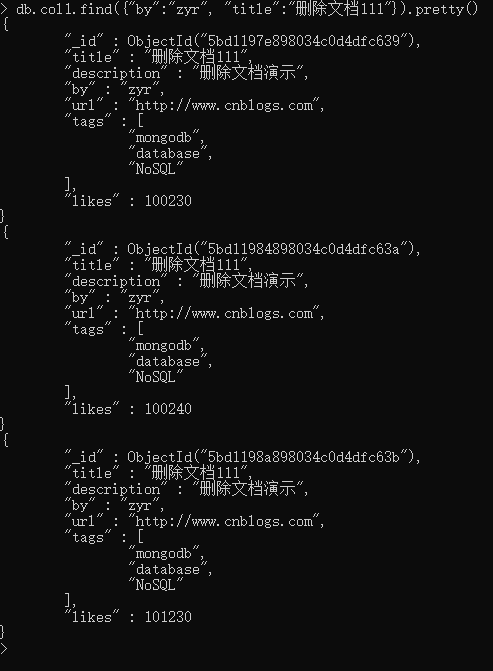
db.col1.find({"by":"zyr", "title":"删除文档111"}).pretty()
以上实例中类似于 WHERE 语句:WHERE by='zyr' AND title='删除文档111'
MongoDB OR 条件
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
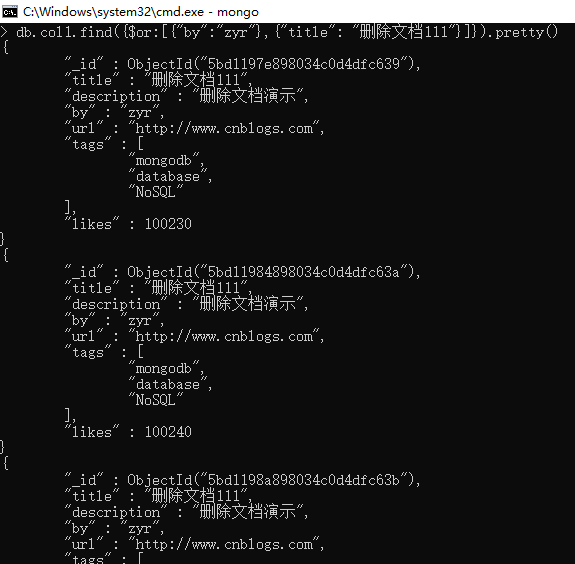
db.col1.find({$or:[{"by":"zyr"},{"title": "删除文档111"}]}).pretty()
AND 和 OR 联合使用
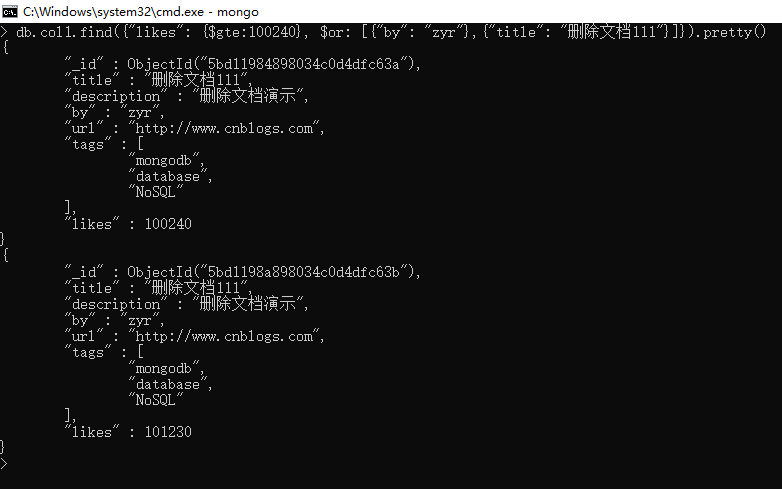
以下实例演示了 AND 和 OR 联合使用,类似常规 SQL 语句为: 'where likes>=100240 AND (by = 'zyr' OR title = '删除文档111')'
db.col1.find({"likes": {$gte:}, $or: [{"by": "zyr"},{"title": "删除文档111"}]}).pretty()
四、MongoDB核心功能
4.1、MongoDB 条件操作符
条件操作符用于比较两个表达式并从mongoDB集合中获取数据。
MongoDB中条件操作符有:
(>) 大于 - $gt
(<) 小于 - $lt
(>=) 大于等于 - $gte
(<= ) 小于等于 - $lte
$gt -------- greater than >
$gte --------- gt equal >=
$lt -------- less than <
$lte --------- lt equal <=
$ne ----------- not equal !=
$eq -------- equal =
查询 title 包含"教"字的文档:
db.col.find({title:/教/})
查询 title 字段以"教"字开头的文档:
db.col.find({title:/^教/})
查询 title字段以"教"字结尾的文档:
db.col.find({title:/教$/})
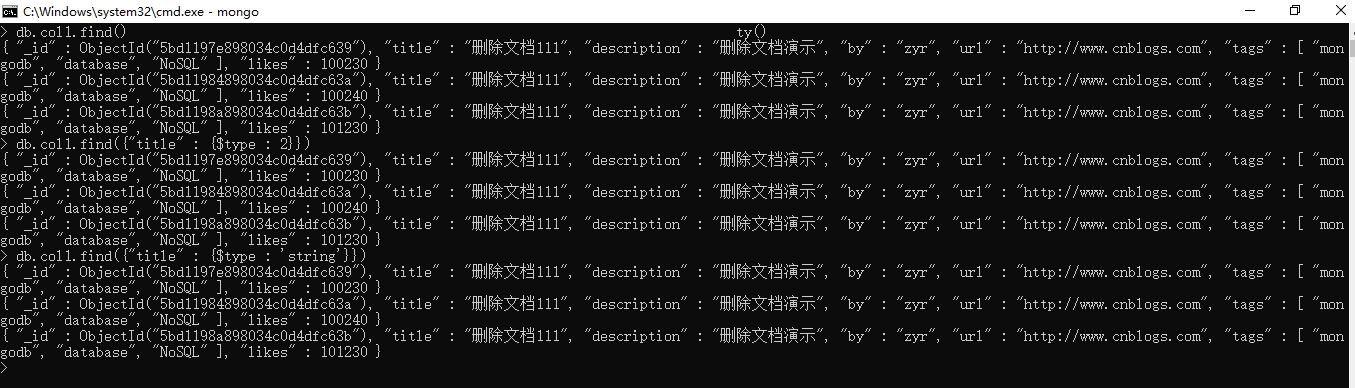
4.2、MongoDB $type 操作符
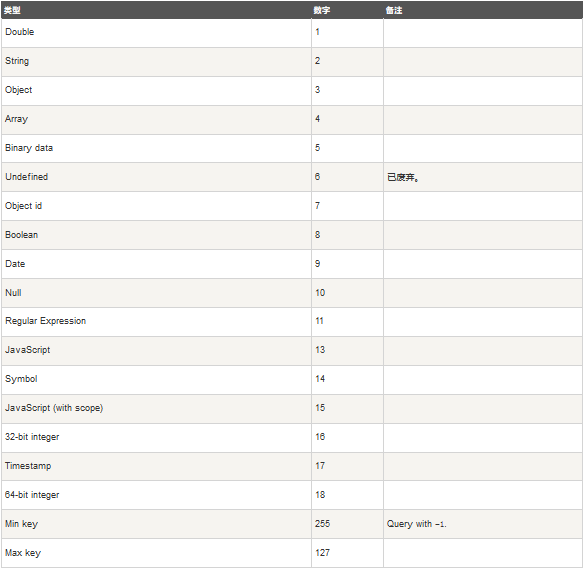
MongoDB中条件操作符 $type。$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
MongoDB 中可以使用的类型如下表所示,编号可以代替类型:
4.3、MongoDB Limit与Skip方法
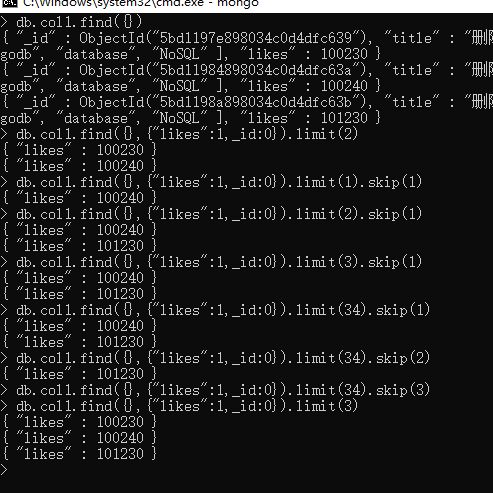
MongoDB Limit() 方法
如果需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
limit()方法基本语法如下所示:
db.COLLECTION_NAME.find().limit(NUMBER)
db.col1.find({},{"likes":,_id:}).limit()
MongoDB Skip() 方法
我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
skip() 方法脚本语法格式如下:
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
db.col1.find({},{"likes":,_id:}).limit().skip()
4.4、 MongoDB sort() 方法
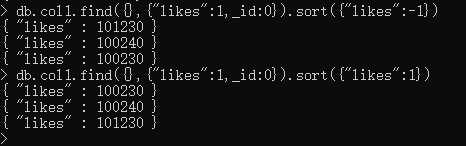
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。sort()方法基本语法如下所示:
db.COLLECTION_NAME.find().sort({KEY:})
db.col1.find({},{"likes":1,_id:0}).sort({"likes":1}
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit()。
4.5、MongoDB 索引
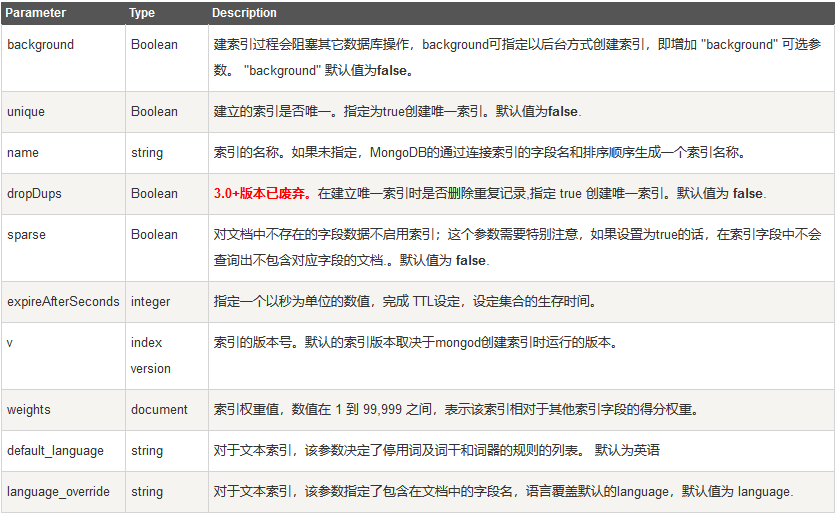
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。MongoDB使用 createIndex() 方法来创建索引。
db.collection.createIndex(keys, options)
语法中 Key 值为要创建的索引字段,1 为指定按升序创建索引,如果想按降序来创建索引指定为 -1 即可。
db.col1.createIndex({"likes":})
createIndex() 方法中也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)。
其中options可以为如下几种:
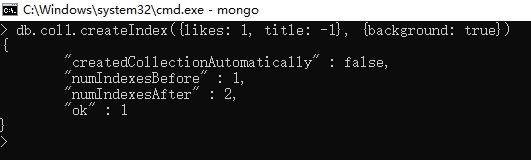
db.col1.createIndex({likes: , title: -}, {background: true})
4.6、MongoDB 聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。MongoDB中聚合的方法使用aggregate()。
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
> db.col1.aggregate([{$group : { _id : "$by", num_count : {$sum : 1}}}])
{ "_id" : "lsx", "num_count" : 1 }
{ "_id" : "zyr", "num_count" : 3 }
> db.col1.aggregate([{$group : { _id : "$by", num_count : {$sum : -1}}}])
{ "_id" : "lsx", "num_count" : -1 }
{ "_id" : "zyr", "num_count" : -3 }
> db.col1.aggregate([{$group : { _id : "$by", last_url : {$last : '$url'}}}])
{ "_id" : "lsx", "last_url" : "http://www.cnblogs.com" }
{ "_id" : "zyr", "last_url" : "http://www.cnblogs.com" }
> db.col1.aggregate([{$group : { _id : "$by", num_count : {$sum : 'likes'}}}])
{ "_id" : "lsx", "num_count" : 0 }
{ "_id" : "zyr", "num_count" : 0 }
> db.col1.aggregate([{$group : { _id : "$by", num_count : {$sum : '$likes'}}}])
{ "_id" : "lsx", "num_count" : 100240 }
{ "_id" : "zyr", "num_count" : 301700 }

管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
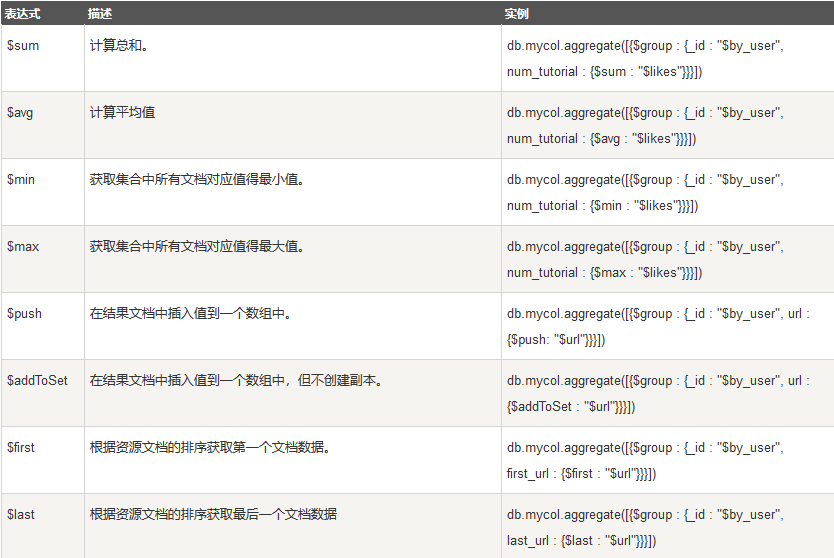
这里我们介绍一下聚合框架中常用的几个操作:
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置的有序文档。
运行案例和结果:
> db.col1.find()
{ "_id" : ObjectId("5bd1197e898034c0d4dfc639"), "title" : "删除文档111", "description" : "删除文档演示", "by" : "zyr", "url" : "http://www.cnblogs.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : }
{ "_id" : ObjectId("5bd11984898034c0d4dfc63a"), "title" : "删除文档111", "description" : "删除文档演示", "by" : "zyr", "url" : "http://www.cnblogs.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : }
{ "_id" : ObjectId("5bd1198a898034c0d4dfc63b"), "title" : "删除文档111", "description" : "删除文档演示", "by" : "zyr", "url" : "http://www.cnblogs.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : }
{ "_id" : ObjectId("5bd12651898034c0d4dfc63c"), "title" : "删除文档111", "description" : "删除文档演示", "by" : "lsx", "url" : "http://www.cnblogs.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : } > db.col1.aggregate(
... { $project : {
... title : ,
... by : ,
... }}
... );
{ "_id" : ObjectId("5bd1197e898034c0d4dfc639"), "title" : "删除文档111", "by" : "zyr" }
{ "_id" : ObjectId("5bd11984898034c0d4dfc63a"), "title" : "删除文档111", "by" : "zyr" }
{ "_id" : ObjectId("5bd1198a898034c0d4dfc63b"), "title" : "删除文档111", "by" : "zyr" }
{ "_id" : ObjectId("5bd12651898034c0d4dfc63c"), "title" : "删除文档111", "by" : "lsx" }
这样的话结果中就只还有_id,tilte和by三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
> db.col1.aggregate(
... { $project : {
... title : ,
... by : ,
... _id :
... }}
... );
{ "title" : "删除文档111", "by" : "zyr" }
{ "title" : "删除文档111", "by" : "zyr" }
{ "title" : "删除文档111", "by" : "zyr" }
{ "title" : "删除文档111", "by" : "lsx" }
$match用于获取分数大于100231,小于或等于110000记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
> db.col1.aggregate( [
... { $match : { likes : { $gt : , $lte : } } },
... { $group: { _id: null, count: { $sum: } } }
... ] );
{ "_id" : null, "count" : } 经过$skip管道操作符处理后,前2个文档被"过滤"掉。
> db.col1.aggregate(
... { $skip : }
... );
{ "_id" : ObjectId("5bd1198a898034c0d4dfc63b"), "title" : "删除文档111", "description" : "删除文档演示", "by" : "zyr", "url" : "http://www.cnblogs.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : }
{ "_id" : ObjectId("5bd12651898034c0d4dfc63c"), "title" : "删除文档111", "description" : "删除文档演示", "by" : "lsx", "url" : "http://www.cnblogs.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : }
>
4.7、MongoDB 复制(副本集)
MongoDB复制是将数据同步在多个服务器的过程。复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。复制还允许您从硬件故障和服务中断中恢复数据。
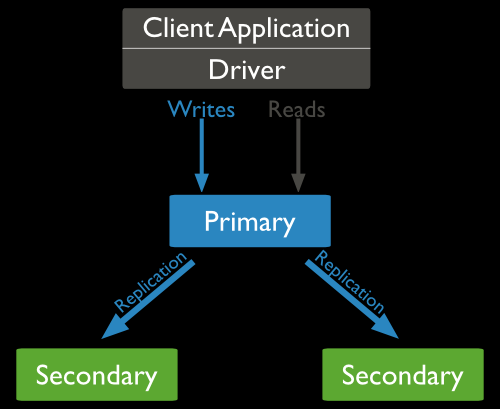
MongoDB复制原理:
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。mongodb各个节点常见的搭配方式为:一主一从、一主多从。主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
MongoDB复制结构图如下所示:
服务器日志:
D:\software_setup\mongo_db_setup\bin>mongod --port --dbpath "D:\data\db" --replSet rs0
--25T10::59.189+ I CONTROL [main] Automatically disabling TLS 1.0, to force-enable TLS 1.0 specify --sslDisabledProtocols 'none'
--25T10::00.235+ I CONTROL [initandlisten] MongoDB starting : pid= port= dbpath=D:\data\db -bit host=zyr
--25T10::00.235+ I CONTROL [initandlisten] targetMinOS: Windows /Windows Server R2
--25T10::00.236+ I CONTROL [initandlisten] db version v4.0.3
--25T10::00.236+ I CONTROL [initandlisten] git version: 7ea530946fa7880364d88c8d8b6026bbc9ffa48c
--25T10::00.236+ I CONTROL [initandlisten] allocator: tcmalloc
--25T10::00.237+ I CONTROL [initandlisten] modules: none
--25T10::00.238+ I CONTROL [initandlisten] build environment:
--25T10::00.239+ I CONTROL [initandlisten] distmod: 2008plus-ssl
--25T10::00.239+ I CONTROL [initandlisten] distarch: x86_64
--25T10::00.240+ I CONTROL [initandlisten] target_arch: x86_64
--25T10::00.241+ I CONTROL [initandlisten] options: { net: { port: }, replication: { replSet: "rs0" }, storage: { dbPath: "D:\data\db" } }
--25T10::00.243+ I STORAGE [initandlisten] Detected data files in D:\data\db created by the 'wiredTiger' storage engine, so setting the active storage engine to 'wiredTiger'.
--25T10::00.244+ I STORAGE [initandlisten] wiredtiger_open config: create,cache_size=1253M,session_max=,eviction=(threads_min=,threads_max=),config_base=false,statistics=(fast),log=(enabled=true,archive=true,path=journal,compressor=snappy),file_manager=(close_idle_time=),statistics_log=(wait=),verbose=(recovery_progress),
--25T10::00.946+ I STORAGE [initandlisten] WiredTiger message [:][:], txn-recover: Main recovery loop: starting at /
--25T10::01.485+ I STORAGE [initandlisten] WiredTiger message [:][:], txn-recover: Recovering log through
--25T10::01.905+ I STORAGE [initandlisten] WiredTiger message [:][:], txn-recover: Recovering log through
--25T10::02.176+ I STORAGE [initandlisten] WiredTiger message [:][:], txn-recover: Set global recovery timestamp:
--25T10::02.573+ I RECOVERY [initandlisten] WiredTiger recoveryTimestamp. Ts: Timestamp(, )
--25T10::02.995+ I CONTROL [initandlisten]
--25T10::02.996+ I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.
--25T10::02.999+ I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.
--25T10::03.000+ I CONTROL [initandlisten]
--25T10::03.002+ I CONTROL [initandlisten] ** WARNING: This server is bound to localhost.
--25T10::03.003+ I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server.
--25T10::03.004+ I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP
--25T10::03.005+ I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to
--25T10::03.007+ I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the
--25T10::03.012+ I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning.
--25T10::03.013+ I CONTROL [initandlisten]
--25T10::04.330+ I FTDC [initandlisten] Initializing full-time diagnostic data capture with directory 'D:/data/db/diagnostic.data'
--25T10::04.477+ I STORAGE [initandlisten] createCollection: local.replset.oplogTruncateAfterPoint with generated UUID: 7b9c553f-e795--a6da-459fe41bd643
--25T10::04.661+ I STORAGE [initandlisten] createCollection: local.replset.minvalid with generated UUID: bcc9c957-0de2-43f3-a25f-38b62903c642
--25T10::04.886+ I REPL [initandlisten] Did not find local voted for document at startup.
--25T10::04.887+ I REPL [initandlisten] Did not find local Rollback ID document at startup. Creating one.
--25T10::04.890+ I STORAGE [initandlisten] createCollection: local.system.rollback.id with generated UUID: 816e6f1c-abc9-4f29-886f-faf6ede8e7c5
--25T10::05.095+ I REPL [initandlisten] Initialized the rollback ID to
--25T10::05.095+ I REPL [initandlisten] Did not find local replica set configuration document at startup; NoMatchingDocument: Did not find replica set configuration document in local.system.replset
--25T10::05.103+ I CONTROL [LogicalSessionCacheRefresh] Sessions collection is not set up; waiting until next sessions refresh interval: Replication has not yet been configured
--25T10::05.104+ I CONTROL [LogicalSessionCacheReap] Sessions collection is not set up; waiting until next sessions reap interval: Replication has not yet been configured
--25T10::05.109+ I NETWORK [initandlisten] waiting for connections on port
--25T10::41.952+ I NETWORK [listener] connection accepted from 127.0.0.1: # ( connection now open)
--25T10::41.953+ I NETWORK [conn1] received client metadata from 127.0.0.1: conn1: { application: { name: "MongoDB Shell" }, driver: { name: "MongoDB Internal Client", version: "4.0.3" }, os: { type: "Windows", name: "Microsoft Windows 10", architecture: "x86_64", version: "10.0 (build 17134)" } }
--25T10::10.788+ I COMMAND [conn1] initiate : no configuration specified. Using a default configuration for the set
--25T10::10.788+ I COMMAND [conn1] created this configuration for initiation : { _id: "rs0", version: , members: [ { _id: , host: "localhost:27017" } ] }
--25T10::10.789+ I REPL [conn1] replSetInitiate admin command received from client
--25T10::10.913+ I REPL [conn1] replSetInitiate config object with members parses ok
--25T10::10.927+ I REPL [conn1] ******
--25T10::10.928+ I REPL [conn1] creating replication oplog of size: 1981MB...
--25T10::10.938+ I STORAGE [conn1] createCollection: local.oplog.rs with generated UUID: 8ee67362-efa8-4a0e-ba22-f5b8b5df4e43
--25T10::11.053+ I STORAGE [conn1] Starting OplogTruncaterThread local.oplog.rs
--25T10::11.054+ I STORAGE [conn1] The size storer reports that the oplog contains records totaling to bytes
--25T10::11.054+ I STORAGE [conn1] Scanning the oplog to determine where to place markers for truncation
--25T10::11.385+ I REPL [conn1] ******
--25T10::11.386+ I COMMAND [monitoring keys for HMAC] command admin.system.keys command: find { find: "system.keys", filter: { purpose: "HMAC", expiresAt: { $gt: Timestamp(, ) } }, sort: { expiresAt: }, $readPreference: { mode: "nearest", tags: [] }, $db: "admin" } planSummary: EOF keysExamined: docsExamined: cursorExhausted: numYields: nreturned: reslen: locks:{ Global: { acquireCount: { r: }, acquireWaitCount: { r: }, timeAcquiringMicros: { r: } }, Database: { acquireCount: { r: } }, Collection: { acquireCount: { r: } } } protocol:op_msg 356ms
--25T10::11.386+ I STORAGE [conn1] createCollection: local.system.replset with generated UUID: cfe342a4-288f-4fd9-98f0-35120444b54e
--25T10::11.679+ I REPL [conn1] New replica set config in use: { _id: "rs0", version: , protocolVersion: , writeConcernMajorityJournalDefault: true, members: [ { _id: , host: "localhost:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: , votes: } ], settings: { chainingAllowed: true, heartbeatIntervalMillis: , heartbeatTimeoutSecs: , electionTimeoutMillis: , catchUpTimeoutMillis: -, catchUpTakeoverDelayMillis: , getLastErrorModes: {}, getLastErrorDefaults: { w: , wtimeout: }, replicaSetId: ObjectId('5bd12dbe1a30a6c802240829') } }
--25T10::11.679+ I REPL [conn1] This node is localhost: in the config
--25T10::11.680+ I REPL [conn1] transition to STARTUP2 from STARTUP
--25T10::11.682+ I REPL [conn1] Starting replication storage threads
--25T10::11.687+ I REPL [conn1] transition to RECOVERING from STARTUP2
--25T10::11.687+ I REPL [conn1] Starting replication fetcher thread
--25T10::11.708+ I REPL [conn1] Starting replication applier thread
--25T10::11.713+ I REPL [conn1] Starting replication reporter thread
--25T10::11.713+ I REPL [rsSync-] Starting oplog application
--25T10::11.714+ I COMMAND [conn1] command local.system.replset appName: "MongoDB Shell" command: replSetInitiate { replSetInitiate: undefined, lsid: { id: UUID("33ad82a2-db94-4d90-b838-d93b1351f575") }, $clusterTime: { clusterTime: Timestamp(, ), signature: { hash: BinData(, ), keyId: } }, $db: "admin" } numYields: reslen: locks:{ Global: { acquireCount: { r: , w: , W: }, acquireWaitCount: { W: }, timeAcquiringMicros: { W: } }, Database: { acquireCount: { r: , w: , W: } }, Collection: { acquireCount: { r: , w: } }, oplog: { acquireCount: { r: , w: } } } protocol:op_msg 925ms
--25T10::11.716+ I REPL [rsSync-] transition to SECONDARY from RECOVERING
--25T10::11.750+ I REPL [rsSync-] conducting a dry run election to see if we could be elected. current term:
--25T10::11.750+ I REPL [replexec-] dry election run succeeded, running for election in term
--25T10::11.752+ I STORAGE [replexec-] createCollection: local.replset.election with generated UUID: eb9903b6-983c-4f29-a324-4f0add59fdfe
--25T10::12.006+ I REPL [replexec-] election succeeded, assuming primary role in term
--25T10::12.006+ I REPL [replexec-] transition to PRIMARY from SECONDARY
--25T10::12.007+ I REPL [replexec-] Resetting sync source to empty, which was :
--25T10::12.007+ I REPL [replexec-] Entering primary catch-up mode.
--25T10::12.008+ I REPL [replexec-] Exited primary catch-up mode.
--25T10::12.008+ I REPL [replexec-] Stopping replication producer
--25T10::13.860+ I STORAGE [rsSync-] createCollection: config.transactions with generated UUID: 36eb2df2-0cba---1f924aa3c3f3
--25T10::14.070+ I COMMAND [rsSync-] command config.transactions command: create { create: "transactions", $db: "config" } numYields: reslen: locks:{ Global: { acquireCount: { r: , w: , W: } }, Database: { acquireCount: { r: , w: , W: } }, Collection: { acquireCount: { r: , w: } }, oplog: { acquireCount: { r: , w: } } } protocol:op_msg 240ms
--25T10::14.071+ I STORAGE [rsSync-] Triggering the first stable checkpoint. Initial Data: Timestamp(, ) PrevStable: Timestamp(, ) CurrStable: Timestamp(, )
--25T10::14.081+ I REPL [rsSync-] transition to primary complete; database writes are now permitted
--25T10::14.082+ I COMMAND [monitoring keys for HMAC] command admin.system.keys command: find { find: "system.keys", filter: { purpose: "HMAC", expiresAt: { $gt: Timestamp(, ) } }, sort: { expiresAt: }, $readPreference: { mode: "nearest", tags: [] }, $db: "admin" } planSummary: EOF keysExamined: docsExamined: cursorExhausted: numYields: nreturned: reslen: locks:{ Global: { acquireCount: { r: }, acquireWaitCount: { r: }, timeAcquiringMicros: { r: } }, Database: { acquireCount: { r: } }, Collection: { acquireCount: { r: } } } protocol:op_msg 252ms
--25T10::14.090+ I STORAGE [monitoring keys for HMAC] createCollection: admin.system.keys with generated UUID: 871ad78c-b1e3-4dec-9b8f-a87c02961b81
--25T10::14.758+ I COMMAND [monitoring keys for HMAC] command admin.system.keys command: insert { insert: "system.keys", bypassDocumentValidation: false, ordered: true, documents: [ { _id: , purpose: "HMAC", key: BinData(, 69CAC597733B683EE192BC98879CE2B459936E94), expiresAt: Timestamp(, ) } ], writeConcern: { w: "majority", wtimeout: }, allowImplicitCollectionCreation: true, $db: "admin" } ninserted: keysInserted: numYields: reslen: locks:{ Global: { acquireCount: { r: , w: }, acquireWaitCount: { r: }, timeAcquiringMicros: { r: } }, Database: { acquireCount: { r: , w: , W: } }, Collection: { acquireCount: { r: , w: } }, oplog: { acquireCount: { w: } } } protocol:op_msg 668ms
--25T10::23.710+ I COMMAND [conn1] initiate : no configuration specified. Using a default configuration for the set
--25T10::23.711+ I COMMAND [conn1] created this configuration for initiation : { _id: "rs0", version: , members: [ { _id: , host: "localhost:27017" } ] }
--25T10::23.712+ I REPL [conn1] replSetInitiate admin command received from client
--25T10::23.334+ I REPL [conn1] replSetReconfig admin command received from client; new config: { _id: "rs0", version: , protocolVersion: , writeConcernMajorityJournalDefault: true, members: [ { _id: , host: "localhost:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: , votes: }, { _id: 1.0, host: "localhost:27017" } ], settings: { chainingAllowed: true, heartbeatIntervalMillis: , heartbeatTimeoutSecs: , electionTimeoutMillis: , catchUpTimeoutMillis: -, catchUpTakeoverDelayMillis: , getLastErrorModes: {}, getLastErrorDefaults: { w: , wtimeout: }, replicaSetId: ObjectId('5bd12dbe1a30a6c802240829') } }
--25T10::23.335+ E REPL [conn1] replSetReconfig got BadValue: Found two member configurations with same host field, members..host == members..host == localhost: while validating { _id: "rs0", version: , protocolVersion: , writeConcernMajorityJournalDefault: true, members: [ { _id: , host: "localhost:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: , votes: }, { _id: 1.0, host: "localhost:27017" } ], settings: { chainingAllowed: true, heartbeatIntervalMillis: , heartbeatTimeoutSecs: , electionTimeoutMillis: , catchUpTimeoutMillis: -, catchUpTakeoverDelayMillis: , getLastErrorModes: {}, getLastErrorDefaults: { w: , wtimeout: }, replicaSetId: ObjectId('5bd12dbe1a30a6c802240829') } }
客户端日志:
C:\Users\>mongo
MongoDB shell version v4.0.3
connecting to: mongodb://127.0.0.1:27017
Implicit session: session { "id" : UUID("33ad82a2-db94-4d90-b838-d93b1351f575") } MongoDB server version: 4.0. Server has startup warnings:
--25T10::02.995+ I CONTROL [initandlisten]
--25T10::02.996+ I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.
--25T10::02.999+ I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.
--25T10::03.000+ I CONTROL [initandlisten]
--25T10::03.002+ I CONTROL [initandlisten] ** WARNING: This server is bound to localhost.
--25T10::03.003+ I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server.
--25T10::03.004+ I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP
--25T10::03.005+ I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to
--25T10::03.007+ I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the
--25T10::03.012+ I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning.
--25T10::03.013+ I CONTROL [initandlisten]
---
Enable MongoDB's free cloud-based monitoring service, which will then receive and display
metrics about your deployment (disk utilization, CPU, operation statistics, etc). The monitoring data will be available on a MongoDB website with a unique URL accessible to you
and anyone you share the URL with. MongoDB may use this information to make product
improvements and to suggest MongoDB products and deployment options to you. To enable free monitoring, run the following command: db.enableFreeMonitoring()
To permanently disable this reminder, run the following command: db.disableFreeMonitoring()
--- > rs.initiate()
{
"info2" : "no configuration specified. Using a default configuration for the set",
"me" : "localhost:27017",
"ok" : ,
"operationTime" : Timestamp(, ),
"$clusterTime" : {
"clusterTime" : Timestamp(, ),
"signature" : {
"hash" : BinData(,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong()
}
}
}
rs0:SECONDARY> rs.conf()
{
"_id" : "rs0",
"version" : ,
"protocolVersion" : NumberLong(),
"writeConcernMajorityJournalDefault" : true,
"members" : [
{
"_id" : ,
"host" : "localhost:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : ,
"tags" : { },
"slaveDelay" : NumberLong(),
"votes" :
}
],
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : ,
"heartbeatTimeoutSecs" : ,
"electionTimeoutMillis" : ,
"catchUpTimeoutMillis" : -,
"catchUpTakeoverDelayMillis" : ,
"getLastErrorModes" : { },
"getLastErrorDefaults" : {
"w" : ,
"wtimeout" :
},
"replicaSetId" : ObjectId("5bd12dbe1a30a6c802240829")
}
}
rs0:PRIMARY> rs.status()
{
"set" : "rs0",
"date" : ISODate("2018-10-25T02:44:09.376Z"),
"myState" : ,
"term" : NumberLong(),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -,
"heartbeatIntervalMillis" : NumberLong(),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"readConcernMajorityOpTime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"appliedOpTime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"durableOpTime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
}
},
"lastStableCheckpointTimestamp" : Timestamp(, ),
"members" : [
{
"_id" : ,
"name" : "localhost:27017",
"health" : ,
"state" : ,
"stateStr" : "PRIMARY",
"uptime" : ,
"optime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"optimeDate" : ISODate("2018-10-25T02:44:04Z"),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -,
"infoMessage" : "could not find member to sync from",
"electionTime" : Timestamp(, ),
"electionDate" : ISODate("2018-10-25T02:43:12Z"),
"configVersion" : ,
"self" : true,
"lastHeartbeatMessage" : ""
}
],
"ok" : ,
"operationTime" : Timestamp(, ),
"$clusterTime" : {
"clusterTime" : Timestamp(, ),
"signature" : {
"hash" : BinData(,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong()
}
}
}
rs0:PRIMARY> rs.initiate()
{
"operationTime" : Timestamp(, ),
"ok" : ,
"errmsg" : "already initialized",
"code" : ,
"codeName" : "AlreadyInitialized",
"$clusterTime" : {
"clusterTime" : Timestamp(, ),
"signature" : {
"hash" : BinData(,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong()
}
}
}
rs0:PRIMARY> db.isMaster()
{
"hosts" : [
"localhost:27017"
],
"setName" : "rs0",
"setVersion" : ,
"ismaster" : true,
"secondary" : false,
"primary" : "localhost:27017",
"me" : "localhost:27017",
"electionId" : ObjectId("7fffffff0000000000000001"),
"lastWrite" : {
"opTime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"lastWriteDate" : ISODate("2018-10-25T02:46:44Z"),
"majorityOpTime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"majorityWriteDate" : ISODate("2018-10-25T02:46:44Z")
},
"maxBsonObjectSize" : ,
"maxMessageSizeBytes" : ,
"maxWriteBatchSize" : ,
"localTime" : ISODate("2018-10-25T02:46:51.011Z"),
"logicalSessionTimeoutMinutes" : ,
"minWireVersion" : ,
"maxWireVersion" : ,
"readOnly" : false,
"ok" : ,
"operationTime" : Timestamp(, ),
"$clusterTime" : {
"clusterTime" : Timestamp(, ),
"signature" : {
"hash" : BinData(,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong()
}
}
}
rs0:PRIMARY> rs.add("localhost:27017")
{
"operationTime" : Timestamp(, ),
"ok" : ,
"errmsg" : "Found two member configurations with same host field, members.0.host == members.1.host == localhost:27017",
"code" : ,
"codeName" : "NewReplicaSetConfigurationIncompatible",
"$clusterTime" : {
"clusterTime" : Timestamp(, ),
"signature" : {
"hash" : BinData(,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong()
}
}
}
rs0:PRIMARY>
我们使用同一个MongoDB来做MongoDB主从的实验, 操作步骤如下:
、关闭正在运行的MongoDB服务器。
现在我们通过指定 --replSet 选项来启动mongoDB。--replSet 基本语法格式如下:
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
mongod --port --dbpath "D:\data\db" --replSet rs0
以上实例会启动一个名为rs0的MongoDB实例,其端口号为27017。启动后打开命令提示框并连接上mongoDB服务。在Mongo客户端使用命令rs.initiate()来启动一个新的副本集。我们可以使用rs.conf()来查看副本集的配置,查看副本集状态使用 rs.status() 命令。
、副本集添加成员
我们需要使用多台服务器来启动mongo服务。进入Mongo客户端,并使用rs.add()方法来添加副本集的成员。
rs.add(HOST_NAME:PORT)
假设你已经启动了一个名为zyr.net,端口号为27017的Mongo服务。 在客户端命令窗口使用rs.add() 命令将其添加到副本集中,命令如下所示:
rs.add("zyr.net:27017")
MongoDB中只能通过主节点将Mongo服务添加到副本集中, 判断当前运行的Mongo服务是否为主节点可以使用命令db.isMaster() 。MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况。
五、总结
在此,我们只是简单地理解了一下MongoDB的原理,概念和使用方式,其实在实际的工程项目之中,我们面临的问题将会是更加复杂和困难的,因此,我们要保持谦虚的心态,多积累,多总结,多掌握。
参考文献:http://www.runoob.com/mongodb/mongodb-tutorial.html
沉淀再出发:mongodb的使用的更多相关文章
- 沉淀再出发:用python画各种图表
沉淀再出发:用python画各种图表 一.前言 最近需要用python来做一些统计和画图,因此做一些笔记. 二.python画各种图表 2.1.使用turtle来画图 import turtle as ...
- 沉淀再出发:在python3中导入自定义的包
沉淀再出发:在python3中导入自定义的包 一.前言 在python中如果要使用自己的定义的包,还是有一些需要注意的事项的,这里简单记录一下. 二.在python3中导入自定义的包 2.1.什么是模 ...
- 沉淀再出发:java中的equals()辨析
沉淀再出发:java中的equals()辨析 一.前言 关于java中的equals,我们可能非常奇怪,在Object中定义了这个函数,其他的很多类中都重载了它,导致了我们对于辨析其中的内涵有了混淆, ...
- 沉淀再出发:web服务器和应用服务器之间的区别和联系
沉淀再出发:web服务器和应用服务器之间的区别和联系 一.前言 关于后端,我们一般有三种服务器(当然还有文件服务器等),Web服务器,应用程序服务器和数据库服务器,其中前面两个的概念已经非常模糊了,但 ...
- 沉淀再出发:jetty的架构和本质
沉淀再出发:jetty的架构和本质 一.前言 我们在使用Tomcat的时候,总是会想到jetty,这两者的合理选用是和我们项目的类型和大小息息相关的,Tomcat属于比较重量级的容器,通过很多的容器层 ...
- 沉淀再出发:dubbo的基本原理和应用实例
沉淀再出发:dubbo的基本原理和应用实例 一.前言 阿里开发的dubbo作为服务治理的工具,在分布式开发中有着重要的意义,这里我们主要专注于dubbo的架构,基本原理以及在Windows下面开发出来 ...
- 沉淀再出发:OpenStack初探
沉淀再出发:OpenStack初探 一.前言 OpenStack是IaaS的一种平台,通过各种虚拟化来提供服务.我们主要看一下OpenStack的基本概念和相应的使用方式. 二.OpenStack的框 ...
- 沉淀再出发:Spring的架构理解
沉淀再出发:Spring的架构理解 一.前言 在Spring之前使用的EJB框架太庞大和重量级了,开发成本很高,由此spring应运而生.关于Spring,学过java的人基本上都会慢慢接触到,并且在 ...
- 沉淀再出发:关于IntelliJ IDEA使用的一些总结
沉淀再出发:关于IntelliJ IDEA使用的一些总结 一.前言 在使用IDEA的时候我们会发现,如果我们先写了一个类的名字,而没有导入这个类的出处,就会提示出错,但是不能自动加入,非常的苦恼,并且 ...
随机推荐
- HTML5 表单 中
input 属性 autofocus 页面加载时自动获得焦点 required 非空字段输入框 placeholder 提供一种提示(hint),输入域为空时显示. pattern 规定验证inp ...
- InnoDB存储引擎的表空间文件,重做日志文件
存储引擎文件:因为MySQL表存储引擎的关系,每个存储引擎都会有自己的文件来保存各种数据.这些存储引擎真正存储了数据和索引等数据. 表空间文件 InnoDB存储引擎在存储设计上模仿了Oracle,将存 ...
- Java 中 String 的构造方法
String 对于所有 Java 程序员来说都不会陌生,几乎每天甚至每个程序都会和 String 打交道,因此将 String 的常用知识汇集在此,方便查阅. 概叙: Java 中是如此定义 Stri ...
- hive-0.5.0安装出错
在安装过程中,第一次启动Hive没有成功,后来在网上查到原因如下,并成功解决: 错误如下: Exception in thread "main" java.lang.NoClass ...
- CentOS 7_64位系统下搭建Hadoop_2.8.0分布式环境
准备条件: CentOS 7 64位操作系统 | 选择minimal版本即可(不带可视化桌面环境),也可以选择带完整版Hadoop-2.8.0 | 本文采用的是Hadoop-2.8.0版本.JDK1. ...
- HTTPS 使用成本
HTTPS 目前唯一的问题就是它还没有得到大规模应用,受到的关注和研究都比较少.至于使用成本和额外开销,完全不用太过担心. 一般来讲,使用 HTTPS 前大家可能会非常关注如下问题: 证书费用以及更新 ...
- 相片Exif协议
今天看他们安卓在做项目遇到一个要让旋转拍摄的相片竖屏方向显示 ,网上搜了下找到了安卓的一个博客,看了下想着既然安卓有ios也应该会有,果然不出所料,确实是有.其实他们都是遵循Exif协议,百度百科也有 ...
- 【angular5项目积累总结】自定义管道 OrderBy
import { Injectable, Pipe } from '@angular/core'; @Pipe({ name: 'orderBy' }) @Injectable() export cl ...
- iOS开源项目周报0302
由OpenDigg 出品的iOS开源项目周报第十期来啦.我们的iOS开源周报集合了OpenDigg一周来新收录的优质的iOS开源项目,方便iOS开发人员便捷的找到自己需要的项目工具等.TodayMin ...
- angular环境搭建时的坑
安装angular环境踩过一些坑,最终还是把工程跑起来了,这里描述一下我的步骤,不排除有些步骤是多余的,希望能对遇到同样问题的小伙伴有帮助. 下载最新版node.js. 安装node,安装过程一路点下 ...