Flink简介及使用
一、Flink概述
官网:https://flink.apache.org/ mapreduce-->maxcompute
HBase-->部门
quickBI
DataV
Hive-->高德地图
Storm-->Jstorm
...... 2019年1月,阿里正式开源flink-->blink Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
Flink设 计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。 大数据计算框架 二、Flink特点
1)mapreduce
2)storm
3)spark 适用于所有企业,不同企业有不同的业务场景。处理数据量,模型都不一样。 1)随机部署应用
以其他组件集成!
flink是分布式系统,需要计算资源才可执行程序。flink可以与常见的集群资源管理器进行集成(Hadoop Yarn,Apache Mesos...)。
可以单独作为独立集群运行。
通过不同部署模式实现。
这些模式允许flink以其惯有的方式进行交互。
当我们部署flink应用程序时,Flink会根据应用程序配置的并行性自动识别所需资源。从资源管理器中请求它们。
如果发生故障,flink会请求新的资源来替换发生故障的容器。
提交或控制程序都通过REST调用进行,简化Flink在许多环境的集成。孵化... 2)以任何比例应用程序(小集群、无限集群)
Flink旨在以任何规模运行有状态流应用程序。应用程序可以并行化在集群中分布和同时执行程序。
因此,我们的应用集群可以利用无限的cpu和磁盘与网络IO。
Flink可以轻松的维护非常大的应用程序状态。
用户可拓展性报告:
1)应用程序每天可以处理万亿个事件
2)应用程序每天可以维护多个TB的状态
3)应用程序可以在数千个内核运行 3)利用内存中的性能
有状态Flink应用程序针对于对本地状态访问进行了优化。任务状态始终的保留在内存中,或者如果
大小超过了可用内存,则保存在访问高效的磁盘数据结构中(SSD 机械/固态)。
任务可以通过访问本地来执行所有计算。从来产生极小的延迟。
Flink定期和异步检查本地状态持久存储来保持出现故障时一次状态的一致性。 三、有界无界
1)无界
有开始,没有结束...
处理实时数据。
2)有界
有开始,有结束...
处理批量数据。 四、无界数据集应用场景(实时计算)
1)源源不断的日志数据
2)web应用,指标分析
3)移动设备终端(分析app状况)
4)应用在任何数据源不断产生的项目中 五、Flink运行模型
1)流计算
数据源源不断产生,我们的需求是源源不断的处理。程序需要一直保持在计算的状态。
2)批处理
计算一段完整的数据集,计算成功后释放资源,那么此时工作结束。 六、Flink的使用
1)处理结果准确:无论是有序数据还是延迟到达的数据。
2)容错机制:
有状态:保持每次的结果往下传递,实现累加。DAG(有向无环图)。
3)有很强大的吞吐量和低延迟。
计算速度快,吞吐量处理的量级大。
4)精准的维护一次的应用状态。
storm:会发生要么多计算一次,要么漏计算。
5)支持大规模的计算
可以运行在数千台节点上。
6)支持流处理和窗口化操作
7)版本化处理
8)检查点机制实现精准的一次性计算保证
checkpoint
9)支持yarn与mesos资源管理器 七、flink单节点安装部署
1)下载安装包
https://archive.apache.org/dist/flink/flink-1.6.2/flink-1.6.2-bin-hadoop28-scala_2.11.tgz
2)上传安装包到/root下 3)解压
cd /root
tar -zxvf flink-1.6.2-bin-hadoop28-scala_2.11.tgz -C hd 4)启动
cd /root/hd/flink-1.6.2
bin/start-cluster.sh 5)启动
cd /root/hd/flink-1.6.2
bin/stop-cluster.sh 6)访问ui界面
http://192.168.146.132:8081 八、flink集群安装部署
1)下载安装包
https://archive.apache.org/dist/flink/flink-1.6.2/flink-1.6.2-bin-hadoop28-scala_2.11.tgz
2)上传安装包到/root下 3)解压
cd /root
tar -zxvf flink-1.6.2-bin-hadoop28-scala_2.11.tgz -C hd 4)修改配置文件
vi flink-conf.yaml
第33行修改为:
jobmanager.rpc.address: hd09-1 5)修改slaves
vi slaves
hd09-2
hd09-3 6)分发flink到其他机器
cd /root/hd
scp -r flink-1.6.2/ hd09-2:$PWD
scp -r flink-1.6.2/ hd09-3:$PWD 7)启动集群
cd /root/hd/flink-1.6.2
bin/start-cluster.sh 8)关闭集群
cd /root/hd/flink-1.6.2
bin/stop-cluster.sh 9)访问ui界面
http://192.168.146.132:8081
九、flink结构
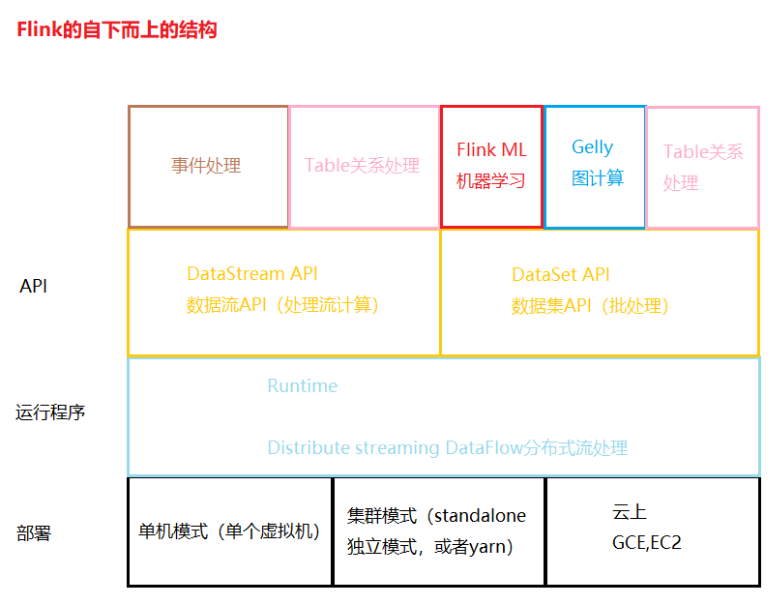
十、WordCount简单实现
需求:实时的wordcount
往端口中发送数据,实时的计算数据
1、SocketWordCount类
package com.demo.flink; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector; /**
* 需求:实时的wordcount
* 往端口中发送数据,实时的计算数据
*/
public class SocketWordCount {
public static void main(String[] args) throws Exception {
//1.定义连接端口
final int port = 9999;
//2.创建执行环境对象
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//3.得到套接字对象(指定:主机、端口、分隔符)
DataStreamSource<String> text = env.socketTextStream("192.168.146.132", port, "\n"); //4.解析数据,统计数据-单词计数 hello lz hello world
DataStream<WordWithCount> windowCounts = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
public void flatMap(String s, Collector<WordWithCount> collector){
//按照空白符进行切割
for (String word : s.split("\\s")) {
//<单词,1>
collector.collect(new WordWithCount(word, 1L));
}
}
})
//按照key进行分组
.keyBy("word")
//设置窗口的时间长度 5秒一次窗口 1秒计算一次
.timeWindow(Time.seconds(5), Time.seconds(1))
//聚合,聚合函数
.reduce(new ReduceFunction<WordWithCount>() {
public WordWithCount reduce(WordWithCount a, WordWithCount b) throws Exception {
//按照key聚合
return new WordWithCount(a.word, a.count + b.count);
}
}); //5.打印可以设置并发度
windowCounts.print().setParallelism(1); //6.执行程序
env.execute("Socket window WordCount");
} public static class WordWithCount {
public String word;
public long count; public WordWithCount() { } public WordWithCount(String word, long count){
this.word = word;
this.count = count;
} public String toString(){
return word + " : " + count;
}
}
}
2、flink的maven依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.2</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.2</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.6.2</version>
</dependency>
3、运行SocketWordCount类的main方法
4、服务器安装netcat
// 安装netcat
yum install -y nc
// 使用nc,其中9999是SocketWordCount类中定义的端口号
nc -lk -p 9999
5、此时在服务器的nc下输入单词后,SocketWordCount的main方法会时时监控到该单词并进行计算处理。
6、也可以把SocketWordCount程序打成jar包放置到服务器上,执行
[root@hd09-1 flink-1.6.2]# bin/flink run -c com.demo.flink.SocketWordCount /root/FlinkTest-1.0-SNAPSHOT.jar
启动WordCount计算程序,此时结果会写到/root/hd/flink-1.6.2/log下的flink-root-taskexecutor-0-hd09-1.out文件中。
Flink简介及使用的更多相关文章
- (转)Flink简介
1. Flink的引入 这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop.Storm,以及后来的 Spark,他们都有着各自专注的应用场景.Spark 掀开了内存计算的先河 ...
- Flink简介
Flink简介 Flink的核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布,数据通信以及容错机制等功能.基于流执行引擎,Flink提供了诸多更高抽象层的API以方便用户编写分布 ...
- flink01--------1.flink简介 2.flink安装 3. flink提交任务的2种方式 4. 4flink的快速入门 5.source 6 常用算子(keyBy,max/min,maxBy/minBy,connect,union,split+select)
1. flink简介 1.1 什么是flink Apache Flink是一个分布式大数据处理引擎,可以对有限数据流(如离线数据)和无限流数据及逆行有状态计算(不太懂).可以部署在各种集群环境,对各种 ...
- Apache 流框架Flink简介
1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是原生的流处理系统,提供high level的API.Flink也提供 API来像Spark ...
- Flink学习之路(一)Flink简介
一.什么是Flink? Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能. 二.Flink特点 1.现有的开源计算方案,会把流处 ...
- Flink(一)Flink的入门简介
一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop.Storm,以及后来的 Spark,他们都有着各自专注的应用场景.Spark 掀开了内存计算的先河 ...
- [转帖]Flink(一)Flink的入门简介
Flink(一)Flink的入门简介 https://www.cnblogs.com/frankdeng/p/9400622.html 一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的 ...
- Flink流处理(一)- 状态流处理简介
1. Flink 简介 Flink 是一个分布式流处理器,提供直观且易于使用的API,以供实现有状态的流处理应用.它能够以fault-tolerant的方式高效地运行在大规模系统中. 流处理技术在当今 ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
随机推荐
- Shell 获取Shell所在目录
SHELL_PATH=$(cd ")";pwd) echo $SHELL_PATH
- 几个shell程序设计小知识(shell常识部分)
[转自]http://blog.chinaunix.net/uid-168249-id-2860686.html 引用:一.用户登陆进入系统后的系统环境变量: $HOME 使用者自己的目录 $PA ...
- 关于代理ip
反爬很重要的手段之一就是根据ip来了,包括新浪微博搜索页 微信搜索页 360全系网站360搜索 360百科 360 问答 360新闻,这些都是明确的提示了是根据ip反扒的,所以需要买ip.买得是快代理 ...
- ios 在https情况下,使用webview加载url出错的解决方法 ios9 适配问题
修改info.plist文件,添加App Transport Security Settings,然后在这个里面添加Allow Arbitrary Loads,改为yes 如下图:
- eclipse、tomca和jvm的相关内存配置
1, 设置Eclipse内存使用情况 修改eclipse根目录下的eclipse.ini文件 -vmargs //虚拟机设置 -Xms40m ...
- docker学习-docker仓库
docker仓库中心:https://hub.docker.com/ 网易蜂巢仓库中心:https://c.163.com/hub#/m/home/
- Android英文文档翻译系列(1)——AlarmManager
原文:个人翻译,水平有限,欢迎看官指正. public class Ala ...
- 谷歌Volley网络框架讲解——第一篇
自从公司新招了几个android工程师后,我清闲了些许.于是就可以有时间写写博客,研究一些没来的研究的东西. 今年的谷歌IO大会上,谷歌推出了自己的网络框架——Volley.不久前就听说了但是没有cl ...
- JavaBean与Map<String,Object>相互转换
一.为什么要实现javaBean与Map<String,Object>相互转换 Spring中的BaseCommandController对象可以将传递过来的参数封装到一个JavaBean ...
- css选择器的性能
性能排序: 1.id选择器(#myid) 2.类选择器(.myclassname) 3.标签选择器(div,h1,p) 4.相邻选择器(h1+p) 5.子选择器(ul < li) 6.后代选择器 ...