关于sparkStreaming(spark on yarn)的一个坑!
前些天我维护的一个streaming实时报表挂了,情况:数据无法实时更新增长,然后查看了报表所依赖的五张sqlserver的表,发现,只有1张的数据是正常写入的,还一张数据非正常写入,还有3张完全没有数据写入.刚开始认为是不是数据库链接出问题了,但是!!!!我们的一个spark on yarn的批处理恢复实时数据的任务可以正常运作!而且5张表都可以正常写入,修改,删除,于是我查看了streaming任务的节点的nodemanager的日志

正常啊!内存和磁盘空间使用都正常!看来不是OOM问题
但是我还是有点不确信,因为一个长期运行的程序好端端怎么就出问题了???也没修改过代码啊,于是我还是不信邪的去修改了excutor的内存(增大),也去尝试修改了driver的内存(增大)
这下好了!!!连streming任务都运行不了了!!!spark on yarn的批处理恢复也恢复不了了!!!!我的天!!开启后几秒就挂掉!!!(想跳楼!)
于是通过 yarn logs -applocationId 查看了streming任务的报错信息如下
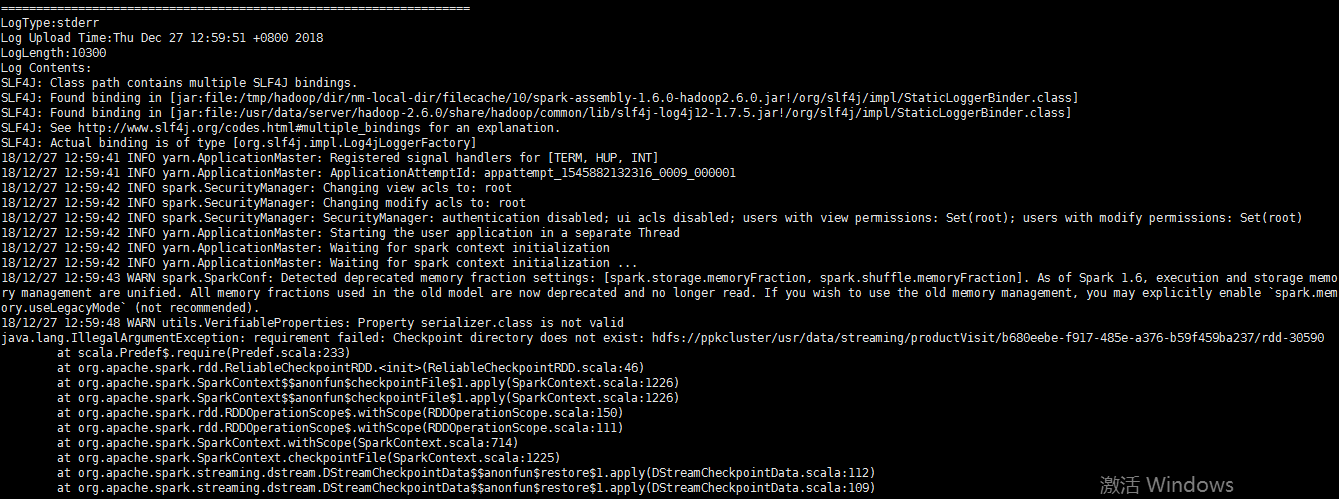
找不到checkpoint目录??
于是我手动创建了这个checkpoint的hdfs目录(若干次)
于是乎!!!可以正常运行不会挂掉了!!!但是!!过了20-30分钟还是会挂掉!!并且出现同样的错误!!,每次都要重新恢复目录才能正常运行!!!!
而且查看了此时的/usr/data/logs/userlogs/下的steaming的任务日志,发现了2个问题!!!!

先是大量的获取0个非空块(其实正常情况也会出现,但不是大量的) 然后跳出下一个错误如下
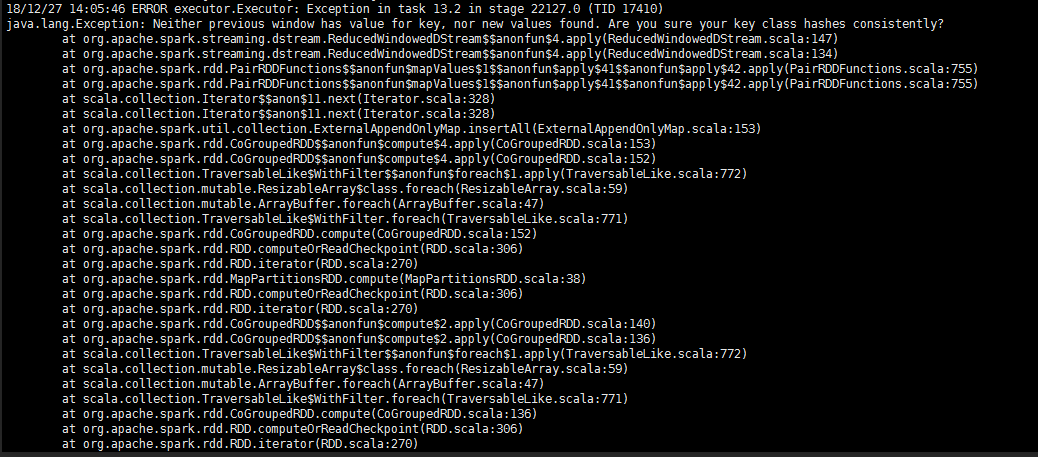
我的天!!!这啥错误!
百度了下,这个错误信息文字好像是自定义的,也没百度到相关错误.一般感觉得话像是代码错误,但是这代码都快半年没更改了!!怎么可能!!!
最后!!!关键来了!修复了!怎么修复的呢如下

我将streaming路径下所有带checkpoint字眼的文件全删除了!然后重启streaming任务!恢复!!!!!!!!!!!!!!!!!!!!
然后我查看了网上相关文档资料

应该就是这个问题了,完全符合我们现有的工作环境! 相关资料链接 : https://blog.csdn.net/rlnLo2pNEfx9c/article/details/81417061
不过我还是不明白那些个错误代表了什么,和删除checkpoint文件到底发生了什么,如有大佬知道,请做出点评与回复
----互帮互助才有提升!
关于sparkStreaming(spark on yarn)的一个坑!的更多相关文章
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- Spark on Yarn年度知识整理
大数据体系结构: Spark简介 Spark是整个BDAS的核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map 函数和reduce函数及计算模型,还提供更为丰富的算子,如f ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- Spark通过YARN提交任务不成功(包含YARN cluster和YARN client)
无论用YARN cluster和YARN client来跑,均会出现如下问题. [spark@master spark-1.6.1-bin-hadoop2.6]$ jps 2049 NameNode ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)(转)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- 配置Spark on YARN集群内存
参考原文:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool 运行文件有几个G大,默 ...
- Spark on Yarn 学习(一)
最近看到明风的关于数据挖掘平台下实用Spark和Yarn来做推荐的PPT,感觉很赞,现在基于大数据和快速计算方面技术的发展很快,随着Apache基金会上发布的一个个项目,感觉真的新技术将会不断出现在大 ...
- Spark on Yarn:任务提交参数配置
当在YARN上运行Spark作业,每个Spark executor作为一个YARN容器运行.Spark可以使得多个Tasks在同一个容器里面运行. 以下参数配置为例子: spark-submit -- ...
- 运行 Spark on YARN
运行 Spark on YARN Spark 0.6.0 以上的版本添加了在yarn上执行spark application的功能支持,并在之后的版本中持续的 改进.关于本文的内容是翻译官网的内容,大 ...
随机推荐
- Linux运维体系
- Windows Azure系列公开课 - 第一课:认识云计算
我们正在经历着一个前所未有的变革时代.信息技术的不断创新也推动着各行业的业务创新. 任何规模和类型的组织都需要拥抱最新的IT趋势才能保持竞争力与创新力,并关注自身的业务. 云计算的最终目标是将计算.服 ...
- .net core系列之《对AOP思想的理解及使用AspectCore实现自定义日志拦截》
对于AOP这个名词,相信对于搞过MVC开发的人来说,都很熟悉,里面各种各样的Filter简直是将AOP体现到了极致. 那么什么是AOP呢? AOP(Aspect Oriented Programmin ...
- C# winfrom Datagridview表头样式和选中样式
Griscolor是表格线的颜色 表头的样式修改如下图: 选中某一行的样色设置
- 将NSString变成贝塞尔曲线
将NSString变成贝塞尔曲线 https://github.com/aderussell/string-to-CGPathRef NSString中的字符串是可以通过CoreText框架将其转换成 ...
- Python学习---Django的request扩展[获取用户设备信息]
关于Django的request扩展[获取用户设备信息] settings.py INSTALLED_APPS = [ ... 'app01', # 注册app ] STATICFILES_DIRS ...
- python 函数式编程之lambda( ), map( ), reduce( ), filter( )
lambda( ), map( ), reduce( ), filter( ) 1. lambda( )主要用于“行内函数”: f = lambda x : x + 2 #定义函数f(x)=x+2 g ...
- codeforces 407C Curious Array
codeforces 407C Curious Array UPD: 我觉得这个做法比较好理解啊 参考题解:https://www.cnblogs.com/ChopsticksAN/p/4908377 ...
- Discuz的一处越权操作,强制回复无权限帖子
合购vip 等教程论坛 都用的是Discuz 看操作步骤: 随便找一处vip教程 接下来 我们审查元素 找到这段代码 然后修改 <a href="http://xxx.xxx.xx ...
- oracle-记录
同時查新多个条件的数量 select sum(DECODE(trim(t.ASSESSED_RESULT),'维持',1,0)) maintainNum, sum(DECODE(trim(t.ASSE ...