消息中间件MetaQ高性能原因分析-转自阿里中间件
简介
MetaQ是一款高性能的消息中间件,经过几年的发展,已经非常成熟稳定,历经多年双11的零点峰值压测,表现堪称完美。
MetaQ当前最新最稳定的稳本是3.x系统,MetaQ 3.x重新设计和实现,比之前的版本更优秀。虽然MetaQ借鉴了linkedin 的消息中间件kafak思想,但已经是青出于蓝而胜于蓝。
本文不对MetaQ做全面的介绍,只选择高性能这点来分析。
性能测试对比图
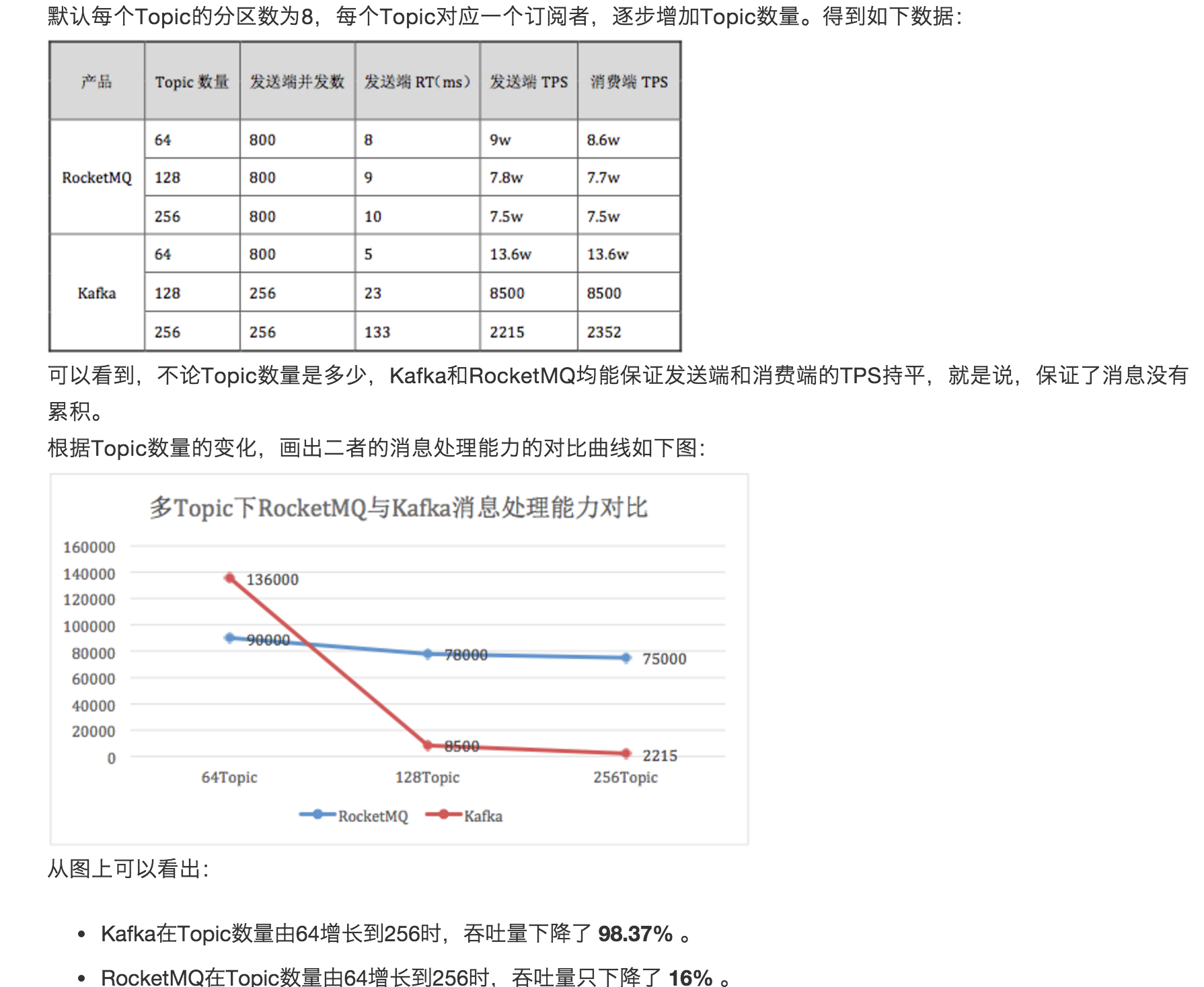
以上测试图片,来自消息测中间件试团队 @以夕 妹子的性能测试结果
核心功能
MetaQ作为一款消息中间件,消息中间件该有的功能,MetaQ也有。本文并不全面介绍MetaQ方面方面,只是选取性能这一角度,来剖析其高性能的原因。
功能组件
MetaQ Server
最为核心的组件,它主要可以接收应用程序发送过来的消息并存储,然后再投递。
MetaQ Master
是MetaQ Server逻辑上的角色,和MySQL Master概念类型,对外提供发送消息、订阅消息以及维护着管理信息。
MetaQ Slave
是MetaQ Server逻辑上的角色,和MySQL Slave概念类型,对外提供订阅消息功能。
MetaQ Client
主要是应用程序使用,使用MetaQ Client来发送消息、订阅消息、其它控制信息。
其它无数据管理及控制信息组件
提供订阅关系管理功能,MetaQ Server服务发现功能。
发送消息
MetaQ Client 发送消息,MetaQ Server收到消息,并存储到文件系统。也就是说MetaQ会有大量write系统调用。
订阅消息
MetaQ Client 订阅消息,因其是Pull的模型。MetaQ Server收到Pull消息的请求,会从磁盘上读取出消息,然后返回给MetaQ Client。这一步有大量的read系统调用。
矛盾
从上面的功能上看,Metaq Server要支持大量的磁盘IO操作,因为其是构建文件系统之上的消息中间件。既然使用了文件系统来存储数据,但磁盘QPS每秒也就是几百。MetaQ Server又必须高性能(如MetaQ Server性能是10W级别的QPS),才能在可接收的成本范围内,满足业务需求(不丢消息)。如何在QPS只有几百的磁盘上,构建出一个高性能的MetaQ消息间件正是本文的中心。
高性能
前面介绍了MetaQ高性能的难点,那么我们如何解决这些难点。要解决这些难点,就必须找出这些难点。那么要写一个高性能的消息中间件,会有哪些会部分会对影响性能。
影响性能的关键几点
序列化与反序列化
从MetaQ Cleint要发送消息,必须要先序列化,然后才能通过网络发送出去。 MetaQ Server收到消息后,要进行反序列化,才能解析出消息内容,最后序列化存储到文件系统。
MetaQ Client收到消息,首页MetaQ Server必须从文件中读取消息,然后通过网络发送给MetaQ Client,收到消息,进行反序列化,应用才能识别消息内容。
MetaQ核心功能,都要通过序列化与反序列化,所以其性能,对MetaQ性能有关键性的影响,其实不是对MetaQ,只要使用了序列化与反序列化,其对性能影响都很大。
write性能
因为MetaQ Server会有大量的write系统调用 ,所以其性能对MetaQ性能有着重要的影响。
read性能
因为MetaQ Server会有大量的read系统调用 ,所以其性能对MetaQ性能有着重要的影响。
网络框架
因为发送消息,订阅消息都必须经过网络,如果网络组件性能不好,对MetaQ性能有着关键的影响。
如何高性能
序列化与反序列化
要解决序列化与反序列化性能问题,我们就必须寻种各种序列化与反序列化技术性能对比,从而选出一个高性能的序列化与反序列化技术来作为MetaQ。
我们来看下Java世界可以选择的序列化与反序列化技术
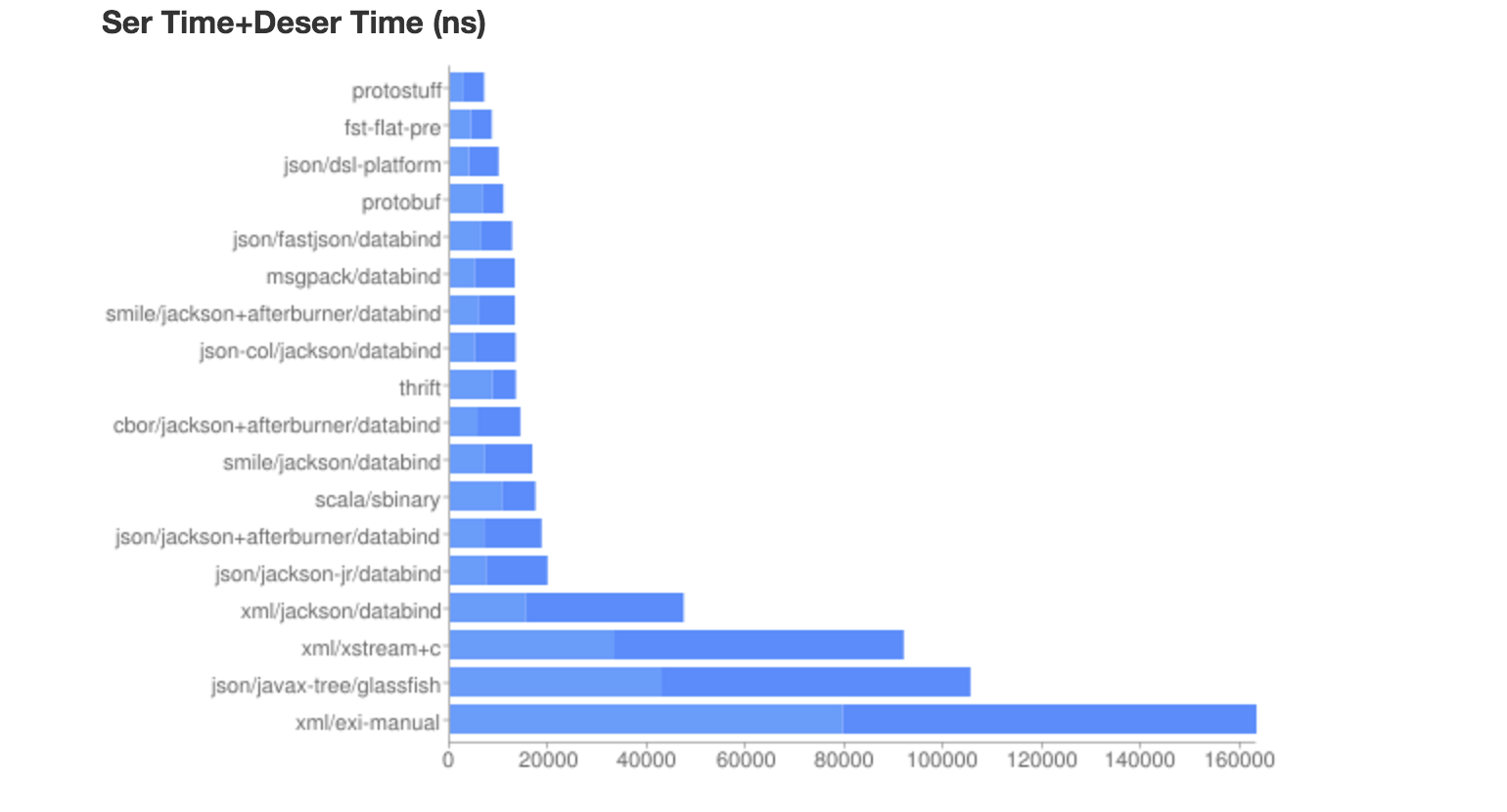
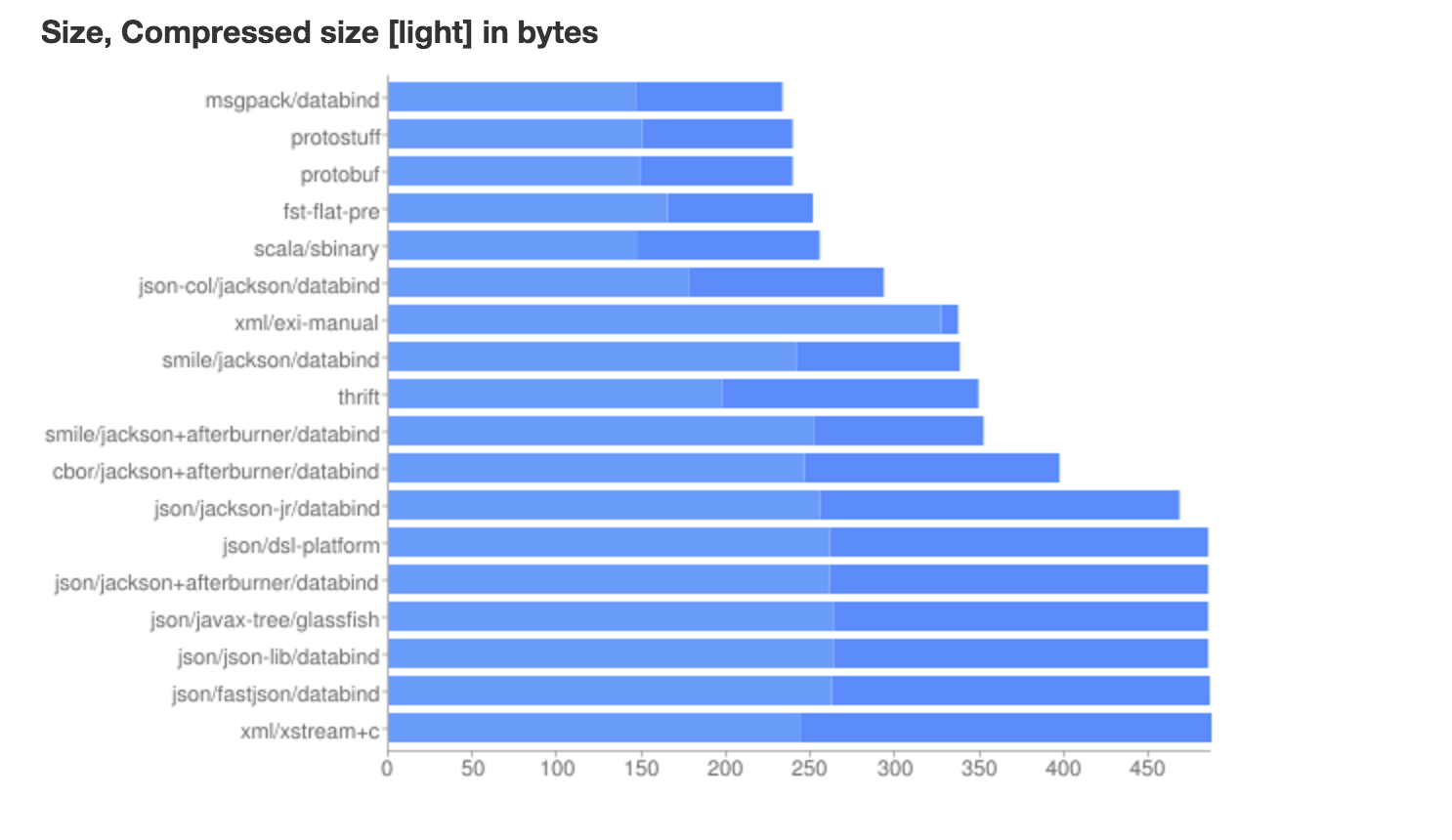
从图中性能数据,可以看出,个人认为Google出品的Protocol Buffers应该是最佳选择,不管软件的质量、社区活跃、软件的后续发展上来说,都是不错的选择。
但MetaQ并没有选择Protocol Buffers作为其序列化与反序列化的技术,一个原因是Protocol Buffers居然在小版之间本都不兼容,2.3和2.5的版本都不兼容。这会带来一个严重的问题,如果MetaQ选择2.3的版本,应用程序选择了2.5,都会导致冲突,反之亦然。
MetaQ消息元数据是通过JSON来序列化与反序列化,消息Body是交给应用自己序列化与反序列化。
虽然使用Protocol Buffers性能会更好,但带给用户带来麻烦。所以MetaQ选择使用JSON。
IO优化
前面也已经介绍了,MetaQ Server 存大大量的IO,那么怎么优化呢?
read优化
read优化主要是使用了mmap文件映射技术。这样可以减少系统上下文切换和复制数据的开销。。
同时文件系统提供了文件预读的功能,也使的读取文件开销,特别是顺序读时,开销比较低。
write优化
前面也介绍了,write可能存在并发问题,那么MetaQ是如何解决的?
MetaQ消息只保留在一个物理文件上,所有的消息都会写一个物理文件,每个物理文件都是固定大小,超过设置的阀值后,自动创建新的一个文件。当磁盘快满时,会自动删除老的文件。
Group Commit技术
Group Commit也就是组提交,组提交是指可以多次分写请求只要通过一次刷新数据,就可以实现这些请求的数据都已刷新到磁盘上。
MySQL数据库能保证ACID,事务提交也使用了Group Commit来提高性能(为了保证D,数据需要持久化到文件系统)。
详细见下图
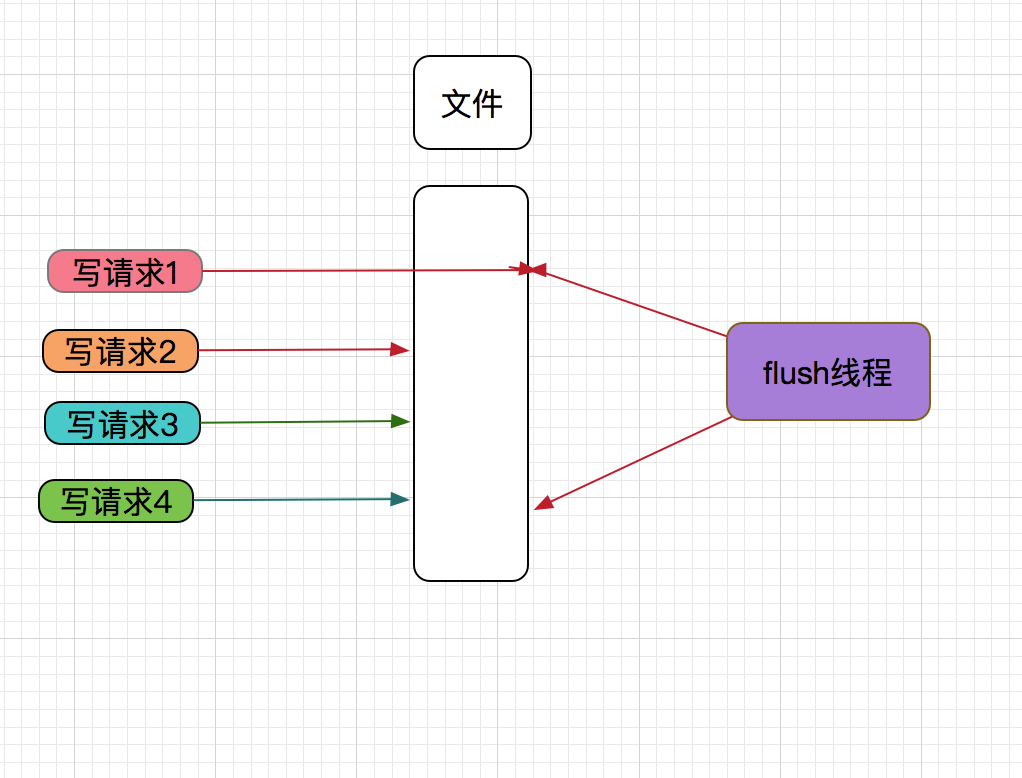
当写请求1到MetaQ Server时,把线程写入内核后,触发flush线程刷新数据到磁盘,以保证数据的可靠性。
然后再向MetaQ Client 响应发送消息成功。这个时间,只要文件系统和磁盘不损坏,数据是不会丢失的。
正在flush线程要准备刷新数据时,写请求2,写请求3,写请求4也到MetaQ Server且写入数据,这样因写请求1写数据,触发的flush顺便也把写请求2,写请求3,写请求4的数据也刷新到磁盘。这样减少了刷新磁盘的次数,性能自然就高了,同时也保证的数据的可靠性。
如何实现Group Commit,请看源码
// Synchronization flush |
并发安全
write如何保证并发安全,在写数据前,需要抢占一个锁,因为这只是把数据写到文件系统缓存中,所以持有锁的时间非常短,对性能友好。请看代码
synchronized (this) {
|
网络性能
MetaQ的网络框架,选择了Netty4。Netty4因出色的性能和易用性,成为高性能场景的不二选择。
后记
MetaQ高性能的秘密,我们从其功能结构,从功能的作用,一个个解释了可能影响性能的点,及怎么解决这些问题,提高性能。
虽然一个个点看起来简单,但要实现一个稳定、高性能的消息系统,还是不容易的。
消息中间件MetaQ高性能原因分析-转自阿里中间件的更多相关文章
- 转:Kafka、RabbitMQ、RocketMQ消息中间件的对比 —— 消息发送性能 (阿里中间件团队博客)
from: http://jm.taobao.org/2016/04/01/kafka-vs-rabbitmq-vs-rocketmq-message-send-performance/ 引言 分布式 ...
- 阿里中间件RocketMQ
阿里RocketMQ是怎样孵化成Apache顶级项目的? RocketMQ 迈入50万TPS消息俱乐部 Apache RocketMQ背后的设计思路与最佳实践 专访RocketMQ联合创始人:项目思路 ...
- 阿里中间件——消息中间件Notify和MetaQ
3.1.Notify Notify是淘宝自主研发的一套消息服务引擎,是支撑双11最为核心的系统之一,在淘宝和支付宝的核心交易场景中都有大量使用.消息系统的核心作用就是三点:解耦,异步和并行.下面让我以 ...
- [转]分布式消息中间件 MetaQ 作者庄晓丹专访
MetaQ(全称Metamorphosis)是一个高性能.高可用.可扩展的分布式消息中间件,思路起源于LinkedIn的Kafka,但并不是Kafka的一个Copy.MetaQ具有消息存储顺序写.吞吐 ...
- RocketMQ 消息发送system busy、broker busy原因分析与解决方案
目录 1.现象 2.原理解读 2.1 RocketMQ 网络处理机制概述 2.2 pair.getObject1().rejectRequest() 2.3 漫谈transientStorePoolE ...
- 阿里开源消息中间件RocketMQ的前世今生-转自阿里中间件
昨天,我们将分布式消息中间件RocketMQ捐赠给了开源软件基金会Apache. 孵化成功后,RocketMQ或将成为国内首个互联网中间件在Apache上的顶级项目. 消息一出,本以为群众的反应是这样 ...
- SQL Server 磁盘请求超时的833错误原因分析以及解决
本文出处:http://www.cnblogs.com/wy123/p/6984885.html 最近遇到一个SQL Server服务器响应极度缓慢,并且出现客户端请求报错的情况,在数据库中的erro ...
- Android ListView异步载入图片乱序问题,原因分析及解决方式
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/45586553 在Android全部系统自带的控件其中,ListView这个控件算是 ...
- MYSQL数据表损坏的原因分析和修复方法小结
MYSQL数据表损坏的原因分析和修复方法小结 1.表损坏的原因分析 以下原因是导致mysql 表毁坏的常见原因: 1. 服务器突然断电导致数据文件损坏. 2. 强制关机,没有先关闭mysql 服务. ...
随机推荐
- C语言结构体里的成员数组和指针
struct test{ int i; char *p; }; struct test *str; ; char *b = "ioiodddddddddddd"; str = (s ...
- Tomcat性能优化
1.关闭AJP协议 注释以下配置 <!-- <Connector port="8009" protocol="AJP/1.3" redirectPo ...
- 拖动对象ondrag
说明: 在进行拖放操作时,dataTransfer 对象用来保存被拖动的数据.它可以保存一项或多项数据.一种或者多种数据类型.dataTransfer对象有两个主要的方法:getData()方法和se ...
- apache和tomcat有什么不同,为什么要整合apache 和tomcat
1. Apache是web服务器,Tomcat是应用(java)服务器,它只是一个servlet容器,是Apache的扩展.2. Apache和Tomcat都可以做为独立的web服务器来运行,但是Ap ...
- jQuery中10个非常有用的遍历函数
使用jQuery,可以 很容易的选择HTML元素.但有些时候,在HTML结构较为复杂时,提炼我们选择的元素就是一件麻烦的事情.在这篇教程中,我们将探讨十种方 法去精炼和扩展我们将要操作的集合. HTM ...
- Mysql上手
使用Mysql,打开 相应的服务.启动-- 打开命令窗口.此处有多种方法,我是在开始菜单(Mysql5.6 Command Line Client)打开的(简单). mysql -h localhos ...
- http://detectmobilebrowsers.com/
<%@ Page Language="C#" %> <%@ Import Namespace="System.Text.RegularExpressio ...
- js 对数据转换成数据容量单位
function bytesToSize(value) { alert(value); alert('value'); debugger; if (value === 0) return '0 B'; ...
- 在CentOS下搭建自己的Git服务器
首先需要装好CentOS系统,作为测试,你可以选择装在虚拟机上,这样比较方便.这步默认你会,就不讲了.有了CentOS,那么如何搭建Git服务器呢?1.首先需要安装Git,可以使用yum源在线安装: ...
- Feature Access
在ArcGIS Server中发布支持Feature Access地图服务,你需要知道的几点: 所绘制的mxd地图文件中包含的数据,必须来自企业级数据库链接: mxd中包含的所有图层的数据,必须来自同 ...