Linux命令去重统计排序
利用Linux命令进行文本按行去重并按重复次数排序
linux命令行提供了非常强大的文本处理功能,组合利用linux命令能实现好多强大的功能。本文这里举例说明如何利用Linux命令行进行文本按行去重并按重复次数排序。主要用到的命令有sort,uniq。其中,sort主要功能是排序,uniq主要功能是实现相邻文本行的去重。
用于演示的测试文件内容如下:
Hello World.
Apple and Nokia.
Hello World.
I wanna buy an Apple device.
The Iphone of Apple company.
Hello World.
The Iphone of Apple company.
My name is Friendfish.
Hello World.
Apple and Nokia.
1、文本去重
(1)排序
由于uniq命令只能对相邻行进行去重复操作,所以在进行去重前,先要对文本行进行排序,使重复行集中到一起。
排序前:
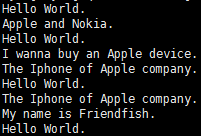
排序后:

(2)去掉相邻的重复行
如图所示:
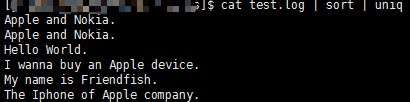
2、文本行去重并按重复次数排序
(1)首先,对文本行进行去重并统计重复次数(uniq命令加-c选项可以实现对重复次数进行统计)
如图所示:
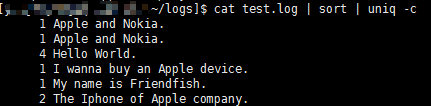
(2)按重复次数排序
sort -n可以识别每行开头的数字,并按其大小对文本行进行排序。默认是按升序排列,如果想要按降序要加-r选项(sort -rn)

-------------------------------------------------------手动分割---------------------------------------------------------
2018/09/04
做数据统计的时候遇见一个问题,对一个包含地区名的地区文件做处理的时候(cat diqu.log | sort | uniq -c),发现相邻的地区名
并没有去重,反复试了好几次也没有解决
注意:uniq 命令读取文本文件或者标准输入,并比较相邻的行。正常情况下,相邻的重复行将被删去
最后查了一下,怀疑应该是编码的问题,最后找到了解决方案:
修改系统配置
vi /etc/sysconfig/i18n #把原配置
LANG="en_US.UTF-8" #修改为 LANG="zh_CN.GB18030"
做以上修改就能解决问题
-------------------------------------------------------手动分割---------------------------------------------------------
2019/09/18
对于一些文件,我们在去重排序后会有空行存在的问题,比如:

可以看到去重之后的文件是存在空行,可以执行如下命令去除空行:
grep -v '^$' file
效果如下所示:

Linux命令去重统计排序的更多相关文章
- Linux 命令 - sort: 行排序文本文件
命令格式 sort [OPTION]... [FILE]... 命令参数 -b, --ignore-leading-blanks 忽略开头的空白字符. -d, --dictionary-order 只 ...
- Linux命令总结_sort排序命令
1.sort命令是帮我们依据不同的数据类型进行排序,其语法及常用参数格式: sort [-bcfMnrtk][源文件][-o 输出文件] 补充说明:sort可针对文本文件的内容,以行为单位 ...
- Linux 命令 - wc: 统计文件的行数、字数和字节数
命令格式 wc [OPTION]... [FILE]... 命令格式 -c, --bytes 打印字节数. -m, --chars 打印字符数. -l, --lines 打印行数. -L, --max ...
- 利用Linux命令行进行文本按行去重并按重复次数排序
最近杂事太多,正事进展缓慢.Fighting! linux命令行提供了非常强大的文本处理功能,组合利用linux命令能实现好多强大的功能.本文这里举例说明如何利用Linux命令行进行文本按行去重并按重 ...
- Linux sort 排序 去重 统计
先写一个命令: cut -d' ' -f1 ~/.bash_history|sort -d | uniq -c|sort -nr|head 这个命令可以统计你历史上输入的命令的次数的前十条 整个命令基 ...
- 转载:Linux命令经典面试题:统计文件中出现次数最多的前10个单词
1.使用linux命令或者shell实现:文件words存放英文单词,格式为每行一个英文单词(单词可以重复),统计这个文件中出现次数最多的前10个单词 主要考察对sort.uniq命令的使用,相关解释 ...
- 《sort帮你排序》-linux命令五分钟系列之二十六
本原创文章属于<Linux大棚>博客,博客地址为http://roclinux.cn.文章作者为rocrocket. 为了防止某些网站的恶性转载,特在每篇文章前加入此信息,还望读者体谅. ...
- Linux 文本去重 之 命令sort 与 uniq
sort [-fbMnrtuk] [file or stdin] 选项与参数: -f :忽略大小写的差异,例如 A 与 a 视为编码相同: -b :忽略最前面的空格符部分: -M :以月份的名字来排序 ...
- Linux命令输出头(标题)、输出结果排序技巧
原文:http://blog.csdn.net/hongweigg/article/details/65446007 ----------------------------------------- ...
随机推荐
- 74.Java异常处理机制
package testDate; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IO ...
- flask框架----flask-script组件
Flask Script扩展提供向Flask插入外部脚本的功能,包括运行一个开发用的服务器,一个定制的Python shell,设置数据库的脚本,cronjobs,及其他运行在web应用之外的命令行任 ...
- codeSourcery交叉编译环境
arm-none-Linux-gnueabi-gcc是 Codesourcery 公司(目前已经被Mentor收购)基于GCC推出的的ARM交叉编译工具.可用于交叉编译ARM系统中所有环节的代码,包括 ...
- 静态代码检查findbugs/阿里巴巴开发规范
findbugs,基本上三类严重的bug检测出来都是比较准确的,如下: 阿里巴巴开发规范 前面两类都是比较重要的: 参考: https://blog.csdn.net/qq_27093465/arti ...
- http 请求头大小写的问题
如果是默认消息头名称,消息头格式已经固定,即便输入的大小写有误,也会给你翻译成默认的写法,如果自己定义的,会自动给你翻译成小写,所以传参数的名称都用小写字母即可,否则可能取不到值,比如encrypte ...
- 基础选择器,长度与颜色,标签display,嵌套关系,盒模型,盒模型布局
css基础选择器 # *(统配选择器): 控制html, body,以及body下所有用于显示的标签 # div(标签选择器): 该标签名对应的所有该标签 # .(class选择器)(eg: .div ...
- 复制文件到U盘错误0x80071AC3,请运行chkdsk并重试
转载:https://www.xitmi.com/1157.html 在日常的工作学习中,我们经常会用到U盘拷贝文件.有时候当我们复制文件到U盘时,总会碰到各种问题,那如果我们碰到错误0x80071A ...
- Ant build.xml详解
Ant的概念 可能有些读者并不连接什么是Ant以及入可使用它,但只要使用通过Linux系统得读者,应该知道make这个命令.当编译Linux内核及一些软件的源程序时,经常要用这个命令.Make命令其实 ...
- Nikto
https://cirt.net/nikto2 Fire Up Kali & Open Nikto Let's fire up Kali and get started with nikto. ...
- SSM集成activiti6.0错误集锦(一)
项目环境 Maven构建 数据库:Orcle12c 服务器:Tomcat9 <java.version>1.8</java.version> <activiti.vers ...