【Oozie学习之一】Oozie
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
CM5.4
同类产品:Azkaban
一、简介
Oozie由Cloudera公司贡献给Apache的基于工作流引擎的开源框架,是用于Hadoop平台的开源的工作流调度引擎,是用来管理Hadoop作业,属于web应用程序,由Oozie client和Oozie Server两个组件构成,Oozie Server运行于Java Servlet容器(Tomcat)中的web程序。
特点:
(1)实际上Oozie不是仅用来配置多个MR工作流的,它可以是各种程序夹杂在一起的工作流,比如执行一个MR1后,接着执行一个java脚本,再执行一个shell脚本,接着是Hive脚本,然后又是Pig脚本,最后又执行了一个MR2,使用Oozie可以轻松完成这种多样的工作流。使用Oozie时,若前一个任务执行失败,后一个任务将不会被调度。
(2)Oozie的工作流必须是一个有向无环图,实际上Oozie就相当于Hadoop的一个客户端,当用户需要执行多个关联的MR任务时,只需要将MR执行顺序写入workflow.xml,然后使用Oozie提交本次任务,Oozie会托管此任务流。
(3)Oozie定义了控制流节点(Control Flow Nodes)和动作节点(Action Nodes),其中控制流节点定义了流程的开始和结束,以及控制流程的执行路径(Execution Path),如decision,fork,join等;而动作节点包括Haoop map-reduce hadoop文件系统,Pig,SSH,HTTP,eMail和Oozie子流程
架构:
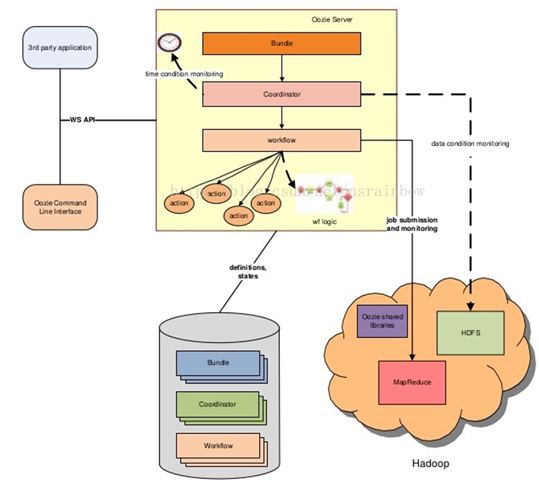
- workflow:工作流,由我们需要处理的每个工作组成,进行需求的流式处理。
- coordinator: 协调器,可将多个工作流协调成一个工作流来进行处理:多个workflow可以组成一个coordinator,可以把前几个workflow的输出作为后 一个workflow的输入,也可以定义workflow的触发条件,来做定时触发
- bundle:捆,束,将一堆的coordinator进行汇总处理,是对一堆coordinator的抽象
二、安装配置
通过CM安装Oozie服务或者手动安装
1、Oozie WEB控制台失效问题
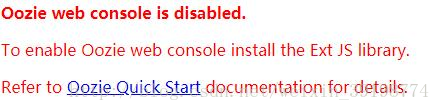
解压ext-2.2到/var/lib/oozie unzip ext-2.2.lib -d /var/lib/oozie
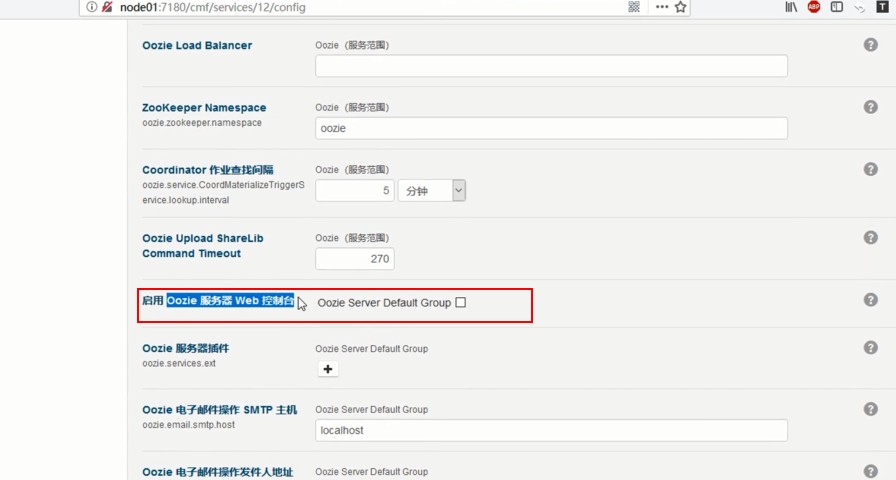
Oozie服务中配置启用web控制台
保存,重启Oozie服务
Oozie配置
1、节点内存配置
2、oozie.service.callablequeueservice.callable.concurrency(节点并发)
3、oozie.service.callablequeueservice.queue.size(队列大小)
4、oozie.service.ActionService.executor.ext.classes(扩展)
Oozie共享库
–/user/oozie/share/lib
web管理地址
oozie自带 WEBUI
http://oozie_host_ip:11000/oozie/

Hue UI:

三、客户端常用命令
Oozie CLI 命令
#启动任务:
[root@node1 oozie] oozie job -oozie http://ip:11000/oozie/ -config job.properties –run
#提交任务:
[root@node1 oozie] oozie job -oozie http://ip:11000/oozie/ -config job.properties –submit
#开始任务:
[root@node1 oozie] oozie job -oozie http://ip:11000/oozie/ -config job.properties –start 0000003-150713234209387-oozie-oozi-W
#停止任务:
[root@node1 oozie] oozie job -oozie http://ip:11000/oozie/ -kill 0000002-150713234209387-oozie-oozi-W #查看任务执行情况:
[root@node1 oozie] oozie job -oozie http://ip:11000/oozie/ -config job.properties –info 0000003-150713234209387-oozie-oozi-W
注意:启动任务其实包含:提交任务和开始任务,两个命令合成一个。
四、Oozie任务配置
1、Hue操作 workflows
参考:
Hue中使用Oozie的workflow执行MR过程
通过hue提交oozie定时任务
2、通过配置文件使用
2.1两个重要的配置文件:
job.properties

2.2workflow.xml
(1)版本信息
–<workflow-app xmlns="uri:oozie:workflow:0.4" name=“workflow name">
(2)EL函数
– 基本的EL函数
•String firstNotNull(String value1, String value2)
•String concat(String s1, String s2)
•String replaceAll(String src, String regex, String replacement)
•String appendAll(String src, String append, String delimeter)
•String trim(String s)
•String urlEncode(String s)
•String timestamp()
•String toJsonStr(Map) (since Oozie 3.3)
•String toPropertiesStr(Map) (since Oozie 3.3)
•String toConfigurationStr(Map) (since Oozie 3.3)
WorkFlow EL
•String wf:id() – 返回当前workflow作业ID
•String wf:name() – 返回当前workflow作业NAME
•String wf:appPath() – 返回当前workflow的路径
•String wf:conf(String name) – 获取当前workflow的完整配置信息
•String wf:user() – 返回启动当前job的用户
•String wf:callback(String stateVar) – 返回结点的回调URL,其中参数为动作指定的退出状态
•int wf:run() – 返回workflow的运行编号,正常状态为0
•Map wf:actionData(String node) – 返回当前节点完成时输出的信息
•int wf:actionExternalStatus(String node) – 返回当前节点的状态
•String wf:lastErrorNode() – 返回最后一个ERROR状态推出的节点名称
•String wf:errorCode(String node) – 返回指定节点执行job的错误码,没有则返回空
•String wf:errorMessage(String message) – 返回执行节点执行job的错误信息,没有则返回空
– HDFS EL
•boolean fs:exists(String path)
•boolean fs:isDir(String path)
•long fs:dirSize(String path) – 目录则返回目录下所有文件字节数;否则返回-1
•long fs:fileSize(String path) – 文件则返回文件字节数;否则返回-1
•long fs:blockSize(String path) – 文件则返回文件块的字节数;否则返回-1
(3)节点
– A、流程控制节点
•start – 定义workflow开始
•end – 定义workflow结束
•decision – 实现switch功能
•sub-workflow – 调用子workflow
•kill – 杀死workflow
•fork – 并发执行workflow
•join – 并发执行结束(与fork一起使用)
– B、动作节点
•shell
•java
•fs
•MR
•hive
•sqoop
<decision name="[NODE-NAME]">
<switch>
<case to="[NODE_NAME]">[PREDICATE]</case>
...
<case to="[NODE_NAME]">[PREDICATE]</case>
<default to="[NODE_NAME]" />
</switch>
</decision>
<fork name="[FORK-NODE-NAME]">
<path start="[NODE-NAME]" />
...
<path start="[NODE-NAME]" />
</fork>
...
<join name="[JOIN-NODE-NAME]" to="[NODE-NAME]" />
五、示例
1、Oozie shell
(1)编写job.properties
nameNode=hdfs://master:8020
jobTracker=master:
queueName=default
examplesRoot=examples
#指定workflow.xml所在目录
oozie.wf.application.path=${nameNode}/user/workflow/oozie/shell
注意:job.properties文件可以不上传到hdfs中,是在执行oozie job ...... -config时,批定的linux本地路径
(2)编写workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>echo</exec>
<argument>my_output=Hello Oozie</argument>
<capture-output/>
</shell>
<ok to="check-output"/>
<error to="fail"/>
</action>
<decision name="check-output">
<switch>
<case to="end"> ${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'} </case>
<default to="fail-output"/>
</switch>
</decision>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
文件上传到HDFS路径:hdfs://master:8020/user/workflow/oozie/shell 或者直接在Hue文件浏览器下创建和编辑workflow.xml
(3)CLI 执行启动任务命令,返回一个job ID

在UI里查看:

点击查看详情:

查看Job DAG

2、Oozie fs
(1)编写job.properties
nameNode=hdfs://master:8020
jobTracker=master:
queueName=default
examplesRoot=examples
#指定oozie使用系统的共享目录
oozie.use.system.libpath=true
#指定workflow.xml所在目录
oozie.wf.application.path=${nameNode}/user/examples/apps/fs/workflow.xml
(2)编写workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.2" name="fs">
<start to="fs-node"/>
<action name="fs-node">
<fs>
<delete path='/home/kongc/oozie'/>
<mkdir path='/home/kongc/oozie1'/>
<move source='/home/kongc/spark-application' target='/home/kongc/oozie1'/>
</fs>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
3、Oozie Sqoop
(1)编写job.properties
nameNode=hdfs://master:8020
jobTracker=master:8032
queueName=default
examplesRoot=examples
#指定oozie使用系统的共享目录
oozie.use.system.libpath=true
#指定workflow.xml所在目录
oozie.wf.application.path=${nameNode}/user/examples/apps/sqoop
#编写配置文件
#HSQL Database Engine 1.8.0.5
#Tue Oct :: SGT
hsqldb.script_format=
runtime.gc_interval=
sql.enforce_strict_size=false
hsqldb.cache_size_scale=
readonly=false
hsqldb.nio_data_file=true
hsqldb.cache_scale=
version=1.8.
hsqldb.default_table_type=memory
hsqldb.cache_file_scale=
hsqldb.log_size=
modified=no
hsqldb.cache_version=1.7.
hsqldb.original_version=1.8.
hsqldb.compatible_version=1.8.
#编写SQL
CREATE SCHEMA PUBLIC AUTHORIZATION DBA
CREATE MEMORY TABLE TT(I INTEGER NOT NULL PRIMARY KEY,S VARCHAR(256))
CREATE USER SA PASSWORD ""
GRANT DBA TO SA
SET WRITE_DELAY 10
SET SCHEMA PUBLIC
INSERT INTO TT VALUES(1,'a')
INSERT INTO TT VALUES(2,'a')
INSERT INTO TT VALUES(3,'a')
(2)编写workflow.xml
<?xml version="1.0" encoding="UTF-8"?>
<workflow-app xmlns="uri:oozie:workflow:0.2" name="sqoop-wf">
<start to="sqoop-node"/>
<action name="sqoop-node">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/oozie/${examplesRoot}/output-data/sqoop"/>
<mkdir path="${nameNode}/user/oozie/${examplesRoot}/output-data"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<command>import --connect jdbc:hsqldb:file:db.hsqldb --table TT --target-dir /user/oozie/${examplesRoot}/output-data/sqoop -m 1</command>
<file>db.hsqldb.properties#db.hsqldb.properties</file>
<file>db.hsqldb.script#db.hsqldb.script</file>
</sqoop>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Sqoop failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
4、Oozie Java
(1)编写job.properties
nameNode=hdfs://master:8020
jobTracker=master:
queueName=default
examplesRoot=examples
#指定oozie使用系统的共享目录
oozie.use.system.libpath=true
#指定workflow.xml所在目录
oozie.wf.application.path=${nameNode}/user/examples/apps/java-main
(2)编写workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.2" name="java-main-kc">
<start to="java-node"/>
<action name="java-node">
<java>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<main-class>org.apache.oozie.example.DemoJavaMain</main-class>
<arg>Hello</arg>
<arg>Oozie!</arg>
</java>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Java failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
5、Oozie Hive
(1)编写job.properties
nameNode=hdfs://master:8020
jobTracker=master:
queueName=default
examplesRoot=examples
#指定oozie使用系统的共享目录
oozie.use.system.libpath=true
#指定workflow.xml所在目录
oozie.wf.application.path=${nameNode}/user/examples/apps/hive
(2)编写workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.5" name="hive2-wf">
<start to="hive2-node"/>
<action name="hive2-node">
<hive2 xmlns="uri:oozie:hive2-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/oozie/${examplesRoot}/output-data/hive2"/>
<mkdir path="${nameNode}/user/oozie/${examplesRoot}/output-data"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<jdbc-url>${jdbcURL}</jdbc-url>
<script>script.q</script>
<param>INPUT=/user/oozie/${examplesRoot}/input-data/table</param>
<param>OUTPUT=/user/oozie/${examplesRoot}/output-data/hive2</param>
</hive2>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Hive2 (Beeline) action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
编写hive脚本
INSERT OVERWRITE DIRECTORY '${OUTPUT}' SELECT * FROM test_machine;
6、Oozie Impala
(1)编写job.properties
nameNode=hdfs://master:8020
jobTracker=master:
queueName=default
examplesRoot=examples
#指定oozie使用系统的共享目录
oozie.use.system.libpath=true
#指定workflow.xml所在目录
oozie.wf.application.path=${nameNode}/user/examples/apps/impala
EXEC=impala.sh
(2)编写workflow.xml
<workflow-app name="shell-impala" xmlns="uri:oozie:workflow:0.4">
<start to="shell-impala-invalidate"/>
<action name="shell-impala-invalidate">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<file>${EXEC}#${EXEC}</file>
</shell>
<ok to="end"/>
<error to="kill"/>
</action>
<kill name="kill">
<message>Action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
(3)impala.sh
#!/bin/bash
impala-shell -i slave2: -q "select count(*) from test_machine"
echo 'Hello Shell'
7、ozie MapReduce
(1)编写job.properties
nameNode=hdfs://master:8020
jobTracker=master:
queueName=default
examplesRoot=examples #指定workflow.xml所在目录
oozie.wf.application.path=${nameNode}/user/examples/apps/map-reduce/workflow.xml
outputDir=map-reduce
(2)编写workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.2" name="map-reduce-wyl">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/oozie/${examplesRoot}/output-data/${outputDir}"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.mapper.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/oozie/${examplesRoot}/input-data/text</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/oozie/${examplesRoot}/output-data/${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
8、Oozie Spark
(1)编写job.properties
nameNode=hdfs://master:8020
jobTracker=master:
queueName=default
examplesRoot=examples
#指定oozie使用系统的共享目录
oozie.use.system.libpath=true
#指定workflow.xml所在目录
oozie.wf.application.path=${nameNode}/user/examples/apps/spark
(2)编写workflow.xml
<workflow-app xmlns='uri:oozie:workflow:0.5' name='SparkFileCopy'>
<start to='spark-node' />
<action name='spark-node'>
<spark xmlns="uri:oozie:spark-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/oozie/${examplesRoot}/output-data/spark"/>
</prepare>
<master>${master}</master>
<name>Spark-FileCopy</name>
<class>org.apache.oozie.example.SparkFileCopy</class>
<jar>${nameNode}/user/oozie/${examplesRoot}/apps/spark/lib/oozie-examples.jar</jar>
<arg>${nameNode}/user/oozie/${examplesRoot}/input-data/text/data.txt</arg>
<arg>${nameNode}/user/oozie/${examplesRoot}/output-data/spark</arg>
</spark>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<message>Workflow failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message>
</kill>
<end name='end' />
</workflow-app>
9、Oozie 定时任务
(1)编写job.properties
nameNode=hdfs://master:8020
jobTracker=master:
queueName=default
examplesRoot=examples oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/aggregator/coordinator.xml
start=--01T01:00Z
end=--01T03:00Z
(2)编写coordinator.xml
<coordinator-app name="aggregator-coord" frequency="${coord:hours(1)}" start="${start}" end="${end}" timezone="UTC" xmlns="uri:oozie:coordinator:0.2">
<controls>
<concurrency>1</concurrency>
</controls>
<datasets>
<dataset name="raw-logs" frequency="${coord:minutes(20)}" initial-instance="2010-01-01T00:00Z" timezone="UTC">
<uri-template>${nameNode}/user/${coord:user()}/${examplesRoot}/input-data/rawLogs/${YEAR}/${MONTH}/${DAY}/${HOUR}/${MINUTE}</uri-template>
</dataset>
<dataset name="aggregated-logs" frequency="${coord:hours(1)}" initial-instance="2010-01-01T01:00Z" timezone="UTC">
<uri-template>${nameNode}/user/${coord:user()}/${examplesRoot}/output-data/aggregator/aggregatedLogs/${YEAR}/${MONTH}/${DAY}/${HOUR}</uri-template>
</dataset>
</datasets>
<input-events>
<data-in name="input" dataset="raw-logs">
<start-instance>${coord:current(-2)}</start-instance>
<end-instance>${coord:current(0)}</end-instance>
</data-in>
</input-events>
<output-events>
<data-out name="output" dataset="aggregated-logs">
<instance>${coord:current(0)}</instance>
</data-out>
</output-events>
<action>
<workflow>
<app-path>${nameNode}/user/${coord:user()}/${examplesRoot}/apps/aggregator</app-path>
<configuration>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
<property>
<name>inputData</name>
<value>${coord:dataIn('input')}</value>
</property>
<property>
<name>outputData</name>
<value>${coord:dataOut('output')}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
注意事项:
- job.properties文件可以不上传到hdfs中,是在执行oozie job ...... -config时,批定的linux本地路径
- workflow.xml文件,一定要上传到job.properties的oozie.wf.application.path对应的hdfs目录下。
- job.properties中的oozie.use.system.libpath=true指定oozie使用系统的共享目录。
- job.properties中的oozie.libpath=${nameNode}/user/${user.name}/apps/mymr,可以用来执行mr时,作业导出的jar包存放位置,否则可能报找不到类的错误。
- oozie调度作业时,本质也是启动一个mapreduce作业来调度,workflow.xml中设置的队列名称为调度作业mr的队列名称。所以如果想让作业运行在指定的队列时,需要在mr或hive中指定好。
【Oozie学习之一】Oozie的更多相关文章
- 大数据技术之_14_Oozie学习_Oozie 的简介+Oozie 的功能模块介绍+Oozie 的部署+Oozie 的使用案列
第1章 Oozie 的简介第2章 Oozie 的功能模块介绍2.1 模块2.2 常用节点第3章 Oozie 的部署3.1 部署 Hadoop(CDH版本的)3.1.1 解压缩 CDH 版本的 hado ...
- Hadoop Oozie 学习笔记
Oozie是一个工作流引擎服务器,用于运行Hadoop Map/Reduce和Pig 任务工作流.同时Oozie还是一个Java Web程序,运行在Java Servlet容器中,如Tomcat. O ...
- oozie学习笔记
#################################################################################################### ...
- connection failed to http://nssa-sensor3:11000/oozie/?user.name=oozie(<urlopen erroer Errno 111] Connection refused>)解决办法(图文详解)
不多说,直接上干货! 解决办法 Copy/Paste oozie.services property tag set from oozie-default.xml to oozie-site.xml. ...
- #数据技术选型#即席查询Shib+Presto,集群任务调度HUE+Oozie
郑昀 创建于2014/10/30 最后更新于2014/10/31 一)选型:Shib+Presto 应用场景:即席查询(Ad-hoc Query) 1.1.即席查询的目标 使用者是产品/运营/销售 ...
- 高可用Hadoop平台-Oozie工作流之Hadoop调度
1.概述 在<高可用Hadoop平台-Oozie工作流>一篇中,给大家分享了如何去单一的集成Oozie这样一个插件.今天为大家介绍如何去使用Oozie创建相关工作流运行与Hadoop上,已 ...
- 高可用Hadoop平台-Oozie工作流
1.概述 在开发Hadoop的相关应用使用,在业务不复杂,任务不多的情况下,我们可以直接使用Crontab去完成相关应用的调度.今天给大家介绍的是统一管理各种调度任务的系统,下面为今天分享的内容目录: ...
- Oozie框架基础
* Oozie框架基础 官方文档地址:http://oozie.apache.org/docs/4.0.0/DG_QuickStart.html 除Oozie之外,类似的框架还有: ** Zeus:h ...
- Oozie、Flume、Mahout配置与应用
-------------------------Oozie-------------------- [一.部署] 1)部署Oozie服务端 [root@cMaster~]#sudo yum inst ...
随机推荐
- 如何在Win10上永久禁用Windows Defender Antivirus
1.使用Windows键+ R键盘快捷键打开运行命令. 2.键入regedit,然后单击确定以打开注册表. 3.浏览以下路径: HKEY_LOCAL_MACHINE/SOFTWARE/Policies ...
- 洛谷P4052 [JSOI2007]文本生成器 AC自动机+dp
正解:AC自动机+dp 解题报告: 传送门! 感觉AC自动机套dp的题还挺套路的,,, 一般就先跑遍AC自动机,然后就用dp dp的状态一般都是f[i][j]:有i个字符,是ac自动机上的第j个节点, ...
- 牛客网Wannafly挑战赛25A 因子 数论
正解:小学数学数论 解题报告: 传送门 大概会连着写几道相对而言比较简单的数学题,,,之后就会比较难了QAQ 所以这题相对而言还是比较水的,,, 首先这种题目不难想到分解质因数趴,, 于是就先对p和n ...
- mvn install package区别
package是把jar打到本项目的target下,而install时把target下的jar安装到本地仓库,供其他项目使用
- oracle用户被锁
使用PLSQL客户端:1.用管理员账户登录PLSQL Developer(登录名可以为system,选择类型的时候把Normal修改为Sysdba).2.左侧选择My Objects,查看Users文 ...
- ZedBoard上运行linux系统的准备工作框架
目标:ZedBoard上运行linux系统. 需要什么:图中上色部分. 应该做哪些工作:上色部分之前的所有步骤. 由上图得知,为了顺利在zedboard上构建嵌入式Linux操作系统,我们一般需要如下 ...
- mysql触发器:插入数据前更新创建时间为服务器的时间
DROP TRIGGER IF EXISTS `upd_patientquestionnaire`; create trigger upd_patientquestionnaire BEFORE in ...
- 卸载postgresql数据库
卸载postgresql数据库有两种方法,第一种一个个包卸载,第二种全部卸载.做这些之前请先做好备份,以防意外! 1.1.查询出postgres数据库,用命令rpm -qa |grep postgre ...
- bat处理打开关闭exe
@echo off rem rem 注释 tastkill /f /im a.exe cd %CD% %CD:~0,1%: cd %Cd%b start %CD%a.exe cd .. %CD:~0 ...
- 细细探究MySQL Group Replicaiton — 配置维护故障处理全集(转)
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持!