storm 001
Hadoop、Storm系统和组件接口对比表: package storm;
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
/**
* 组织各个处理组件形成一个完整的处理流程,就是所谓的topology(类似于mapreduce程序中的job)
* 并且将该topology提交给storm集群去运行,topology提交到集群后就将永无休止地运行,除非人为或者异常退出
*/
public class TopoMain {//storm.TopoMain
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
// 将我们的spout组件设置到topology中去
// parallelism_hint :4 表示用4个excutor来执行这个组件
// setNumTasks(8) 设置的是该组件执行时的并发task数量,也就意味着1个excutor会运行2个task
builder.setSpout("randomspout", new RandomWordSpout(), 4).setNumTasks(8);
// 将大写转换bolt组件设置到topology,并且指定它接收randomspout组件的消息
// .shuffleGrouping("randomspout")包含两层含义:
// 1、upperbolt组件接收的tuple消息一定来自于randomspout组件
// 2、randomspout组件和upperbolt组件的大量并发task实例之间收发消息时采用的分组策略是随机分组shuffleGrouping
builder.setBolt("upperbolt", new UpperBolt(), 4).shuffleGrouping("randomspout");
// 将添加后缀的bolt组件设置到topology,并且指定它接收upperbolt组件的消息
builder.setBolt("suffixbolt", new SuffixBolt(), 4).shuffleGrouping("upperbolt");
// 用builder来创建一个topology
StormTopology demotop = builder.createTopology();
// 配置一些topology在集群中运行时的参数
Config conf = new Config();
// 这里设置的是整个demotop所占用的槽位数,也就是worker的数量
conf.setNumWorkers(4);
conf.setDebug(true);
conf.setNumAckers(0);
//System.setProperty("storm.jar", "/home/hadoop/storm.jar");
// 将这个topology提交给storm集群运行
StormSubmitter.submitTopology("demotopo2", conf, demotop);
//Must submit topologies using the 'storm' client script so that StormSubmitter knows which jar to upload.
}
}
-----------------------------------------------------------------------------------------------------------------
package storm; import java.util.Map; import java.util.Random; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; public class RandomWordSpout extends BaseRichSpout { private SpoutOutputCollector collector; // 模拟一些数据 String[] str = { "hello", "word", "you", "how", "are" }; // 初始化方法,在spout组件实例化时调用一次 @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.collector = collector; } // 声明本spout组件发送出去的tuple中的数据的字段名 @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("orignname")); } @Override public void nextTuple() { // 随机挑选出一个名称 Random random = new Random(); int index = random.nextInt(str.length); // 获取名称 String name = str[index]; // 将名称进行封装成tuple,发送消息给下一个组件 collector.emit(new Values(name)); } }
************************************************
package storm; import java.io.FileWriter; import java.io.IOException; import java.util.Map; import java.util.UUID; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Tuple; public class SuffixBolt extends BaseBasicBolt { FileWriter fileWriter = null; // 在bolt组件运行过程中只会被调用一次 @Override public void prepare(Map stormConf, TopologyContext context) { try { fileWriter = new FileWriter("/home/hadoop/stormoutput2/" + UUID.randomUUID()); } catch (IOException e) { throw new RuntimeException(e); } } // 该bolt组件的核心处理逻辑 // 每收到一个tuple消息,就会被调用一次 @Override public void execute(Tuple tuple, BasicOutputCollector collector) { // 先拿到上一个组件发送过来的名称 String upper_name = tuple.getString(0); String suffix_name = upper_name + "_itisok"; // 为上一个组件发送过来的商品名称添加后缀 try { fileWriter.write(suffix_name); fileWriter.write("\n"); fileWriter.flush(); } catch (IOException e) { throw new RuntimeException(e); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { // TODO Auto-generated method stub } }
***********************************************
package storm; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; public class UpperBolt extends BaseBasicBolt { // 业务处理逻辑 @Override public void execute(Tuple tuple, BasicOutputCollector collector) { // 先获取到上一个组件传递过来的数据,数据在tuple里面 String godName = tuple.getString(0); // 将名称转换成大写 String godName_upper = godName.toUpperCase(); // 将转换完成的商品名发送出去 collector.emit(new Values(godName_upper)); } // 声明该bolt组件要发出去的tuple的字段 @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("uppername")); } }
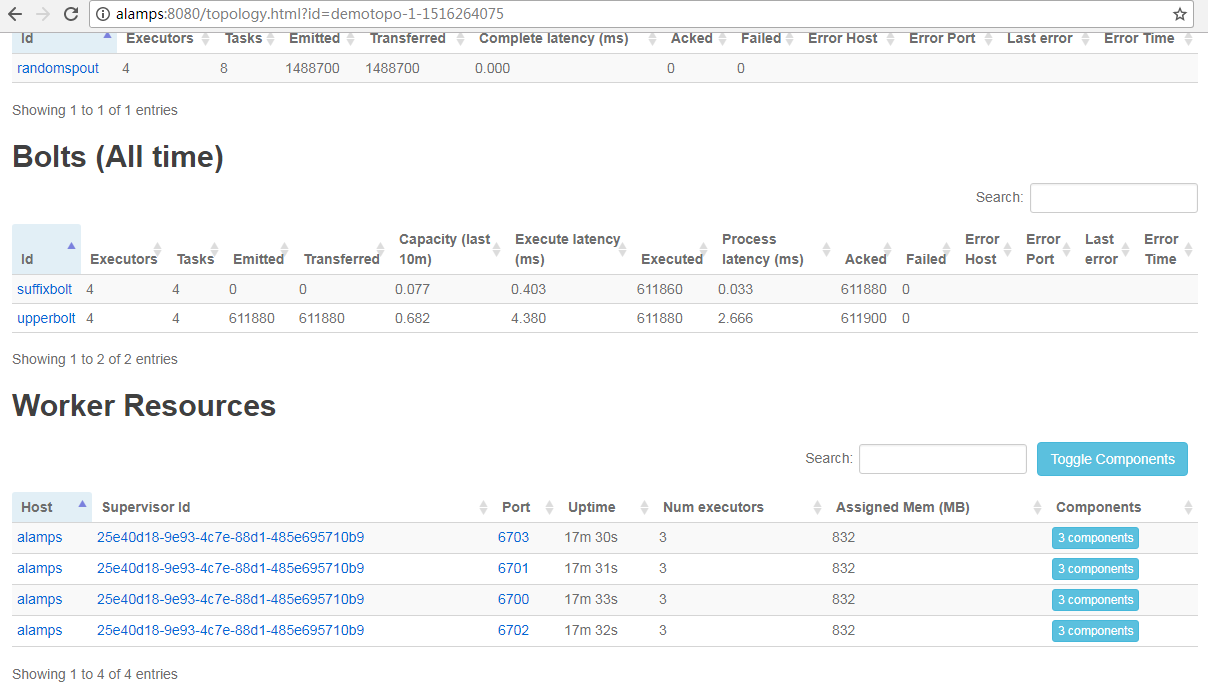
[root@alamps bin]# mkdir /home/hadoop/stormoutput2
[root@alamps bin]# storm jar /home/hadoop/storm2.jar storm.TopoMain
Running: /home/hadoop/app/jdk1..0_144/bin/java -client -Ddaemon.name= -Dstorm.options= -Dstorm.home=/home/hadoop/app/storm -Dstorm.log.dir=/home/hadoop/app/storm/logs -Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file= -cp /home/hadoop/app/storm/lib/storm-rename-hack-1.1..jar:/home/hadoop/app/storm/lib/log4j-core-2.8..jar:/home/hadoop/app/storm/lib/reflectasm-1.10..jar:/home/hadoop/app/storm/lib/log4j-over-slf4j-1.6..jar:/home/hadoop/app/storm/lib/minlog-1.3..jar:/home/hadoop/app/storm/lib/kryo-3.0..jar:/home/hadoop/app/storm/lib/objenesis-2.1.jar:/home/hadoop/app/storm/lib/disruptor-3.3..jar:/home/hadoop/app/storm/lib/storm-core-1.1..jar:/home/hadoop/app/storm/lib/servlet-api-2.5.jar:/home/hadoop/app/storm/lib/asm-5.0..jar:/home/hadoop/app/storm/lib/log4j-slf4j-impl-2.8..jar:/home/hadoop/app/storm/lib/log4j-api-2.8..jar:/home/hadoop/app/storm/lib/ring-cors-0.1..jar:/home/hadoop/app/storm/lib/slf4j-api-1.7..jar:/home/hadoop/app/storm/lib/clojure-1.7..jar:/home/hadoop/storm2.jar:/home/hadoop/app/storm/conf:/home/hadoop/app/storm/bin -Dstorm.jar=/home/hadoop/storm2.jar -Dstorm.dependency.jars= -Dstorm.dependency.artifacts={} storm.TopoMain
[main] WARN o.a.s.u.Utils - STORM-VERSION new 1.1. old null
[main] INFO o.a.s.StormSubmitter - Generated ZooKeeper secret payload for MD5-digest: -:-
[main] INFO o.a.s.u.NimbusClient - Found leader nimbus : alamps:
[main] INFO o.a.s.s.a.AuthUtils - Got AutoCreds []
[main] INFO o.a.s.u.NimbusClient - Found leader nimbus : alamps:
[main] INFO o.a.s.StormSubmitter - Uploading dependencies - jars...
[main] INFO o.a.s.StormSubmitter - Uploading dependencies - artifacts...
[main] INFO o.a.s.StormSubmitter - Dependency Blob keys - jars : [] / artifacts : []
[main] INFO o.a.s.StormSubmitter - Uploading topology jar /home/hadoop/storm2.jar to assigned location: /home/hadoop/app/storm/storm-local/nimbus/inbox/stormjar-408de160-c6d7-4d2c-895a-1416d94ea4a2.jar
[main] INFO o.a.s.StormSubmitter - Successfully uploaded topology jar to assigned location: /home/hadoop/app/storm/storm-local/nimbus/inbox/stormjar-408de160-c6d7-4d2c-895a-1416d94ea4a2.jar
[main] INFO o.a.s.StormSubmitter - Submitting topology demotopo2 in distributed mode with conf {"topology.acker.executors":,"storm.zookeeper.topology.auth.scheme":"digest","storm.zookeeper.topology.auth.payload":"-8576047804864739509:-7581013764627825431","topology.workers":,"topology.debug":true}
[main] WARN o.a.s.u.Utils - STORM-VERSION new 1.1. old 1.1.
[main] INFO o.a.s.StormSubmitter - Finished submitting topology: demotopo2
storm 001的更多相关文章
- storm实战:基于storm,kafka,mysql的实时统计系统
公司对客户开放多个系统,运营人员想要了解客户使用各个系统的情况,在此之前,数据平台团队已经建设好了统一的Kafka消息通道. 为了保证架构能够满足业务可能的扩张后的性能要求,选用storm来处理各个应 ...
- Kafka+Storm+HDFS整合实践
在基于Hadoop平台的很多应用场景中,我们需要对数据进行离线和实时分析,离线分析可以很容易地借助于Hive来实现统计分析,但是对于实时的需求Hive就不合适了.实时应用场景可以使用Storm,它是一 ...
- 参考storm中的RotatingMap实现key超时处理
storm0.8.1以后的RotatingMap完全可以独立于storm用来实现hashmap的key超时删除,并调用回调函数 RotatingMap.java: import java.util.H ...
- Storm系列二: Storm拓扑设计
Storm系列二: Storm拓扑设计 在本篇中,我们就来根据一个案例,看看如何去设计一个拓扑, 如何分解问题以适应Storm架构,同时对Storm拓扑内部的并行机制会有一个基本的了解. 本章代码都在 ...
- Storm如何保证可靠的消息处理
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文主要翻译自Storm官方文档Guaranteeing messag ...
- Storm
2016-11-14 22:05:29 有哪些典型的Storm应用案例? 数据处理流:Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去.不像其它的流处理系统,Storm不 ...
- Storm介绍(一)
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 内容简介 本文是Storm系列之一,介绍了Storm的起源,Storm ...
- 理解Storm并发
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 注:本文主要内容翻译自understanding-the-parall ...
- Storm构建分布式实时处理应用初探
最近利用闲暇时间,又重新研读了一下Storm.认真对比了一下Hadoop,前者更擅长的是,实时流式数据处理,后者更擅长的是基于HDFS,通过MapReduce方式的离线数据分析计算.对于Hadoop, ...
随机推荐
- Servlet基本介绍和使用
基本概念 Servlet又称为Java Servlet是一个基于java技术的web组件,运行在服务器端,用于生成动态的内容.Servlet是平台独立的java类,编写一个Servlet实际上就是按照 ...
- 原声js,取消事件冒泡,点击按钮,显示box,点击屏幕其他地方,box隐藏
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- /var/run/utmp文件操作函数
相关函数:getutent, getutid, getutline, setutent, endutent, pututline, utmpname utmp 结构定义如下:struct utmp{ ...
- jquery代码修改input的value值,而页面上input框的值没有改变的解决办法
问题描述: 在搜索框中输入一些字符,并且点击搜索框右边的五角星做收藏操作时,打开的弹框中Save Search:后面的input中的值被赋值了外面搜索框的值,但是当此次操作完成之后,再次做同样的操作, ...
- intellij idea建立maven项目
配置jdk 配置mvn http://jingyan.baidu.com/article/d8072ac45d3660ec94cefd51.html 右键“计算机”,选择“属性”,之后点击“高级系统设 ...
- 火币网API文档——REST 行情、交易API简介
REST API 简介 火币为用户提供了一套全新的API,可以帮用户快速接入火币PRO站及HADAX站的交易系统,实现程序化交易. 访问地址 适用站点 适用功能 适用交易对 https://api.h ...
- what's the python之函数及装饰器
what's the 函数? 函数的定义:(return是返回值,可以没有,不过没有的话就返回了None) def wrapper(参数1,参数2,*args,默认参数,**kwargs): '''注 ...
- The type org.springframework.context.ConfigurableApplicationContext cannot be resolved.
The type org.springframework.context.ConfigurableApplicationContext cannot be resolved. eclipse导入mav ...
- Mongodb 基础 查询表达式
数据库操作 查看:show dbs; 创建:use dbname; // db.createCollection('collection_name'); 隐式创建,需要创建的数据库中有表才表示创 ...
- 2018-2019-1 20189221 《Linux内核原理与分析》第八周作业
2018-2019-1 20189221 <Linux内核原理与分析>第八周作业 实验七 编译链接过程 gcc –e –o hello.cpp hello.c / gcc -x cpp-o ...