目标检测--Scalable Object Detection using Deep Neural Networks(CVPR 2014)
Scalable Object Detection using Deep Neural Networks
作者: Dumitru Erhan, Christian Szegedy, Alexander Toshev, and Dragomir Anguelov
引用: Erhan, Dumitru, et al. "Scalable object detection using deep neural networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014.
引用次数: 181(Google Scholar, by 2016/11/23).
项目地址: https://github.com/google/multibox
1 介绍
这是一篇2014年发表的CVPR会议论文, 几个作者都是Google公司的,文中的检测算法被命名为"DeepMultiBox".首先来看一下本文模型的思路: 本文的目标检测还是采用两步走的策略:
第一步: 在图像上生成候选区域; 以前常用的生成候选区域的方法是穷举法,对图像上所有的位置以及尺度进行穷举,这种计算效率太低,已经遭到废弃,现在陆续出来一些其他的方法,比如论文<论文阅读笔记--Selective Search for Object Recognition>里面提出的Selective Search的方法,利用层次聚类的思想,生成指定数目最可能包含目标的候选区域.同样,本文也是在这一方面做努力,提出了使用CNN来生成候选区域,并且命名为"DeepMultiBox";
第二步: 利用CNN对生成的候选区域进行分类; 生成候选区域后,提取特征,然后利用分类器进行分类从而达到识别的目的,这是一般的思路,没有什么好讲的,本文的重心在第一步.
2 本文模型
2.1 回归模型DeepMultiBox
如何使用CNN来在图像上生成候选区域呢? 本文借鉴了AlexNet网络的结构:
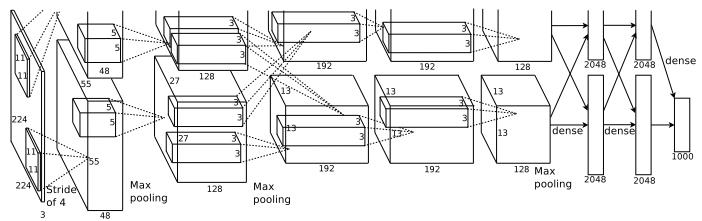
要对这个问题进行建模! 我们这里的目的是想让CNN输出一定数量的bounding boxes(每个box用4个参数表示,分别是此box的左上角的横坐标+纵坐标,右下角的横坐标+纵坐标,对每个坐标值要用图像的宽和高进行归一化),另外还要输出每个box上还要有一个是否包含目标的置信度(值介于0~1之间).这样,如果我们想让CNN输出K=100个bounding boxes,CNN输出层节点的维度要为(K*(4+1)=5*K=500).
2.1.1 DeepMultiBox的训练集构造
训练集是如何构造的? 训练集的输入肯定是每张训练图像上的"maximum center square crop",这个的含义是先计算每张图像的中心点,然后以它为中心从图像上裁剪出来一个最大的正方形,为了满足AlexNet的网络结构,可能每张图像还要resize到220*220大小(这点在原文中的4.2.2中讲述);关键在于输出,这点文中讲的比较隐晦,原文的表述为:"For each image,we generate the same number of square samples such that the total number of samples is about ten million.For each image, the samples are bucketed such that for each of the ratios in the ranges of 0−5%, 5−15%, 15−50%, 50−100%,there is an equal number of samples in which the ratio covered by the bounding boxes is in the given range." 我的理解是,对于训练集中的每个图像,产生固定数量(假设为N)的正方形的区域作为训练集(问题1:为什么要是正方形? 这些区域的大小都是相同的吗?如果相同,如何满足目标多尺度要求?如果不相同,如何选择区域的大小?),这N个区域的选择是有讲究的:它由四份组成,每份中区域向数量相等,而且每份中的区域与图像上GT boxes的重合程度分别是0-5%,5-15%,15-50%,50-100%.每个区域的置信度也没有讲要如何确定,我想应该就是每个区域与GT boxes的重合程度吧!
(问题2: 训练样本是不是这样构造的,还请指教!)
2.1.2 DeepMultiBox的训练
2.2里面讲述了训练集是如何构造的(有可能我理解的不正确,但是文中讲述的也太隐晦了),下面开始训练AlexNet模型.假如回归bounding box的数目K设定为100的话,将有500个参量需要回归,这样AlexNet的输出层节点的数目就要被设置为500(这点文中也没有讲).由于是回归,在CNN后面直接用Softmax可能不行,作者自己定于了目标函数,具体的见原论文.
2.2 CNN分类模型
2.2.1 分类模型的训练集构造
DeepMultiBox在每张图像上回归了K个候选区域,然而这些候选区域到底属于哪一类还不能确定,因此这里需要再训练一个CNN来对这些区域进行分类.
原文中的4.2.1节简短讲述了用于训练CNN分类器的训练样本构造(对于VOC数据集来说的,类别总数目为20):
正样本: 为每个类别构造正样本,如果候选区域和此类的GT boxes之间的Jaccard大于0.5,则此区域被标记成正样本,这样共产生了1千万个正样本,遍布20个类;
负样本: 和正样本构造的方式类似,只是Jaccard要小于0.2才被认定是负样本,这样,总共产生了2千万个负样本;
2.2.2 分类模型的结构
文中貌似没有具体讲述分类模型的结构,只知道用的也是AlexNet,输出层的节点数目肯定改成了21(对于VOC数据集而言),样本集区域的大小是多少不知道!每个样本区域要resize到AlexNet网络输入的指定大小,这点也没看到!
2.3 测试过程
测试的过程在原文的4.2.2节有讲到(假设有N个目标): 给定一张测试图像 --> 裁剪出它的最大正方形区域 --> 将此区域resize到220*220大小 --> 送入DeepMultiBox网络进行回归,得到K个回归boxes以及每个box的置信度分数 --> 利用非最大值抑制的方法将重叠度小于0.5的box去除掉 --> 拥有最高置信度分数的10个区域将被保留 --> 将这些区域送到分类CNN里面进行软分类,输出每个区域的概率值,得到10*(N+1)的概率矩阵 --> 每个区域的置信度分割乘上概率值作为它最终的分数 --> 这些分数用于估计和计算P-R曲线.
(问题3:这个测试的过程我认为最后少了一个对最终分数进行判断的过程,不知道最后是如何确定最终结果的!)
参考文献:
[1]
目标检测--Scalable Object Detection using Deep Neural Networks(CVPR 2014)的更多相关文章
- Scalable Object Detection using Deep Neural Networks译文
原文:https://arxiv.org/abs/1312.2249
- 多尺度目标检测 Multiscale Object Detection
多尺度目标检测 Multiscale Object Detection 我们在输入图像的每个像素上生成多个锚框.这些定位框用于对输入图像的不同区域进行采样.但是,如果锚定框是以图像的每个像素为中心生成 ...
- 基于深度学习的目标检测(object detection)—— rcnn、fast-rcnn、faster-rcnn
模型和方法: 在深度学习求解目标检测问题之前的主流 detection 方法是,DPM(Deformable parts models), 度量与评价: mAP:mean Average Precis ...
- 目标检测 - Tensorflow Object Detection API
一. 找到最好的工具 "工欲善其事,必先利其器",如果你想找一个深度学习框架来解决深度学习问题,TensorFlow 就是你的不二之选,究其原因,也不必过多解释,看过其优雅的代码架 ...
- 吴恩达《深度学习》第四门课(3)目标检测(Object detection)
3.1目标定位 (1)案例1:在构建自动驾驶时,需要定位出照片中的行人.汽车.摩托车和背景,即四个类别.可以设置这样的输出,首先第一个元素pc=1表示有要定位的物体,那么用另外四个输出元素表示定位框的 ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- 中文版 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 摘要 最先进的目标检测网络依靠区域提出算法 ...
- Object detection with deep learning and OpenCV
目录 Single Shot Detectors for Object Detection Deep learning-based object detection with OpenCV 这篇文 ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
随机推荐
- Sublime Text3—Project(项目管理)
摘要 Project 可以理解为项目.工程或者站点,以下称项目.使用项目管理的好处是:不用将所有文件都放到同一个根目录,可以将相关但不同路径的文件组成一个Project,每个项目都是独立的,文件的状态 ...
- 多线程(Thread,Runnable)
一.多线程. 1.进程:一个正在执行的程序叫做进程. 每一个进程的执行都有一个执行顺序,这个顺序就是一个执行的路径,或者叫做一个控制单元. 2.线程:就是上述进程中的一个独立控制单元, 线程在控制着进 ...
- pandas简短介绍
1.数据结构 维数 名称 描述 1 Series 一维带标签单一数据类型的数组 2 DataFrame 不同数据类型的列 2.十分钟学习pandas 2.1.导入所需模块 import pandas ...
- GO语言的进阶之路-Golang高级数据结构定义
GO语言的进阶之路-Golang高级数据结构定义 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们之前学习过Golang的基本数据类型,字符串和byte,以及rune也有所了解, ...
- python自动化运维之路~DAY2
python自动化运维之路~DAY2 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.字符编码与转码 1.什么是编码. 基本概念很简单.首先,我们从一段信息即消息说起,消息以人类 ...
- vue项目中使用scss
npm install sass-loader node-sass --save-dev
- 小心错误使用EasyUI 让网站性能减半
先不谈需求,和系统架构,直接上来就被抛来了一个问题----基础性能太差了,一个网页打开要好几秒.我了个天,我听了也简直不敢相信,难道是数据量特别大?还是其中业务逻辑特别复杂? 简单的介绍下,基础系统是 ...
- Spring+quartz 实现定时任务job集群配置【原】
为什么要有集群定时任务? 因为如果多server都触发相同任务,又同时执行,那在99%的场景都是不适合的.比如银行每晚24:00都要汇总营业额.像下面3台server同时进行汇总,最终计算结果可能是真 ...
- Linux命令(十)打包压缩、软件安装
- 21. Spring Boot Druid 数据源配置解析
1.数据源配置属性类源码 package org.springframework.boot.autoconfigure.jdbc; @ConfigurationProperties( prefix = ...