随机森林学习-sklearn
随机森林的Python实现 (RandomForestClassifier)

# -*- coding: utf- -*-
"""
RandomForestClassifier
skleran 的随机森林回归模型,应用流程。
.源数据随机的切分:%作为训练数据 %最为测试数据
.训练数据中的因变量(分类变量)处理成数字形式
.设定参数,训练/fit
.对测试数据,预测/predict结果y_pre
.对预测数据y列,y_pre列,生成混淆矩阵,显示分类/预测效果
"""
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names) #合并 自变量 和 因变量
df['is_train'] = np.random.uniform(, , len(df)) <= . #相当于随机抽取了75%作为训练数据
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names) #将数字类别转为文字类别
df.head() train, test = df[df['is_train']==True], df[df['is_train']==False] #拆分训练集和测试集 features = df.columns[:] # 前4个指标 为自变量
clf = RandomForestClassifier(n_jobs=) # n_jobs=2是线程数
y, _ = pd.factorize(train['species']) # 将文字类别 转为数字类别。一种序列化方法。第一参数是序列化后结果,第二个时参考
clf.fit(train[features], y) #训练过程 preds = iris.target_names[clf.predict(test[features])] # 获取测试数据预测结果
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds']) #生成混淆矩阵
#有意思的输出
clf.feature_importances_ # 输出 自变量的总要程度
clf.predict_proba(test[features]) #输出每个测试样本对应几种数据类型的概率值
150个数据,112做训练 38个最测试.
df数据示例- 测试数据,输出结果-
测试数据,输出结果-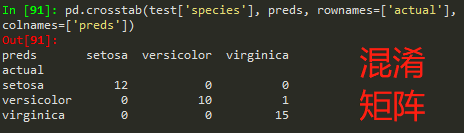
参考:[Machine Learning & Algorithm] 随机森林(Random Forest)
=============================================================================================================
知识点:
对 ‘RandomForestClassifier’ 原文 的 翻译
知识点:
#将数字类别转为文字类别
pd.Categorical.from_codes([0,1,2,1,0,0,1,-1], ['小猫','中猫','大猫'])
#Out[76]:
#[小猫, 中猫, 大猫, 中猫, 小猫, 小猫, 中猫, NaN]
#Categories (3, object): [小猫, 中猫, 大猫]
知识点:
# pd.factorize 用法
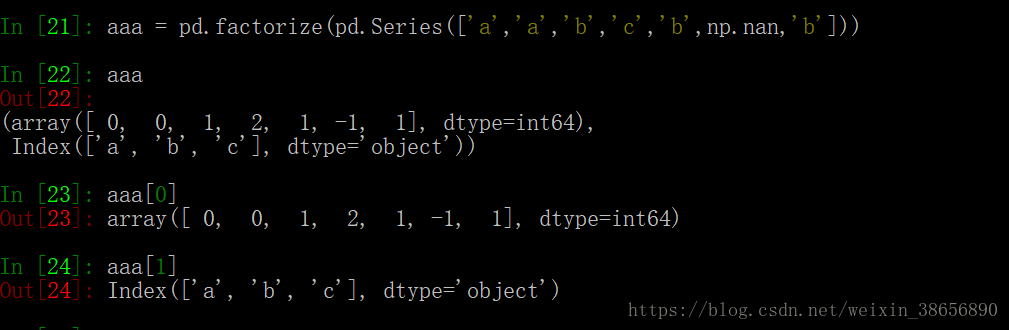
从例子中可以看到 pd.factorize() 返回的是一个tuple ,包含连个元素,第二个是源数据中所有数据的类别,当然取出了nan ,第一个是源数据在类别中对应的序号组成的array 看到这里可以发现 和pd.Categorical() 真的是非常像了。
知识点:
Pandas:透视表(pivotTab)和交叉表(crossTab)
知识点:
numpy.random.seed(1) #设定随机种子且仅在下一次随机时有效.
介绍Python-random模块的链接:
==================================================================================================================================================
随机森林学习-sklearn的更多相关文章
- 随机森林学习-2-sklearn
# -*- coding: utf-8 -*- """ RandomForestClassifier skleran的9个模型在3份数据上的使用. 1. 知识点: skl ...
- 随机森林random forest及python实现
引言想通过随机森林来获取数据的主要特征 1.理论根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系 ...
- 100天搞定机器学习|Day33-34 随机森林
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 04-10 Bagging和随机森林
目录 Bagging算法和随机森林 一.Bagging算法和随机森林学习目标 二.Bagging算法原理回顾 三.Bagging算法流程 3.1 输入 3.2 输出 3.3 流程 四.随机森林详解 4 ...
- 【笔记】随机森林和Extra-Trees
随机森林和Extra-Trees 随机森林 先前说了bagging的方法,其中使用的算法都是决策树算法,对于这样的模型,因为具有很多棵树,而且具备了随机性,那么就可以称为随机森林 在sklearn中封 ...
- 美团店铺评价语言处理以及分类(tfidf,SVM,决策树,随机森林,Knn,ensemble)
第一篇 数据清洗与分析部分 第二篇 可视化部分, 第三篇 朴素贝叶斯文本分类 支持向量机分类 支持向量机 网格搜索 临近法 决策树 随机森林 bagging方法 import pandas as pd ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
- (数据科学学习手札26)随机森林分类器原理详解&Python与R实现
一.简介 作为集成学习中非常著名的方法,随机森林被誉为“代表集成学习技术水平的方法”,由于其简单.容易实现.计算开销小,使得它在现实任务中得到广泛使用,因为其来源于决策树和bagging,决策树我在前 ...
- 大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2)
大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2) 上一节中我们讲解了随机森林的基本概念,本节的话我们讲解随机森 ...
随机推荐
- 警告: No data sources are configured to run this SQL and provide advanced code assistance. Disable this inspection via problem menu (Alt+Enter). more... (Ctrl+F1) SQL dialect is not configured. Postgr
python3出现问题: 警告: No data sources are configured to run this SQL and provide advanced code assistance ...
- MySQL 5.6版本内存占用过高的解决办法
最近在阿里云购买了一台云服务器,因为是自己测试玩的,所以配置按最低的来了,1G内存,然后啪啪啪(指键盘声音)的安装了JDK,Tomcat,MySQL(5.6)等一系列环境,开始很爽,然后噩梦开始了: ...
- shell提取文件后缀名,并判断其是否为特定字符串
如果文件是 .css文件 或 .js文件,则进行处理. file=$1 if [ "${file##*.}"x = "css"x ]||[ "${fi ...
- go函数练习
1.编写程序,在终端输出九九乘法表. package main import ( "fmt" ) func main() { for i := 1; i <= 9; i++ ...
- Kruskal算法:最小生成树
//Kruskal算法按照边的权值从小到大查看一遍,如果不产生圈(重边等也算在内),就把当前这条表加入到生成树中. //如果判断是否产生圈.假设现在要把连接顶点u和顶点v的边e加入生成树中.如果加入之 ...
- ERROR 1045 (28000): Access denied for user 'ODBC'@'localhost' (using password:NO)
转自:http://blog.sina.com.cn/s/blog_586a1f3e01000b82.html 刚使用mysql, 就老是碰到这个问题,真是郁闷, 终于找到原因.. C:\Progra ...
- wireshark数据包分析
最近有不少同事开始学习Wireshark,他们遇到的第一个困难就是理解不了主界面上的提示信息,于是跑来问我.问的人多了,我也总结成一篇文章,希望对大家有所帮助.Wireshark的提示可是其最有价值之 ...
- 解决virtualbox与mac文件拖拽问题
apt-get purge virtualbox-guest-x11apt-get autoremove --purgerebootapt-get updateapt-get dist-upgrade ...
- 打包pyinstaller
安装:pip3 install pyinstaller 了解几个常用命令 参数 用处 -F 将程序打包成一个文件 -w 去除黑框 -i 添加程序图标 我们将需要打包的test.py文件放到桌面上,之后 ...
- luogu P4074 [WC2013]糖果公园
传送门 这种题显然要用树上莫队 何为树上莫队?就是在树上跑莫队算法就是先把树分块,然后把询问离线,按照左端点所在块为第一关键字,右端点所在块为第二关键字,时间戳(如果有修改操作)为第三关键字排序,然后 ...