递归与尾递归(C语言)【转】
作者:archimedes
在计算机科学领域中,递归式通过递归函数来实现的。程序调用自身的编程技巧称为递归( recursion)。
一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。递归的能力在于用有限的语句来定义对象的无限集合。
一般来说,递归需要有:边界条件、递归前进段和递归返回段。
当边界条件不满足时,递归前进;当边界条件满足时,递归返回。
注意:
(1) 递归就是在过程或函数里调用自身;
(2) 在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。
本文地址:http://www.cnblogs.com/archimedes/p/rescuvie-tailrescuvie.html,转载请注明源地址。
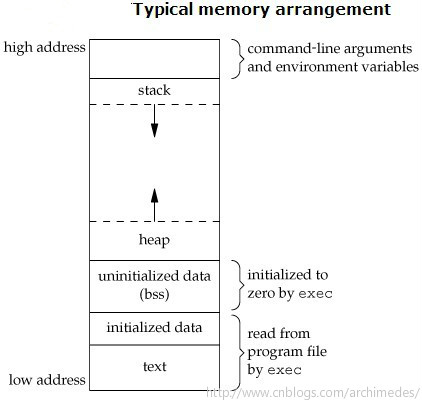
c程序在虚拟内存中的地址从低地址到高地址的顺序依次是.text段(代码区)、.rodata段(常量区)、.data段(已初始化的全局变量区)、.bss段(未初始化的全局变量区)、堆、动态库映射区、栈、内核区(用户态代码不可访问)
基本递归
问题:计算n!
数学上的计算公式为:n!=n×(n-1)×(n-2)……2×1
使用递归的方式,可以定义为:

以递归的方式计算4!
F(4)=4×F(3) 递归阶段
F(3)=3×F(2)
F(2)=2×F(1)
F(1)=1 终止条件
F(2)=(2)×(1) 回归阶段
F(3)=(3)×(2)
F(4)=(4)×(6)
24 递归完成
以递归方式实现阶乘函数的实现:
int fact(int n) {
if(n < 0)
return 0;
else if (n == 0 || n == 1)
return 1;
else
return n * fact(n - 1);
}
下面来详细分析递归的工作原理
先看看C语言中函数的执行方式,需要了解一些关于C程序在内存中的组织方式:
BSS段:(bss segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
数据段 :数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
代码段: 代码段(code segment/text segment)通常是指用来存放 程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读 , 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量 ,例如字符串常量等。程序段为程序代码在内存中的映射.一个程序可以在内存中多有个副本.
堆(heap) :堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc/free等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张)/释放的内存从堆中被剔除(堆被缩减)
栈(stack) :栈又称堆栈, 存放程序的局部变量(但不包括static声明的变量, static 意味着 在数据段中存放变量)。除此以外,在函数被调用时,栈用来传递参数和返回值。由于栈的后进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
堆的增长方向为从低地址到高地址向上增长,而栈的增长方向刚好相反(实际情况与CPU的体系结构有关)
当C程序中调用了一个函数时,栈中会分配一块空间来保存与这个调用相关的信息,每一个调用都被当作是活跃的。栈上的那块存储空间称为活跃记录或者栈帧
栈帧由5个区域组成:输入参数、返回值空间、计算表达式时用到的临时存储空间、函数调用时保存的状态信息以及输出参数,参见下图:
可以使用下面的程序来检验:
#include <stdio.h>
int g1=0, g2=0, g3=0;
int max(int i)
{
int m1 = 0, m2, m3 = 0, *p_max;
static n1_max = 0, n2_max, n3_max = 0;
p_max = (int*)malloc(10);
printf("打印max程序地址\n");
printf("in max: 0x%08x\n\n",max);
printf("打印max传入参数地址\n");
printf("in max: 0x%08x\n\n",&i);
printf("打印max函数中静态变量地址\n");
printf("0x%08x\n",&n1_max); //打印各本地变量的内存地址
printf("0x%08x\n",&n2_max);
printf("0x%08x\n\n",&n3_max);
printf("打印max函数中局部变量地址\n");
printf("0x%08x\n",&m1); //打印各本地变量的内存地址
printf("0x%08x\n",&m2);
printf("0x%08x\n\n",&m3);
printf("打印max函数中malloc分配地址\n");
printf("0x%08x\n\n",p_max); //打印各本地变量的内存地址
if(i) return 1;
else return 0;
}
int main(int argc, char **argv)
{
static int s1=0, s2, s3=0;
int v1=0, v2, v3=0;
int *p;
p = (int*)malloc(10);
printf("打印各全局变量(已初始化)的内存地址\n");
printf("0x%08x\n",&g1); //打印各全局变量的内存地址
printf("0x%08x\n",&g2);
printf("0x%08x\n\n",&g3);
printf("======================\n");
printf("打印程序初始程序main地址\n");
printf("main: 0x%08x\n\n", main);
printf("打印主参地址\n");
printf("argv: 0x%08x\n\n",argv);
printf("打印各静态变量的内存地址\n");
printf("0x%08x\n",&s1); //打印各静态变量的内存地址
printf("0x%08x\n",&s2);
printf("0x%08x\n\n",&s3);
printf("打印各局部变量的内存地址\n");
printf("0x%08x\n",&v1); //打印各本地变量的内存地址
printf("0x%08x\n",&v2);
printf("0x%08x\n\n",&v3);
printf("打印malloc分配的堆地址\n");
printf("malloc: 0x%08x\n\n",p);
printf("======================\n");
max(v1);
printf("======================\n");
printf("打印子函数起始地址\n");
printf("max: 0x%08x\n\n",max);
return 0;
}
栈是用来存储函数调用信息的绝好方案,然而栈也有一些缺点:
栈维护了每个函数调用的信息直到函数返回后才释放,这需要占用相当大的空间,尤其是在程序中使用了许多的递归调用的情况下。除此之外,因为有大量的信息需要保存和恢复,因此生成和销毁活跃记录需要消耗一定的时间。我们需要考虑采用迭代的方案。幸运的是我们可以采用一种称为尾递归的特殊递归方式来避免前面提到的这些缺点。
尾递归
定义
如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的。当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归。尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码。
原理
当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。虽然编译器能够优化尾递归造成的栈溢出问题,但是在编程中,我们还是应该尽量避免尾递归的出现,因为所有的尾递归都是可以用简单的goto循环替代的。
实例
为了理解尾递归是如何工作的,让我们再次以递归的形式计算阶乘。首先,这可以很容易让我们理解为什么之前所定义的递归不是尾递归。回忆之前对计算n!的定义:在每个活跃期计算n倍的(n-1)!的值,让n=n-1并持续这个过程直到n=1为止。这种定义不是尾递归的,因为每个活跃期的返回值都依赖于用n乘以下一个活跃期的返回值,因此每次调用产生的栈帧将不得不保存在栈上直到下一个子调用的返回值确定。现在让我们考虑以尾递归的形式来定义计算n!的过程。
这种定义还需要接受第二个参数a,除此之外并没有太大区别。a(初始化为1)维护递归层次的深度。这就让我们避免了每次还需要将返回值再乘以n。然而,在每次递归调用中,令a=na并且n=n-1。继续递归调用,直到n=1,这满足结束条件,此时直接返回a即可。
代码实例给出了一个C函数facttail,它接受一个整数n并以尾递归的形式计算n!。这个函数还接受一个参数a,a的初始值为1。facttail使用a来维护递归层次的深度,除此之外它和fact很相似。读者可以注意一下函数的具体实现和尾递归定义的相似之处。
int facttail(int n, int a)
{
if (n < 0)
return 0;
else if (n == 0)
return 1;
else if (n == 1)
return a;
else
return facttail(n - 1, n * a);
}
示例中的函数是尾递归的,因为对facttail的单次递归调用是函数返回前最后执行的一条语句。在facttail中碰巧最后一条语句也是对facttail的调用,但这并不是必需的。换句话说,在递归调用之后还可以有其他的语句执行,只是它们只能在递归调用没有执行时才可以执行。
尾递归是极其重要的,不用尾递归,函数的堆栈耗用难以估量,需要保存很多中间函数的堆栈。比如f(n, sum) = f(n-1) + value(n) + sum; 会保存n个函数调用堆栈,而使用尾递归f(n, sum) = f(n-1, sum+value(n)); 这样则只保留后一个函数堆栈即可,之前的可优化删去。
也许在C语言中有很多的特例,但编程语言不只有C语言,在函数式语言Erlang中(亦是栈语言),如果想要保持语言的高并发特性,就必须用尾递归来替代传统的递归。
递归与尾递归(C语言)【转】的更多相关文章
- 递归与尾递归(C语言)
原文:递归与尾递归(C语言)[转] 作者:archimedes 出处:http://www.cnblogs.com/archimedes/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留 ...
- 递归、尾递归和使用Stream延迟计算优化尾递归
我们在学数据结构的时候必然会接触栈(Stack),而栈有一个重要的应用是在程序设计语言中实现递归.递归用途十分广泛,比如我们常见的阶乘,如下代码: 1234 public static int (in ...
- JAVA中使用递归和尾递归实现1000的阶乘的比较
在JAVA中求阶乘首先遇到的问题就是结果溢出,不管是使用int还是long,double都无法表示1000!这么大的天文数字,这里暂且用BigInteger解决这个问题! 下面是使用递归和尾递归分别计 ...
- day13-Python运维开发基础(递归与尾递归)
递归与尾递归 # ### 递归函数 """ 递归函数: 自己调用自己的函数 递:去 归:回 有去有回是递归 """ # 简单递归 def d ...
- 归并排序,递归法,C语言实现。
利用归并排序法对序列排序的示意图(递归法): 一.算法分析:利用递归的分治方法:1.将原序列细分,直到成为单个元素:2.在将分割后的序列一层一层地按顺序合并,完成排序.细分通过不断深入递归完成,合并通 ...
- 【Python学习之四】递归与尾递归
看完廖雪峰老师的教程,感觉尾递归函数是一个相对难点.于是复习一下,思考了一下,发表一些见解,记录一下. 1.递归函数 在函数内部,可以调用其他函数.如果一个函数在内部调用自身本身,这个函数就是递归函数 ...
- Java 递归、尾递归、非递归、栈 处理 三角数问题
import java.io.BufferedReader; import java.io.InputStreamReader; //1,3,6,10,15...n 三角数 /* * # 1 * ## ...
- Java 递归、尾递归、非递归 处理阶乘问题
n!=n*(n-1)! import java.io.BufferedReader; import java.io.InputStreamReader; /** * n的阶乘,即n! (n*(n-1) ...
- Python实现斐波那契递归和尾递归计算
##斐波那契递归测试 def fibonacciRecursive(deepth): if deepth == 1: return 1 elif deepth == 2: return 1 else: ...
随机推荐
- SQLite 学习笔记(一)
(1)创建数据库 在命令行中切换到sqlite.exe所在的文件夹 在命令中键入sqlite3 test.db;即可创建了一个名为test.db的数据库 由于此时的数据库中没有任何表及 ...
- forEach、for、$.each()跳出循环比较
无论工作上或是学习上,用过的知识点总是容易忘记,于是略作记录,方便你我他. 说起跳出循环,第一时间想起的是 break \ continue,这是经典的for循环. 1.for 循环 先上例子,思考输 ...
- 在kubernetes中运行单节点有状态MySQL应用
Deploy MySQL https://kubernetes.io/docs/tasks/run-application/run-single-instance-stateful-applicati ...
- Linux命令之grep
grep命令 用处:文本搜索工具 用法:grep + ‘查找关键字的名字’ + 文件名 示例: 还在profile里面查找then 干净利落强大,有关then的信息显示
- mysql -- 逻辑语句
1.if语句 delimiter \\ create procedure p1() begin declare i ; then ; elseif i = then ; else ; end if; ...
- mysql 缓存机制
了解mysql缓存吗(顺丰) mysql缓存机制就是缓存sql 文本及缓存结果,用KV形式保存再服务器内存中,如果运行相同的sql,服务器直接从缓存中去获取结果,不需要在再去解析.优化.执行sql. ...
- POJ - 1426 Find The Multiple(搜索+数论)
转载自:優YoU http://user.qzone.qq.com/289065406/blog/1303946967 以下内容属于以上这位dalao http://poj.org/problem? ...
- mysql运行警告
警告信息: Fri Oct 28 09:33:35 CST 2016 WARN: Establishing SSL connection without server's identity verif ...
- 15. Spring boot CRUD
一.列表页 templates/emp/list.html 0.侧边栏链接: <li class="nav-item"> <a class="nav-l ...
- java Future模式的使用
一.Future模式的使用. Future模式简述 传统单线程环境下,调用函数是同步的,必须等待程序返回结果后,才可进行其他处理. Futrue模式下,调用方式改为异步. Futrue模式的核心在于: ...