【Udacity并行计算课程笔记】- Lesson 2 The GPU Hardware and Parallel Communication Patterns
本小节笔记大纲:
- 1.Communication patterns
- gather,scatter,stencil,transpose
- 2.GPU hardware & Programming Model
- SMs,threads,blocks,ordering
- Synchronization
- Memory model: local, shared, global
- Atomic Operation
- 3.Efficient GPU Programming
- Access memory faster
- coalescing global memory
- use faster memory
- Avoid thread divergence
- Access memory faster
一、Communication Patterns
1.Patterns
- Map

map很好理解,其实就是映射,也就是输入和输出一一对应,一个萝卜一个坑
- Gather

Gather中文名为收集,是将若干个输入数据经过计算后得到一个输出值,如图左示。很典型的应用就是比如说对于一个图像,我们需要每一个像素值是其四周像素的平均值。
- Scatter
scatter的特点是每个线程一次会向内存输出多个值,也可能多个线程向一个内存输出值。

- Stencil
Stencil表示模板的意思,所以也就是计算的时候用模子来选择输入数据,看下图就清楚了

- Transpose
其实就是转置啦~

具体应用实例如下:

在C语言中,加入我们定义了如上图示的一个结构体,包含float和int两种变量,然后我们又定义了一个该结构体的变量数组,一般来说其在内存中是像上面那样排列的,强迫症看起来是不是不舒服,而且这种排列方式比较浪费空间,所以通过转置后形成下面的排列方式后既美观又使运算加速了,岂不美哉?
2.练习题

- 第一个很简单就是map,不仔细解释了
- 第二个个表达式我之前脑袋一热就选了C。。但是要注意,scatter的特点是每个线程一次会向内存输出多个值,这显然不符合该特点,而应该是Transpose。
- 第三个就是scatter了,原因如上
- 最后一个很容易选stencil,但是你要注意if条件语句的限制,所以应该是Gather。
3.总结神图

二、GPU Hardware
1.问题导向
- 线程是如何有效地一致访问内存
- 子话题:如何利用数据重用
- 线程如何通过共享内存通信部分结果
2.硬件组成

如图示,GPU由若干个SM(Stream Multiprocessor流多处理器)组成,而每个SM又包含若干个SP(教材上是Stream Processor流处理器,改视频中是simple processor),anyway...开心就好,管他叫什么名字~
GPU的作用是负责分配线程块在硬件SM上运行,所有SM都以并行独立的方式运行。
下面做一下题目吧:

解析:
- 1正确.一个线程块包含许多线程
- 2正确.一个SM可能会运行多个多个线程块
- 3错误,因为一个线程块无法在一个以上的SM上运行
- 4正确,在一个线程块上所有线程有可能配合起来解决某个子问题
- 5错误,一个SM上可能有多个线程块,但是根据定义,线程和不同的线程块不应该存在协作关系。
3.程序员与GPU分工
另外需要注意的是程序员负责定义线程块,而GPU则负责管理硬件,因此程序员不能指定线程块的执行顺序,也不能指定线程块在某一特定的SM上运行。
这样设计的好处如下:
- 硬件可以运行的更加有效率
- 运行切换不需要等待,一旦一个线程块运行完毕,SM可以自动的将另一个线程块加载进来
- 最大的优势:可扩展性,因为可以自动分配硬件资源,所以向下到单个SM,上到超级计算机的大量SM,均可以很好的适应。
有如上好处的同时,自然也就有局限性:
- 对于哪个块在哪个SM上运行无法进行任何假设
- 无法获得块之间的明确的通信
4.GPU Memory Model

如图示
- 每个线程都有它自己的本地内存(local memory)
- 线程块有一个共享内存(shared memory),块中所有线程都可以访问该内存中的数据
- GPU中的全局内存(global memory) 是所有线程块中的线程都能访问的内存,也是CPU进行数据传递的地方。
访问速度:
local memory > shared memory > global
例题:

解析:
s,t,u是本地内存中的变量,所以t=s最先运行,同理可以排除其他代码运行顺序。
注意:这只是为了说明访问速度出的例题,实际情况中,编译器可能会做出相应的调整来达到我们的目的
5.Sychronization
说道线程,很自然我们就需要考虑同步。GPU中的同步有如下几种:
Barrier(屏障)
顾名思义,就是所有线程运行到这个点都需要停下来。

如图示,红色、蓝色、绿色代表的线程先后到达barrier这个时间点后都停下来进行同步操作,完成之后线程的执行顺序是不一定的,可能如图示蓝色线程先执行,绿色,红色紧随其后。
另外其实还有一种隐式的barrier,比如说先后启动kernel A和kernel B,一般来说kernel B执行之前kernel A肯定是执行完毕了的。
说了这么多来做下题吧~233
题目:如下图示,现在需要实现一个数组前移的操作,即后面一个往前面挪,共享数组大小是128,问为实现这个功能,需要设置几次同步操作(或者说需要设置几个barrier?)

解析:
最开始的时候没想明白,写了127,128,但是都不对。后来听解释才明白。前移操作可以分为三步:
- 为每个数组元素赋值,即
array[idx] = threadIdx.x;
__syncthreads(); # 128个线程都执行完赋值语句后才能进行下一步
- 读取后面一个元素的值,存在临时变量里
int temp = array[idx+1];
__syncthreads();
- 将后一元素的值往前移
array[idx] = temp;
__syncthreads();

6.Atomic Memory Operation
在cuda编程中经常会碰到这样的情况,即大量的线程同时都需要对某一个内存地址进行读写操作,很自然这会发生冲突,如下图示:

下面是发生冲突的具体的代码示例:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#define NUM_THREADS 10000
#define ARRAY_SIZE 10
#define BLOCK_WIDTH 100
void printDevice();
__global__ void increment_naive(int *g) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
i = i % ARRAY_SIZE;
g[i] = g[i] + 1;
}
int main(int argc, char **argv){
printDevice();
printf("\n");
int h_array[ARRAY_SIZE];
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(int);
int *d_array;
// 分配内存
cudaMalloc((void **) &d_array, ARRAY_BYTES);
cudaMemset((void *) d_array, 0, ARRAY_BYTES);
increment_naive<<<NUM_THREADS/BLOCK_WIDTH, BLOCK_WIDTH>>>(d_array);
cudaMemcpy(h_array, d_array, ARRAY_BYTES, cudaMemcpyDeviceToHost);
for(int i=0; i<ARRAY_SIZE; i++){
printf("%d:%d\n",i,h_array[i]);
}
// 释放内存
cudaFree(d_array);
getchar();
//CUDA_SAFE_CALL(cudaGetDeviceCount(&deviceCount));
return 0;
}
运行结果:(每次运行的结果是不确定的)


这里就需要引入原子操作,只需要将读写函数进行如下修改
__global__ void increment_atomicNaive(int *g) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
i = i % ARRAY_SIZE;
atomicAdd(&g[i], 1);
}
运行结果:
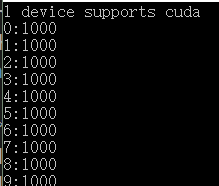
使用原子操作也是有一定限制的,如下:
- 只能使用一些特定的运算(如加、减、最小值、异或等运算,但是取模,求幂等运算则不行)和数据类型(一般是整型int)
- 每个线程块里的不同线程以及线程块本身将以不定的顺序运行,我们在内存上用原子进行的运算顺序也是不定的。
例如下面的计算表达式的记过会不一样:
\((a+b+c)\) 和 \(a+(b+c)\),其中\(a=1,b=10^{99},c=-10^{99})\) - 虽然顺序不确定,但是要知道的是GPU还是会强制每个线程轮流访问内存,这把不同线程对内存的访问串行化
提高CUDA编程效率策略
高运算密度(high arithmetic intensity)
\(\frac{math}{memory}\)
前面提到了很多优化策略是集中在memory上的,把数据尽可能放到更快地内存上去,其中内存速度是
local > share > global
- 避免线程发散(avoid thread divergence)

如图是线程发散的主要场景,即if else语句,上图右边非常生动的展现了线程发散的情形,可以看到各个线程在碰到if条件句后开始发散,最后聚合,但是最后各个线程之间的编号还是保持原来的不变的,这就是线程发散。
下面举一个更加极端的例子,就是循环语句,如下图示:

可以看到有蓝、红、绿、紫四个线程同时运行,蓝线程只循环了一次,其他线程循环次数都多于蓝线程,当蓝线程退出循环后就不得不一直等着其他线程,上图左下角的示意图可以很直观的看到这大大降低了运行效率,这也是为什么我们需要避免线程发散。
Summary

【Udacity并行计算课程笔记】- Lesson 2 The GPU Hardware and Parallel Communication Patterns的更多相关文章
- Udacity并行计算课程笔记-The GPU Hardware and Parallel Communication Patterns
本小节笔记大纲: 1.Communication patterns gather,scatter,stencil,transpose 2.GPU hardware & Programming ...
- 【Udacity并行计算课程笔记】- Lesson 4 Fundamental GPU Algorithms (Applications of Sort and Scan)
I. Scan应用--Compact 在介绍这节之前,首先给定一个情景方便理解,就是因为某种原因我们需要从扑克牌中选出方块的牌. 更formal一点的说法如下,输入是 \(s_0,s_1,...\), ...
- 【Udacity并行计算课程笔记】- Lesson 3 Fundamental GPU Algorithms (Reduce, Scan, Histogram)
本周主要内容如下: 如何分析GPU算法的速度和效率 3个新的基本算法:归约.扫描和直方图(Reduce.Scan.Histogram) 一.评估标准 首先介绍用于评估GPU计算的两个标准: ste ...
- 【Udacity并行计算课程笔记】- lesson 1 The GPU Programming Model
一.传统的提高计算速度的方法 faster clocks (设置更快的时钟) more work over per clock cycle(每个时钟周期做更多的工作) more processors( ...
- Udacity并行计算课程笔记-The GPU Programming Model
一.传统的提高计算速度的方法 faster clocks (设置更快的时钟) more work over per clock cycle(每个时钟周期做更多的工作) more processors( ...
- udacity android 学习笔记: lesson 4 part b
udacity android 学习笔记: lesson 4 part b 作者:干货店打杂的 /titer1 /Archimedes 出处:https://code.csdn.net/titer1 ...
- udacity android 实践笔记: lesson 4 part b
udacity android 实践笔记: lesson 4 part b 作者:干货店打杂的 /titer1 /Archimedes 出处:https://code.csdn.net/titer1 ...
- udacity android 学习笔记: lesson 4 part a
udacity android 学习笔记: lesson 4 part a 作者:干货店打杂的 /titer1 /Archimedes 出处:https://code.csdn.net/titer1 ...
- udacity android 实践笔记: lesson 4 part a
udacity android 实践笔记: lesson 4 part a 作者:干货店打杂的 /titer1 /Archimedes 出处:https://code.csdn.net/titer1 ...
随机推荐
- Rsync 服务器端配置
Centos 6.3 已经自带Rsync服务 安装xinetd # yum -y install xinetd 编辑/etc/xinetd.d/rsync文件,把disable = yes修改为dis ...
- $Min\_25$筛学习笔记
\(Min\_25\)筛学习笔记 这种神仙东西不写点东西一下就忘了QAQ 资料和代码出处 资料2 资料3 打死我也不承认参考了yyb的 \(Min\_25\)筛可以干嘛?下文中未特殊说明\(P\)均指 ...
- 自学Zabbix11.1 Zabbix 配置SNMP监控
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 自学Zabbix11.1 Zabbix 配置SNMP监控 1. 概述 zabbix采集数据方式: ...
- 2018 省选 T1 一双木棋
题目描述 菲菲和牛牛在一块n 行m 列的棋盘上下棋,菲菲执黑棋先手,牛牛执白棋后手. 棋局开始时,棋盘上没有任何棋子,两人轮流在格子上落子,直到填满棋盘时结束. 落子的规则是:一个格子可以落子当且仅当 ...
- BCD码(如何转换,转换方式的证明)
1. 十进制转2421码:小于4不考虑使用最高位,从最高位向最低位依次相减. 如3=2+1,为0011:7=2+4+1,为1101 2. 十进制5211码:按照最高位,次高位,最低位,次低位的顺序依次 ...
- SQL 运算符
运算符是一个保留字或字符,主要用于连接WHERE后面的条件. 一.算数运算符 运算符 描述 + 加法 把运算符两边的值相加 - 减法 左操作数减去右操作数 * 乘法 把运算符两边的值相乘 / 除法 左 ...
- DOM表格操作
注意:就算代码中不包含<tbody>标签,浏览器解析时也可能会自动添加,因此需要注意子元素的选择 表格操作用到的属性: 1.tHead 2.tBodies 3.tFoot 更为细致的有: ...
- #define 多行多语句
#define DEBUG_ENABLE 1 #if DEBUG_ENABLE > 0 #define DEBUG_PORT UART_PORT2 #define DBG_BUF_LEN 512 ...
- Java需要强制捕获的异常
Java编译器要求我们强制捕获Excetion,但不包括RuntimeException 不强制要求捕获Error和RuntimeException是因为,这两种异常我们程序一般无能为力,而其他Exc ...
- Kafka集群优化篇-调整broker的堆内存(heap)案例实操
Kafka集群优化篇-调整broker的堆内存(heap)案例实操 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看kafka集群的broker的堆内存使用情况 1>. ...