『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍
一、论文介绍
读论文系列:Object Detection ECCV2016 SSD
一句话概括:SSD就是关于类别的多尺度RPN网络
基本思路:
- 基础网络后接多层feature map
- 多层feature map分别对应不同尺度的固定anchor
- 回归所有anchor对应的class和bounding box
网络结构简介
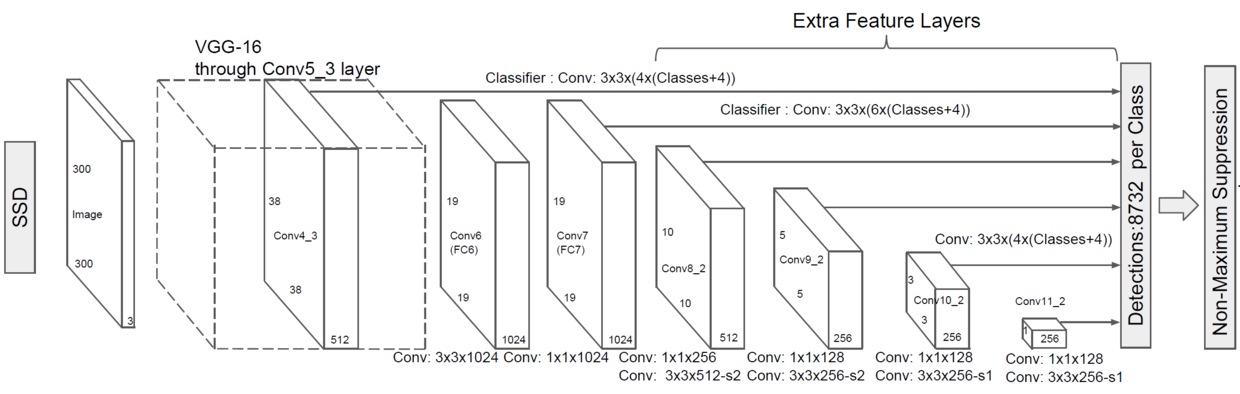
输入:300x300
经过VGG-16(只到conv4_3这一层)
经过几层卷积,得到多层尺寸逐渐减小的feature map
每层feature map分别做3x3卷积,每个feature map cell(又称slide window)对应k个类别和4个bounding box offset,同时对应原图中6(或4)个anchor(又称default box)
- 38x38, 最后3x3, 1x1三个feature map的每个feature map cell只对应4个anchor,分别为宽高比: 1:1两种,1:2, 2:1两种,因此总共有 38 x 38 x 4 + 19 x 19 x 6 + 10 x 10 x 6 + 5 x 5 x 6 + 3 x 3 x 4 + 1 x 1 x 4 = 8732 个anchor
- 其他feature map的feature map cell对应6个anchor,分别为宽高比: 1:1两种,1:2, 2:1两种,1:3, 3:1两种
- 每层的feature map cell对应的anchor计算方法如下
- 位置:假设当前feature map cell是位于第i行,第j列,则anchor的中心为(i+0.5,j+0.5),注意,这个值需要处理放缩到0-1之间作为相对位置
- 缩放因子:
其中s_min为0.2,s_max为0.9,m为添加的feature map的层数,缩放因子就是为不同feature map选择不同的大小的anchor,要求小的feature map对应的anchor尽量大,因为越小的feature map,其feature map cell的感受野就越大
anchor宽高:
其中,a_r∈{1,2,3,1/2,1/3},可以理解为在缩放因子选择好anchor尺寸后,用a_r来控制anchor形状,从而得到多尺度的各种anchor,当a_r=1时,增加一种s_k=sqrt(s_{k-1}*s_{k+1}),于是每个feature map cell通常对应6种anchor。
网络的训练目标就是,回归各个anchor对应的类别和位置
实际送入分类/回归器的样本选择问题
正样本 选择与bounding box jaccard overlap(两张图的交集/并集)大于0.5的anchor作为正样本
样本比例 Hard negative mining:由于负样本很多,需要去掉一部分负样本,先整图经过网络,根据每个anchor的最高类置信度进行排序,选择置信度靠前的样本,这样筛选出来的负样本也会更难识别,并且最终正负样本比例大概是1:3
Loss
还是一如既往的location loss + classification loss,并为location loss添加了系数α(然而实际上α=1)进行平衡,并在batch维度进行平均
- x是x_{ij}^{p}的集合x_{ij}^{p}={1,0},用于判断第i个anchor是否是第j个bounding box上的p类样本
- c是c_{i}^{p}的集合,c_{i}^{p}是第i个anchor预测为第p类的概率
- l是预测的bounding box集合
- g是ground true bounding box集合
其中定位loss与faster rcnn相同
这个式子里的k不是很明确,其实想表达不算背景0类的意思,且前景类只为match的类算location loss
分类loss就是很常用的softmax交叉熵了
相关内容各篇代码介绍部分还会涉及,可加深理解:
『TensorFlow』SSD源码学习_其二:基于VGG的SSD网络前向架构
『TensorFlow』SSD源码学习_其四:数据介绍及TFR文件生成
『TensorFlow』SSD源码学习_其五:TFR数据读取&数据预处理
二、开源代码文档
原项目地址:SSD-Tensorflow
Fork版本项目地址:SSD
根据README的介绍,该项目收到了tf-slim项目中包含了多种经典网络结构(分类用)的启发,使用了模块化的编程思想,可以替换检查网络的结构,其模块组织如下:
- datasets: 数据及接口,interface to popular datasets (Pascal VOC, COCO, ...) and scripts to convert the former to TF-Records;
- networks: 网络结构定义,definition of SSD networks, and common encoding and decoding methods (we refer to the paper on this precise topic);
- pre-processing: 预处理和数据增强,pre-processing and data augmentation routines, inspired by original VGG and Inception implementations.
项目给提供了两个已训练的VGG网络,输入分别为300和512。
除此之外,还有一个迷你的SSD展示ipynb脚本,可以快读演示预测ssd_notebook。
脚本tf_convert_data.py
将数据转换为一组TF-Record文件,调用示意如下:
DATASET_DIR=./VOC2007/test/
OUTPUT_DIR=./tfrecords
python tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=${DATASET_DIR} \
--output_name=voc_2007_train \
--output_dir=${OUTPUT_DIR}
脚本caffe_to_tensorflow.py
可以把caffe的模型转换为checkpoints,供程序使用:
CAFFE_MODEL=./ckpts/SSD_300x300_ft_VOC0712/VGG_VOC0712_SSD_300x300_ft_iter_120000.caffemodel
python caffe_to_tensorflow.py \
--model_name=ssd_300_vgg \
--num_classes=21 \
--caffemodel_path=${CAFFE_MODEL}
脚本train_ssd_network.py
用于训练模型,
- 可以自定义训练的明细(dataset, optimiser, hyper-parameters, model, ...)
- 可以载入ckeckpoints后fine-tune
使用VGG-300模型进行微调的示意如下,
DATASET_DIR=./tfrecords
TRAIN_DIR=./logs/
CHECKPOINT_PATH=./checkpoints/ssd_300_vgg.ckpt
python train_ssd_network.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2012 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=${CHECKPOINT_PATH} \
--save_summaries_secs=60 \
--save_interval_secs=600 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.001 \
--batch_size=32
脚本eval_ssd_network.py
使用checkpoint文件来检验训练效果,调用示意如下:
EVAL_DIR=./logs/
CHECKPOINT_PATH=./checkpoints/VGG_VOC0712_SSD_300x300_ft_iter_120000.ckpt
python eval_ssd_network.py \
--eval_dir=${EVAL_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=test \
--model_name=ssd_300_vgg \
--checkpoint_path=${CHECKPOINT_PATH} \
--batch_size=1
这个脚本可以在训练脚本运行的同时运行,动态的监测当前训练效果,此时命令如下:
EVAL_DIR=${TRAIN_DIR}/eval
python eval_ssd_network.py \
--eval_dir=${EVAL_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=test \
--model_name=ssd_300_vgg \
--checkpoint_path=${TRAIN_DIR} \
--wait_for_checkpoints=True \
--batch_size=1 \
--max_num_batches=500
而且文档描述的很不简单,eval脚本可以监测到GPU空闲,
one can pass to training and validation scripts a GPU memory upper limit such that both can run in parallel on the same device. If some GPU memory is available for the evaluation script, the former can be run in parallel as follows:
脚本ssd_vgg_preprocessing.py、ssd_vgg_300/512.py
、ssd_vgg_300/512.pyone may also want to experiment with data augmentation parameters (random cropping, resolution, ...) in ssd_vgg_preprocessing.py or/and network parameters (feature layers, anchors boxes, ...) in ssd_vgg_300/512.py
预训练分类网络扩展为SSD
可以尝试构建一个基于标准体系结构的新的SSD模型(VGG, ResNet, Inception,…),并在其之上设置multibox层(使用特定的锚点,比率,…)。为此,还可以只加载原始架构的权重,并随机初始化网络的其余部分,从而对网络进行微调。例如,在vgg16架构的情况下,可以将一个新模型训练如下:
DATASET_DIR=./tfrecords
TRAIN_DIR=./log/
CHECKPOINT_PATH=./checkpoints/vgg_16.ckpt
python train_ssd_network.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=${CHECKPOINT_PATH} \
--checkpoint_model_scope=vgg_16 \
--checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--save_summaries_secs=60 \
--save_interval_secs=600 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.001 \
--learning_rate_decay_factor=0.94 \
--batch_size=32
在前一个命令中,训练脚本随机初始化checkpoint_exclusive de_scope的权重,并从检查点文件vgg_16加载。ckpt网络的剩余部分。注意,我们还指定了trainable_scope参数,以便此时只训练新的SSD组件,并保持VGG网络的其余部分不变。一旦网络收敛到良好的第一个结果(例如~0.5 mAP),就可以对整个网络进行如下微调:
DATASET_DIR=./tfrecords
TRAIN_DIR=./log_finetune/
CHECKPOINT_PATH=./log/model.ckpt-N
python train_ssd_network.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=${CHECKPOINT_PATH} \
--checkpoint_model_scope=vgg_16 \
--save_summaries_secs=60 \
--save_interval_secs=600 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.00001 \
--learning_rate_decay_factor=0.94 \
--batch_size=32
在TF-Slim模型页面上可以找到许多流行的深度架构的预先训练权重。
『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍的更多相关文章
- 『TensorFlow』SSD源码学习_其五:TFR数据读取&数据预处理
Fork版本项目地址:SSD 一.TFR数据读取 创建slim.dataset.Dataset对象 在train_ssd_network.py获取数据操作如下,首先需要slim.dataset.Dat ...
- 『TensorFlow』SSD源码学习_其四:数据介绍及TFR文件生成
Fork版本项目地址:SSD 一.数据格式介绍 数据文件夹命名为VOC2012,内部有5个子文件夹,如下, 我们的检测任务中使用JPEGImages文件夹和Annotations文件夹. JPEGIm ...
- 『TensorFlow』SSD源码学习_其二:基于VGG的SSD网络前向架构
Fork版本项目地址:SSD 参考自集智专栏 一.SSD基础 在分类器基础之上想要识别物体,实质就是 用分类器扫描整张图像,定位特征位置 .这里的关键就是用什么算法扫描,比如可以将图片分成若干网格,用 ...
- 『TensorFlow』SSD源码学习_其七:损失函数
Fork版本项目地址:SSD 一.损失函数介绍 SSD损失函数分为两个部分:对应搜索框的位置loss(loc)和类别置信度loss(conf).(搜索框指网络生成的网格) 详细的说明如下: i指代搜索 ...
- 『TensorFlow』SSD源码学习_其八:网络训练
Fork版本项目地址:SSD 作者使用了分布式训练的写法,这使得训练部分代码异常臃肿,我给出了部分注释.我对于多机分布式并不很熟,而且不是重点,所以不过多介绍,简单的给出一点训练中作者的优化手段,包含 ...
- 『TensorFlow』SSD源码学习_其六:标签整理
Fork版本项目地址:SSD 一.输入标签生成 在数据预处理之后,图片.类别.真实框格式较为原始,不能够直接作为损失函数的输入标签(ssd向前网络只需要图像就行,这里的处理主要需要满足loss的计算) ...
- 『TensorFlow』SSD源码学习_其三:锚框生成
Fork版本项目地址:SSD 上一节中我们定义了vgg_300的网络结构,实际使用中还需要匹配SSD另一关键组件:被选取特征层的搜索网格.在项目中,vgg_300网络和网格生成都被统一进一个class ...
- 是否应该学习qt源码(碰到问题的时候,或者文档对函数描述不清楚的时候,可以看一下)
是否应该学习qt源码 如果你想调用某个函数,但是文档并没有清晰描述这个函数的功能的时候,你就需要去阅读源码,看看Qt究竟是怎么实现的.比如用QNetworkAccessManager发送一个QHttp ...
- nginx源码学习_源码结构
nginx的优秀除了体现在程序结构以及代码风格上,nginx的源码组织也同样简洁明了,目录结构层次结构清晰,值得我们去学习.nginx的源码目录与nginx的模块化以及功能的划分是紧密结合,这也使得我 ...
随机推荐
- FancyBox的使用技巧 (汇总)
http://note.youdao.com/share/?id=1c8373249f523529a6b6dcde60777400&type=note#/
- oracle 之 伪列 rownum 和 rowid的用法与区别
rownum的用法 select rownum,empno,ename,job from emp where rownum<6 可以得到小于6的值数据 select rownum,empno, ...
- js变量按照存储方式区分,有哪些类型,并表述其特点
// 值类型 拷贝形式 不像引用类型是指针指向,共用空间 值类型有 undefined string number Boolean var a = 100; var b = a; var a = 20 ...
- pyqt笔记2 布局管理
https://zhuanlan.zhihu.com/p/28559136 绝对布局 相关方法setGeometry().move() 箱式布局 QHBoxLayout和QVBoxLayout是基本的 ...
- Idea中配置Tomcat
配置步骤 在idea项目左上角选择‘Edit Configurations’ 2. 配置server 3. 配置项目 4. 配置成功后就可以在项目下面看到tomcat了 运行Tomcat遇到权限问题: ...
- Python 学习笔记 多进程 multiprocessing--转载
本文链接地址 http://quqiuzhu.com/2016/python-multiprocessing/ Python 解释器有一个全局解释器锁(PIL),导致每个 Python 进程中最多同时 ...
- 【Python】【容器 | 迭代对象 | 迭代器 | 生成器 | 生成器表达式 | 协程 | 期物 | 任务】
Python 的 asyncio 类似于 C++ 的 Boost.Asio. 所谓「异步 IO」,就是你发起一个 IO 操作,却不用等它结束,你可以继续做其他事情,当它结束时,你会得到通知. Asyn ...
- 真刀实战地搭建React+Webpack+Express搭建一个简易聊天室
一.前面bb两句 因为自惭(自残)webpack配置还不够熟悉,想折腾着做一个小实例熟悉.想着七夕快到了,做一个聊天室自己和自己聊天吧哈哈.好了,可以停止bb了,说一下干货. 二. 这个项目能学到啥? ...
- _event_team
EventId 事件ID TeamId 事件玩家分组,仅传送(0为联盟 1为部落)对线(防守为1,进攻为2),自定义阵营(_faction表自定义阵营ID),公会(公会guid) TeamName 事 ...
- [原][粒子特效][spark]事件action
深入浅出spark粒子特效连接:https://www.cnblogs.com/lyggqm/p/9956344.html group调用action的地方: 可以看到使用action的可以是出生一次 ...