Scrapy学习笔记(5)-CrawlSpider+sqlalchemy实战
基础知识
实践
有了前面的知识和基本概念之后,下面就是写代码了,本文目标是使用CrawlSpider和sqlalchemy实现如下网站中的高匿代理IP采集入库http://ip84.com,新建项目和spider的过程我就不写了,不会的可以参考之前的文章,本次项目名称为”ip_proxy_pool”,顾名思义就是IP代理池,学习爬虫的应该都知道,不过本文仅仅是采集特定网站公开的代理IP,维护一个IP代理池那是后话,OK,Talk is cheap,Show you the code!
项目结构如上图所示,model目录存放数据库表的映射文件,proxy.py是目标表的映射文件,rules.py以及和model目录同级的__init__.py文件本文中暂时用不到先不管,其他文件都是本次实践需要用到的。
1.items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class IpProxyPoolItem(scrapy.Item): ip_port = scrapy.Field()
type = scrapy.Field()
level = scrapy.Field()
country = scrapy.Field()
location = scrapy.Field()
speed = scrapy.Field()
source = scrapy.Field()
2.model目录下的__init__.py
# -*- coding: utf-8 -*-
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker # 创建对象的基类:
Base = declarative_base() # 初始化数据库连接:
engine = create_engine('mysql+mysqldb://root:123456@localhost:3306/scrapy?charset=utf8') #返回数据库会话
def loadSession():
Session = sessionmaker(bind=engine)
session = Session()
return session
3.proxy.py(数据库表proxies的映射文件)
# -*- coding: utf-8 -*-
from sqlalchemy import Column,String,Integer,DateTime from . import Base
import datetime
class Proxy(Base):
__tablename__ = 'proxies' ip_port=Column(String(30),primary_key=True,nullable=False)
type=Column(String(20),nullable=True)
level=Column(String(20),nullable=True)
location=Column(String(100),nullable=True)
speed=Column(Integer,nullable=True)
source = Column(String(500), nullable=False)
indate=Column(DateTime,nullable=False) def __init__(self,ip_port,source,type=None,level=None,location=None,speed=None):
self.ip_port=ip_port
self.type=type
self.level=level
self.location=location
self.speed=speed
self.source=source
self.indate=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
4.pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
from model import Base,engine,loadSession
from model import proxy class IpProxyPoolPipeline(object):
#搜索Base的所有子类,并在数据库中生成表
Base.metadata.create_all(engine) def process_item(self, item, spider):
a = proxy.Proxy(
ip_port=item['ip_port'],
type=item['type'],
level=item['level'],
location=item['location'],
speed=item['speed'],
source=item['source']
)
session = loadSession()
session.add(a)
session.commit()
return item
5.proxy_spider.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import IpProxyPoolItem class ProxySpiderSpider(CrawlSpider): name = 'proxy_spider'
allowed_domains = ['ip84.com']
start_urls = ['http://ip84.com/gn'] rules = (
#跟随下一页链接
Rule(LinkExtractor(restrict_xpaths="//a[@class='next_page']"),follow=True),
#对所有链接中含有"/gn/数字"的链接调用parse_item函数进行数据提取并过滤重复链接
Rule(LinkExtractor(allow=r'/gn/\d+',unique=True), callback='parse_item'),
) def parse_item(self, response):
print 'Hi, this is an item page! %s' % response.url
item=IpProxyPoolItem() for proxy in response.xpath("//table[@class='list']/tr[position()>1]"): ip=proxy.xpath("td[1]/text()").extract_first()
port=proxy.xpath("td[2]/text()").extract_first()
location1=proxy.xpath("td[3]/a[1]/text()").extract_first()
location2=proxy.xpath("td[3]/a[2]/text()").extract_first()
level=proxy.xpath("td[4]/text()").extract_first()
type = proxy.xpath("td[5]/text()").extract_first()
speed=proxy.xpath("td[6]/text()").extract_first()
item['ip_port']=(ip if ip else "")+":"+(port if port else "")
item['type']=(type if type else "")
item['level']=(level if level else "")
item['location']=(location1 if location1 else "")+" "+(location2 if location2 else "")
item['speed']=(speed if speed else "")
item['source']=response.url
return item
6.settings.py
# -*- coding: utf-8 -*- # Scrapy settings for ip_proxy_pool project BOT_NAME = 'ip_proxy_pool' SPIDER_MODULES = ['ip_proxy_pool.spiders']
NEWSPIDER_MODULE = 'ip_proxy_pool.spiders' # Obey robots.txt rules
ROBOTSTXT_OBEY = True ITEM_PIPELINES = {
'ip_proxy_pool.pipelines.IpProxyPoolPipeline': 300,
} DOWNLOAD_DELAY = 2
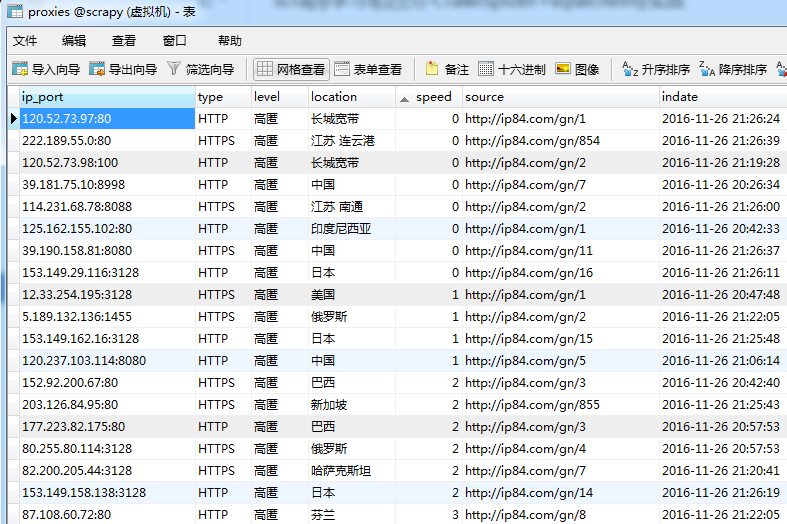
7.运行spider,查看结果
Scrapy学习笔记(5)-CrawlSpider+sqlalchemy实战的更多相关文章
- Scrapy:学习笔记(2)——Scrapy项目
Scrapy:学习笔记(2)——Scrapy项目 1.创建项目 创建一个Scrapy项目,并将其命名为“demo” scrapy startproject demo cd demo 稍等片刻后,Scr ...
- Scrapy:学习笔记(1)——XPath
Scrapy:学习笔记(1)——XPath 1.快速开始 XPath是一种可以快速在HTML文档中选择并抽取元素.属性和文本的方法. 在Chrome,打开开发者工具,可以使用$x工具函数来使用XPat ...
- scrapy 学习笔记1
最近一段时间开始研究爬虫,后续陆续更新学习笔记 爬虫,说白了就是获取一个网页的html页面,然后从里面获取你想要的东西,复杂一点的还有: 反爬技术(人家网页不让你爬,爬虫对服务器负载很大) 爬虫框架( ...
- 爱了!阿里大神最佳总结“Flutter进阶学习笔记”,理论与实战
前言 "小步快跑.快速迭代"的开发大环境下,"一套代码.多端运行"是很多开发团队的梦想,美团也一样.他们做了很多跨平台开发框架的尝试:React Native. ...
- Python--网络编程学习笔记系列01 附实战:udp聊天器
Python--网络编程学习系列笔记01 网络编程基本目标: 不同的电脑上的软件能够实现数据传输 网络编程基础知识: IP地址: 用来在网络中标记一台电脑 网络号+主机号(按网络号和主机号占位分类A ...
- Angular 4 学习笔记 从入门到实战 打造在线竞拍网站 基础知识 快速入门 个人感悟
最近搞到手了一部Angular4的视频教程,这几天正好有时间变学了一下,可以用来做一些前后端分离的网站,也可以直接去打包web app. 环境&版本信息声明 运行ng -v @angular/ ...
- Angular4.0学习笔记 从入门到实战打造在线竞拍网站学习笔记之二--路由
Angular4.0基础知识见上一篇博客 路由 简介 接下来学习路由的相关知识 本来是不准备写下去的,因为当时看视频学的时候感觉自己掌握的不错 ( 这是一个灰常不好的想法 ) ,过了一段时间才发现An ...
- scrapy学习笔记(1)
初探scrapy,发现很多入门教程对应的网址都失效或者改变布局了,走了很多弯路.于是自己摸索做一个笔记. 环境是win10 python3.6(anaconda). 安装 pip install sc ...
- scrapy 学习笔记2
本章学习爬虫的 回调和跟踪链接 使用参数 回调和跟踪链接 上一篇的另一个爬虫,这次是为了抓取作者信息 # -*- coding: utf-8 -*- import scrapy class Myspi ...
随机推荐
- [django]django权限简单实验
djagno https://www.jianshu.com/p/01126437e8a4 开始我一直没明白内置的view_car 怎么实现view 只读库的. 后来发现这个api需要在views.p ...
- Java通过POI读取Excel
package com.hd.all.test.testjava; import java.io.File; import java.io.FileInputStream; import java.i ...
- Nginx或Apache通过反向代理配置wss服务
nginx配置参考 前提条件及准备工作: 1.假设ws服务监听的是8282端口(websocket协议) 2.已经申请了证书(pem/crt文件及key文件)放在了/etc/nginx/conf.d/ ...
- Appium环境搭建(一)
python环境做测试,需要准备工具如下: 1.python2.7(这里使用的是python2你也可以选更高版本) 2.Appium(Window版) 3.Android SDK 4.Appium_P ...
- unity3d-游戏实战突出重围,第四天 添加角色
1:添加unity自带的第一人称角色控制器,命名为hreo 2:添加第三人称角色控制器.这里是添加源文件Sources下面的.如箭头指示:而不是“3rd Person Controller”.并命名为 ...
- Ajax的重构
Ajax的重构方法: (1)创建一个单独的JS文件,命名为AjaxRequest.js,并且在该文件中编写重构Ajax所需要的代码. var net = new Object(); //创建一个全局变 ...
- sql 存储过程命名规范
规范的命名可以提高开发和维护的效率,如果你正在创建一个新的存储过程,请参考如下的命名规范. 句法: 存储过程的命名有这个的语法:[proc] [MainTableName] By [FieldName ...
- Unity shader学习之阴影,衰减统一处理
使用unity AutoLight.cginc文件里的内置函数 UNITY_LIGHT_ATTENUATION shader如下: // Upgrade NOTE: replaced 'mul(UNI ...
- [ Learning ] Design Pattens
1. 单例2. 模板3. 代理,装饰 (代理和装饰的区别)4. 状态
- Vue系列之 => 组件切换
组件切换方式一 <!DOCTYPE html> <html lang="en"> <head> <meta charset="U ...