Java—集合框架详解
一、描述Java集合框架
集合,在Java语言中,将一系类的对象看成一个整体。
首先查看jdk中的Collection类的源码后会发现Collection是一个接口类,其继承了java迭代接口Iterable.
API:

java集合框架图:
在图当中,虚线框的类型是接口,短横线框的类型是抽象类,实线框的类型是实现类。
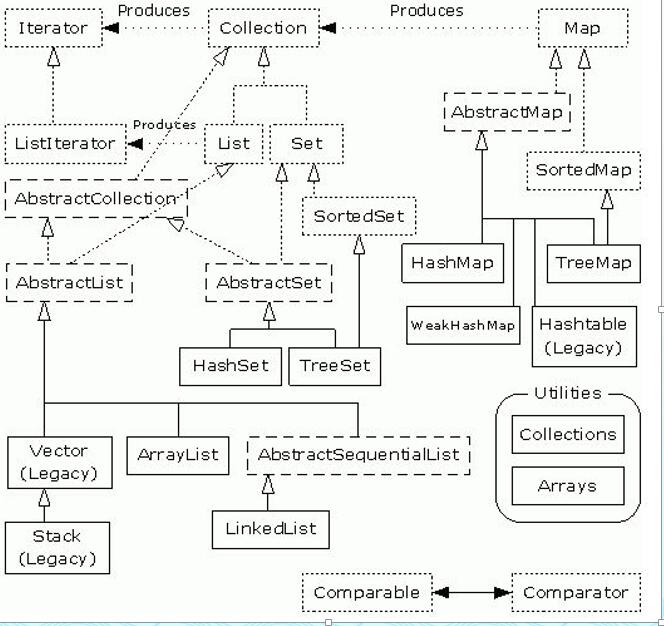
集合的包在java.util下
集合框架的顶层接口:java.util.Collection,迭代器接口:Java.util.Iterator;
Collection接口有两个主要的字接口List和Set,但是要注意Map不是Collection的子接口,因为其本身就是一个顶层接口,放在此是由于映射键与值使用了set。Collection中可以储存的元素间无序可以重复组各自独立的元素,即其内的每个位置仅持有一个元素,同时允许有多个null元素对象。
Collection接口中的方法如下:
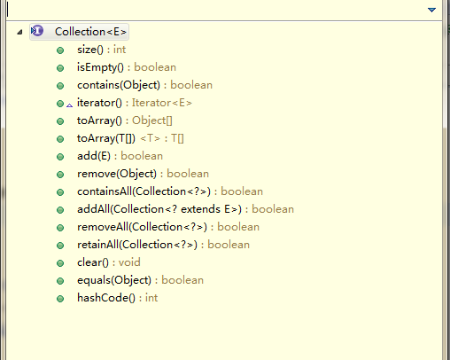
集合分类有三种List 、Set、Map
1、列表:java.util.List
List中储存的元素实现类排序,而且可以重复储存相关元素。List有ArrayList、Vector、LinkedList等等的实现类,ArrayList和Vector都是数组的实现,Vector线程是安全的,LinkedList是链表的实现。
List接口有两个常用的实现类ArrayList和LinkedList。
(一)ArrayList:
ArrayList数组线性表的特点为:类似数组的形式进行存储,因此它的随机访问速度极快。
ArrayList数组线性表的缺点为:不适合于在线性表中间需要频繁进行插入和删除操作。因为每次插入和删除都需要移动数组中的元素。可以这样理解ArrayList就是基于数组的一个线性表,只不过数组的长度可以动态改变而已。
编程练习ArrayList的使用,示例:
1、
import java.util.ArrayList;
import java.util.List; public class ArrayListDemo { public static void main(String[] args) {
//实例化一个集合实例,下面两个集合实例化都是可以的
List list0 = new ArrayList();
ArrayList list1 = new ArrayList();
//向列表中添加元素
list0.add(123456);
list0.add(null);
list0.add("abcdef");
//显示指定位置的元素
System.out.println(list0.get(1));//索引是从0开始的,结果显示null
//显示列表中所有的元素
for(Object l : list0) {
System.out.println(l);
}
2、
//在列表集合ArrayList中查找一个元素,显示“找到”与“未找到”
ArrayList list2 = new ArrayList();
list1.add(123);
list1.add(null);
list1.add("abc");
if(list2.contains(123)) {
System.out.println("元素存在");
}
else {
System.out.println("元素不存在");//结果:元素存在
}
3、来一个Vector使用的例子
package org.sl.jiheDemo;
import java.util.Vector;
public class VectorDemo {
public static void main(String[] args) {
Vector v = new Vector();
v.add("小小酥");
v.add(123);
v.add(null);
for(Object a : v) {
System.out.println(a);
}
}
}
ArrayList面试小问答:
a、如果在初始化ArrayList的时候没有指定初始化长度的话,默认的长度为10.

b、ArrayList在增加新元素的时候如果超过了原始的容量的话,ArrayList扩容ensureCapacity的方案为“ 原始容量*3/2+1 "哦
c、ArrayList是线程不安全的,在多线程的情况下不要使用。
如果一定在多线程使用List的,您可以使用Vector,因为Vector和ArrayList基本一致,区别在于Vector中的绝大部分方法都使用了同步关键字修饰,这样在多线程的情况下不会出现并发错误哦,还有就是它们的扩容方案不同,ArrayList是通过“原始容量*3/2+1”,而Vector是允许设置默认的增长长度,Vector的默认扩容方式为原来的2倍。
切记Vector是ArrayList的多线程的一个替代品。
d、ArrayList实现遍历的几种方法,三种,示例:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List; public class ListDemo { public static void main(String[] args) {/*
* ArrayList实现遍历有哪几种方法
*/
ArrayList<String> list = new ArrayList<String>();
list.add("abc");
list.add("小小酥");
list.add("def");
//第一种方法是使用foreach遍历List
for(String str : list) { //这里也可以用for(int i=0; i<list.size(); i++)
System.out.println(str);
}
//第二种方法把链表变为数组相关的内容进行遍历
String[] strArray = new String[list.size()];
list.toArray(strArray);
for(String str1 : strArray) { //也可以用for(int i=0; i<strArray.length; i++)
System.out.println(str1);
}
//第三种方法 使用迭代器进行相关遍历
//首先获取迭代器对象,Iterator
Iterator<String> ite = list.iterator();
while(ite.hasNext()) { //hasNext():表示是否有下一个元素
System.out.println(ite.next()); //next():指向下一个元素
}
} }
显示结果:我截图就行了,三种方法显示了三次结果,结果都是一样的。
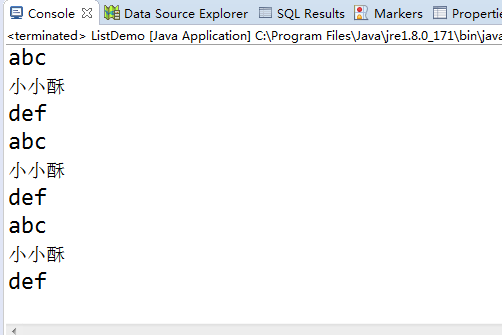
(二)LinkedList
LinkedList的链式线性表的特点为: 适合于在链表中间需要频繁进行插入和删除操作。
LinkedList的链式线性表的缺点为: 随机访问速度较慢。查找一个元素需要从头开始一个一个的找。速度你懂的。
可以这样理解LinkedList就是一种双向循环链表的链式线性表,只不过存储的结构使用的是链式表而已。
对于LinkedList的详细使用信息以及创建的过程可以查看jdk中LinkedList的源码,这里不做过多的讲解。
LinkedList面试小问答:
a.LinkedList和ArrayList的区别和联系
ArrayList数组线性表的特点为:类似数组的形式进行存储,因此它的随机访问速度极快。
ArrayList数组线性表的缺点为:不适合于在线性表中间需要频繁进行插入和删除操作。因为每次插入和删除都需要移动数组中的元素。
LinkedList的链式线性表的特点为: 适合于在链表中间需要频繁进行插入和删除操作。
LinkedList的链式线性表的缺点为: 随机访问速度较慢。查找一个元素需要从头开始一个一个的找。速度你懂的。
b.LinkedList的内部实现
对于这个问题,你最好看一下jdk中LinkedList的源码。这样你会醍醐灌顶的。
这里我大致说一下:
LinkedList的内部是基于双向循环链表的结构来实现的。在LinkedList中有一个类似于c语言中结构体的Entry内部类。
在Entry的内部类中包含了前一个元素的地址引用和后一个元素的地址引用类似于c语言中指针。
c.LinkedList不是线程安全的
注意LinkedList和ArrayList一样也不是线程安全的,如果在对线程下面访问可以自己重写LinkedList
然后在需要同步的方法上面加上同步关键字synchronized
d.LinkedList的遍历方法:示例
import java.util.LinkedList;
import java.util.List; public class LinkedListDemo {
public static void main(String[] args) {
List<String> list = new LinkedList<String>();
list.add("小小酥");
list.add("小张");
list.add("abc");
//使用foreach遍历LinkedList
for(String str : list) {
System.out.println(str);
}
//使用数组遍历
String[] strArray = new String[list.size()];
list.toArray(strArray);
for(String str1 : strArray) {
System.out.println(str1);
}
//还有其他的方法的话我没去研究了
}
}
结果如下:
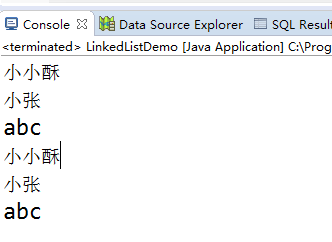
e.LinkedList可以被当做堆栈来使用
由于LinkedList实现了接口Dueue,所以LinkedList可以被当做堆栈来使用,这个你自己研究吧。
2、集:java.util.Set
Set接口也是Collection接口的一个常用的子接口 ,Set中的元素实现了不重复,无序,不允许有重复的元素,最多允许一个null元素对象。
查看Set接口的源码:
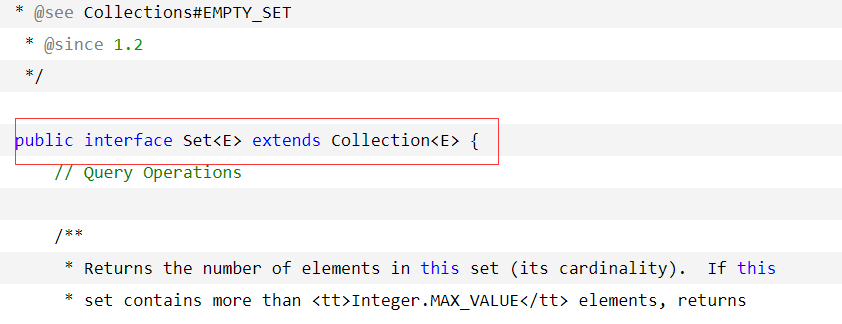
这里就自然而然的知道Set接口是Collection接口的子接口了吧。
需要注意的是:虽然Set中元素没有顺序,但是元素在set中的位置是由该元素的HashCode决定的,其具体位置其实是固定的。
此外需要说明一点,在set接口中的不重复是由特殊要求的。
举一个例子:对象A和对象B,本来是不同的两个对象,正常情况下它们是能够放入到Set里面的,但是
如果对象A和B的都重写了hashcode和equals方法,并且重写后的hashcode和equals方法是相同的话。那么A和B是不能同时放入到Set集合中去的,也就是Set集合中的去重和hashcode与equals方法直接相关。
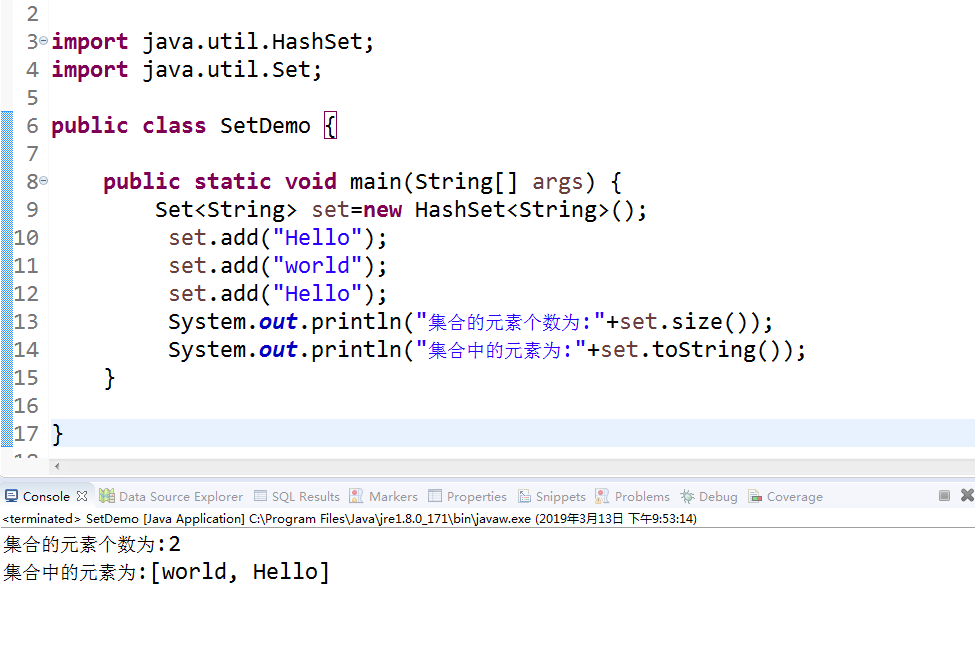
示例:截图(set集是不保证顺序的,没有索引的说明)
Set接口的常见实现类有HashSet,LinedHashSet和TreeSet这三个。下面我们将分别讲解这三个类:
(1)HashSet
HashSet是Set接口的最常见的实现类了。其底层是基于Hash算法进行存储相关元素的。
下面是HashSet的部分源码::
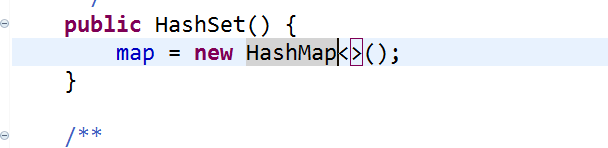
对于HashSet的底层就是基于HashMap来实现的。
HashSet使用和理解中容易出现的误区:
a.HashSet中存放null值
HashSet中时允许出入null值的,但是在HashSet中仅仅能够存入一个null值哦。
b.HashSet中存储元素的位置是固定的
HashSet中存储的元素的是无序的,这个没什么好说的,但是由于HashSet底层是基于Hash算法实现的,使用了hashcode,
所以HashSet中相应的元素的位置是固定的
c.遍历HashSet的几种方法:
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set; public class SetDemo { public static void main(String[] args) {
Set<String> set=new HashSet<String>();
//向集合中放入元素,set集是不保证顺序的,没有索引的说明
set.add("Hello");
set.add("world");
set.add("小小酥");
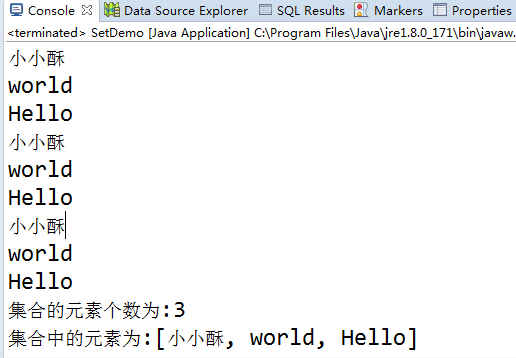
//第一种set集合直接遍历
for(String str : set) {
System.out.println(str);
}
//第二种使用数组方法
String[] strArray = new String[set.size()];
set.toArray(strArray);
for(String str1 : set) {
System.out.println(str1);
}
//第三种使用迭代器的方法,Iterator
Iterator<String> ite = set.iterator();
while(ite.hasNext()) {
System.out.println(ite.next());
}
System.out.println("集合的元素个数为:"+set.size());
System.out.println("集合中的元素为:"+set.toString());
}
}
结果输出:
(2)LinkHashSet
LinkHashSet不仅是Set接口的子接口而且还是上面HashSet接口的子接口。
查看LinkedHashSet的部分源码如下:
3)TreeSet
TreeSet是一种排序二叉树。存入Set集合中的值,会按照值的大小进行相关的排序操作。底层算法是基于红黑树来实现的。
TreeSet和HashSet的主要区别在于TreeSet中的元素会按照相关的值进行排序~
TreeSet和HashSet的区别和联系
1. HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,只不过Set用的只是Map的key
2. Map的key和Set都有一个共同的特性就是集合的唯一性.TreeMap更是多了一个排序的功能.
3. hashCode和equal()是HashMap用的, 因为无需排序所以只需要关注定位和唯一性即可.
a. hashCode是用来计算hash值的,hash值是用来确定hash表索引的.
b. hash表中的一个索引处存放的是一张链表, 所以还要通过equal方法循环比较链上的每一个对象
才可以真正定位到键值对应的Entry.
c. put时,如果hash表中没定位到,就在链表前加一个Entry,如果定位到了,则更换Entry中的value,并返回旧value
4. 由于TreeMap需要排序,所以需要一个Comparator为键值进行大小比较.当然也是用Comparator定位的.
a. Comparator可以在创建TreeMap时指定
b. 如果创建时没有确定,那么就会使用key.compareTo()方法,这就要求key必须实现Comparable接口.
c. TreeMap是使用Tree数据结构实现的,所以使用compare接口就可以完成定位了.
3、映射:java.util.Map
Map接口实现的是一组Key-Value的键值对的组合。 Map中的每个成员方法由一个关键字(key)和一个值(value)构成。Map接口不直接继承于Collection接口(需要注意啦),因为它包装的是一组成对的“键-值”对象的集合,而且在Map接口的集合中也不能有重复的key出现,因为每个键只能与一个成员元素相对应。如图
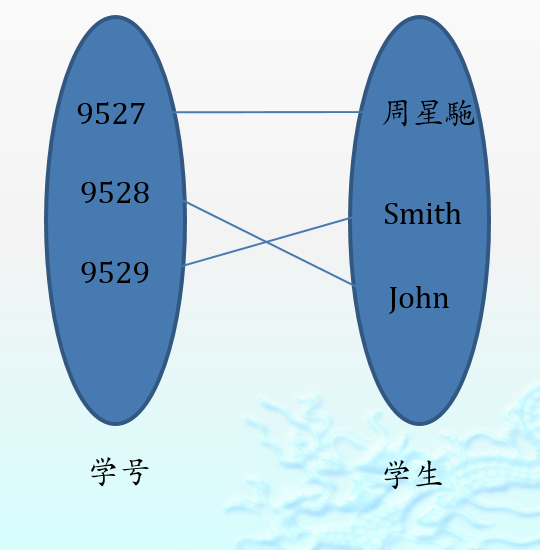
(图简略将就看看)
在我们的日常的开发项目中,我们无时无刻不在使用者Map接口及其实现类。Map有两种比较常用的实现:HashMap和TreeMap等。HashMap也用到了哈希码的算法,以便快速查找一个键,TreeMap则是对键按序存放,因此它便有一些扩展的方法,比如firstKey(),lastKey()等,你还可以从TreeMap中指定一个范围以取得其子Map。键和值的关联很简单,用pub(Object key,Object value)方法即可将一个键与一个值对象相关联。用get(Object key)可得到与此key对象所对应的值对象。
简单介绍一下HashMap和Hashtable
HashMap
HashMap实现了Map、CloneMap、Serializable三个接口,并且继承自AbstractMap类。HashMap基于hash数组实现,若key的hash值相同则使用链表方式进行保存。
新建一个HashMap时,默认的话会初始化一个大小为16,负载因子为0.75的空的HashMap
先来个示例,我懒得敲了,直接截图
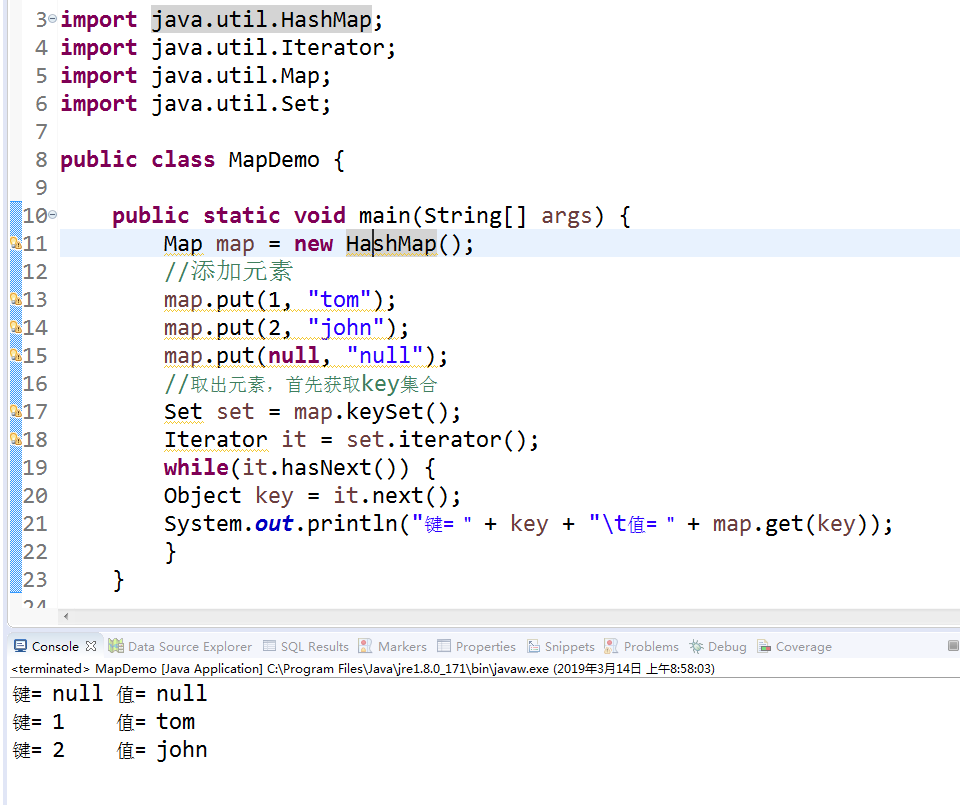
HashMap与Hashtable的区别:
HashMap:线程不安全,可以在列表中放置一个key为null的元素,也可以多个value为null的元素
Hashtable:线程安全,不允许键和值有null的元素。
还有一个集合工具排序那个,见下章,对了不对的请指教,谢谢
Java—集合框架详解的更多相关文章
- java集合框架详解
java集合框架详解 一.Collection和Collections直接的区别 Collection是在java.util包下面的接口,是集合框架层次的父接口.常用的继承该接口的有list和set. ...
- Java集合框架详解(全)
一.Java集合框架概述 集合可以看作是一种容器,用来存储对象信息.所有集合类都位于java.util包下,但支持多线程的集合类位于java.util.concurrent包下. 数组与集合的区别如下 ...
- java的集合框架详解
前言:数据结构对程序设计有着深远的影响,在面向过程的C语言中,数据库结构用struct来描述,而在面向对象的编程中,数据结构是用类来描述的,并且包含有对该数据结构操作的方法. 在Java语言中,Jav ...
- Collection集合框架详解
[Java的集合框架] 接口: collection map list set 实现类: ArryList HashSet HashMap LinkList LinkHash ...
- Java集合框架全解
Collection 集合 集合接口有2个基本方法: public interface Collection<E> { //向集合中添加元素.如果添加元素确实改变了集合就返回 true, ...
- java SSH框架详解(面试和学习都是最好的收藏资料)
Java—SSH(MVC)1. 谈谈你mvc的理解MVC是Model—View—Controler的简称.即模型—视图—控制器.MVC是一种设计模式,它强制性的把应用程序的输入.处理和输出分开.MVC ...
- JAVA集合类型详解
一.前言 作为java面试的常客[集合类型]是永恒的话题:在开发中,主要了解具体的使用,没有太多的去关注具体的理论说明,掌握那几种常用的集合类型貌似也就够使用了:导致这一些集合类型的理论有可能经常的忘 ...
- Java Collection框架详解
引用自:http://blog.sina.com.cn/s/blog_6d6f5d7d0100s9nu.html 经常会看到程序中使用了记录集,常用的有Collection.HashMap.HashS ...
- Java集合-----Set详解
Set是没有重复元素的集合,是无序的 1.HashSet HashSet它是线程不安全的 HashSet常用方法: add(E element) 将指定的元素添加到此集合(如果尚未存 ...
随机推荐
- C - 数字配对 (网络流 最大费用最大流)
题目链接:https://cn.vjudge.net/contest/281959#problem/C 题目大意:中文题目 具体思路:用网络流的思想,我们求得是最大的匹配数,那么我们按照二分图的形式去 ...
- ACM-ICPC 2018 沈阳赛区网络预赛 K题
题目链接: https://nanti.jisuanke.com/t/31452 AC代码(看到不好推的定理就先打表!!!!): #include<bits/stdc++.h> using ...
- Pytorch 各种奇葩古怪的使用方法
h1 { counter-reset: h2counter; } h2 { counter-reset: h3counter; } h3 { counter-reset: h4counter; } h ...
- xcode查找当前程序的沙盒
随意在程序中添加一个断点,当程序命中断点的时候,控制台中会出现一个"lldb" 此时在"lldb"后面添加上 po NSHomeDirectory() 回车 ...
- oracle存储过程,sql语句执行时间
create or replace procedure sum_info is i integer; temp1 varchar2(50); temp2 varchar2(50); t1 date; ...
- Linux mmc framework2:基本组件之mmc
1.前言 本文主要mmc组件的主要流程,在介绍的过程中,将详细说明和mmc相关的流程,涉及到其它组件的详细流程再在相关文章中说明. 2.主要数据结构和API TODO 3. 主要流程 3.1 mmc_ ...
- Vistual Studio Community 2017 账号的许可证过期,公安网激活方法
方法: 1.外网电脑打开Vistual Studio Community2017 2.在许可证过期弹窗中登陆账号即可自动下载许可证完成激活 许可证下载路径(C:\用户\user\Ap ...
- plsql developer无法识别32位oracle问题如何解决?
1.登录PL/SQL Developer这里省略Oracle数据库和PL/SQL Developer的安装步骤,注意在安装PL/SQL Developer软件时,不要安装在Program Files ...
- Linux下常见音频格式之间的转换方法
Linux下常见音频格式之间的转换方法[转] 下面简单介绍下Linux环境常见音频格式之间的转换方法: MP3 相关工具: lameOGG 相关工具: vorbis-toolsAPE 相关工具: ma ...
- 转载:Linux内核参数的优化(1.3.4)《深入理解Nginx》(陶辉)
原文:https://book.2cto.com/201304/19615.html 由于默认的Linux内核参数考虑的是最通用的场景,这明显不符合用于支持高并发访问的Web服务器的定义,所以需要修改 ...