爬取w3c课程—Urllib库使用
爬虫原理
浏览器获取网页内容的步骤:浏览器提交请求、下载网页代码、解析成页面,爬虫要做的就是:
- 模拟浏览器发送请求:通过HTTP库向目标站点发起请求Request,请求可以包含额外的header等信息,等待服务器响应
- 获取响应内容:如果服务器正常响应,会得到一个响应Response,响应的内容便是所要获取的页面内容,类型可能是HTML,Json字符串,二进制数据(图片或者视频)等
- 解析响应内容:获取响应内容后,解析各种数据,如:解析html数据:正则表达式,第三方解析库,解析json数据:json模块,解析二进制数据:进一步处理或以wb的方式写入文件
- 保存数据:保存为文本,数据库,或者保存特定格式的文件
简单例子:利用Urllib库爬取w3c网站教程
1、urllib的request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应:例如,对百度的一个w3c发送一个GET请求,并返回响应:
# coding:utf-8
import urllib.request my_url='https://www.w3cschool.cn/tutorial'#要获取课程的网址
page = urllib.request.urlopen(my_url)
html = page.read().decode('utf-8')
print(html)
把发送一个GET请求到指定的页面,返回HTTP的响应写成一个函数:
def get_html(url):#访问url
page = urllib.request.urlopen(url)
html = page.read().decode('utf-8')
return html
将返回如下内容,这与在浏览器查看源码看到的是一样的,接下来可以根据返回的内容进行解析:

2、利用正则表达式的分组提取课程名称、课程简介、课程链接,导入python里面的re库
reg = r'<a href="([\s\S]*?)" title=[\s\S]*?<h4>(.+)</h4>\n<p>([\s\S]*?)</p>'#运用正则表达式,分组提取数据
reg_tutorial = re.compile(reg)#编译一下正则表达式,运行更快
tutorial_list = reg_tutorial.findall(get_html(my_url))#进行匹配,
到现在代码如下:
# coding:utf-8
import urllib.request
import re my_url='https://www.w3cschool.cn/tutorial'#要获取课程的网址 def get_html(url):#访问url
page = urllib.request.urlopen(url)
html = page.read().decode('utf-8')
return html reg = r'<a href="([\s\S]*?)" title=[\s\S]*?<h4>(.+)</h4>\n<p>([\s\S]*?)</p>'#运用正则表达式,分组提取数据
reg_tutorial = re.compile(reg)#编译一下正则表达式,运行更快
tutorial_list = reg_tutorial.findall(get_html(my_url))#进行匹配 print("一共有课程数:" + str(len(tutorial_list)))#打印出有多少课程 for i in range(len(tutorial_list)):#把课程名称、课程简介、课程链接写到excel,python里面excel从0开始计算
print (tutorial_list[i])
运行,打印结果:

3、保存数据,保存数据到excel里面,用到excel第三方库xlwt,也可以只用openpyxl,库的使用可以参照官网:http://www.python-excel.org/
本次需要新建一个Excel,把课程名称、课程简介、课程链接写到Excel里面,课程链接用xlwt.Formula设置超链接,Excel第一行设置为宋体,加粗,写一些课程内容外的东西
import xlwt
excel_path=r'tutorial.xlsx'#excel的路径
book = xlwt.Workbook(encoding='utf-8', style_compression=0)# 创建一个Workbook对象,这就相当于创建了一个Excel文件
sheet = book.add_sheet('课程',cell_overwrite_ok=True)# 添加表
style = xlwt.XFStyle()#初始化样式
font = xlwt.Font()#创建字体
font.name = '宋体'#指定字体名字
font.bold = True#字体加粗
style.font = font#将该font设定为style的字体
sheet.write(0, 0, '序号',style)#用之前的style格式写第一行,行、列从0开始计算
sheet.write(0, 1, '课程',style)
sheet.write(0, 2, '简介',style)
sheet.write(0, 3, '课程链接',style)
写课程内容到Excel
for i in range(len(tutorial_list)):#把课程名称、课程简介、课程链接写到excel,python里面excel从0开始计算
print (tutorial_list[i])
sheet.write(i+1, 0, i+1)
sheet.write(i+1, 1, tutorial_list[i][1])
sheet.write(i+1, 2, tutorial_list[i][2])
sheet.write(i+1, 3, xlwt.Formula("HYPERLINK(" +'"'+"https:" + tutorial_list[i][0]+'"'+')'))#把链接写进去,并用xlwt.Formula设置超链接 book.save(excel_path)#保存到excel
Excel内容:
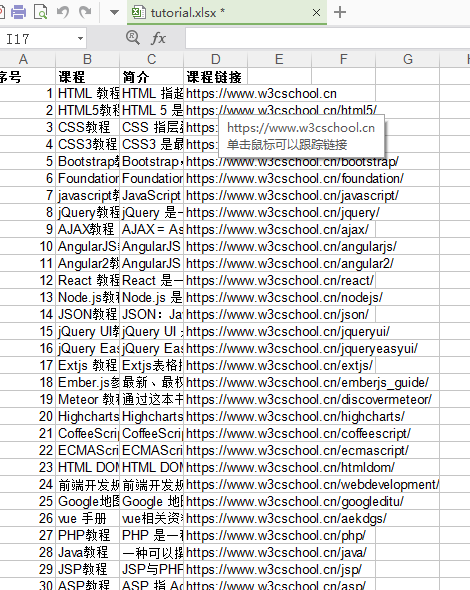
全部代码如下:
# coding:utf-8
import urllib.request
import re
import xlwt
excel_path=r'tutorial.xlsx'#excel的路径
my_url='https://www.w3cschool.cn/tutorial'#要获取课程的网址
book = xlwt.Workbook(encoding='utf-8', style_compression=0)# 创建一个Workbook对象,这就相当于创建了一个Excel文件
sheet = book.add_sheet('课程',cell_overwrite_ok=True)# 添加表
style = xlwt.XFStyle()#初始化样式
font = xlwt.Font()#创建字体
font.name = '宋体'#指定字体名字
font.bold = True#字体加粗
style.font = font#将该font设定为style的字体
sheet.write(0, 0, '序号',style)#用之前的style格式写第一行,行、列从0开始计算
sheet.write(0, 1, '课程',style)
sheet.write(0, 2, '简介',style)
sheet.write(0, 3, '课程链接',style) def get_html(url):#访问url
page = urllib.request.urlopen(url)
html = page.read().decode('utf-8')
return html reg = r'<a href="([\s\S]*?)" title=[\s\S]*?<h4>(.+)</h4>\n<p>([\s\S]*?)</p>'#运用正则表达式,分组提取数据
reg_tutorial = re.compile(reg)#编译一下正则表达式,运行更快
tutorial_list = reg_tutorial.findall(get_html(my_url))#进行匹配 print("一共有课程数:" + str(len(tutorial_list)))#打印出有多少课程 for i in range(len(tutorial_list)):#把课程名称、课程简介、课程链接写到excel,python里面excel从0开始计算
print (tutorial_list[i])
sheet.write(i+1, 0, i+1)
sheet.write(i+1, 1, tutorial_list[i][1])
sheet.write(i+1, 2, tutorial_list[i][2])
sheet.write(i+1, 3, xlwt.Formula("HYPERLINK(" +'"'+"https:" + tutorial_list[i][0]+'"'+')'))#把链接写进去,并用xlwt.Formula设置超链接 book.save(excel_path)#保存到excel
爬取w3c课程—Urllib库使用的更多相关文章
- python爬取course课程的信息
目录 1.大模块页面 2.每个大模块中小模块的简单信息 3.每个小课程的详细信息 4.爬取所有评论 @ 这几天爬取了course动态网页的课程信息,有关数据分析,机器学习,还有概率论和数理统计课程 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python爬虫从入门到放弃(三)之 Urllib库的基本使用
官方文档地址:https://docs.python.org/3/library/urllib.html 什么是Urllib Urllib是python内置的HTTP请求库包括以下模块urllib.r ...
- scrapy框架 + selenium 爬取豆瓣电影top250......
废话不说,直接上代码..... 目录结构 items.py import scrapy class DoubanCrawlerItem(scrapy.Item): # 电影名称 movieName = ...
- 爬虫常用的 urllib 库知识点
urllib 库 urllib 库是 Python 中一个最基本的网络请求库.它可以模仿浏览器的行为向指定的服务器发送请求,同时可以保存服务器返回的数据. urlopen() 在 Python3 的 ...
- python之爬虫(三) Urllib库的基本使用
官方文档地址:https://docs.python.org/3/library/urllib.html 什么是Urllib Urllib是python内置的HTTP请求库包括以下模块urllib.r ...
- Python爬虫--Urllib库
Urllib库 Urllib是python内置的HTTP请求库,包括以下模块:urllib.request (请求模块).urllib.error( 异常处理模块).urllib.parse (url ...
- urllib库的基本使用
urllib库的使用 官方文档地址:https://docs.python.org/3/library/urllib.html 什么是urllib Urllib是python内置的HTTP请求库包括以 ...
- 爬虫之Urllib库的基本使用
官方文档地址:https://docs.python.org/3/library/urllib.html 什么是Urllib Urllib是python内置的HTTP请求库包括以下模块urllib.r ...
随机推荐
- 解决:[DCC Fatal Error] **.dpk : E2202 Required package '***' not found
//[DCC Fatal Error] **.dpk : E2202 Required package '***' not found 意思是:[DCC致命错误] *:e2202需包***没有发现 D ...
- 在Mysql中查询两个时间段的差,可以是秒,天,星期,月份,年...
SELECT TIMESTAMPDIFF(SECOND, now(), "2016-11-11 00:00:00") 语法为:TIMESTAMPDIFF(unit,datetime ...
- VMware xp系统联网
1.
- aircrack-ng笔记
开启监听: airmon-ng start wlan0 抓包: airodump-ng wlan0mon 查看wifi ^C结束 airodump-ng -c 6 --bssid C8:3A:35:3 ...
- freeRTOS中文实用教程6--错误排查
1.前言 本章主要是为刚接触FreeRTOS 的用户指出那些新手通常容易遇到的问题.这里把最主要的篇幅放在栈溢出以及栈溢出侦测上 2.printf-stdarg.c 当调用标准C 库函数时,栈空间使用 ...
- 深入理解linux内核v4l2框架之videobuf2【转】
转自:https://blog.csdn.net/ramon1892/article/details/8444193 Videobuf2框架 1. 什么是videobuf2框架? 它是一个针对多媒体设 ...
- WCF错误远程服务器返回了意外响应: (413) Request Entity Too Large。解决方案
这个问题出现的原因是 调用wcf服务的时候传递的参数 长度太大 wcf数据传输采用的默认的大小是65535字节. ---------------------------------------- ...
- 创建虚拟机时,提示No valid host was found解决办法
1.http://blog.csdn.net/yxwmzouzou/article/details/43892261 2.http://www.cnblogs.com/kevingrace/p/601 ...
- Qt Ubuntu 编译出错-1: error: 找不到 -lGL
安装好,编译界面程序出错“-1: error: 找不到 -lGL” 在终端运行如下命令(安装Qt5.8.0) sudo apt-get install libqt5-dev sudo apt-get ...
- SQL中的 if 结构和循环(while)结构