Apache Spark 2.3.0 重要特性介绍
文章标题
Introducing Apache Spark 2.3
Apache Spark 2.3 介绍
Now Available on Databricks Runtime 4.0
现在可以在Databrcks Runtime 4.0上使用。
作者介绍
Sameer Agarwal, Xiao Li, Reynold Xin and Jules Damji
文章正文:
Today we are happy to announce the availability of Apache Spark 2.3.0 on Databricks as part of its Databricks Runtime 4.0. We want to thank the Apache Spark community for all their valuable contributions to Spark 2.3 release.
今天,我们很高兴地

Continuing with the objectives to make Spark faster, easier, and smarter, Spark 2.3 marks a major milestone for Structured Streaming by introducing low-latency continuous processing and stream-to-stream joins; boosts PySpark by improving performance with pandas UDFs; and runs on Kubernetes clusters by providing native support for Apache Spark applications.
In addition to extending new functionality to SparkR, Python, MLlib, and GraphX, the release focuses on usability, stability, and refinement, resolving over 1400 tickets. Other salient features from Spark contributors include:
- DataSource v2 APIs [SPARK-15689, SPARK-20928]
- Vectorized ORC reader [SPARK-16060]
- Spark History Server v2 with K-V store [SPARK-18085]
- Machine Learning Pipeline API model scoring with Structured Streaming [SPARK-13030, SPARK-22346, SPARK-23037]
- MLlib Enhancements Highlights [SPARK-21866, SPARK-3181, SPARK-21087, SPARK-20199]
- Spark SQL Enhancements [SPARK-21485, SPARK-21975, SPARK-20331, SPARK-22510, SPARK-20236]
In this blog post, we briefly summarize some of the high-level features and improvements, and in the coming days, we will publish in-depth blogs for these features. For a comprehensive list of major features across all Spark components and JIRAs resolved, read the Apache Spark 2.3.0 release notes.
1、Continuous Stream Processing at Millisecond Latencies
Structured Streaming in Apache Spark 2.0 decoupled micro-batch processing from its high-level APIs for a couple of reasons. First, it made developer’s experience with the APIs simpler: the APIs did not have to account for micro-batches. Second, it allowed developers to treat a stream as an infinite table to which they could issue queries as they would a static table.
However, to provide developers with different modes of stream processing, we introduce a new millisecond low-latency mode of streaming: continuous mode.
Under the hood, the structured streaming engine incrementally executed query computations in micro-batches, dictated by a trigger interval, with tolerable latencies suitable for most real-world streaming applications.
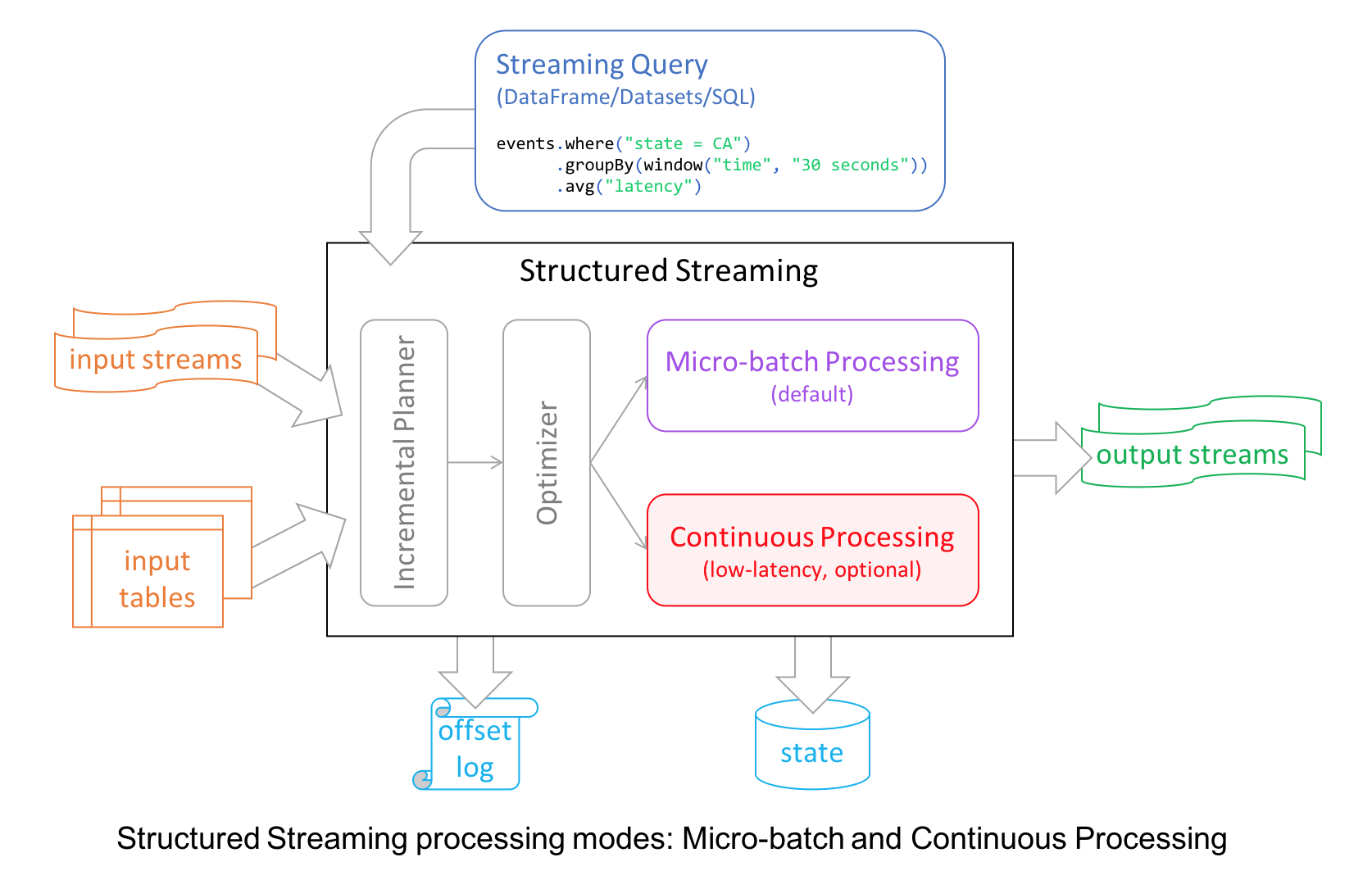
For continuous mode, instead of micro-batch execution, the streaming readers continuously poll source and process data rather than read a batch of data at a specified trigger interval. By continuously polling the sources and processing data, new records are processed immediately upon arrival, as shown in the timeline figure below, reducing latencies to milliseconds and satisfying low-level latency requirements.

As for operations, it currently supports map-like Dataset operations such as projections or selections and SQL functions, with the exception of current_timestamp(), current_date() and aggregate functions. As well as supporting Apache Kafka as a source and sink, continuous mode currently supports console and memory as sinks, too.
Now developers can elect either mode—continuous or micro-batching—depending on their latency requirements to build real-time streaming applications at scale while benefiting from the fault-tolerance and reliability guarantees that Structured Streaming engine affords.
In short, the continuous mode in Spark 2.3 is experimental and it offers the following:
- end-to-end millisecond low latencies
- provides at-least-once guarantees.
- supports map-like Dataset operations
In this technical blog on Continuous Processing mode, we illustrate how to use it, its merits, and
how developers can write continuous streaming applications with millisecond low-latency requirements.
2、Stream-to-Stream Joins
While Structured Streaming in Spark 2.0 has supported joins between a streaming DataFrame/Dataset and a static one, this release introduces the much awaited stream-to-stream joins, both inner and outer joins for numerous real-time use cases.
The canonical use case of joining two streams is that of ad-monetization. For instance, an impression stream and an ad-click stream share a common key (say, adId) and relevant data on which you wish to conduct streaming analytics, such as, which adId led to a click.
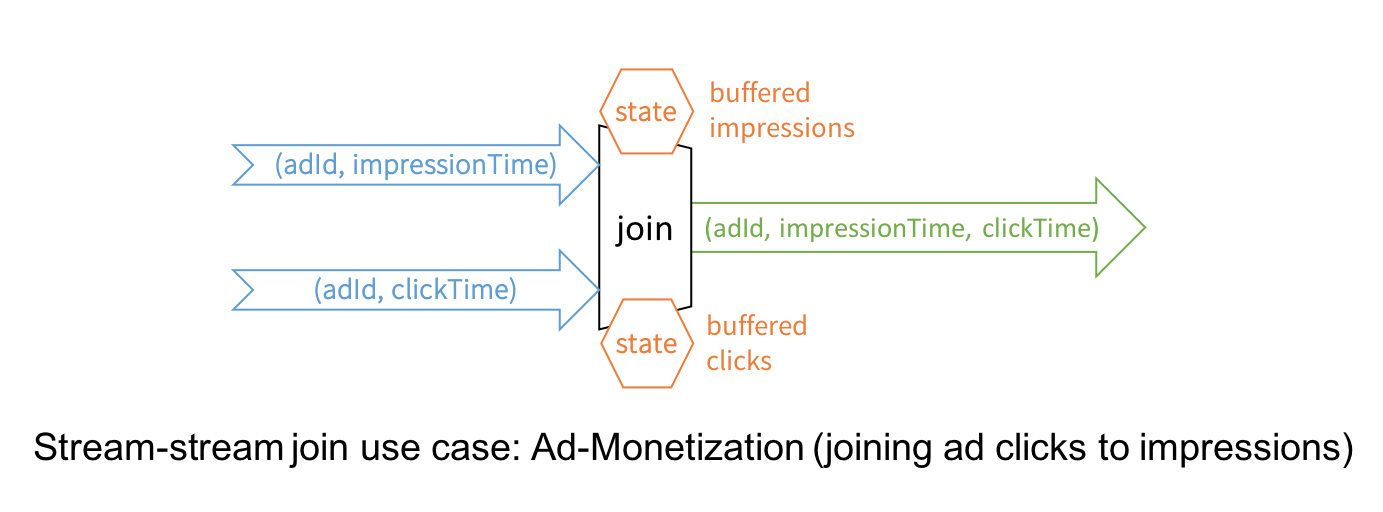
While conceptually the idea is simple, stream-to-stream joins resolve a few technical challenges. For example, they:
- handle delayed data by buffering late events as streaming “state” until matching event is found from the other stream
- limit the buffer from growing and consuming memory with watermarking, which allows tracking of event-time and accordingly clearing of old state
- allow a user to control the tradeoff between the resources consumed by state and the maximum delay handled by the query
- maintain consistent SQL join semantics between static joins and streaming joins
In this technical blog, we dive deeper into streams-to-stream joins.
3、Apache Spark and Kubernetes
No surprise that two popular open source projects Apache Spark and Kubernetes combine their functionality and utility to provide distributed data processing and orchestration at scale. In Spark 2.3, users can launch Spark workloads natively on a Kubernetes cluster leveraging the new Kubernetes scheduler backend. This helps achieve better resource utilization and multi-tenancy by enabling Spark workloads to share Kubernetes clusters with other types of workloads.
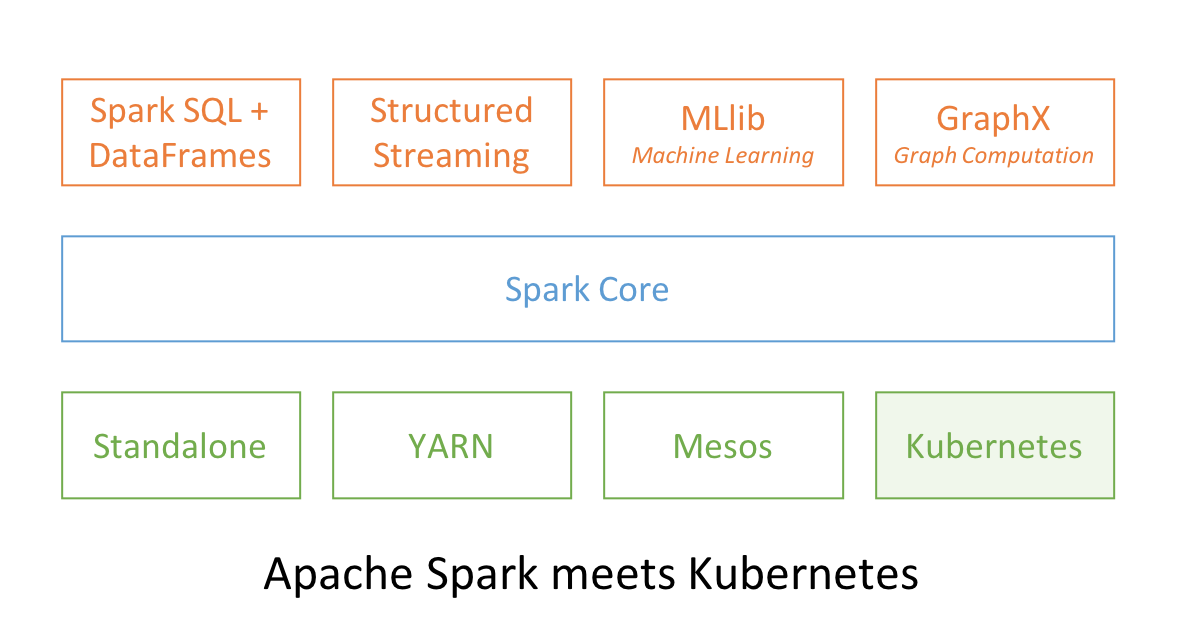
Also, Spark can employ all the administrative features such as Resource Quotas, Pluggable Authorization, and Logging. What’s more, it’s as simple as creating a docker image and setting up the RBAC to start employing your existing Kubernetes cluster for your Spark workloads.
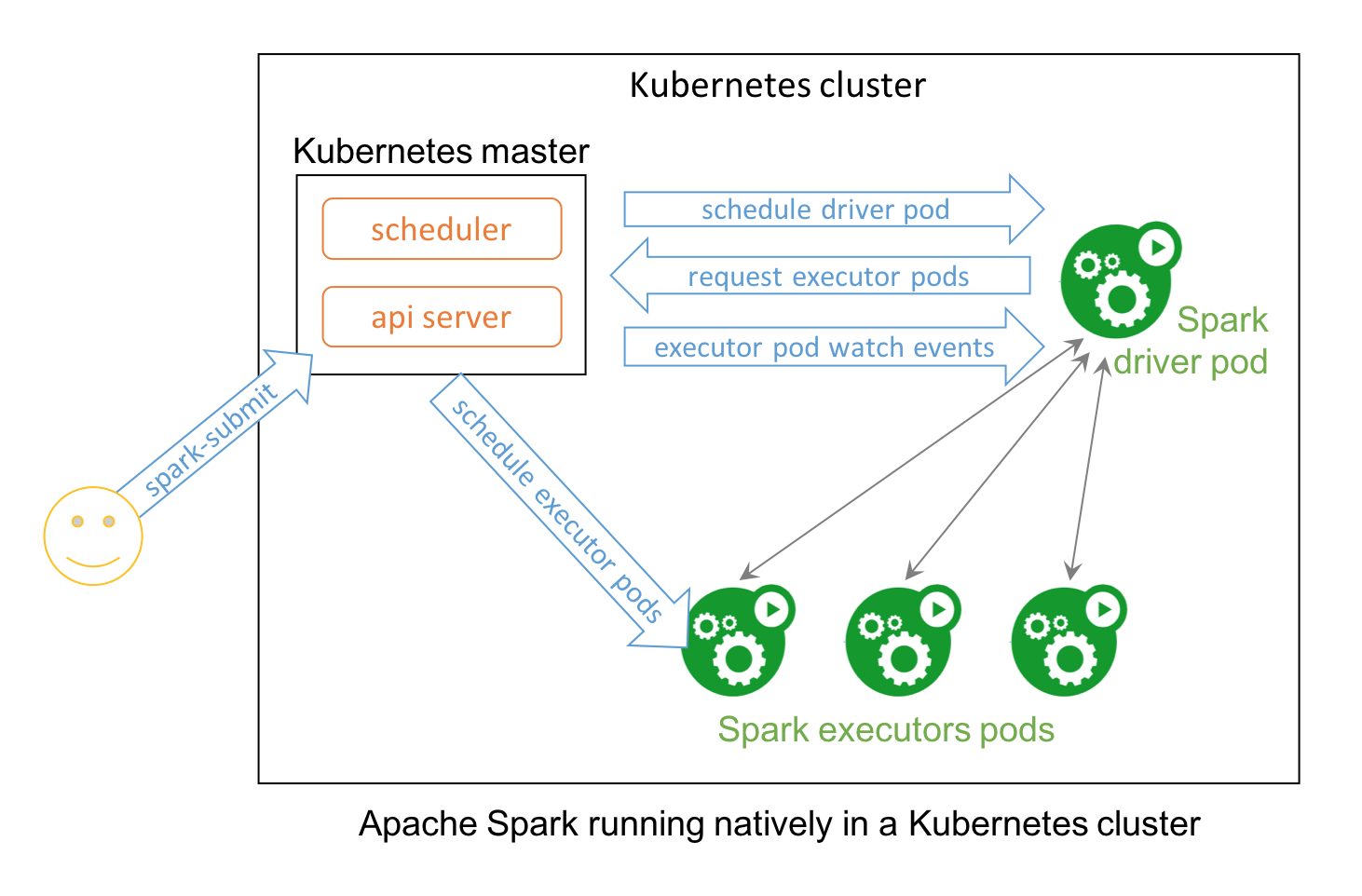
This technical blog explains how you can use Spark natively with Kubernetes and how to get involved in this community endeavor.
4、Pandas UDFs for PySpark
Pandas UDFs, also called Vectorized UDFs, is a major boost to PySpark performance. Built on top of Apache Arrow, they afford you the best of both worlds—the ability to define low-overhead, high-performance UDFs and write entirely in Python.
In Spark 2.3, there are two types of Pandas UDFs: scalar and grouped map. Both are now available in Spark 2.3. Li Jin of Two Sigma had penned an earlier blog, explaining their usage through four examples: Plus One, Cumulative Probability, Subtract Mean, Ordinary Least Squares Linear Regression.
Running some micro benchmarks, Pandas UDFs demonstrate orders of magnitude better performance than row-at-time UDFs.
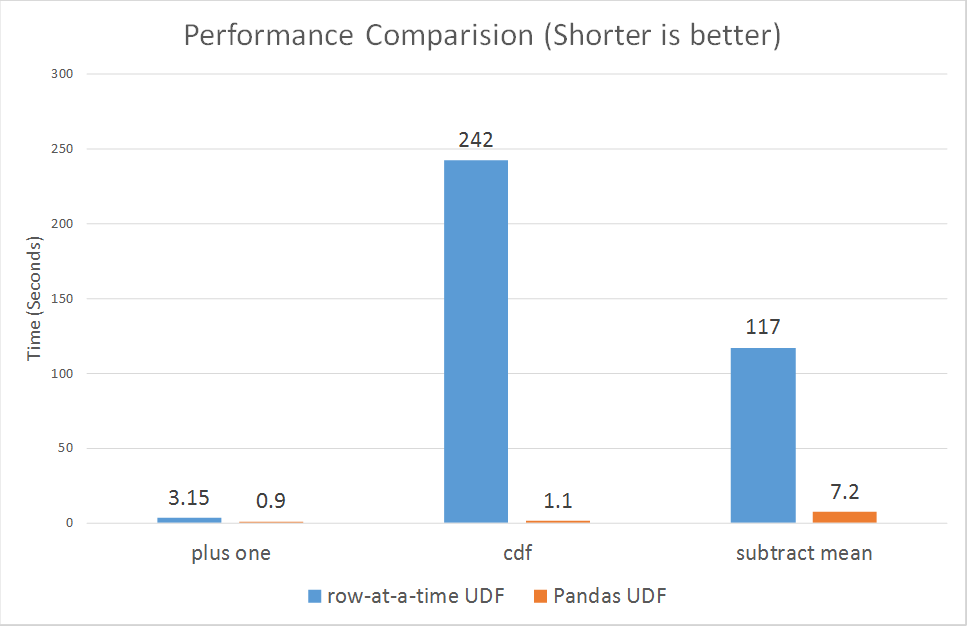
According to Li Jin and other contributors, they plan to introduce support for Pandas UDFs in aggregations and window functions, and its related work can be tracked in SPARK-22216.
5、MLlib Improvements
Spark 2.3 includes many MLlib improvements for algorithms and features, performance and scalability, and usability. We mention three highlights.
First, for moving MLlib models and Pipelines to production, fitted models and Pipelines now work within Structured Streaming jobs. Some existing Pipelines will require modifications to make predictions in streaming jobs, so look for upcoming blog posts on migration tips.
Second, to enable many Deep Learning image analysis use cases, Spark 2.3 introduces an ImageSchema [SPARK-21866] for representing images in Spark DataFrames, plus utilities for loading images from common formats.
And finally, for developers, Spark 2.3 introduces improved APIs in Python for writing custom algorithms, including a UnaryTransformer for writing simple custom feature transformers and utilities for automating ML persistence for saving and loading algorithms. See this blog post for details.
参考文献:
Apache Spark 2.3.0 重要特性介绍的更多相关文章
- Apache Spark 2.2.0新特性介绍(转载)
这个版本是 Structured Streaming 的一个重要里程碑,因为其终于可以正式在生产环境中使用,实验标签(experimental tag)已经被移除.在流系统中支持对任意状态进行操作:A ...
- Apache Spark 2.2.0 新特性详细介绍
本章内容: 待整理 参考文献: Apache Spark 2.2.0新特性详细介绍 Introducing Apache Spark 2.2
- Apache Spark 1.6公布(新特性介绍)
Apache Spark 1.6公布 CSDN大数据 | 2016-01-06 17:34 今天我们很高兴可以公布Apache Spark 1.6,通过该版本号,Spark在社区开发中达到一个重要的里 ...
- Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性
Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性 Apache hadoop 项目组最新消息,hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+ ...
- Apache Spark 2.2.0 中文文档
Apache Spark 2.2.0 中文文档 - 快速入门 | ApacheCN Geekhoo 关注 2017.09.20 13:55* 字数 2062 阅读 13评论 0喜欢 1 快速入门 使用 ...
- webpack 4.0.0-beta.0 新特性介绍
webpack 可以看做是模块打包机.它做的事情是:分析你的项目结构,找到JavaScript模块以及其它的一些浏览器不能直接运行的拓展语言(Scss,TypeScript等),并将其打包为合适的格式 ...
- Apache Spark 2.2.0 正式发布
本章内容: 待整理 参考文献: Apache Spark 2.2.0正式发布 Spark Release 2.2.0
- Pivotal Greenplum 6.0 新特性介绍
Pivotal Greenplum 6.0 新特性介绍 在1月12日举办的Greenplum开源有道智数未来技术研讨会上,Pivotal中国研发中心Greenplum 产品经理李阳向大家介绍了Pi ...
- [转帖]Pivotal Greenplum 6.0 新特性介绍
Pivotal Greenplum 6.0 新特性介绍 https://cloud.tencent.com/developer/news/391063 原来 greenplum 也是基于pg研发的. ...
随机推荐
- 【AtCoder】ARC080
C - 4-adjacent 我们挑出来4的倍数和不是4的倍数而是2的倍数,和奇数 然后就是放一个奇数,放一个4,如果一个奇数之后无法放4,然后它又不是最后一个,那么就不合法 #include < ...
- NDK 开发实例一(Android.mk环境配置下)
在我写这篇文章的时候,Android Studio已经是2.3版本了,已经集成CMake 编译工具, 用户只需在 新建项目的时候,添加选项(Include C++ support),Andr ...
- C#: 执行批处理文件(*.bat)的方法
static void Main(string[] args) { Process proc = null; try { proc = new Process(); proc.StartInfo.Fi ...
- POJ3348 Cows 计算几何 凸包
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - POJ3348 题意概括 求凸包面积(答案÷50) 题解 凸包裸题. 代码 #include <cstr ...
- Ubuntu 18.04安装Codeblocks
安装步骤: 一:首先安装简版CodeBlocks sudo apt install codeblocks 二:把编译环境,C库.C++库和Boost库装好 sudo apt install build ...
- Unicode字符编码表(转)
Unicode字符编码表 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/zhenyu5211314/article/details/5153 ...
- python小工具myqr生成动态二维码
python小工具myqr生成动态二维码 (一)安装 (二)使用 (一)安装 命令: pip install myqr 安装完成后,就可以在命令行中输入 myqr 查看下使用帮助: myqr --he ...
- Golang vs PHP 之文件服务器
前面的话 作者为golang脑残粉,本篇内容可能会引起phper不适,请慎读! 前两天有同事遇到一个问题,需要一个能支持上传.下载功能的HTTP服务器做一个数据中心.我刚好弄过,于是答应帮他搭一个. ...
- Python开发之pip使用详解
1 pip的优点 pip如今已经成为了Python的一大特色,可以很方便得协助Python开发者进行包管理.综合来说,匹配拥有如下优点: pip提供了丰富的功能,其竞争对手easy_install只支 ...
- Metasploit AFP爆破模块afp_login
Metasploit AFP爆破模块afp_login AFP是苹果系统支持的文件服务.用户可以使用指定的账户名和密码进行远程文件管理.afp_login是一个AFP认证信息暴力破解模块.它支持对 ...