ML(3)——线性回归
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。
模型
一元回归
以房价预测为例,假设存在这样的训练集:
|
m2 |
Price |
|
123 |
2250000 |
|
86 |
1850000 |
|
76 |
1280000 |
|
179 |
2860000 |
|
120 |
2050000 |
|
123 |
2350000 |
|
90 |
1300000 |
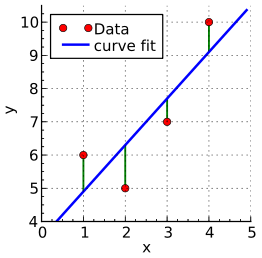
在上表中,房价和房屋大小存在一定的关联,我们试图寻找到一个模型表达这个关联,从而预测某个面积的房价。线性回归就是这样一种模型,它用一条直线拟合数据:
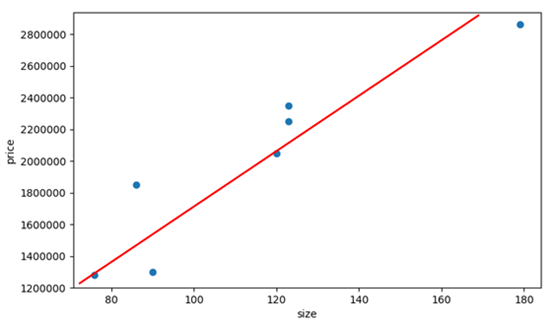
通过这条直线,可以预测任意面积的房价:
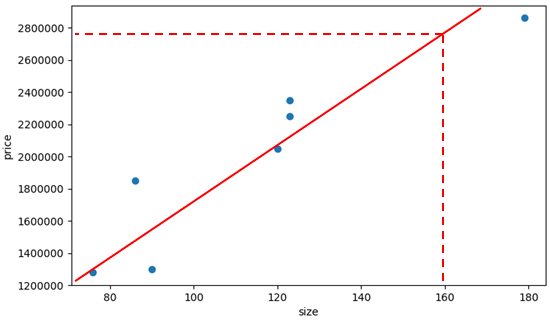
160平米的房价大概是2750000。线性回归之所以叫“线性”,正是由于其连续型,也就是模型函数是连续的,可以对任意值进行预测;至于“回归”,还是别去计较了。
上面是线性回归中最简单的一元模型,只有一个自变量,它用线性模型去拟合数据,其假设函数(hypothesis function) hθ(x)是:
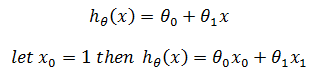
这也是我们熟悉的直线函数y = kx + b。
多元回归
在真实的世界中,房价还和很多因素有关,比如房屋的位置,楼层高度,是否是学区房等,此时需要用到多元回归模型:
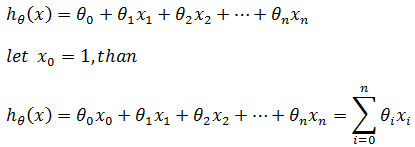
如果用向量表示:
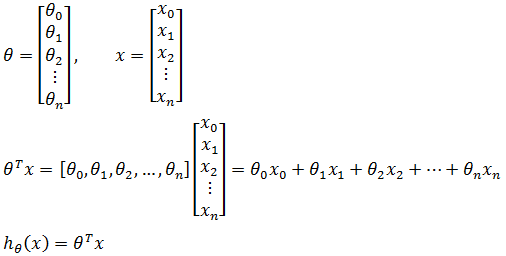
向量有几种写法,在线性代数中用矩阵表示,高数中用尖括号<x1,x2….>表示,我们选取其中一种即可。关于向量的内容可参考《线性代数》中的相关内容。
从上面可以看到,多元模型最终又化简为y = kx的形式。
学习策略
我们的最终目标是找到最佳的θ以拟合最多数据,也就是找到恰当的θ使得所有训练数据误差的总和达到最小化。计算误差的办法有很多种,其中两种典型的做法,一是计算数据到直线的距离(几何距离),二是数据和直线所对应的y值(代数距离)。根据计算方法的不同,得到的最终训练模型也不同。
实际应用中,如果计算点到直线的距离,就需使用两个维度的数据进行计算,而实际上两个维度大多数时候都不存在直接的计算关系,比如时间和房价,二者并不能直接进行指数和加减运算,想要运算必须通过成本函数转换。基于上述原因,通常使用第二种方法,也就是计算数据和直线所对应的y值:
在线性回归中,通常使用平方差损失函数作为J(θ):
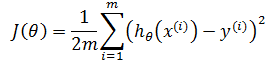
其中m是训练样本的个数,上标i表示第i个训练样本,y表示实际结果。平方是为了得能够进行凸优化的曲线,1/m 是为了使实际值与预测值误差均值接近于0,也就是每一个样本的误差接近于0:
如果写成矩阵的形式:
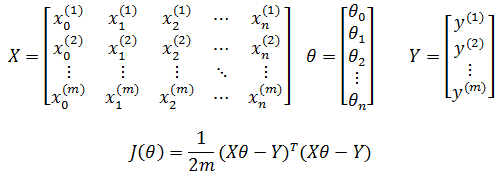
算法
梯度下降
梯度下降是适用范围很广的方法,其更多内容可参考《ML(附录1)——梯度下降》。
根据梯度下降:
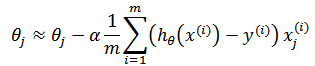
使用更为简洁的矩阵形式:
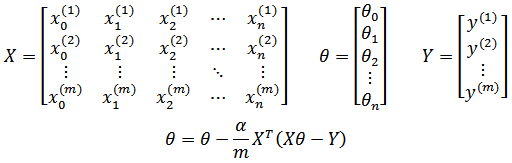
也可以使用随机梯度下降,每次仅选取第i个样本进行迭代:
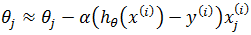
最小二乘法
也可以使用最小二乘法,形成一个对θ求偏导的方程组,通过方程组直接求得θ。关于最小二乘法,可参考《ML(附录2)——最小二乘法》。对于n维向量,转化过程如下:
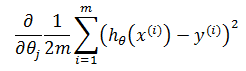
当训练集中仅有一个训练数据,即m = 1时,对θj求偏导:
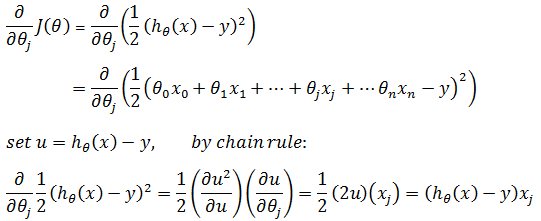
推广到m个数据:
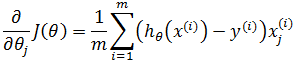
根据最小二乘法,令每个偏导都为0,由此得到含有n+1个方程的方程组:
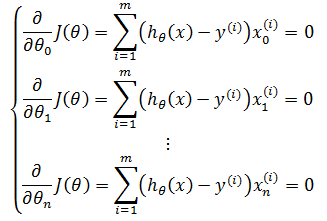
以第二个方程为例:
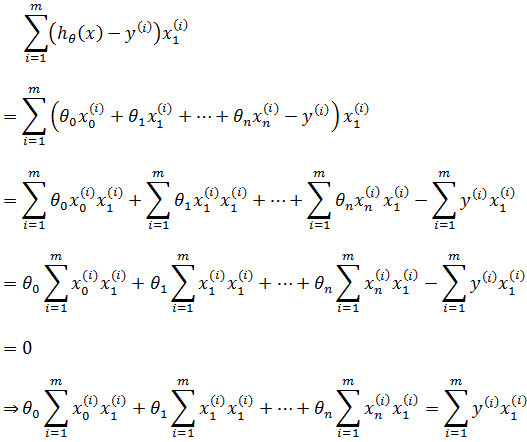
注意:
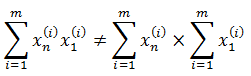
这里需要抑制住冲动,除非m = 1,否则不能将等式两边同时除以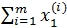
推广至方程组,得到n+1个不同的方程:
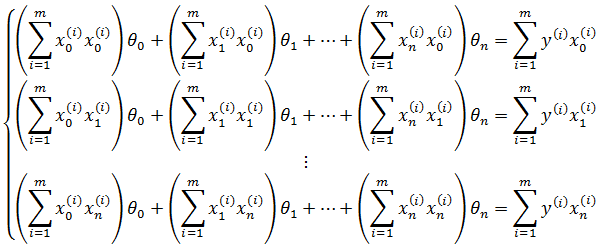
写成矩阵:
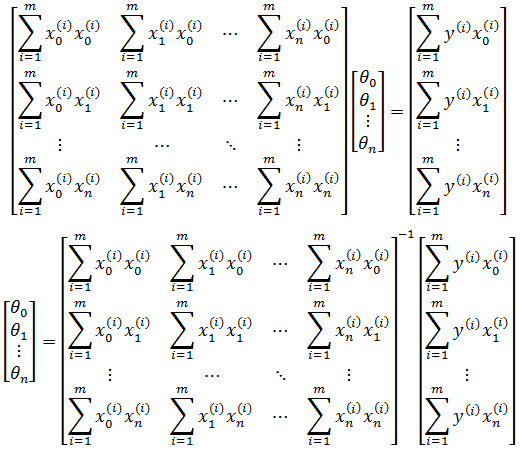
虽然能够最终求得θ,但是这种写法太过低效,在计算时很容易出错,更高效的法案是改为矩阵。以房价为例, 如果最终预测模型是hθ(x) = 20 + 2x,那么对于123m2,86m2,76m2三个数据的预测结果可以写作:
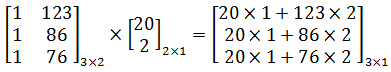
如果将模型参数和训练集全部看作矩阵向量:
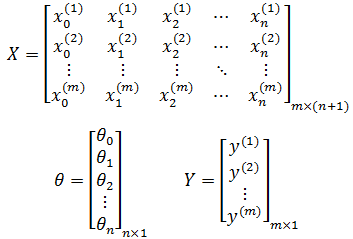
现在:
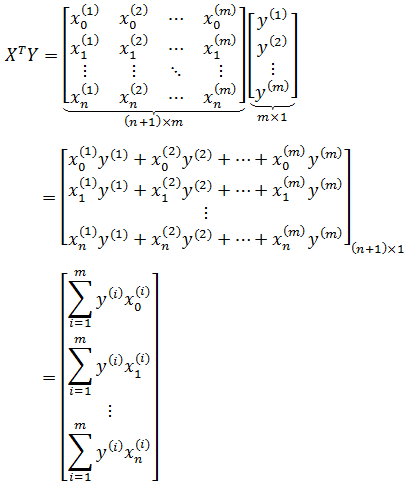
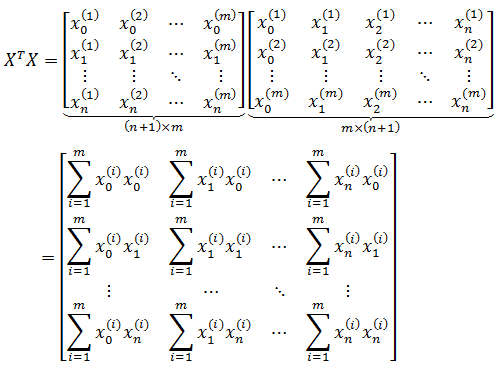
最终得到和代数结果吻合的矩阵形式:
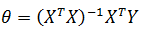
更简单的方法是直接把损失函数写成矩阵形式,然后对矩阵偏导,具体推导过程将在后续线性代数部分补充。
梯度下降和最小二乘的对比
既然最小二乘法的实现更加简单,是否我们可以总是使用它呢?当然不是,最主要的原因就是矩阵的乘法和求逆十分耗时,当X是n×n矩阵时,对(XTX)-1的运算耗时是O(n3)。在实际应用中,如果n > 10000,就应该考虑体地下降。
|
梯度下降 |
最小二乘法 |
|
需要选择学习率α |
不需要学习率 |
|
需要多次迭代 |
不需要迭代 |
|
当n很大时,能够有效运行 O(kn2) |
当n很大时,无法有效工作 O(n3) |
数据预处理
在房价的例子中,房子的总价过于庞大,每次迭代都使用这种大数计算将会减慢速度;对于梯度下降来说,将会导致收敛速度变慢,从而增加迭代次数。如果把所有房价都除以10000,将得到这样的数据:
|
m2 |
Price |
|
123 |
225 |
|
86 |
185 |
|
76 |
128 |
|
179 |
286 |
|
120 |
205 |
|
123 |
235 |
|
90 |
130 |
根据这样的值计算,会使算法速度加快。需要注意的是,由于改变的是因变量的值,所以最终预测结果要再乘以10000。
更一般的数据整理方法是一种被称“归一化”的方法,它能使所有维度的数据都转换为同一量级,其公式是:
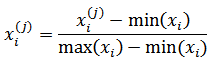
max(xi) – min(xi)表示所有样本集中最大xi和最小xi之间的差值,该方法也称为max-min归一化。
代码实现
这里给出了python和Matlab两种实现,二者使用的训练集一致,都使用梯度下降。在Python中使用普通代数法循环计算,Matlab中使用矩阵直接计算。
训练数据ex1data1.txt:
6.1101,17.592
5.5277,9.1302
8.5186,13.662
7.0032,11.854
5.8598,6.8233
8.3829,11.886
7.4764,4.3483
8.5781,
6.4862,6.5987
5.0546,3.8166
5.7107,3.2522
14.164,15.505
5.734,3.1551
8.4084,7.2258
5.6407,0.71618
5.3794,3.5129
6.3654,5.3048
5.1301,0.56077
6.4296,3.6518
7.0708,5.3893
6.1891,3.1386
20.27,21.767
5.4901,4.263
6.3261,5.1875
5.5649,3.0825
18.945,22.638
12.828,13.501
10.957,7.0467
13.176,14.692
22.203,24.147
5.2524,-1.22
6.5894,5.9966
9.2482,12.134
5.8918,1.8495
8.2111,6.5426
7.9334,4.5623
8.0959,4.1164
5.6063,3.3928
12.836,10.117
6.3534,5.4974
5.4069,0.55657
6.8825,3.9115
11.708,5.3854
5.7737,2.4406
7.8247,6.7318
7.0931,1.0463
5.0702,5.1337
5.8014,1.844
11.7,8.0043
5.5416,1.0179
7.5402,6.7504
5.3077,1.8396
7.4239,4.2885
7.6031,4.9981
6.3328,1.4233
6.3589,-1.4211
6.2742,2.4756
5.6397,4.6042
9.3102,3.9624
9.4536,5.4141
8.8254,5.1694
5.1793,-0.74279
21.279,17.929
14.908,12.054
18.959,17.054
7.2182,4.8852
8.2951,5.7442
10.236,7.7754
5.4994,1.0173
20.341,20.992
10.136,6.6799
7.3345,4.0259
6.0062,1.2784
7.2259,3.3411
5.0269,-2.6807
6.5479,0.29678
7.5386,3.8845
5.0365,5.7014
10.274,6.7526
5.1077,2.0576
5.7292,0.47953
5.1884,0.20421
6.3557,0.67861
9.7687,7.5435
6.5159,5.3436
8.5172,4.2415
9.1802,6.7981
6.002,0.92695
5.5204,0.152
5.0594,2.8214
5.7077,1.8451
7.6366,4.2959
5.8707,7.2029
5.3054,1.9869
8.2934,0.14454
13.394,9.0551
5.4369,0.61705
Python
from __future__ import division
import numpy as np
import random
import matplotlib.pyplot as plt def train(X, Y, iterateNum=1500, alpha=0.01):
'''
:param X:
:param Y:
:param iterateNum: 梯度下降的迭代次数
:param alpha: 学习率
:return:theta
'''
m, n = np.shape(X)
# 在第一列添加x0
X_new = np.c_[np.ones(m), X]
theta = np.zeros((n + 1, 1)) for i in range(iterateNum):
h = h_function(X_new, theta)
theta -= (alpha / m) * np.dot(X_new.T, h - Y) return theta # 计算假设函数的值
def h_function(X, theta):
'''
:param X: 训练集的特征,m * n矩阵
:param theta: θ列向量, n * 1矩阵
:return: m * 1矩阵,每一行都是假设函数的值, hθ(x)
'''
return np.dot(X, theta) def plot_datas(X, Y, theta):
# paint line g = θ0 + θ1x1
x = [5, 25]
# y = θ0 + θ1x1
y = [h_function([1, 5], theta), h_function([1, 25], theta)]
plt.plot(x, y) plt.xlabel('x')
plt.ylabel('y')
# paint scatter points
plt.scatter(X, Y, c='r', marker='x') label = ['Training data', 'Linear regression']
plt.legend(label)
plt.show() if __name__ == '__main__':
train_datas = np.loadtxt("ex1data1.txt", delimiter=',')
X = train_datas[:, [0]]
Y = train_datas[:, [1]]
theta = train(X, Y)
print(theta)
plot_datas(X, Y, theta) # [-3.6302914394043602, 1.166362350335582]
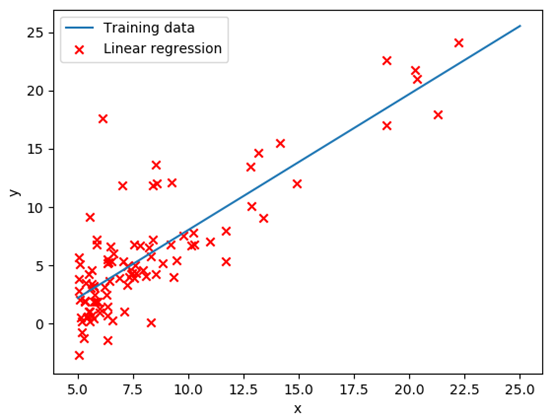
Θ = [-3.6302914394043602, 1.166362350335582]
sklearn
sklearn
from sklearn.linear_model import LinearRegression
import numpy as np if __name__ == '__main__':
train_datas = np.loadtxt("ex1data1.txt", delimiter=',')
X_train = train_datas[:,[0]]
Y_train = train_datas[:,[1]]
linear = LinearRegression()
linear.fit(X_train, Y_train) theta = [linear.intercept_[0], linear.coef_[0][0]]
print(theta)
Matlab
%% =======================Load data and Plotting =======================
fprintf('Plotting Data ...\n')
data = load('ex1data1.txt');
X = data(:, 1); y = data(:, 2);
m = length(y); % number of training examples % Plot Data
figure;
plot(x, y, 'rx', 'MarkerSize', 10);
xlabel('x');
ylabel('y'); fprintf('Program paused. Press enter to continue.\n');
pause; %% =================== Cost and Gradient descent =================== X = [ones(m, 1), data(:,1)]; % Add a column of ones to x
theta = zeros(2, 1); % initialize fitting parameters % Some gradient descent settings
iterations = 1500;
alpha = 0.01; fprintf('\nRunning Gradient Descent ...\n') % run gradient descent
theta = [0;0];
m = length(y); % number of training examples for iter = 1:num_iters
theta -= (alpha / m) * (X' * (X * theta - y));
end; % print theta to screen
fprintf('Theta found by gradient descent:\n');
fprintf('%f\n', theta); % Plot the linear fit
hold on; % keep previous plot visible
plot(X(:,2), X*theta, '-')
legend('Training data', 'Linear regression')
hold off
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公众号“我是8位的”

ML(3)——线性回归的更多相关文章
- ml的线性回归应用(python语言)
线性回归的模型是:y=theta0*x+theta1 其中theta0,theta1是我们希望得到的系数和截距. 下面是代码实例: 1. 用自定义数据来看看格式: # -*- coding:utf ...
- ML:多变量线性回归(Linear Regression with Multiple Variables)
引入额外标记 xj(i) 第i个训练样本的第j个特征 x(i) 第i个训练样本对应的列向量(column vector) m 训练样本的数量 n 样本特征的数量 假设函数(hypothesis fun ...
- JavaScript机器学习之线性回归
译者按: AI时代,不会机器学习的JavaScript开发者不是好的前端工程师. 原文: Machine Learning with JavaScript : Part 1 译者: Fundebug ...
- 大叔学ML第四:线性回归正则化
目录 基本形式 梯度下降法中应用正则化项 正规方程中应用正则化项 小试牛刀 调用类库 扩展 正则:正则是一个汉语词汇,拼音为zhèng zé,基本意思是正其礼仪法则:正规:常规:正宗等.出自<楚 ...
- 大叔学ML第二:线性回归
目录 基本形式 求解参数\(\vec\theta\) 梯度下降法 正规方程导法 调用函数库 基本形式 线性回归非常直观简洁,是一种常用的回归模型,大叔总结如下: 设有样本\(X\)形如: \[\beg ...
- ML之多元线性回归
转自:http://www.cnblogs.com/zgw21cn/archive/2009/01/07/1361287.html 1.多元线性回归模型 假定被解释变量与多个解释变量之间具有线性关系, ...
- ML 线性回归Linear Regression
线性回归 Linear Regression MOOC机器学习课程学习笔记 1 单变量线性回归Linear Regression with One Variable 1.1 模型表达Model Rep ...
- ML:单变量线性回归(Linear Regression With One Variable)
模型表达(model regression) 用于描述回归问题的标记 m 训练集(training set)中实例的数量 x 特征/输入变量 y 目标变量/输出变量 (x,y) 训练集中的实例 (x( ...
- 线性回归与梯度下降(ML作业)
Loss函数 题目一:完成computeCost.m function J = computeCost(X, y, theta) %COMPUTECOST Compute cost for linea ...
随机推荐
- ssh 免密登陆
A 要免密码登录要B 那么需要在A电脑上使用命令 ssh-keygen -t rsa 在~/.ssh/ 目录下生成id_rsa.pub 这个文件,然后将这个文件的内容拷到B电脑de ~/.ssh/au ...
- netty源码理解(一):new一个NioEventLoopGroup的时候做了哪些事
好了,回到构造方法的调用中
- Final阶段第1周/共1周 Scrum立会报告+燃尽图 07
作业要求[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2486] 版本控制:https://git.coding.net/liuyy08 ...
- linux 断网 扫描基本命令
kali使用arpspoof命令进行ARP欺骗. 做法是获取目标主机IP镜像流量,再进行ARP欺骗. 此次测试实在局域网中进行,使用kali虚拟机和Windows10物理机测试. 最终效果是利用kal ...
- 地理空间数据云--TM影像下载
实验要用到遥感影像,,TM,,之前是可以在美国USGS上下载的,但是要FQ了,有点麻烦,, 想到之前本科实在地理空间数据云平台下载的,就试了一下以前的账号,完美!,, TM数据很丰富,到2017年的都 ...
- saliency 2015-2016的论文、代码
https://github.com/ArcherFMY/Paper_Reading_List 另外2013年之前的见chengmingming的benchmark主页.
- Java单链表简单实现* @version 1.0
package com.list; /** * 数据结构与算法Java表示 * @version 1.0 * @author 小明 * */ public class MyLinkedList { p ...
- 无根树同构_hash
先贴上地址 https://vjudge.net/problem/HDU-5732 判断有根树同构: 1. 直接用括号最小表示法 2. 利用括号最小表示法的思想进行hash 判断无根树同构: 1. 找 ...
- SEO : 建站注意
1.url格式.尽可能的短一些,实践证明,较短的url格式还是比较利于搜索引擎收录的. 2.网站前台要纯静态.虽然搜索引擎对静态页面和动态页面并没有本质上的差别对待,但是实践告诉我们静态页面对服务器的 ...
- get新技能:上传了 flv 或 MP4 文件到服务器,可访问总是出现 “无法找到该页”的 404 错误
为什么我上传了 flv 或 MP4 文件到服务器,可访问总是出现 “无法找到该页”的 404 错误 为什么我上传了 flv 或 MP4 文件到服务器,可输入正确地址通过协议来访问总是出现 “无法找到该 ...