【ZZ】详解哈希表的查找
详解哈希表的查找
https://mp.weixin.qq.com/s/j2j9gS62L-mmOH4p89OTKQ
详解哈希表的查找
来自:静默虚空
http://www.cnblogs.com/jingmoxukong/p/4332252.html
哈希表和哈希函数
在记录的存储位置和它的关键字之间是建立一个确定的对应关系(映射函数),使每个关键字和一个存储位置能唯一对应。
这个映射函数称为哈希函数,根据这个原则建立的表称为哈希表(Hash Table),也叫散列表。
以上描述,如果通过数学形式来描述就是:
若查找关键字为 key,则其值存放在 f(key) 的存储位置上。由此,不需比较便可直接取得所查记录。
注:哈希查找与线性表查找和树表查找最大的区别在于,不用数值比较。
冲突
若 key1 ≠ key2 ,而 f(key1) = f(key2),这种情况称为冲突(Collision)。
根据哈希函数f(key)和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这一映射过程称为构造哈希表。
构造哈希表这个场景就像汽车找停车位,如果车位被人占了,只能找空的地方停。
构造哈希表
由以上内容可知,哈希查找本身其实不费吹灰之力,问题的关键在于如何构造哈希表和处理冲突。
常见的构造哈希表的方法有 5 种:
(1)直接定址法
说白了,就是小学时学过的一元一次方程。
即 f(key) = a * key + b。其中,a和b 是常数。
(2)数字分析法
假设关键字是R进制数(如十进制)。并且哈希表中可能出现的关键字都是事先知道的,则可选取关键字的若干数位组成哈希地址。
选取的原则是使得到的哈希地址尽量避免冲突,即所选数位上的数字尽可能是随机的。
(3)平方取中法
取关键字平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,仅取其中的几位为地址不一定合适;
而一个数平方后的中间几位数和数的每一位都相关, 由此得到的哈希地址随机性更大。取的位数由表长决定。
(4)除留余数法
取关键字被某个不大于哈希表表长 m 的数 p 除后所得的余数为哈希地址。
即 f(key) = key % p (p ≤ m)
这是一种最简单、最常用的方法,它不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。
注意:p的选择很重要,如果选的不好,容易产生冲突。根据经验,一般情况下可以选p为素数。
(5)随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即 f(key) = random(key)。
通常,在关键字长度不等时采用此法构造哈希函数较为恰当。
解决冲突
设计合理的哈希函数可以减少冲突,但不能完全避免冲突。
所以需要有解决冲突的方法,常见有两类
(1)开放定址法
如果两个数据元素的哈希值相同,则在哈希表中为后插入的数据元素另外选择一个表项。
当程序查找哈希表时,如果没有在第一个对应的哈希表项中找到符合查找要求的数据元素,程序就会继续往后查找,直到找到一个符合查找要求的数据元素,或者遇到一个空的表项。
例子
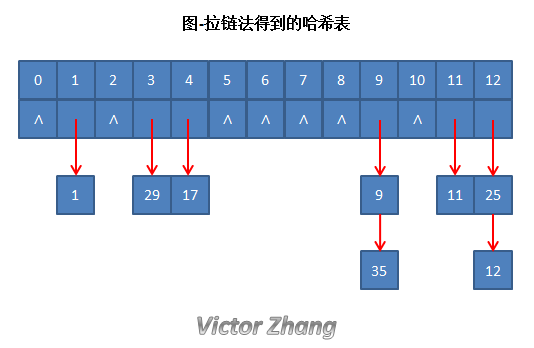
若要将一组关键字序列 {1, 9, 25, 11, 12, 35, 17, 29} 存放到哈希表中。
采用除留余数法构造哈希表;采用开放定址法处理冲突。
不妨设选取的p和m为13,由 f(key) = key % 13 可以得到下表。


需要注意的是,在上图中有两个关键字的探查次数为 2 ,其他都是1。
这个过程是这样的:
a. 12 % 13 结果是12,而它的前面有个 25 ,25 % 13 也是12,存在冲突。
我们使用开放定址法 (12 + 1) % 13 = 0,没有冲突,完成。
b. 35 % 13 结果是 9,而它的前面有个 9,9 % 13也是 9,存在冲突。
我们使用开放定址法 (9 + 1) % 13 = 10,没有冲突,完成。
(2)拉链法
将哈希值相同的数据元素存放在一个链表中,在查找哈希表的过程中,当查找到这个链表时,必须采用线性查找方法。
在这种方法中,哈希表中每个单元存放的不再是记录本身,而是相应同义词单链表的头指针。
例子
如果对开放定址法例子中提到的序列使用拉链法,得到的结果如下图所示:
实现一个哈希表
假设要实现一个哈希表,要求
a. 哈希函数采用除留余数法,即 f(key) = key % p (p ≤ m)
b. 解决冲突采用开放定址法,即 f2(key) = (f(key)+i) % size (p ≤ m)
(1)定义哈希表的数据结构
class HashTable {
public int key = 0; // 关键字
public int data = 0; // 数值
public int count = 0; // 探查次数
}
(2)在哈希表中查找关键字key
根据设定的哈希函数,计算哈希地址。如果出现地址冲突,则按设定的处理冲突的方法寻找下一个地址。
如此反复,直到不冲突为止(查找成功)或某个地址为空(查找失败)。
/**
* 查找哈希表
* 构造哈希表采用除留取余法,即f(key) = key mod p (p ≤ size)
* 解决冲突采用开放定址法,即f2(key) = (f(key) + i) mod p (1 ≤ i ≤ size-1)
* ha为哈希表,p为模,size为哈希表大小,key为要查找的关键字
*/
public int searchHashTable(HashTable[] ha, int p, int size, int key) {
int addr = key % p; // 采用除留取余法找哈希地址
// 若发生冲突,用开放定址法找下一个哈希地址
while (ha[addr].key != NULLKEY && ha[addr].key != key) {
addr = (addr + 1) % size;
}
if (ha[addr].key == key) {
return addr; // 查找成功
} else {
return FAILED; // 查找失败
}
}
(3)删除关键字为key的记录
在采用开放定址法处理冲突的哈希表上执行删除操作,只能在被删记录上做删除标记,而不能真正删除记录。
找到要删除的记录,将关键字置为删除标记DELKEY。
public int deleteHashTable(HashTable[] ha, int p, int size, int key) {
int addr = 0;
addr = searchHashTable(ha, p, size, key);
if (FAILED != addr) { // 找到记录
ha[addr].key = DELKEY; // 将该位置的关键字置为DELKEY
return SUCCESS;
} else {
return NULLKEY; // 查找不到记录,直接返回NULLKEY
}
}
(4)插入关键字为key的记录
将待插入的关键字key插入哈希表
先调用查找算法,若在表中找到待插入的关键字,则插入失败;
若在表中找到一个开放地址,则将待插入的结点插入到其中,则插入成功。
public void insertHashTable(HashTable[] ha, int p, int size, int key) {
int i = 1;
int addr = 0;
addr = key % p; // 通过哈希函数获取哈希地址
if (ha[addr].key == NULLKEY || ha[addr].key == DELKEY) { // 如果没有冲突,直接插入
ha[addr].key = key;
ha[addr].count = 1;
} else { // 如果有冲突,使用开放定址法处理冲突
do {
addr = (addr + 1) % size; // 寻找下一个哈希地址
i++;
} while (ha[addr].key != NULLKEY && ha[addr].key != DELKEY);
ha[addr].key = key;
ha[addr].count = i;
}
}
(5)建立哈希表
先将哈希表中各关键字清空,使其地址为开放的,然后调用插入算法将给定的关键字序列依次插入。
public void createHashTable(HashTable[] ha, int[] list, int p, int size) {
int i = 0;
// 将哈希表中的所有关键字清空
for (i = 0; i < ha.length; i++) {
ha[i].key = NULLKEY;
ha[i].count = 0;
}
// 将关键字序列依次插入哈希表中
for (i = 0; i < list.length; i++) {
this.insertHashTable(ha, p, size, list[i]);
}
}
完整代码
class HashTable {
public int key = 0; // 关键字
public int data = 0; // 数值
public int count = 0; // 探查次数
}
public class HashSearch {
private final static int MAXSIZE = 20;
private final static int NULLKEY = 1;
private final static int DELKEY = 2;
private final static int SUCCESS = 0;
private final static int FAILED = 0xFFFFFFFF;
/**
* 查找哈希表
* 构造哈希表采用除留取余法,即f(key) = key mod p (p ≤ size)
* 解决冲突采用开放定址法,即f2(key) = (f(key) + i) mod p (1 ≤ i ≤ size-1)
* ha为哈希表,p为模,size为哈希表大小,key为要查找的关键字
*/
public int searchHashTable(HashTable[] ha, int p, int size, int key) {
int addr = key % p; // 采用除留取余法找哈希地址
// 若发生冲突,用开放定址法找下一个哈希地址
while (ha[addr].key != NULLKEY && ha[addr].key != key) {
addr = (addr + 1) % size;
}
if (ha[addr].key == key) {
return addr; // 查找成功
} else {
return FAILED; // 查找失败
}
}
/**
* 删除哈希表中关键字为key的记录
* 找到要删除的记录,将关键字置为删除标记DELKEY
*/
public int deleteHashTable(HashTable[] ha, int p, int size, int key) {
int addr = 0;
addr = searchHashTable(ha, p, size, key);
if (FAILED != addr) { // 找到记录
ha[addr].key = DELKEY; // 将该位置的关键字置为DELKEY
return SUCCESS;
} else {
return NULLKEY; // 查找不到记录,直接返回NULLKEY
}
}
/**
* 将待插入的关键字key插入哈希表
* 先调用查找算法,若在表中找到待插入的关键字,则插入失败;
* 若在表中找到一个开放地址,则将待插入的结点插入到其中,则插入成功。
*/
public void insertHashTable(HashTable[] ha, int p, int size, int key) {
int i = 1;
int addr = 0;
addr = key % p; // 通过哈希函数获取哈希地址
if (ha[addr].key == NULLKEY || ha[addr].key == DELKEY) { // 如果没有冲突,直接插入
ha[addr].key = key;
ha[addr].count = 1;
} else { // 如果有冲突,使用开放定址法处理冲突
do {
addr = (addr + 1) % size; // 寻找下一个哈希地址
i++;
} while (ha[addr].key != NULLKEY && ha[addr].key != DELKEY);
ha[addr].key = key;
ha[addr].count = i;
}
}
/**
* 创建哈希表
* 先将哈希表中各关键字清空,使其地址为开放的,然后调用插入算法将给定的关键字序列依次插入。
*/
public void createHashTable(HashTable[] ha, int[] list, int p, int size) {
int i = 0
// 将哈希表中的所有关键字清空
for (i = 0; i < ha.length; i++) {
ha[i].key = NULLKEY;
ha[i].count = 0;
}
// 将关键字序列依次插入哈希表中
for (i = 0; i < list.length; i++) {
this.insertHashTable(ha, p, size, list[i]);
}
}
/**
* 输出哈希表
*/
public void displayHashTable(HashTable[] ha) {
int i = 0;
System.out.format("pos: ", "pos");
for (i = 0; i < ha.length; i++) {
System.out.format("%4d", i);
}
System.out.println();
System.out.format("key: ");
for (i = 0; i < ha.length; i++) {
if (ha[i].key != NULLKEY) {
System.out.format("%4d", ha[i].key);
} else {
System.out.format(" ");
}
}
System.out.println();
System.out.format("count: ");
for (i = 0; i < ha.length; i++) {
if (0 != ha[i].count) {
System.out.format("%4d", ha[i].count);
} else {
System.out.format(" ");
}
}
System.out.println();
}
public static void main(String[] args) {
int[] list = { 3, 112, 245, 27, 44, 19, 76, 29, 90 };
HashTable[] ha = new HashTable[MAXSIZE];
for (int i = 0; i < ha.length; i++) {
ha[i] = new HashTable();
}
HashSearch search = new HashSearch();
search.createHashTable(ha, list, 19, MAXSIZE);
search.displayHashTable(ha);
}
}
参考资料
《数据结构习题与解析》(B级第3版)
【ZZ】详解哈希表的查找的更多相关文章
- 小甲鱼PE详解之输入表(导出表)详解(PE详解09)
小甲鱼PE详解之输出表(导出表)详解(PE详解09) 当PE 文件被执行的时候,Windows 加载器将文件装入内存并将导入表(Export Table) 登记的动态链接库(一般是DLL 格式)文件一 ...
- [LeetCode] #1# Two Sum : 数组/哈希表/二分查找/双指针
一. 题目 1. Two SumTotal Accepted: 241484 Total Submissions: 1005339 Difficulty: Easy Given an array of ...
- zz详解深度学习中的Normalization,BN/LN/WN
详解深度学习中的Normalization,BN/LN/WN 讲得是相当之透彻清晰了 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Ba ...
- 小甲鱼PE详解之输入表(导入表)详解(PE详解07)
捷径并不是把弯路改直了,而是帮你把岔道堵上! 走得弯路跟成长的速度是成正比的!不要害怕走上弯路,弯路会让你懂得更多,最终还是会在终点交汇! 岔路会将你引入万劫不复的深渊,并越走越深…… 在开始讲解输入 ...
- 详解MySQL大表优化方案( 转)
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- 详解MySQL大表优化方案
单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型值为主的表在千万级以下,字符串为主的表在五百万以下是没有太大问题的.而事实上很多时 ...
- linux shell 字符串操作详解(获取长度、查找,替换)
在做shell批处理程序时候,常常会涉及到字符串相关操作.有许多命令语句,如:awk,sed都能够做字符串各种操作. 事实上shell内置一系列操作符号,能够达到相似效果,大家知道,使用内部操作符会省 ...
- 详解Windows注册表分析取证
大多数都知道windows系统中有个叫注册表的东西,但却很少有人会去深入的了解它的作用以及如何对它进行操作.然而对于计算机取证人员来说注册表无疑是块巨大的宝藏.通过注册表取证人员能分析出系统发生了什么 ...
- 小甲鱼PE详解之输入表(导入表)详解2(PE详解08)
在此之前,我们已经对这个输入表进行了一些实践和理解,这有助于大家对这个概念更进一步的加深认识.小甲鱼觉得,越是复杂的问题我们应该越是去动手操作它,认识它,这样才容易熟悉它! 在上一节课我们像小鹿一样的 ...
随机推荐
- js中将一个字一个字的打印出来
第一种方式: setTimeout(function(){ var cc=document.createTextNode(ss[i]) content.appendChild(cc) },3000)
- @PropertySouce注解
1.@ProtertySource @PropertySouce是spring3.1开始引入的基于java config的注解. 通过@PropertySource注解将properties配置文件中 ...
- nginx日志格式配置
我一向对日志这个东西有些许恐惧,因为在分析日志是需要记住不同服务器日志的格式,就拿提取ip这一项来说,有的服务器日志是在第一列,有的是第二列或则第三列等等.知道今天我才发现,日志格式是可以自定义配置的 ...
- 系统限制和选项limit(一)
从shell中获取系统限制和选项 终端输入getconf value [pathname] [root@bogon code]# getconf ARG_MAX 2097152 [root@bogon ...
- Full Schema Stitching with Apollo Server
转自: https://tomasalabes.me/blog/nodejs/graphql/apollo/2018/09/18/schema-stitiching-apollo.html Full ...
- Java各个知识点详解总结
Java基础知识总结 写代码: 1,明确需求.我要做什么? 2,分析思路.我要怎么做?1,2,3. 3,确定步骤.每一个思路部分用到哪些语句,方法,和对象. 4,代码实现.用具体的java语言代码把思 ...
- 求两个数的平均值,不能只用(a+b)/2的方法
#include<stdio.h> int avg1(int a, int b) { //利用移位操作符 //右移移位相当于——>除以2 :(a+b)>>1 //考虑到溢 ...
- MySQL联结查询和组合查询
联结查询 1.关系表 主键:一列或一组列,能够唯一区分表中的每一行,用来表示一个特定的行 外键:为某个表中的一列,包含另一个表的主键,定义量表的关系. 2.创建联结 规定要连接的表和他们如何关联即可 ...
- 关联本地文件夹到 GitLab 项目
关联本地文件夹到 GitLab 项目的 dev 分支: rm -rf .git git init git remote add origin git pull git checkout dev git ...
- 安装Redis的PHP扩展
1.安装phpize(php如果升级到php7,这步会报错,报错参考:https://www.cnblogs.com/clubs/p/10091103.html) yum install php-de ...