dRMT: Disaggregated Programmable Switching, SIGCOMM17
Reference:
今年的SIGCOMM17会议上,Cisco System和MIT的团队针对RMT模型现有的问题,合作发表了这篇"dRMT: Disaggregated Programmable Switching",从芯片方面推近了可编程数据平面领域的发展。本次SIGCOMM17会议上,数据平面可编程领域再次成为焦点,具体内容可以参考:
dRMT: Disaggregated Programmable Switching, SIGCOMM 2017
简评:
1.将disaggregated的思想与RMT模型相结合:
- 内存的非集计化使内存和处理器位置解耦,提升了硬件资源的利用率;
- 计算资源的非集计化使match/action操作能够按照任意的顺序进行,支持多包同时并发处理,提升系统吞吐量(>=RMT Throughput)。
2.通过处理器插入空操作的机制,满足了程序、架构限制的基础,简化了dRMT的调度机制,保证了确定性的性能。
3.将程序依赖和硬件限制作为约束条件,给定调度目标,进行ILP线性规划,来模拟并简化dRMT的调度过程。
4.进行了以下的实验验证:
- 1.用四个P4程序来对比两个架构分别在不同情况下,维持线速所需要的最小处理器数和进程数;
- 使用100个随机生成的操作依赖图ODG进行大规模的对比;
- 在减少处理器数目的情况下,对比吞吐量下降情况,以证明dRMT避免了性能坠崖;
- 报告了dRMT ILP线性规划程序的运行时间(run-times),表明其调度时间随着处理器的增多而大幅减小。
引言
高速的交换芯片的架构大多为一个由许多阶段组成的pipeline,对于一个需要处理的数据报,每一个阶段会做以下三个阶段的工作:
- 解析特定的数据报首部位,以生成match key;
- 在一张match-action流表中查找这个key;
- 使用匹配之后的结果执行一个动作。
近年来,出现的可编程交换机架构支持使用网络编程语言,比如P4来对交换机内部pipeline进行编程。
用于可编程交换机的经典芯片架构是SIGCOMM13提出的RMT(Reconfigurable Match-Action Table):使用了由许多stage组成的pipeline,每一个stage都是可编程的。RMT pipeline的stage包含三种硬件资源:
- 用于从match key中解析首部位的匹配单元;
- 在本地内存集群中的流表内存;
- 可以修改数据报首部的可编程动作单元。
但是,RMT架构有两个很关键的缺点:
1.资源利用率低:每一个pipeline的阶段只能访问它本地的内存资源,当一张流表没有在运行时使用的时候,它的资源白瞎了。
2.hard wired:RMT的流水只能按照固定的顺序,即匹配 => 动作来操作,在匹配和地址操作不平衡的情况下导致了物理资源利用率的降低。举个例子,此时一张流表做L3转发,只需要将IPv4的TTL-1,那么不需要经过任何的匹配操作,浪费了匹配和流表的内存。
于是乎,本篇论文提出了dRMT模型,dRMT全称为:disaggregated Reconfigurable Match-Action Table,是一种用于可编程交换机的新架构。dRMT旨在解决上述RMT模型的两个问题:
- 流表的内存局限于RMT pipeline阶段(stage)的位置,一个RMT阶段所使用的内存无法被其他阶段所使用;
- RMT是hard-wired的模型,当处理数据报时只能够按顺序执行匹配-动作。
dRMT通过将内存和计算资源非集计化(Disaggregated),解决了上述两个问题:
- 将流表的内存集中为一个统一的资源池,运行时交换机通过crossbar访问这个资源池以获取流表信息;
- 用一些处理器(processors)取代原RMT模型中的阶段,并能够按任意顺序执行匹配和动作操作。当数据报来到交换机时,进入一个dRMT的处理器进行全部流水的处理。
RMT:
Rx NIC => parser => stage1 => stage2 => ... => stageN => deparser => queues => Tx NIC
dRMT:
Rx NIC => parser => distributer => processor => deparser => queues => Rx NIC
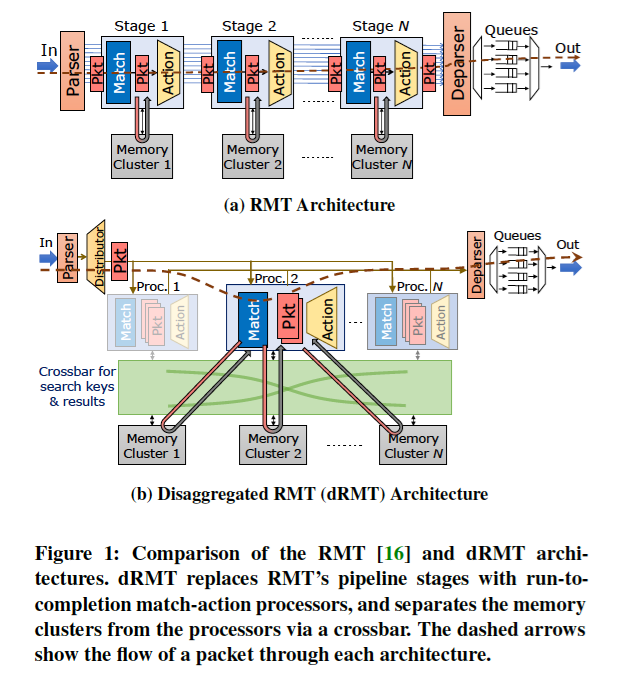
内存和计算资源的非集计化提供了非常高的灵活性。首先,内存的非集计化将内存与流表的位置相解耦来进行match-action;其次,计算的非集计化使match/action操作能够按照任意的顺序进行;最后,计算资源的非集计化支持包的并发处理,每一个处理器都能够同时处理多包。
dRMT run-to-completion的数据报处理模型已被先前的一些网络处理器使用了,但是这些处理器并没有保证确定性(deterministic)的数据报吞吐量和时延。在网络节点上有很多原因会产生非确定性,比如cache未命中和内部连接,处理器-内存的冲突。dRMT中通过一个特定的调度算法在编译时计算出一种静态的调度,避免了冲突的发生从而保证了高吞吐和低时延。
本篇论文通过四个分支P4程序(三个来自switch.p4,一个专利程序)对dRMT进行验证,结果表明为取得线速(每一个时钟周期处理一个数据报),相比RMT需要的处理器数目,dRMT需要的处理器数目减少了4.5%、16%、41%以及50%。同时,使用了100个随机生成的、与switch.p4有相同特征的P4程序进行了测试,dRMT减少了用于实现线速吞吐量的处理器数目(10%-30%)。进一步的实验表明,在更少处理器的情况下,dRMT的吞吐量平缓地(gracefully)下降,而RMT的性能就像掉下悬崖(falls off a cliff)一般锐减。
本篇论文展示了dRMT的硬件设计,并对它的可行性和芯片区域的开销进行了分析,dRMT的芯片区域开销主要有以下两个部分:
- 实现了crossbar;
- 实现了存储并执行完整P4程序的处理器。
并表明了架构的操作权衡了适当的限制,以实现低开销;虽然本文的作者们截稿时还未实现一个基于dRMT的芯片,但是分析表明在芯片上使用相同的处理器的情况下,实现dRMT是可行的;dRMT的拓展性受限于crossbar的写复杂性,对于超过32个处理器的拓展而言会有困难,但是好在现有的交换机芯片不大可能需要超过32处理器的场景,dRMT足以支撑现有的交换机芯片的要求。
非集计化的用例
内存非集计化
RMT:每一个阶段只能访问本地内存集群,导致问题:
- 每一个阶段都需要执行对match-action操作的选择;
需要阶段间的匹配-动作操作调度,影响程序依赖关系。 - 将程序的流表放在内存集群中。
dRMT通过允许所有的处理器通过crossbar访问所有的内存集群解决了这些问题,有以下的优点:
(1)提升了硬件的利用率,使映射操作更加灵活,流表到硬件资源的配置更加高效;
第一个例子是并行的搜寻(Parallel searches):如果有一些流表的search key能够在一个RMT阶段被解析,但是这些流表的总大小超过了一个内存集群的大小,就必须将它们放置在不同的阶段,这样会导致内存的利用率降低;dRMT通过非集计化内存资源,支持在一个处理器上对这些流表的match key进行并行解析,并将这些match key通过crossbar送到存放流表的内存位置。
第二个例子是大型流表(Large table):一张大型流表可能无法完全放在一个本地内存集群,会需要跨不同的阶段;在RMT模型中,每一个阶段都必须搜寻这张大型流表的一部分,需要多次解析同样的key,并且这些阶段的匹配阶段必须整合起来,该流表的动作阶段必须在存放该流表的最后一个阶段执行,导致所有存放该流表阶段的前驱阶段的动作单元都被浪费了;在dRMT模型中,crossbar能够将search key分发(multicast)到多个内存的集群,并发处理这张流表的各个搜寻部分,在返回路径上通过一个小规模的结果整合逻辑把具有最高优先级的匹配结果从内存集群的位置送回处理器。
(2)独立地拓展处理/内存的能力;
内存非集计化使处理器的数目和内存集群的数目互相解耦,能够基于程序的类型进行选择。往dRMT的内存集群中加入一块新的TCAM,在处理器处理的时候就能够通过crossbar的分发能力将这块新的TCAM分配到任意的流表,从而提升内存的能力;相反的是,如果往RMT的某一个阶段上增加内存,是无法起到相同的效果的。
(3)简单的编译;
一个RMT编译器必须根据程序操作之间的依赖关系,合理地在多个流水阶段放置流表;而一个dRMT编译器只需要解决两个简单的问题:1.将流表打包(packing)至内存的集群,这通过简单的二进制打包就能够做到;2.调度处理器的操作。dRMT的一个重要性质是这两个问题之间是解耦的,流表在内存中的安置方法是独立于操作调度的,反之亦然(vice versa)。这些使得将程序编译到dRMT更加简单。
当然这些优点不局限于dRMT模型,同样也能够往RMT模型中加入一个crossbar做到:将所有的阶段连接到所有的内存单元。但是dRMT进一步地将计算资源进行非集计化,本篇论文的结论展示了计算资源非集计化对于发掘全部非集计化潜力的重要性。
计算非集计化
RMT架构实现了一个硬性的匹配后动作(match-then-action)的序列。而在dRMT中,在遵守依赖关系好资源限制的情况下,一个处理器在对数据报进行处理时能够以任意顺序交叉存取匹配和动作操作。有以下优点:
(1)提升了资源的利用率;
计算非集计化进一步提升了操作顺序的灵活性,同时最大化了资源利用率。本文通过一张图(给出了程序的依赖关系)说明了该优点:
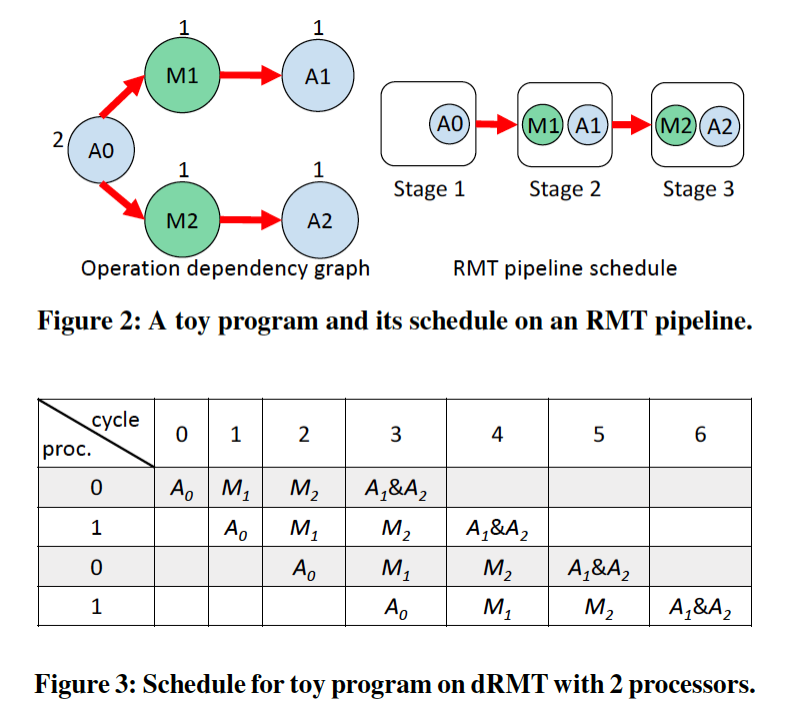
RMT架构实现了一个硬性的匹配后动作(match-then-action)的序列。而在dRMT中,在遵守依赖关系好资源限制的情况下,一个处理器在对数据报进行处理时能够以任意顺序交叉存取匹配和动作操作。有以下优点:
(1)提升了资源的利用率;
计算非集计化进一步提升了操作顺序的灵活性,同时最大化了资源利用率。本文通过一张图(通过DAG, Directed Acyclic Graph给出了程序的依赖关系)说明了该优点:
假设每一条边在边的操作之间要求一个时钟周期的最小时延,节点上的数字代表了它们匹配、动作的资源要求。在RMT和dRMT模型上运行该DAG,假设在这两个模型的每一个阶段/处理器上,每一个时钟周期都能够实现一次匹配和两次动作。
在RMT模型,因为其并不高效的匹配能力,这个DAG需要至少三个RMT阶段(图2),该调度的主要问题在于滞留(stranded)在第一个阶段的匹配单元。如图3所示,dRMT模型能够在只使用两个处理器的情况下调度同样的程序。注意,数据报是以循环的顺序发往处理器的:在时钟周期k抵达的数据报会在处理器k mod 2上进行处理;此外,每一个处理器上的操作不会超过每一个时钟周期一次匹配、两次操作的能力限制。
(2)避免性能坠崖(eliminating performance cliffs):
数据报交换的ASIC芯片会有一条数据报回流(recirculation)的路径,在数据报处理在经过一次流水还没有结束时将数据报送回开始的地方(会与新进来的数据报相混杂)。在流水线架构中,如果一个特殊的程序无法在适配可用的匹配-动作阶段的情况下被调度,可能就会将这个程序划分为多次流水passes,K-pass数据报调度的速率是系统最大速率的的1/K。
相比之下,基于dRMT模型,当程序复杂度升高,吞吐量是平稳下降的。比如,如果一个RMT系统能够在线速(一个时钟周期处理一个数据报)下支持M张流表的搜索,它就可能支持这样的一种程序:需要在接近每个时钟周期处理M/M‘个数据报(M'>M)速率的情况下支持M'张流表的搜索;只需要简单地需要增加数据报在处理器中的时间和降低数据报送往处理器的速率。
用于提升确定性的性能(deteministic performance)的调度
接下来的章节描述了dRMT的调度问题,并开发了一种调度的技术以在dRMT硬件上高效地执行一个P4程序,同时保证了确定性(deterministic)的吞吐量和时延。具体来说,给定一个P4程序,在编译时预计算一个满足以下两个依赖的固定调度:(1)P4程序特定的依赖;(2)dRMT架构的资源限制。本篇论文所提出的公式中一个重要的方面在于,相同的调度总是以轮询调度的方式在处理器之间重复,这大幅简化了问题,并且减小了调度所使用的空间,而这些调度是我们必须搜索的;此外,它引起了一个我们的调度所必须满足的、独立的循环依赖集。
调度问题
首先介绍P4程序依赖关系的约束和dRMT架构的约束,接着是在这两个约束下调度的操作问题,并在定义之后阐述了一个样例。
程序依赖:
每一个进入dRMT的数据报都需要遵循P4程序指定的流控制程序,这个程序指明了数据报的处理过程。使用操作依赖图(ODG, Operation Dependency Graph)来表明程序的依赖关系:
- 节点代表匹配和动作;
- 边代表节点间的依赖关系,后续的节点的执行依赖于前一个节点的执行;
- 边权代表两个节点操作间的最小时延,等于先前节点的操作完成时间。
对于基于情况执行的操作(依赖于前一个节点的执行情况,比如table miss)来说,虽然在运行时只会执行其中一条情况分支,但这里假设两种情况的分支都同时执行和调度,以模拟最差的情况来简化调度的问题。
例3.1:图4a描述了一个简单P4程序的流控制程序,支持单播和多播路由;图4b描述了对应的ODG。
ODG类似于TDG(Table Dependency Graph),但是更加简单(简单地采用了时延作为边权)。
架构限制:
1.处理器。dRMT架构包含N个处理器,每一个时钟周期每一个处理器都要进行以下的步骤来处理数据报:
- 进行流表匹配;
- 进行动作操作;
- no-op。
每一个流表匹配需要ΔM个时钟周期,每一个动作需要ΔA个时钟周期。每一个时钟周期中,当决定进行何种操作时,处理器:
(1)能够启动M'次并行的流表查询,每次查询的key的宽度上限是b位;举个例子,在M'>=3的情况下,处理器发送三个并行的向量,每个向量为b位,并使用一个大小为2.5*b (M'*b>2.5*b)的key查询一张流表;
(2)能够同时修改上限为A‘的动作字段;
(3)最多只能够同时匹配/动作操作IPC(Inter-Packet Concurrency)个不同的数据报,进行匹配的数据报集合不等于进行动作的数据报集合。
2.内存访问:每一个时钟周期,一张P4流表(及其对应的内存集群)只能够被来自一个处理器的一个数据报访问。
3.Crossbar:每一个时钟周期,上述的限制表明了每一个处理器最多只能生成M'个b位宽的key用于流表查找,并通过crossbar进行内存访问;crossbar支持多播(multicast)。

固定的调度:
在给出一个P4程序和dRMT框架的时候,需要先找到一个固定的调度(在编译时决定了数据报的所有类型)。
特别地,假设有N个处理器,每个新抵达的数据报以轮询机制找到一个对应的处理器,每个处理器经过每P个时钟周期接收一个新的数据报,那么这个处理器每个时钟周期处理1/P个数据报,交换机的吞吐量就是N/P(当N=P的时候,代表交换机每个时钟周期接收一个新的数据报,意味着线速line-rate)。
接着需要确定一个固定的调度,也就是一个时钟周期接着一个时钟周期的调度;举个例子,在线速的情况下(N=P),处理器0在时钟周期t执行的处理动作,与处理器1在时钟周期t+1的处理动作一样,与处理器2在时钟周期t+2的处理动作一样,等等,直到时钟周期t+P时,处理器0又执行了一遍相同的操作。
例3.2:参考图4c,在原有的固化调度情况下,违反了两个架构的限制:(1) IPC=1,对于处理器0,第一个数据报和第三个数据报在时钟周期2下同时被调度(2>IPC),(2)M'=2,但是时钟周期2时进行了四张流表的并行查询(4>M')。解决方法的思路就是在冲突的时钟周期中插入空操作no-op,虽然增加了处理时延,但是满足了所有的依赖限制,如图4d所示。
给定一个有N个处理器的dRMT架构和一个P4程序,通用的目标是最大化dRMT的吞吐量。在编译时采用了一个最优的子程序(sub-routine)来指明在P4程序依赖和架构限制下的吞吐量是否合适,接着在二分查找程序中使用这个子程序来建立最大的吞吐量。
此外,给定一个任意的dRMT吞吐量,需要最小化所需的系统资源,特别是每一个处理器需要处理的数据报数目,来支持该吞吐量。
- T := 调度的固定数据报时延
- P := 接收一个新的数据报所用的时钟周期
- 每一个处理器支持的最大并发数据报数目 := T/P
调度目标:

简化dRMT的调度
在建立了调度目标之后,介绍如何简化一个单处理器以及单数据报单处理器情况下dRMT的调度问题。
单处理器调度。调度dRMT时,应该考虑单处理器的情况而不是调度所有的处理器。具体来说,如果一个单处理器的固定调度满足上述限制(程序依赖、M'、A'以及IPC),且被所有的处理器以相同的行为所采用,那么我们称之为一个合法的dRMT调度。特别地,在存取内存集群的时候,它是不会和其他处理器冲突的。
观察1:考虑一个应用在所有处理器上的单处理器调度,它是不存在内存冲突的;也就是说,同一个时钟周期中,所有来自不同的处理器的匹配请求会被引导到不同的内存。
原因:
- 1.所有数据报都是在不同的时钟周期到达交换机的;
- 2.调度是固定的,数据报访问内存的时钟周期也是固定的;
- 3.ODG是非循环的,每个数据报最多只会访问某一特定内存一次;
- 4.调度满足ODG的依赖限制。
观察一的推论:dRMT实现了比RMT更高的吞吐量。
直观地来看,考虑一个RMT流水的操作序列,该序列也可以以相同的顺序用于每一个dRMT的处理器上(译者:设原RMT流水的吞吐量是T,dRMT的处理器数目是N,那么dRMT的吞吐量是N*T)。很明显,如果这个dRMT的处理器和一个RMT阶段有一样的M'和A'能力,那么该调度就会遵守程序特定的依赖限制和M'、A'以及IPC的架构限制,因此它是一个dRMT的合法调度。
定理3.3:基于dRMT架构,一个程序的吞吐量大于等于基于RMT架构的吞吐量。
单数据报调度。正如上文所述,一个固化的调度以相同的顺序对来访的数据报进行相同的操作处理,一个给定的处理器每P个间隔(slots)接收数据报。考虑一个在时间t抵达的数据报,在这个时候,处理器会同时执行:用于该数据报的操作集0、用于在时间t-P抵达的数据报的操作集P、用于在时间t-2P抵达的数据报的操作集2P,等等。这些同时执行的集合对应于第一个数据报在每一个时钟周期执行的操作集t mod P,原因是第一个数据报也会在t+P的时候执行集合P,在t+2P的时候执行集合2P,等等。因此,比起分析不同数据报如何共享处理器的资源来说,分析单个数据报的所有操作更加有效。
例3.4(单数据报调度):
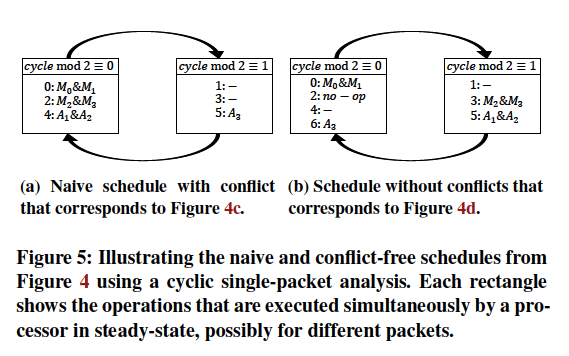
图5展示了图4c和4d的单数据报调度,每一个矩形代表一个同时执行的操作集;图5a对应于图4c,这样的调度违反了两个架构的限制:(1) IPC=1,同时调度两个数据报(2>IPC) (注:体现在cycle mod 2 = 0的矩形中,操作0和操作2表明同时对两个数据报进行处理),(2)M'=2,但是进行了四张流表的并行查询(4>M')。
为了建立满足M'、A'以及IPC架构限制的单数据报调度,我们可以将这些限制转换为循环型的限制,也就是说,在单数据报调度序列上进行限制 mod P。特别地,我们定义了P个等价类,对应于调度的时期长度,并依赖于以下的观察:
观察2:构造一个合法的单处理器调度,相当于在ODG中指定每一个匹配和动作的操作至一个等价类中(注:每一个等价类中所有的操作均互不冲突),同时保证对每一个等价类操作的要求不会违背架构的限制,也就是M',A'和IPC。
通过考虑每一个等价类中的所有操作,可以直接判断M'、A'的限制是否被满足。但是验证IPC的限制还需要另外一个额外的观察结论:
观察3(数据报分类):一个处理器在时钟周期t时所操作(开始匹配/动作操作)的不同数据报的数量,等于在等价类 t mod P (当执行开始次数被P划分时,所有具有相同余数的节点组合的类) 中匹配/动作节点不同的执行次数。
使用上述观察,我们能够得到以下结论:
定理3.5:单数据报的调度是合法的,当且仅当整个dRMT的调度是合法的。
整数线性问题(integer linear program)
本篇论文通过将dRMT的限制、调度目标进行整数线性规划形式的数学建模,得到以下结论:
定理3.6:dRMT的调度问题是NP-hard的问题。
具体细节参考论文表述。
实验验证
在数据报处理程序方面,我们使用了两个度量来比较RMT和dRMT:(1)需要维持线速(每时钟周期处理一个数据报)的最小处理器数量;(2)需要维持每时钟周期处理一个数据报的最小进程数。对于固定的吞吐量,即每个时钟周期一个数据报而言,在处理器之间的所有进程数等同于程序的时延。
实验验证部分由四个部分组成:
- 用四个P4程序来对比两个架构;
- 使用100个随机生成的操作依赖图ODG对比两个架构;
- 在减少处理器数目的情况下,对比吞吐量下降情况,以证明dRMT避免了性能坠崖;
- 通过报告dRMT ILP的运行时间(run-times)进行总结。
设置
我们对以下四个架构进行了对比:RMT,fine-grained RMT,dRMT with IPC=1,dMRT with IPC=2。fine-grained RMT(细粒度的RMT)支持一张P4流表的匹配和动作操作划分到不同的RMT阶段中,它在可忽略的开销(在数据报首部中保留动作的结果)前提下,大幅提升了RMT的灵活性。此外,这些结果还与最低界限相比较,最低界限是在瓶颈资源(如匹配、动作能力)完全利用的情况下,获取需要维持线速的处理器的最小数目,同时也获取了基于关键路径的程序的最小时延。
数值参数:
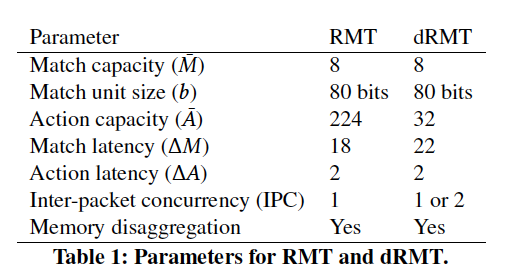
假设内存集群的数目 = 处理器/阶段的数目;其他设置如图:
验证RMT的性能:
对于细粒度的和默认的RMT架构来说,本文阐述了一个ILP来处理上文提及的匹配和动作的限制以及从ODG中获取的依赖限制。RMT ILP没有考虑每一个阶段的流表能力约束,在完全非集计化内存的情况下高效地模拟RMT流水线,这意味着dRMT与RMT有关的实际提升将会高于这儿报告的数字。本文使用RMT ILP来计算满足所有约束的RMT模型的最小流水线阶段数目S。
验证dRMT的性能:
对于dRMT,本文运行了上文提及的ILP,并加速了ILP的运行时间。使用二分查找的程序来计算最小调度周期P,即单处理器每P个时钟周期能够接收一个数据报。
度量:
对于dRMT而言,如果最小的调度周期是P,那么单处理器的最大处理能力为每P个时钟周期接收一个数据报,说明至少需要P个处理器才能达到线速。对于RMT来说,假设每一个阶段能够每个时钟周期能够处理一个数据报,那么至少要有S个阶段才能达到线速。
用于RMT的最少进程数是通过将每个阶段RMT匹配和动作处理的时延之和乘以最小阶段数来获取的。对于dRMT,它是ILP的一种输出。
备注:
用于RMT和dRMT的ILP假定情况的两种分支总是一起执行的(上文有提及)。调度中互相排斥的操作(对于任何数据报来说都无法同时执行)可能会减少两个架构中处理器/阶段数以及进程数。
实验结果
基于真实的P4程序比较dRMT和RMT模型。
表2和表3展示了需要运行四个P4程序时,需要维持线速的最小处理器数目和进程数。其中三个P4程序来自于开源的switch.p4,分别对应于switch.p4的ingress阶段、egress阶段以及一个运行在单条共享的物理流水线上的,将ingress+egress结合的(combined) 的程序,该程序通过静态的多路复用,高效提升了硬件资源的利用率。还有一个专用的P4程序来自于一家大型交换ASIC制造商。
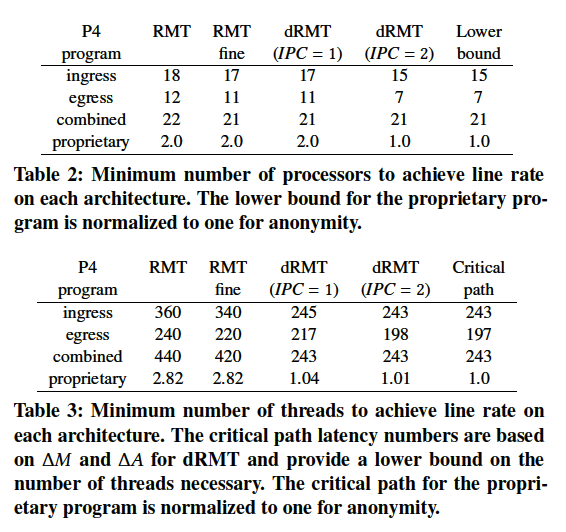
实验结果表明:
- 由于进一步的非集计化保证了更加灵活的调度,导致从RMT -> dRMT(IPC=1) -> dRMT(IPC=2),所需的最小处理器数和进程数是在递减的;
- 对于同样的处理器来说,IPC=2对利用内部数据报并行的机制是非常重要的;
- IPC=2时到达了能够实现吞吐量的上限,表明低程度的内部数据报并行足以实现高吞吐量。
这些P4程序导致匹配和动作操作不平衡,因此浪费了硬件资源,在基于这些程序的测试中,dRMT将程序紧凑至一些处理器中,得到了较好的测试结果。
基于随机生成ODG的比较。
为使用大量潜在可能的P4程序来对比dRMT和RMT的架构,本实验基于switch.p4的ODG随机生成了一系列随机的ODG。具体来说,生成了100个不同的ODG来反映不同大小的P4程序,对于每一个ODG而言,测试反映了支持线速处理该程序所需最小数目的处理器数和阶段数。生成ODG是依赖于某些准则的,详细请参考原文。
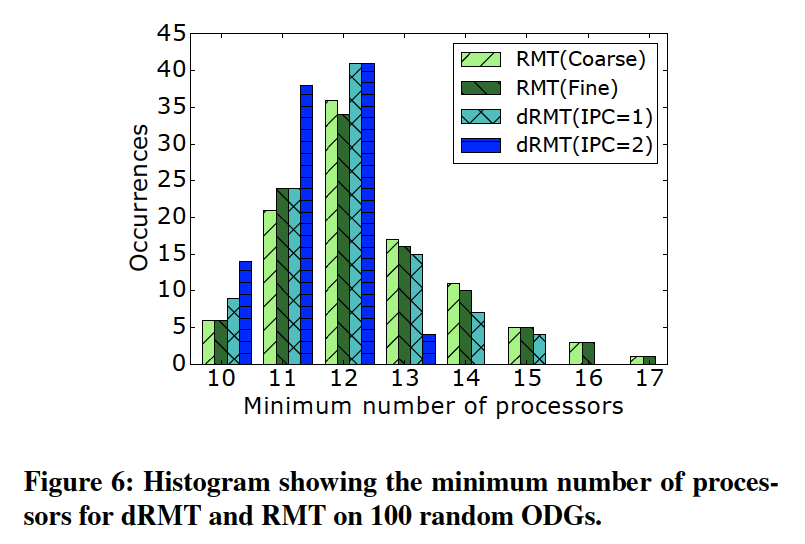
图6展示了测试的结果,dRMT with IPC=2 提供了更高的灵活性,并使用了最少的处理器和进程,与预期相符;dRMT with IPC=1 优于RMT的结果。在这一百个随机生成的图中,dRMT with IPC=2比RMT模型平均减少了10%的处理器数目,最多可以减少30%。
dRMT避免了性能坠崖。
一旦决定了:
- S: RMT维持线速吞吐所需要的阶段数;
- P: dRMT维持线速吞吐所需要的处理器数。
就可以计算吞吐量 th(N) ,是处理器数目N的函数。
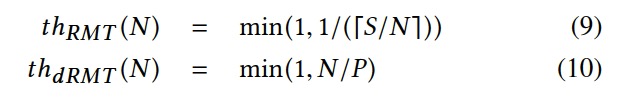
构建支持每个周期两个或者更多的读写操作(换句话说,一个周期处理多个数据报)需要的芯片内存是非常困难的,因此吞吐的上限为1。

图七表明了在减少处理器数目的情况下,对于吞吐量的影响。该图将每个架构在运行switch.p4的egress程序时的数据绘制了出来,它表明了两个RMT架构的性能坠崖以及dRMT架构下吞吐量的线性递减。
dRMT ILP运行时间的验证。
论文在固定线速吞吐量的前提下,测量了dRMT ILP的运行时间,它是处理器数目N的函数。
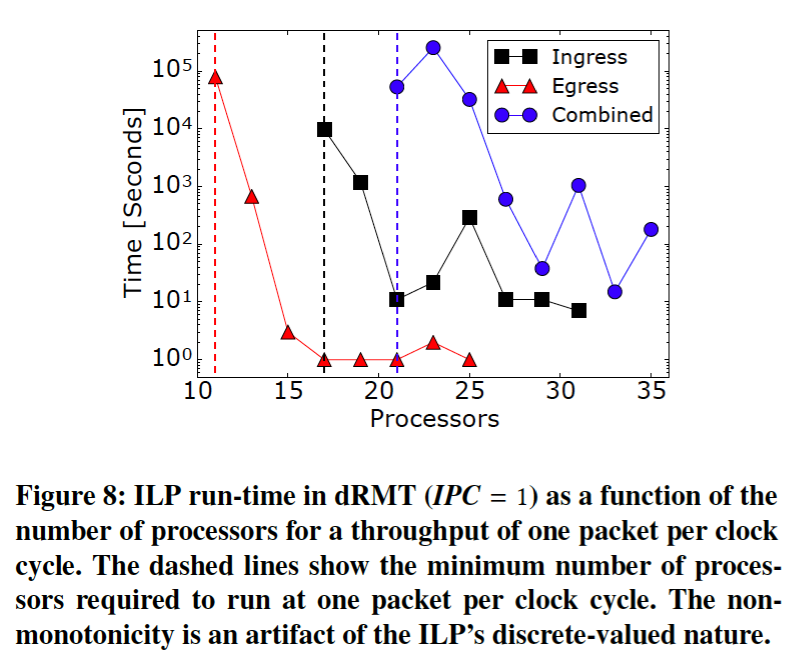
图8表明了dRMT with IPC=1架构的结果,随着处理器数目的增多ILP运行时间迅速下降,原因是因为当有部分松弛(a little bit of slack)时,ILP更加容易求解。这里没有展示dRMT with IPC=2的情况,原因是IPC=2简化了调度问题,提供了更多的灵活性,使得无论处理器的数目有多少,运行时间从来没有超过几分钟。
剩余部分细节请参照原论文。
2017.8
dRMT: Disaggregated Programmable Switching, SIGCOMM17的更多相关文章
- dRMT: Disaggregated Programmable Switching
dRMT: Disaggregated Programmable Switching 2017年SIGCOMM会议上提出的新型可编程交换机架构,对2013年提出的RMT架构存在的问题进行了优化. 主要 ...
- Changing the Output Voltage of a Switching Regulator on the Fly
http://www.powerguru.org/changing-the-output-voltage-of-a-switching-regulator-on-the-fly/ There are ...
- DYNAMIC CONTEXT SWITCHING BETWEEN ARCHITECTURALLY DISTINCT GRAPHICS PROCESSORS
FIELD OF INVENTION This invention relates to computer graphics processing, and more specifically to ...
- Disable the screen switching about VI
If you want to disable the screen switching, and you don't want tochange your termcap, you can add t ...
- Multiprotocol Label Switching (MPLS)
Posted by: Margaret Rouse WhatIs.com Contributor(s): Robert Sturt This definition is part of our E ...
- Note for Computer Networks_Circuit Switching & Packet Switching
Packet Switching: - In a packet switched network data is transmitted in blocks(packets), typically l ...
- Cortex-M3 Context Switching
http://www.embedded.com/design/embedded/4231326/Taking-advantage-of-the-Cortex-M3-s-pre-emptive-cont ...
- [Practical Git] Switching between current branch and last checkout branch
When working on a project, it is much easier to work on features and bugs in isolation of the rest o ...
- RH033读书笔记(14)-Lab 15 Switching Users and Setting a Umask
Lab 15 Switching Users and Setting a Umask Goal: Become familiar with the use of several essential c ...
随机推荐
- 用 hashcat 破解 WIFI WPA2破解
首先用CDlinux系统进行抓包,CDlinux抓包我就不详细说明 到这里可以查看如何安装CDlinux http://jingyan.baidu.com/article/7f766daf5173a9 ...
- [转]Hive开发总结
看到一篇挺不错的hive开发总结文章,在此转载一下,有兴趣的可以去看原文,传送门HIVE开发总结. 基本数据类型 查看所有函数 搜索函数 搜索表 查看函数使用方法 关键字补全 显示表头 SET环境变量 ...
- flask模板应用-空白控制
模板应用实践 空白控制 在实际输出的HTML文件中,模板中的jinja2语句.表达式和注释会保留移除后的空行. 例如下面的代码: {% set user.age = 23 %} {% if urer. ...
- PyCharm2017破解步骤
前段时间买了一套python的学习视频,附带一个Pycharm的安装包和注册码,现在注册码被JetBrains封杀了,不得已在网上找了一下破解的教程,在这里记录一下: 先找到破解补丁无需使用注册码,下 ...
- PyCharm 2017.2.3 版本在2017年9月7日发布,支持 Docker Compose
PyCharm是由JetBrains打造的一款Python IDE.PyCharm具备用于一般IDE的功能,比如, 调试.语法高亮.Project管理.代码跳转.智能提示.自动完成.单元测试.版本控制 ...
- 一篇关于蓝牙SDP和L2CAP协议的文章
SDP地址:http://www.cnblogs.com/strive-forever/archive/2011/11/04/2236640.html L2CAP地址:http://www.cnblo ...
- Lambda表达式select()和where()的区别
可能很多同学和我一样对于select()和where()区别并不是太清晰,其实两者还是有本质区别的. 1.where()用法:必须加条件,且返回对象结果. static void Main(strin ...
- Oracle执行计划 explain plan
Rowid的概念:rowid是一个伪列,既然是伪列,那么这个列就不是用户定义,而是系统自己给加上的. 对每个表都有一个rowid的伪列,但是表中并不物理存储ROWID列的值.不过你可以像使用其它列那样 ...
- 前端框架VUE----node.js的简单介绍
一.什么是node.js? 它是可以运行JavaScript的服务平台,可以吧它当做一门后端程序,只是它的开发语言是JavaScript 二.安装 1.node.js的特性: - 非阻塞IO模型 - ...
- Django的View
一个视图函数(类),简称视图,是一个简单的Python 函数(类),它接受Web请求并且返回Web响应. 响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XML文档,或者一张图片. ...