【pytorch】目标检测:新手也能彻底搞懂的YOLOv5详解
YOLOv5是Glenn Jocher等人研发,它是Ultralytics公司的开源项目。YOLOv5根据参数量分为了n、s、m、l、x五种类型,其参数量依次上升,当然了其效果也是越来越好。从2020年6月发布至2022年11月已经更新了7个大版本,在v7版本中还添加了语义分割的功能。本文以YOLOv5_v6为媒介,对YOLOv5进行学习。
1. 综述
先放上个人对YOLOv5_v6的理解(可结合图1进行阅读),这里我们假设对一组图片进行训练。首先我们要了解,YOLOv5_v6是对三个尺度的特征图进行目标检测的,即large(大)、medium(中)、small(小)三种。
1)准备工作(Input中进行):图片需要经过数据增强(尤其是Mosaic数据增强),并且初始化一组anchor预设(YOLOv5_v6针对不同参数量的模型给出了不同的通用预设)。
2)特征提取(Backbone中进行):使用了Conv、C3、SPPF基本结构对输入图片进行特征提取。Conv用于对输入进行下采样(共进行了5次下采样);C3用于对输入进行特征提取、融合,丰富特征的语义信息,在这个过程中使用了Boottleneck减少参数量和计算量、借鉴CSPNet思想增强CNN学习能力;SPPF利用池化、特征融合的方式丰富特征的语义信息,使得最深层的特征图拥有极丰富的语义信息。
3)加工特征(Neck中进行):对要进行目标检测的三种尺度的特征图融合浅层特征(浅层特征有利于检测)。v6借鉴了PANet,对提取的特征图融合浅层特征,使得特征图既具有丰富的语义信息又具有物体准确的位置信息。
4)预测目标(Head中进行):对加工后的特征图进行预测,根据损失函数(Classificition Loss和Bounding Box Regeression Loss)和优化器优化参数权重。
图1 网络构架图
2. 前置知识
2.1. 特征融合方式
concat:张量拼接,会扩充两个张量的维度,例如2626256和2626512两个张量拼接,结果是2626768。
add:张量相加,张量直接相加,不会扩充维度,例如104104128和104104128相加,结果还是104104128。
2.2. anchor
YOLOv5是基于anchor的目标检测网络,虽然YOLOv5实现了自适应锚框计算,不过了解anchor有助于我们深入理解YOLOv5。
anchor(锚框)就是在图像上预设好的不同大小,不同长宽比的参照框。anchor是由Faster-RCNN提出的,anchor解决了scale和aspect ratio变化范围大的问题,即将单元格的预测框空间划分为了几个子空间,降低模型学习难度。在YOLOv5中,输入图片的尺寸是640640,经过32倍、16倍、8倍下采样,会产生2020、4040、8080大小的特征图(也就是网格尺寸),特征图的每个像素(该像素对应的视野域大小就是网格中的单元格大小)设置3个anchor,因此v5一共有 (2020+4040+8080)3=25200个anchor。
那么,anchor是如何对输出的预测框产生影响的呢?借助神经网络强大的拟合能力,直接让神经网络输出每个anchor是否包含(或者说与物体有较大重叠,也就是IoU较大)物体,以及被检测物体相对本anchor的中心点偏移以及长宽比例。因为anchor的位置都是固定的,所以就可以很容易的换算出来实际物体的位置。以下图中的小猫为例,红色的anchor就以99%的概率认为它是一只猫,并同时给出了猫的实际位置相对于该anchor的偏移量,这样,我们将输出解码后就得到了实际猫的位置,如果它能通过NMS(非最大抑制)筛选,它就能顺利的输出来。但是,绿色的anchor就认为它是猫的概率就很小,紫色的anchor虽然与猫有重叠,但是概率只有26%。
图2-图源:https://zhuanlan.zhihu.com/p/112574936
2.3. Bottleneck
Bottleneck结构是为了减少参数量和计算量而设计的,其包括三个卷积层:两个11卷积层和一个33卷积层,其结构如下图左(图右是等效的33卷积层)所示: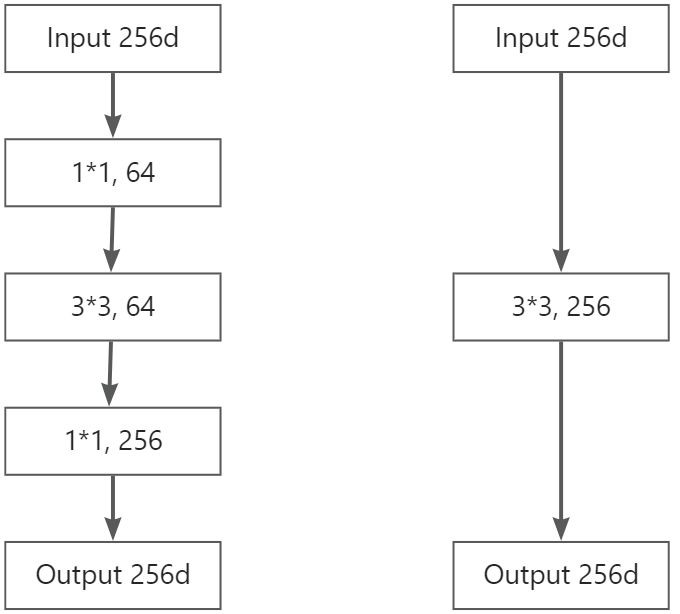
图3
假设Input是[1, 256, 10, 10],则
普通卷积的参数量(params):25633256+256=590, 080(最后一个256是BN层参数,不考虑bias)
普通卷积的计算量(FLOPs):256332561010=58,982,400(不考虑bias)
Bottleneck结构的参数量(params):(2561164+64)+(643364+64)+(6411256+256)=70, 016(最后一个256是BN层参数,不考虑bias)
Bottleneck结构的计算量(FLOPs):25611641010+6433641010+641125610*10=6,963,200(不考虑bias)
可以看到Bottleneck结构减少了的参数量和计算量十分明显。
2.4. CSPNet(Cross Stage Partial Network)
CSPNe是一种增强CNN学习能力的跨阶段局部网络。CSPNet全称是Cross Stage Partial Network,主要从网络结构设计的角度来解决以往工作在推理过程中需要很大计算量的问题,其能够在降低20%计算量的情况下保持甚至提高CNN的能力。作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的,因此CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。需要指出的是CSPNet是一种处理思想,它可以与ResNet、DenseNet、HarNet等分类网络和YOLO等目标检测网络结合。下图展示了CSPNet与不同网络的backbone结合后的效果,可以看出计算量大幅下降、准确率保持不变或提升。
图4 CSPNet应用到不同网络的backbone中的结果
以上简述了CSPNet的设计思路及展示结果,现在让我们看一下它解决了哪些具体的问题:
1)增强CNN的学习能力,能够在轻量化的同时保持准确性;
2)消除计算瓶颈,计算瓶颈太高会导致更多的周期来完成推理过程,或者一些算术单元经常空闲;
3)降低内存成本,动态随机存取存储器(DRAM)的晶圆制造成本非常昂贵,而且占用大量空间。
CSPNet在DenseNet网络中的实现如下图(提出该结构的论文是基于DenseNet网络实现的,这里也以DenseNet为例),实际上就是将Base layer分为两部分,部分1不进行操作,部分2进行Dense Bock和Transition操作变换,然后将两部分特征融合:
图5 DenseNet和CSPDenseNet 图6 a)原DenseNet的backbone; b)引入Partial Dense Layer 和 Partial Transition Layer的backbone
图6 a)原DenseNet的backbone; b)引入Partial Dense Layer 和 Partial Transition Layer的backbone
引入了两个模块Partial Dense Layer 和 Partial Transition Layer,如图5(b)。
部分密集块的目的有三个:1)增加梯度路径:通过拆分和合并策略,可以使梯度路径的数量增加一倍。由于跨阶段策略,可以缓解使用显式特征图副本进行连接所带来的缺点;2)每一层的平衡计算:由于部分稠密块中稠密层操作所涉及的基层通道只占原始数量的一半,因此可以有效解决近一半的计算瓶颈;3)减少内存流量:部分密集块最多可以节省网络一半的内存流量。
部分过渡层的目的是为了最大化梯度组合的差异。部分过渡层是一种分层特征融合机制,它使用截断梯度流的策略来防止不同层学习重复的梯度信息。
2.5. SPP(Spatial Pyramid Pooling)
SPP(Spatial Pyramid Pooling)是为了确保输入预定义全连接层的feature vector(特征向量)是固定尺寸。feature vector是由feature maps展开的,因此常规做法是在输入数据做文章,即对图像进行裁剪和变形操作。但是这两种方式可能会出现不同的问题,1)裁剪的区域可能没法包含物体的整体;2)变形操作造成目标无用的几何失真。而SPP是在feature maps展开为feature vector时做文章的,即SPP将输入的不同图像的feature maps展开为一个固定尺寸的feature vector。以上两种解决问题的思路如下图所示。
图7 两种解决问题的思路
SPP的工作原理很简单,对每个特征图,使用三种不同尺寸的池化核进行最大池化,分别得到预设的特征图尺寸,最后将所有特征图展开为特征向量并融合,过程如下图所示。现在,我们以经过5次卷积模块运算后的Tensor[1, 256, 10, 10]为例,运用SPP原理倒推最大池化层的信息。
1)明确全连接层的输入参数尺寸,如107521= 21X256=16X256+4X256+1X256;
2)明确三种池化后的特征图尺寸,如44、22、11;
3)求三种kernel、stride、padding;
a. 44对应的kernel、stride、padding:kernel---⌈10/4⌉=3;stride---⌈10/4⌉=3;padding---⌊(34-10+1)/2⌋=1
b. 22对应的kernel、stride、padding:kernel---⌈10/2⌉=5;stride---⌈10/2⌉=5;padding---⌊(52-10+1)/2⌋=0
c. 11对应的kernel、stride、padding:kernel---⌈10/1⌉=10;stride---⌊10/1⌋=10;padding---⌊(101-10+1)/2⌋=0
图8 SPP工作原理示意
SPP有以下优点
1)可以忽略输入尺寸并且产生固定长度的输出;
2)SPP在利用不同的池化核尺寸提取特征的方式可以获得丰富的特征信息,有利于提高网络的识别精度。(这也是在YOLOv5_v6的作用)
2.6. FPN(Feature pyramid network)
FPN(Feature pyramid network)是CVPR2017年的一篇文章,它在目标检测中融入了特征金字塔,提高了目标检测的准确率,尤其体现在小物体的检测上。
特征金字塔的高(深)层特征包含有丰富的语义信息(利于分类),但分辨率底,很难准确地保存物体的位置信息;低(浅)层特征虽然语义信息较少,但分辨率高,包含准确的物体位置信息(利于检测和分割)。FPN就是将低层特征和高层特征融合起来,得到一个识别和定位都准确的目标检测结构。FPN的结构主要包括三个部分:Bottom-up,Top-down和Lateral connection,如下图所示。
图9 FPN结构
1)Bottom-up:Bottom-up的过程就是将图片输入到backbone中提取特征的过程。
2)Top-down:Top-down的过程就是将高层得到的feature map进行上采样然后往下传递,这样做是因为,高层的特征包含丰富的语义信息,经过top-down的传播就能使得这些语义信息传播到低层特征上,使得低层特征也包含丰富的语义信息。
3)Lateral connection:Lateral connection是一个特征融合的过程,如上图所示,即P1是C1经1*1卷积后的特征与P2上采样后的特征进行融合(add方式)。
2.7. PANet(Path Aggregation Network)
PANet(Path Aggregation Network)是一个用于实例分割的路径聚合网络,它充分的融合了特征。PANet总共有5个结构,如下图所示,分别是FPN(a)、Bottom-Up Path Augmentation(b)、Adaptive Feature Pooling(c)、Box branch(d)、Fully-Connected Fusion(e)。
图10 PANet结构
1)FPN上文已经介绍,这里不再赘述。
2)Bottom-Up Path Augmentation:考虑到网络的浅层特征对于实例分割非常重要,FPN虽然已经融合了一次浅层特征,但是仍不能达到很好的分割效果,因此引入Bottom-Up Path Augmentation,以保留更多的浅层特征。它是将N2(N2和P2是同一特征图,因此N2已经包含大量低层特征)进行下采样,下采样后的特征图与P3进行融合,得到N3。因此N3包含的低层特征要多与P3。N4,N5同N3。
3)Adaptive Feature Pooling:这一结构做的仍然是特征融合。
YOLOv5_v6使用了PANet中的FAN和Bottom-Up Path Augmentation,因此Box branch、Fully-Connected Fusion不再介绍。读者如想了解其他结构,可参见这里。
3. 基本原理
YOLOv5的原理和YOLOv1基本是一致的,这里不再复述与YOLOv1一致的内容,只讲解与YOLOv1不同的部分,关于YOLOv1的基本原理见:https://www.cnblogs.com/wpx123/p/17640452.html。
1)YOLOv5引入了anchor(锚框),实际上从YOLOv2开始就引入了它。没有引入锚框之前,YOLO只能随机初始化边界框,这就导致了基本上几乎所有的初始边界框都不相同、某些框相对于真实框来说差别十分离谱,继而花费了不必要的算力。引入预设的锚框可以大大减少这种花费。
2)单元格预测类别机制更改为了预测该单元格对应边界框内图像的类别,且每个单元格对应三个边界框。
3)网格尺度增加到了三种,可以从小、中、大三个尺度检测目标对象,极大地减少了漏检情况。
4)网络构架,详见下一小节。
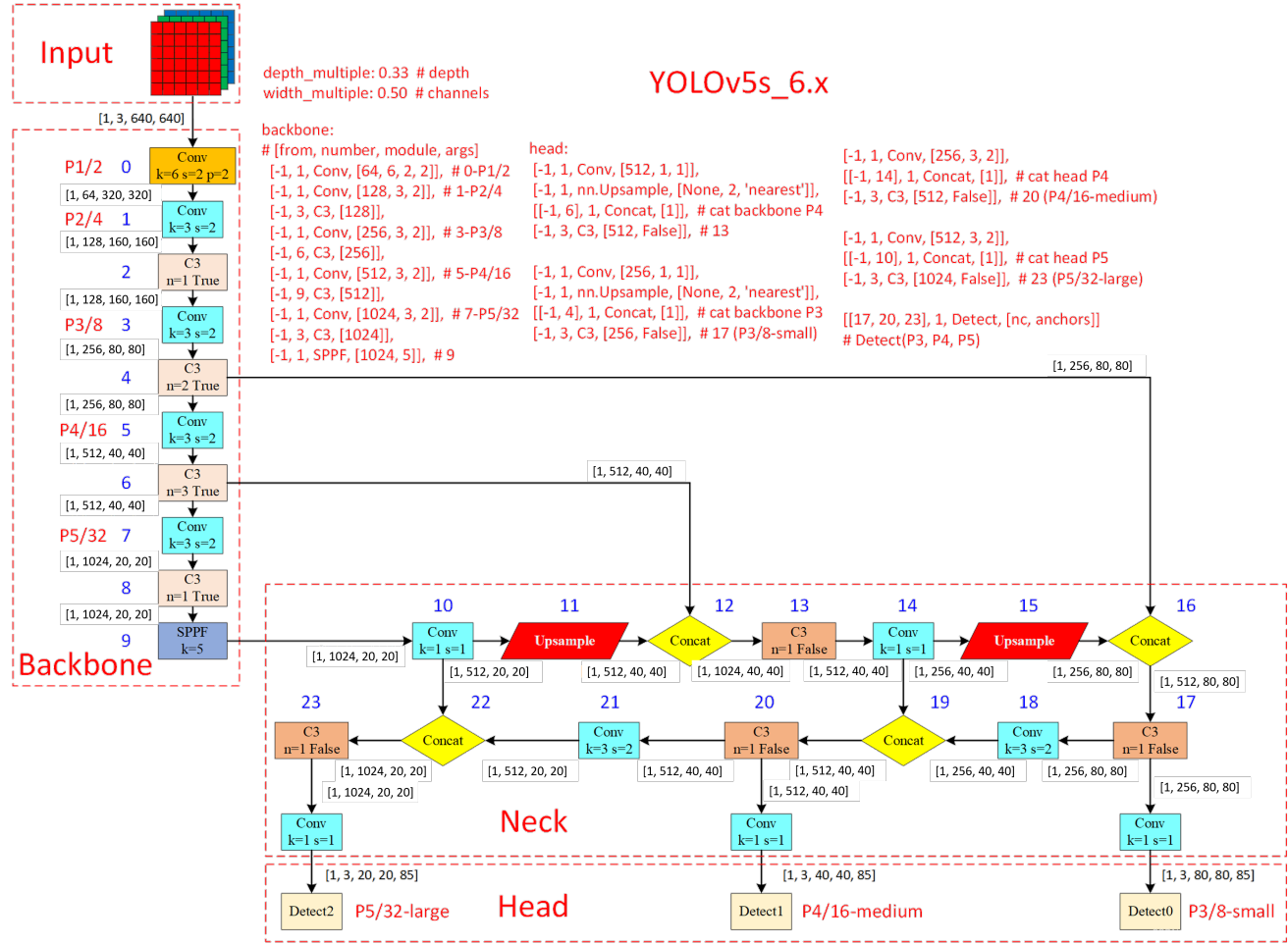
4. 网络构架

图11 网络构架图(参考:https://blog.csdn.net/weixin_43799388/article/details/123271962)

图12 基本模块构成
我们先来对上图做个简述,以便可以快速get上图传递的信息。上图可分为两个部分,右上的备注区域及其他区域的网络结构示意。
首先来看网络构架。
1)共分为四块,Input、Backbone、Neck、Head;
2)不同颜色的矩形框代表了不同的基本模块,如Conv、C3、Upsample;
3)Input、Backbone、Neck中的Tensor,[x1, x2, x3, x4]分别是[batch_size, channels, height, width],即[B, C, H, W]。Head中的Tensor,[x1, x2, x3, x4, x5]分别是[batch_size, bounding_boxs, height, width, A],A是指边界框的(x, y, w, h, c)与80个类别的概率;
4)Backbone中的Pn1/n2是指第n1次下采样,下采样倍数为n2;
5)Head中的P5/32-large是指此时的每个网格单元是3232像素,网格尺寸是2020,在32*32(大尺度)的单元格基础上绘制边界框。P4/16-medium、P3/8-small同P5/32-large。
其次看一下,备注区域的信息。图片中的信息是来自yolov5.yaml文件,因此我们只需要对yolov5.yaml文件进行解读就可理解图中信息。
# Parameters
nc: 80 # 类别数量
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
"""
depth_multiple:控制子模块的数量
width_multiple:控制卷积核的数量
"""
anchors:
- [10,13, 16,30, 33,23] # P3/8,检测小目标,10,13是一组尺寸
- [30,61, 62,45, 59,119] # P4/16,检测中目标
- [116,90, 156,198, 373,326] # P5/32,检测大目标
# YOLOv5 v6.0 backbone
backbone:
"""
from:输入来自那一层,-1代表上一次,1代表第1层,3代表第3层
number:模块的数量,最终数量需要乘width,然后四舍五入取整,如果小于1,取1
module:子模块
args:模块参数,channel,kernel_size,stride,padding,bias等
"""
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
4.1. Input:Mosaic数据增强、自适应锚框、自适应图片缩放
Mosaic数据增强
对应类:datasets.LoadImagesAndLabels()
Mosaic数据增强是指将4张图片随即缩放、随机裁剪、随机排布的方式进行拼接成新的图片,该方式仅在训练过程中使用。下图就是一个Mosaic数据增强的过程。
图13 Mosaic数据增强示意图
为什么要使用Mosaic数据增强呢?
1)丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
2)减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
自适应锚框
对应模块:autoanchor.py
在YOLO算法中针对不同的数据集都会有初始设定长款的锚框,比如YOLOv5s_v6在Coco数据集上初始设定的锚框为:
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算损失,再反向更新,迭代网络参数。在Yolov3、Yo1lov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
自适应图片缩放
对应函数:augmentations.letterbox()
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中,如下图所示。但是,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。因此YOLOv5作者在augmentations.letterbox()中对图像自适应添加最少的黑边(代码中添加的是灰边,本文以黑边代替)。
图14 一般的图片缩放

图15 自适应缩放
计算过程如下:
1)计算缩放比例:min(640/640, 640/960)-->min(1.0, 0.666)-->0.666
2)计算图片缩放后的尺寸:size=(6400.666)(9600.666)=426640
3)计算黑边填充数值:np.mod(640-426, 32)-->np.mod(214, 32)-->22,即共需填充22行像素黑边,上下个11行。
4)图像的最终尺寸:size=(426+22)640=448640
备注:
1)训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到640*640大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
2)为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余。
4.2. Backbone:Conv、C3、SPPF
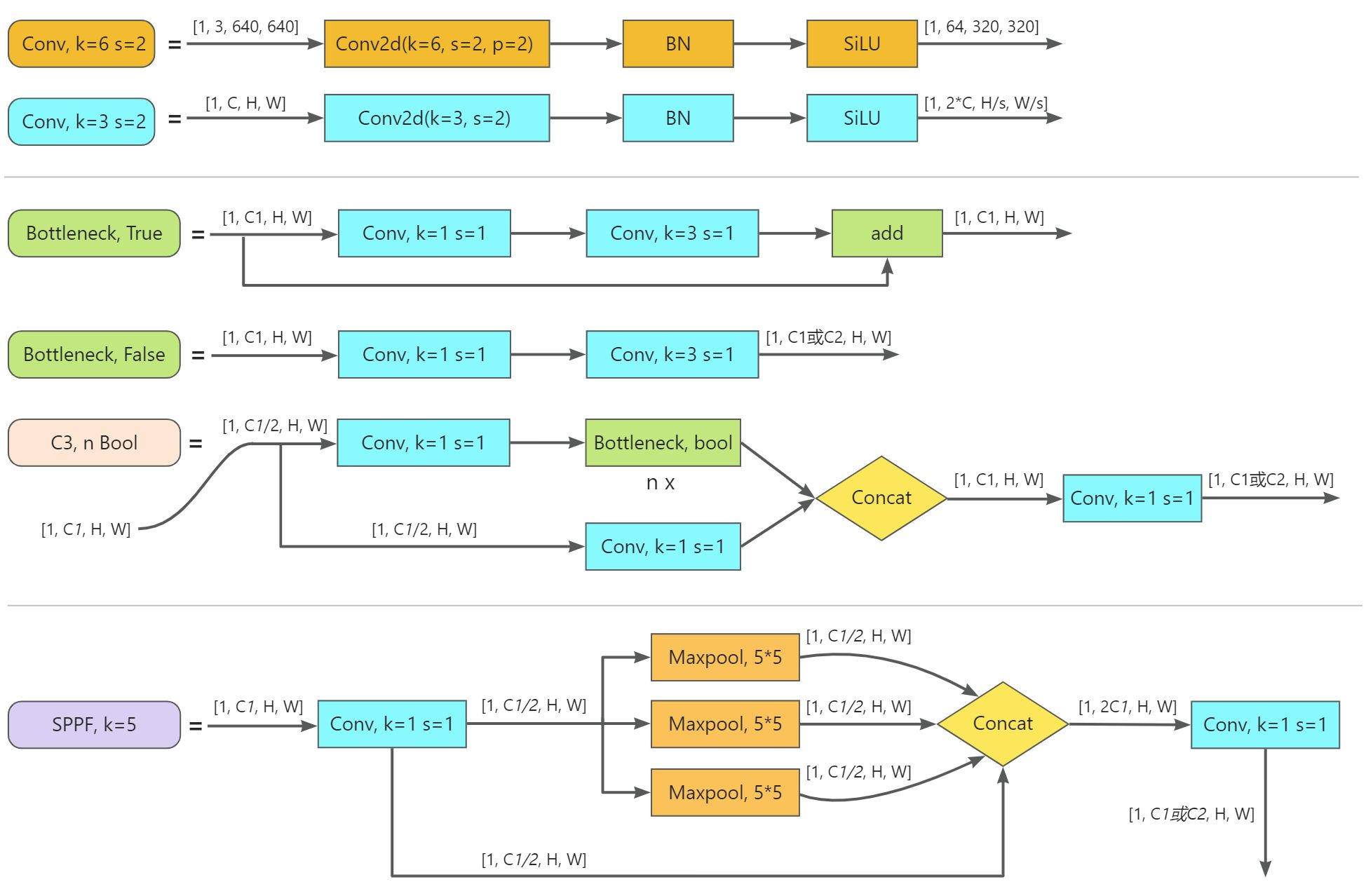
Conv

Conv, k=6 s=2,是由2D卷积层+BN层+SiLU激活函数组成的,其目的是减少计算量和参数量,达到提速效果。在YOLOv5_v6之前是使用Focus结构达到的,Conv, k=6 s=2相对于Focus的优点是便于导出其他框架类型的文件。下面让我们看一下Conv, k=6 s=2是如何减少计算量和参数量的,这里我们以一张10103的图片进行举例。
在剖析之前必须要先知道它是对什么结构的改进,从下图可以看出,它是对Conv, [32, 3, 1]、Conv, [64, 3, 2]、Bottleneck, [64]结构的改进。
原darknet53 backbone中的params:(33332+32)+(323364+64)+[(641164)+64+(643364)+64]=60, 480(不考虑bias)
原darknet53 backbone中的FLOPs:(333321010)+(3233641010)+(64116455+64336455)=2, 953, 600(不考虑bias)
YOLOv5_v6 backbone中的params:36664+64=6, 976(最后一个64是BN层参数,不考虑bias)
YOLOv5_v6 backbone中的FLOPs:366641010=691, 200(不考虑bias)
从上述的计算结果不难看出,Conv, k=6 s=2的确减少了参数量和计算量,而且从实验结果看其效果与darknet53中的差别不大。
Conv, k=3 s=2,k、s是可定义的,在YOLOv5_v6中大都是k=3, s=2和k=1, s=1两种。是由2D卷积层+BN层+SiLU激活函数组成的,可以理解为广义的卷积(因为卷积层后一般都会紧跟BN层、激活函数)。它是YOLO中最基本的结构单元,参与构成其他结构,如Bottleneck、C3、SPPF等。
C3
Bottleneck
Bottleneck用于减少计算量和参数量,与Bottleneck等效的普通卷积计算量和参数量高于Bottleneck。带有短路的Bottleneck还具有丰富特征语义信息的作用。
class Bottleneck(nn.Module):
# 标准bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # 隐藏层
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
YOLOv5_v6中还存在BottleneckCSP、GhostBottleneck变体,它们都在common.py中。Bottlenect减少了参数量和计算量,具体减少了多少和c1、c2、e都有关系,其计算方式前面已经介绍,这里不再赘述。
C3(CSP Bottleneck with 3 convolutions)
C3可以增强CNN的学习能力,使网络轻量化的同时提升准确度。
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
C3借鉴了CSPNet处理思想,利用n个Bottleneck、3个卷积模块、Concat来实现。C3减少了梯度信息的重复,这极大地减小了计算量,同时也使准确率有所提升。总结来说就是它增强了backbone的学习能力、消除了计算瓶颈、降低了内存成本。它与CSPNet相比更简单、更迅速、融合性更好,且对CNN网络学习能力的增强基本一致。
SPPF(Spatial Pyramid Pooling - Fast)
SPPF顾名思义,就是为了保证准确率相似的条件下爱,减少计算量,以提高速度,使用3个5×5的最大池化,代替原来v6之前的5×5、9×9、13×13最大池化。使用SPPF的目的是为了利用不同的池化核尺寸提取特征的方式可以获得更多的特征信息,提高网络的识别精度。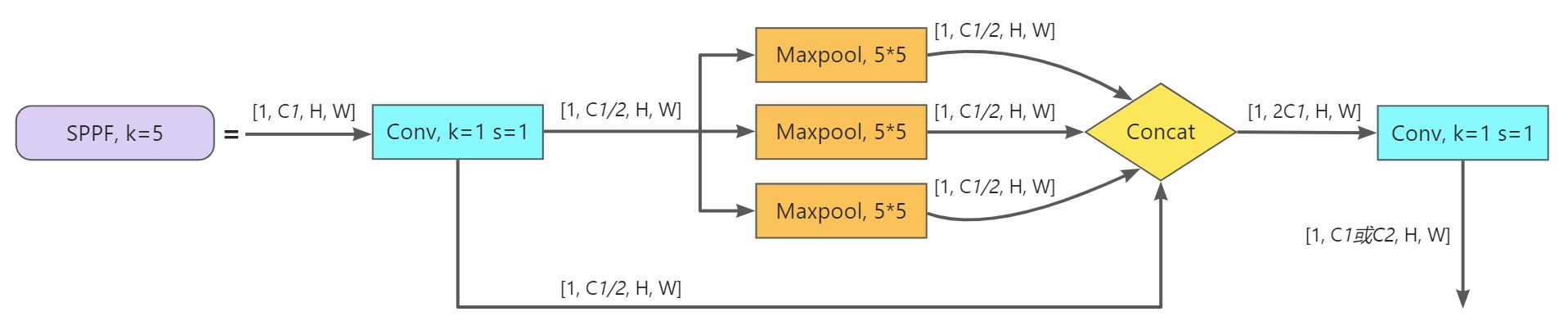
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
4.3. Neck
这一部分不能单独进行理解,需要和backbone结合在一起进行理解,Neck和Backbone结合在一起就是PANet中的FPN+Bottom-Up Path Augmentation结构,其目的就是将深层特征的语义信息和浅层特征在三种尺度的特征图中进行充分融合,使其更利于进行目标检测。
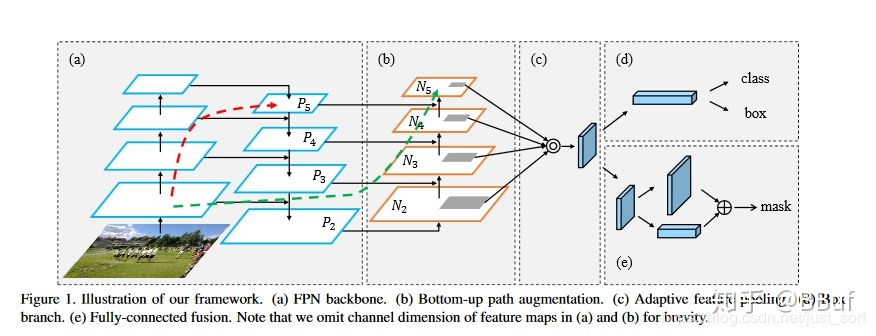
读者将上面两图仔细进行比对就不难理解Neck的作用了。
5. 参考内容
- 新手也能彻底搞懂的目标检测Anchor是什么?怎么科学设置?[附代码]
- 轻量级网络:Bottleneck结构(沙漏型结构)_那年聪聪的博客-CSDN博客
- 增强CNN学习能力的Backbone:CSPNet
- 【CV】CSPNet:通过分层特征融合机制增强 CNN 学习能力的骨干网络_cspdensenet 截断梯度流_datamonday的博客-CSDN博客
- SPP(Spatial Pyramid Pooling)网络
- 【目标检测】FPN(Feature Pyramid Network)
- 【CV中的特征金字塔】四,CVPR 2018 PANet
- 【YOLOv5-6.x】网络模型&源码解析_yolov5中6.0版本什么时候发布的_嗜睡的篠龙的博客-CSDN博客
- yolov5中的Focus模块的理解_focus结构_三叔家的猫的博客-CSDN博客
【pytorch】目标检测:新手也能彻底搞懂的YOLOv5详解的更多相关文章
- C++入门教程:大白话讲解,新手基础篇⭐⭐⭐(附源码及详解、视频课程资料推荐)
目录 C++教程 前言 视频教程 文字教程 集成开发环境(IDE) 编译器 工作原理 学习指南 入门书籍 进阶书籍 算法.竞赛书籍 教程 标准构建 程序解释 第一个C++程序--"hello ...
- 从零开始实现SSD目标检测(pytorch)(一)
目录 从零开始实现SSD目标检测(pytorch) 第一章 相关概念概述 1.1 检测框表示 1.2 交并比 第二章 基础网络 2.1 基础网络 2.2 附加网络 第三章 先验框设计 3.1 引言 3 ...
- 【目标检测】YOLO:
PPT 可以说是讲得相当之清楚了... deepsystems.io 中文翻译: https://zhuanlan.zhihu.com/p/24916786 图解YOLO YOLO核心思想:从R-CN ...
- 如何使用 pytorch 实现 SSD 目标检测算法
前言 SSD 的全称是 Single Shot MultiBox Detector,它和 YOLO 一样,是 One-Stage 目标检测算法中的一种.由于是单阶段的算法,不需要产生所谓的候选区域,所 ...
- 目标检测-基于Pytorch实现Yolov3(1)- 搭建模型
原文地址:https://www.cnblogs.com/jacklu/p/9853599.html 本人前段时间在T厂做了目标检测的项目,对一些目标检测框架也有了一定理解.其中Yolov3速度非常快 ...
- 目标检测之Faster-RCNN的pytorch代码详解(模型训练篇)
本文所用代码gayhub的地址:https://github.com/chenyuntc/simple-faster-rcnn-pytorch (非本人所写,博文只是解释代码) 好长时间没有发博客了 ...
- 目标检测Object Detection概述(Tensorflow&Pytorch实现)
1999:SIFT 2001:Cascades 2003:Bag of Words 2005:HOG 2006:SPM/SURF/Region Covariance 2007:PASCAL VOC 2 ...
- PyTorch专栏(八):微调基于torchvision 0.3的目标检测模型
专栏目录: 第一章:PyTorch之简介与下载 PyTorch简介 PyTorch环境搭建 第二章:PyTorch之60分钟入门 PyTorch入门 PyTorch自动微分 PyTorch神经网络 P ...
- 目标检测之Faster-RCNN的pytorch代码详解(模型准备篇)
十月一的假期转眼就结束了,这个假期带女朋友到处玩了玩,虽然经济仿佛要陷入危机,不过没关系,要是吃不上饭就看书,吃精神粮食也不错,哈哈!开个玩笑,是要收收心好好干活了,继续写Faster-RCNN的代码 ...
- 目标检测入门论文YOLOV1精读以及pytorch源码复现(yolov1)
结果展示 其中绿线是我绘制的图像划分网格. 这里的loss是我训练的 0.77 ,由于损失函数是我自己写的,所以可能跟大家的不太一样,这个不重要,重要的是学习思路. 重点提示 yolov1是一个目标检 ...
随机推荐
- 2021-01-31:Redis集群方案不可用的情况有哪些?
福哥答案2021-01-31:[答案来自此链接:](https://www.zhihu.com/question/442112697)一个集群模式的官方推荐最小最佳实践方案是 6 个节点,3 个 Ma ...
- 深入理解 python 虚拟机:破解核心魔法——反序列化 pyc 文件
深入理解 python 虚拟机:破解核心魔法--反序列化 pyc 文件 在前面的文章当中我们详细的对于 pyc 文件的结构进行了分析,pyc 文件主要有下面的四个部分组成:魔术. Bite Filed ...
- Python基础 - 解释性语言和编译性语言
什么是机器语言 计算机是不能理解高级语言,当然也就不能直接执行高级语言了.计算机只能直接理解机器语言,所以任何语言,都必须将其翻译成机器语言,计算机才能运行高级语言编写的程序. 如何把我们写的代码 ...
- Isito 入门:为什么学 Istio、Istio 是什么
1,Istio 概述 聊聊微服务设计 似乎用上 Kubernetes ,就是微服务系统了. 碰到很多人或公司盲目崇拜 Kubernetes ,一直喊着要上 Kubernetes,但是本身既没有技术储备 ...
- Django认证流程源码及自定义 Backend
Django自己的认证方法只能认证用户名和密码 user = authenticate(**credentials) # authenticate会自动校验用户名和密码 authenticate 源码 ...
- Nucleic Acids Research上关于生物医学分析Galaxy平台在几个独立面上的最新发展。
该平台的官方主服务器拥有超过124000注册用户,每月新注册用户~2000。平均而言,......
本文分享自微信公众号 - 生信科技爱好者(bioitee).如有侵权,请联系 support@oschina.cn 删除.本文参与"OSC源创计划",欢迎正在阅读的你也加入,一起分 ...
- Python socket记录
目录 网络编程 1.基本概念 Python中的网络编程 网络编程 1.基本概念 1.什么是客户端/服务器架构? 服务器就是一系列硬件或软件,为一个或多个客户端(服务的用户)提供所需的"服务& ...
- 解决github无法打开问题
在国内访问国外服务器(如github)会有卡顿.无法加载等问题,提供两种解决方案: 1.查看github的IP地址并修改Hosts windows键+R,打开cmd(或windows键+X,打开Win ...
- Dapr v1.11 版本已发布
Dapr是一套开源.可移植的事件驱动型运行时,允许开发人员轻松立足云端与边缘位置运行弹性.微服务.无状态以及有状态等应用程序类型.Dapr能够确保开发人员专注于编写业务逻辑,而不必分神于解决分布式系统 ...
- 通用密钥,无需密码,在无密码元年实现Passkeys通用密钥登录(基于Django4.2/Python3.10)
毋庸讳言,密码是极其伟大的发明,但拜病毒和黑客所赐,一旦密码泄露,我们就得绞尽脑汁再想另外一个密码,但记忆力并不是一个靠谱的东西,一旦遗忘密码,也会造成严重的后果,2023年业界巨头Google已经率 ...