(三)xpath爬取4K高清美女壁纸


功能:通过xpath爬取彼岸图网的高清美女壁纸
url = 'http://pic.netbian.com/4kmeinv/'
1. 通过url请求整张页面的数据
2.通过页面的标签定位图片所在的位置
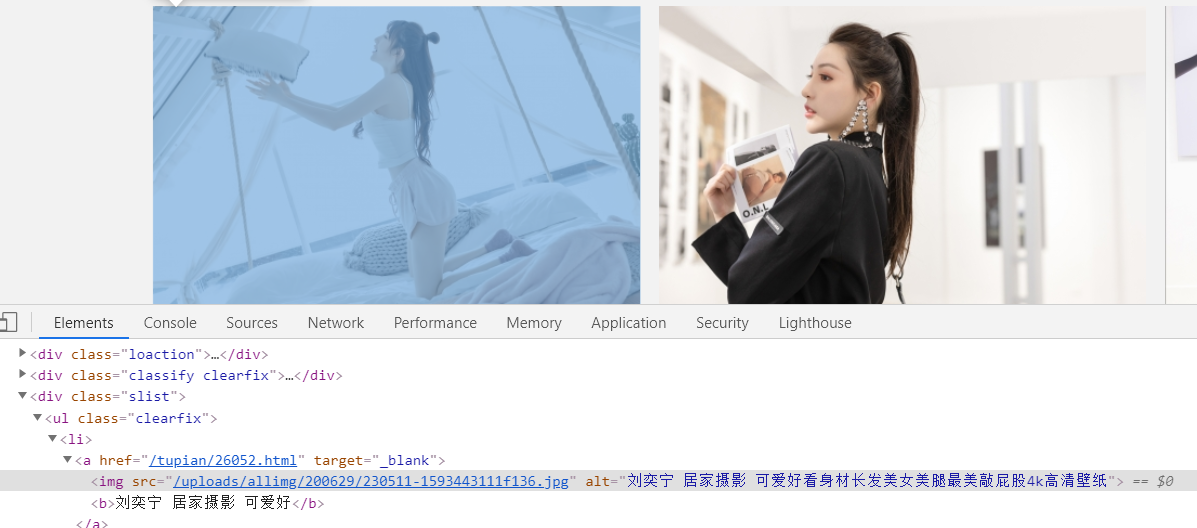
3.找到所有图片的通用的标签
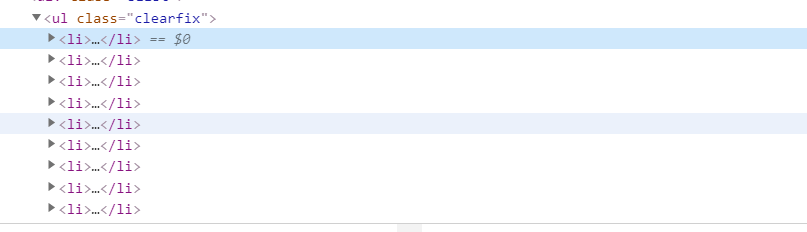
向图片标签的父级查找,可以发现每一张图片都在ul下的li标签下。
4.知道每一个li标签下图片所处的位置
5.思路:通过url拿到整张页面的数据,通过etree进行标签定位,拿到所有的li标签,再循环对每一个li标签下的每一个图片发送请求,拿到图片。
import requests
from lxml import etree
import os
import time
if not os.path.exists('./4kPic'):
os.makedirs('./4kPic')
url ='http://pic.netbian.com/4kmeinv/'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
}
response = requests.get(url=url,headers=headers)
# 获取网页所有数据
page_text = response.text
# 实例化etree对象
tree = etree.HTML(page_text)
# 找到所有的li标签
li_list = tree.xpath("//div[@class='slist']/ul/li")
# 遍历所有li标签
for li in li_list:
# 局部解析用./表示当前的li标签
img_src = li.xpath('.//img/@src')[0] # 获取图片路径
img_alt = li.xpath('.//img/@alt')[0] # 获取图片名称
# 解决中文乱码问题的通用方式
img_name = img_alt.encode('iso-8859-1').decode('gbk')
# 获取图片完整路径
img_url = 'http://pic.netbian.com'+img_src
try:
# content获取图片的二进制数据 文件传输都是以二进制的形式
img_data = requests.get(url=img_url, headers=headers).content
except requests.exceptions.ConnectionError:
time.sleep(1) # 数据请求过快会请求失败 可以time.sleep
continue
fileName = img_name+'.jpg'
with open('4kPic/'+fileName,'wb') as f:
f.write(img_data)
print(img_name+'--------------爬取成功')
注:解决中文乱码问题的方式
方式1:
response.encoding='utf-8' 有些数据不能直接用utf8编码 这不是一种通用的方式
方式2:
img_name = img_alt.encode('iso-8859-1').decode('gbk') 这种为通用方式
(三)xpath爬取4K高清美女壁纸的更多相关文章
- 实例学习——爬取Pexels高清图片
近来学习爬取Pexels图片时,发现书上代码会抛出ConnectionError,经查阅资料知,可能是向网页申请过于频繁被禁,可使用time.sleep(),减缓爬取速度,但考虑到爬取数据较多,运行时 ...
- 别人用钱,而我用python爬虫爬取了一年的4K高清壁纸
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取htt ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- python网络爬虫之解析网页的XPath(爬取Path职位信息)[三]
目录 前言 XPath的使用方法 XPath爬取数据 后言 @(目录) 前言 本章同样是解析网页,不过使用的解析技术为XPath. 相对于之前的BeautifulSoup,我感觉还行,也是一个比较常用 ...
- Python爬虫实战 批量下载高清美女图片
彼岸图网站里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过python爬虫批量下载网站里的高清美女图片,熟悉python写爬虫的基本方法: ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
随机推荐
- 【知识点】如何快速开发、部署 Serverless 应用?
简介: 本文将详细介绍如何开发和部署 Serverless 应用,并通过阿里云函数计算控制台与开发者工具 Serverless Devs 进行应用的初始化.部署:最后分享应用的调试,通过科学发布.可观 ...
- 块存储监控与服务压测调优利器-EBS Lens发布
简介:SLS团队联合EBS团队发布了EBS Lens,针对块存储提供数据分析.资源监控的功能,可以帮助用户获取云上块存储资源信息与性能监控数据.提升云上块存储资源的管理效率.高效分析业务波动与资源性 ...
- 【详谈 Delta Lake 】系列技术专题 之 Streaming(流式计算)
简介: 本文翻译自大数据技术公司 Databricks 针对数据湖 Delta Lake 的系列技术文章.众所周知,Databricks 主导着开源大数据社区 Apache Spark.Delta ...
- 尝试 IIncrementalGenerator 进行增量 Source Generator 生成代码
在加上热重载时,源代码生成 Source Generator 的默认行为会让 Visual Studio 有些为难,其原因是热重载会变更代码,变更代码触发代码生成器更新代码,代码生成器更新的代码说不定 ...
- 2.生产环境k8s-1.28.2集群小版本升级到1.28.5
环境:https://www.cnblogs.com/yangmeichong/p/17956335 # 流程:先升级master,再升级node # 1.备份组件参考:https://kuberne ...
- RT-Thread线程同步与线程通信
一.线程同步 线程同步的使用场景 例如一项工作中的两个线程:一个线程从传感器中接收数据并且将数据写到共享内存中,同时另一个线程周期性的从共享内存中读取数据并发送去显示,下图描述了两个线程间的数据传递: ...
- STM32定时器原理
一.简介 不同的芯片定时器的数量不同,STM32F10x中一共有11个定时器,其中2个高级控制定时器,4个普通定时器和2个基本定时器,以及2个看门狗定时器和1个系统嘀嗒定时器. 基本定时器:TIM6. ...
- 利用引用传递一次遍历构造菜单树(附java&go demo)
目录 原理讲解 java demo Go demo 优点 原理讲解 利用引用传递,当儿子的儿子变动的时候,自己的儿子的儿子也变动(取地址) java demo package com.huiyuan. ...
- 深入浅出玩转fPGA-读书笔记
笔记1 关于异步复位同步释放的理解 先看代码: 其中有两个always语句,把2个触发器叠加,当按下复位信号rst_n是,两个触发器都复位(清零).当rst_n释放时,重点就来了,rst_n释放的时刻 ...
- .NET Emit 入门教程:第七部分:实战项目1:将 DbDataReader 转实体
前言: 经过前面几个部分学习,相信学过的同学已经能够掌握 .NET Emit 这种中间语言,并能使得它来编写一些应用,以提高程序的性能. 随着 IL 指令篇的结束,本系列也已经接近尾声,在这接近结束的 ...