使用阿里canal实现mysql与Elasticsearch增量同步
一、背景介绍
最近在做一个地理信息相关的项目,需要维护大量的地址描述数据,同时需要提供对数据检索的功能,准备采用Elasticsearch(6.7)实现。那么问题就来了,地址数据需要同时在MySQL和ES中维护,如果通过代码层面实现会增加代码量也不易维护,权衡之下决定使用阿里的Canal中间件来实现,留念备查。
Canal主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费,工作原理是伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议,MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ),canal 解析 binary log 对象(原始为 byte 流)。同时支持客户端数据落地的适配功能,目前支持关系型数据库的数据同步、HBase的数据同步和ElasticSearch多表数据同步。
二、环境准备
1、MySQL数据库安装;
2、Elasticsearch安装;
3、Canal Server安装及配置,参考https://github.com/alibaba/canal/wiki/QuickStart;
4、Canal Client Adapter安装,参考https://github.com/alibaba/canal/wiki/ClientAdapter;
三、Canal Server配置instance
1、在canal server安装目录下找到/conf/canal.properties,在canal.destinations配置项中增加一个instance,我这里配置的是es-address-original
1 #################################################
2 ######### destinations #############
3 #################################################
4 canal.destinations = es-address-original
2、在/conf目录下创建es-address-original文件夹,并创建instance.properties文件,大家可以直接复制conf目录下的example目录进行修改,主要配置参数如下,其它参考自行参考官方文档
# MySQL数据库连接信息
canal.instance.master.address=192.168.x.x:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8 # mysql 数据解析关注的表,Perl正则表达式
# 多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
# 常见例子:
# 1. 所有表:.* or .*\\..*
# 2. canal schema下所有表: canal\\..*
# 3. canal下的以canal打头的表:canal\\.canal.*
# 4. canal schema下的一张表:canal\\.test1
# 5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
canal.instance.filter.regex=address-platform\\.address_original
四、Canal Adapter配置
client-adapter分为适配器和启动器两部分, 适配器为多个fat jar, 每个适配器会将自己所需的依赖打成一个包, 以SPI的方式让启动器动态加载, 目前所有支持的适配器都放置在plugin目录下
1、在canal adapter的conf目录下找到application.yml配置文件(根据官方介绍启动器为SpringBoot项目)
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null canal.conf:
mode: tcp # 客户端模式 tcp or kafka or rocketMQ
canalServerHost: 127.0.0.1:11111 # canal server address
# zookeeperHosts: slave1:2181
# mqServers: 127.0.0.1:9092 #or rocketmq
# flatMessage: true
batchSize: 500 # 每次获取数据的批大小,单位为K
syncBatchSize: 1000 # 每次同步的批数量
retries: 0 # 重试次数,-1为无限重试
timeout: # 同步超时时间,单位为毫秒
accessKey:
secretKey:
srcDataSources: # 源数据库
defaultDS:
url: jdbc:mysql://192.168.0.201:3306/address-platform?useUnicode=true
username: root
password: 123456
canalAdapters:
- instance: es-address-original # canal instance Name or mq topic name对应canal server中配置的instance名称
groups:
- groupId: g1
outerAdapters:
-
key: addressOriginalKey
name: es
hosts: 192.168.x.x:9200 # 127.0.0.1:9200 for rest mode
properties:
mode: rest # transport or rest
# # security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch # ES集群名称
2、/conf/es下新增配置文件,文件名随意,配置内容如下
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
outerAdapterKey: addressOriginalKey # 对应application.yml中es配置的key
destination: es-address-original # cannal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:
_index: address_original # es 的索引名称
_type: _doc # es 的type名称, es7下无需配置此项
_id: id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
upsert: true
# pk: id
sql: "select a.ID as id, a.ADDRESS as address, a.SERIAL_NO as serial_no from address_original a" # sql映射,注意区分表字段和索引字段大小写
# objFields:
# _labels: array:;
# etlCondition: "where a.c_time>={}" # etl 的条件参数
commitBatch: 3000 # 提交批大小
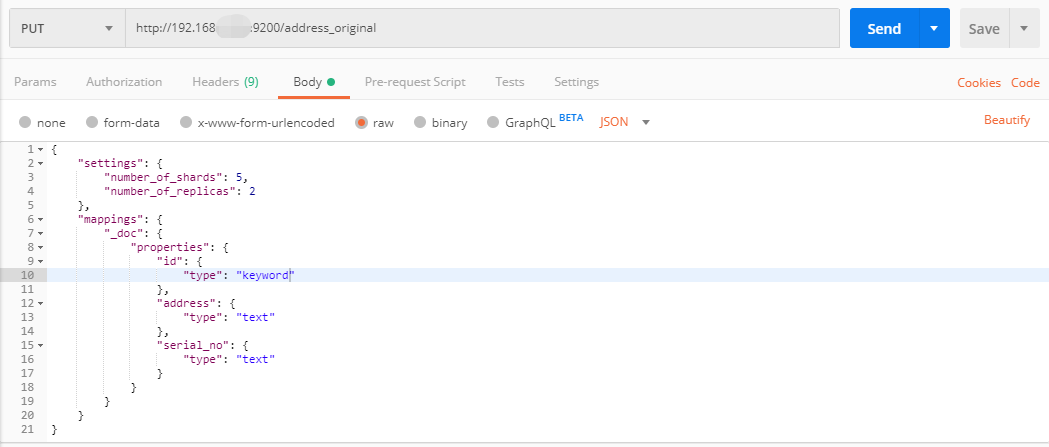
3、创建ES索引信息,通过postman请求ES服务器http://192.168.x.x:9200/address_original,address_original是索引的名称,请求方式为PUT,参数类型为raw(json)
4、这里有几个坑注意一下:
1)canal适配器会通过GET http://192.168.x.x:9200/address_original/_mapping的方式读取es mapping,如果创建索引的时候没有配置mappings信息,会报Not found the mapping info of index异常;
2)测试的时候表字段名是大写,es索引字段名称小写,抛了空指针异常没有具体的异常描述,后来将/canal adapter/conf/es目录中的配置文件sql配置项采用别名统一小写后解决,这里推测数据库表与索引映射名称区分大小写的,后面再看看源码求证一下;
五、运行测试
1、在MySQL数据库address_original表中维护数据(增删改);
2、观察canal adapter日志;
六、运行结果
索引文档结果会根据数据库操作同步更新

使用阿里canal实现mysql与Elasticsearch增量同步的更多相关文章
- 转载:阿里canal实现mysql binlog日志解析同步redis
from: http://www.cnblogs.com/duanxz/p/5062833.html 背景 早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求.不过早期的数 ...
- alibaba/canal 阿里巴巴 mysql 数据库 binlog 增量订阅&消费组件
基于日志增量订阅&消费支持的业务: 数据库镜像 数据库实时备份 多级索引 (卖家和买家各自分库索引) search build 业务cache刷新 价格变化等重要业务消息 项目介绍 名称:ca ...
- MySQL数据实时增量同步到Kafka - Flume
转载自:https://www.cnblogs.com/yucy/p/7845105.html MySQL数据实时增量同步到Kafka - Flume 写在前面的话 需求,将MySQL里的数据实时 ...
- canal 实现Mysql到Elasticsearch实时增量同步
简介: MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第二篇:canal 实现Mysql到Elasticsearch实时增量同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484377&idx=1&sn=199bc88 ...
- mysql 与elasticsearch实时同步常用插件及优缺点对比(ES与关系型数据库同步)
前言: 目前mysql与elasticsearch常用的同步机制大多是基于插件实现的,常用的插件包括:elasticsearch-jdbc, elasticsearch-river-MySQL , g ...
- logstash-input-jdbc实现mysql 与elasticsearch实时同步(ES与关系型数据库同步)
引言: elasticsearch 的出现使得我们的存储.检索数据更快捷.方便.但很多情况下,我们的需求是:现在的数据存储在mysql.oracle等关系型传统数据库中,如何尽量不改变原有数据库表结构 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第五篇:logstash-input-jdbc实现mysql 与elasticsearch实时同步深入详解
文章转载自: https://blog.csdn.net/laoyang360/article/details/51747266 引言: elasticsearch 的出现使得我们的存储.检索数据更快 ...
- 用solr DIH 实现mysql 数据定时,增量同步到solr
基础环境: (二)设置增量导入为定时执行的任务: 很多人利用Windows计划任务,或者Linux的Cron来定期访问增量导入的连接来完成定时增量导入的功能,这其实也是可以的,而且应该没什么问题. 但 ...
- 使用canal增量同步mysql数据库信息到ElasticSearch
本文介绍如何使用canal增量同步mysql数据库信息到ElasticSearch.(注意:是增量!!!) 1.简介 1.1 canal介绍 Canal是一个基于MySQL二进制日志的高性能数据同步系 ...
随机推荐
- Java 集合(二) Map
Map 定义的是键值对的映射关系,一般情况下,都会选择 HashMap 作为具体的实现,除了 HashMap 之外,另一个使用到的比较多的 Map 实现是 TreeMap HashMap 构造函数 H ...
- 云图说 | 华为云MCP多云容器平台,让您轻松灾备!
摘要:多云容器平台是华为云基于多年容器云领域实践经验和社区先进的集群联邦技术,提供的容器多云和混合云的解决方案. 多云容器平台(Multi-Cloud Container Platform,MCP)是 ...
- 带你掌握如何使用CANN 算子ST测试工具msopst
摘要:本期带您了解如何使用msopst工具. 本文分享自华为云社区<[CANN文档速递13期]算子ST测试工具[msopst]>,作者: 昇腾CANN . 如何获取msopst工具 mso ...
- 高性能 Jsonpath 框架,Snack3 3.2.54 发布(支持 kotlin data 类反序化)
Snack3,一个高性能的 JsonPath 框架 借鉴了 Javascript 所有变量由 var 申明,及 Xml dom 一切都是 Node 的设计.其下一切数据都以ONode表示,ONode也 ...
- 朋友们,就在今天,JDK 21,它终于带着重磅新特性正式发布了!
你好呀,我是歪歪. 朋友们,好消息,好消息,重磅好消息. 从今年年初就一直在喊的具有革命性.未来性.开创新纪元的 JDK 21 按照官方的时间计划表,今天终于是要正式 GA 了: https://op ...
- MySQL 数据分组后取第一条数据
SQL SERVER数据分组后取第一条数据--PARTITION BY -- 不加 distinct(a.id) order by 会有问题 导致获取出来的数据不对 SELECT id,title,d ...
- 白嫖:GPT-4
众所周知,GPT-4需要充OpenAI 的 Plus才能使用,Plus则需要每月20美金. 很多同学很想体验GPT-4,但一方面不想花钱,一方面想花也没那么容易花出去(懂的都懂) 我看到有人分享可以免 ...
- AI绘画,Midjourney极简入门
前几天看报道说: 一位小哥用AI绘画工具Midjourney生成的作品,在美国科罗拉多州博览会的艺术比赛中获得了第一名. 作者表示,他多次调整了输入的提示词,生成了100多幅画作,经过数周的修改和挑选 ...
- Nginx--安装模块
一 安装系统自带模块 #进入安装目录[root@localhost ~]# cd nginx-1.18.0/#查看原来的编译选项 [root@localhost nginx-1.18.0]# ngin ...
- 【HZERO】feign调用
feign调用 https://open.hand-china.com/community/detail/603204901962649600 # Hiam获取用户信息示例