ACMMM2021|在多模态训练中融入“知识+图谱”:方法及电商应用实践
简介: 随着人工智能技术的不断发展,知识图谱作为人工智能领域的知识支柱,以其强大的知识表示和推理能力受到学术界和产业界的广泛关注。近年来,知识图谱在语义搜索、问答、知识管理等领域得到了广泛的应用。

作者 | 朱渝珊
来源 | 阿里技术公众号
一 背景
1 多模态知识图谱
随着人工智能技术的不断发展,知识图谱作为人工智能领域的知识支柱,以其强大的知识表示和推理能力受到学术界和产业界的广泛关注。近年来,知识图谱在语义搜索、问答、知识管理等领域得到了广泛的应用。多模态知识图谱与传统知识图谱的主要区别是,传统知识图谱主要集中研究文本和数据库的实体和关系,而多模态知识图谱则在传统知识图谱的基础上,构建了多种模态(例如视觉模态)下的实体,以及多种模态实体间的多模态语义关系。当前典型的多模态知识图谱有DBpedia、Wikidata、IMGpedia和MMKG。
多模态知识图谱的应用场景十分广泛,它极大地帮助了现有自然语言处理和计算机视觉等领域的发展。多模态结构数据虽然在底层表征上是异构的,但是相同实体的不同模态数据在高层语义上是统一的,所以多种模态数据的融合对于在语义层级构建多种模态下统一的语言表示模型提出数据支持。其次多模态知识图谱技术可以服务于各种下游领域,例如多模态实体链接技术可以融合多种模态下的相同实体,可应用于新闻阅读,同款商品识别等场景中,多模态知识图谱补全技术可以通过远程监督补全多模态知识图谱,完善现有的多模态知识图谱,多模态对话系统可用于电商推荐,商品问答领域。
2 多模态预训练
预训练技术在计算机视觉(CV)领域如VGG、Google Inception和ResNet,以及自然语言处理(NLP)如BERT、XLNet和GPT-3的成功应用,启发了越来越多的研究者将目光投向多模态预训练。本质上,多模态预训练期望学习到两种或多种模态间的关联关系。学术界的多模态预训练方案多基于Transformer模块,在应用上集中于图文任务,方案大多大同小异,主要差异在于采用模型结构与训练任务的差异组合,多模态预训练的下游任务可以是常规的分类识别、视觉问答、视觉理解推断任务等等。VideoBERT是多模态预训练的第一个作品,它基于BERT训练大量未标记的视频文本对。目前,针对图像和文本的多模态预训练模型主要可以分为单流模型和双流模型两种架构。VideoBERT,B2T2, VisualBERT, Unicoder-VL , VL-BERT和UNITER使用了单流架构,即利用单个Transformer的self-attention机制同时建模图像和文本信息。另一方面,LXMERT、ViLBERT和FashionBERT引入了双流架构,首先独立提取图像和文本的特征,然后使用更复杂的cross-attention机制来完成它们的交互。为了进一步提高性能,VLP应用了一个共享的多层Transformer进行编码和解码,用于图像字幕和VQA。基于单流架构,InterBERT将两个独立的Transformer流添加到单流模型的输出中,以捕获模态独立性。
3 知识增强的预训练
近年来,越来越多的研究人员开始关注知识图(KG)和预训练语言模型(PLM)的结合,以使PLM达到更好的性能。K-BERT将三元组注入到句子中,以生成统一的知识丰富的语言表示。ERNIE将知识模块中的实体表示集成到语义模块中,将令牌和实体的异构信息表示到一个统一的特征空间中。KEPLER将实体的文本描述编码为文本嵌入,并将描述嵌入视为实体嵌入。KnowBERT使用一个集成的实体链接器,通过一种单词到实体的注意形式生成知识增强的实体广度表示。KAdapter为RoBERTa注入了事实知识和语言知识,并为每种注入的知识提供了神经适配器。DKPLM可以根据文本上下文动态地选择和嵌入知识,同时感知全局和局部KG信息。JAKET提出了一个联合预训练框架,其中包括为实体生成嵌入的知识模块,以便在图中生成上下文感知的嵌入。KALM、ProQA、LIBERT等研究还探索了知识图与PLM在不同应用任务中的融合实验。然而,目前的知识增强的预训练模型仅针对单一模态,尤其是文本模态,而将知识图融入多模态预训练的工作几乎没有。
二 多模态商品知识图谱及问题
随着人工智能技术的不断发展,知识图谱作为人工智能领域的知识支柱,以其强大的知识表示和推理能力受到学术界和产业界的广泛关注。多模态知识图谱与传统知识图谱的主要区别是,传统知识图谱主要集中研究文本和数据库的实体和关系,而多模态知识图谱则在传统知识图谱的基础上,构建了多种模态(例如视觉模态)下的实体,以及多种模态实体间的多模态语义关系。如图1所示,在电商领域,多模态商品知识图谱通常有图像、标题和结构知识。
多模态商品知识图谱的应用场景十分广泛,多模态结构数据虽然在底层表征上是异构的,但是相同实体的不同模态数据在高层语义上是统一的,所以多种模态数据的融合有利于充分表达商品信息。多模态商品知识图谱技术可以服务于各种下游领域,例如多模态实体链接技术可以融合多种模态下的相同实体,可以广泛应用于产品对齐,明星同款等场景中,多模态问答系统对于电商推荐,商品问答领域的进步有着重大的推进作用。但目前还相当缺乏有效的技术手段来有效融合这些多模态数据,以支持广泛的电商下游应用。

图1
最近几年,一些多模态预训练技术被提出(如VLBERT、ViLBERT、LXMERT、InterBERT等),这些方法主要用于挖掘图像模态与文本模态信息之间的关联。然而,将这些多模态预训练方法直接应用到电子商务场景中会产生问题,一方面,这些模型不能建模多模态商品知识图谱的结构化信息,另一方面,在电商多模态知识图谱中,模态缺失和模态噪声是两个挑战(主要是文本和图片的缺失和噪声),这将严重降低多模态信息学习的性能。在真实的电子商务场景中,有的卖家没有将商品图片(或标题)上传到平台,有的卖家提供的商品图片(或标题)没有正确的主题或语义。图 2中的Item-2和Item-3分别显示了阿里场景中的模态噪声和模态缺失的例子。
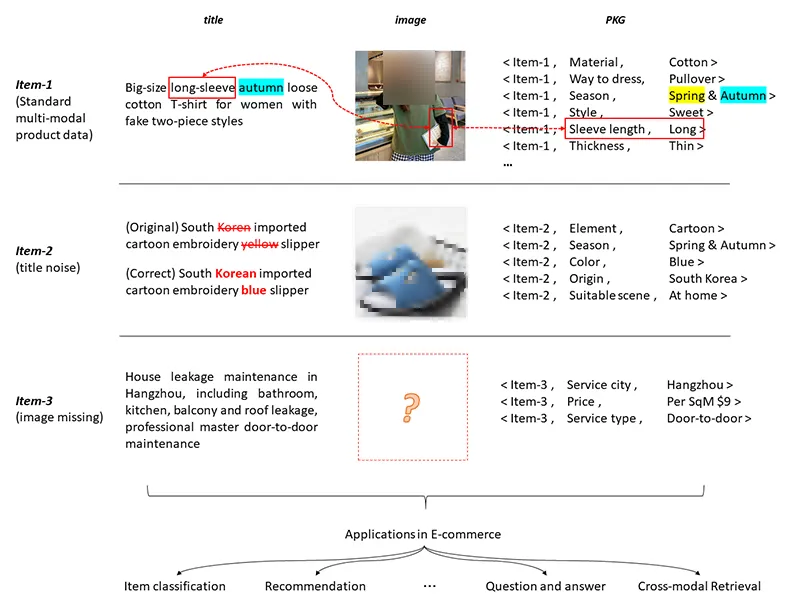
图2
三 解决方案
为了解决这一问题,我们将产品结构化知识作为一种独立于图像和文本的新的模态,称为知识模态,即对于产品数据的预训练,我们考虑了三种模态的信息:图像模态(产品图像)、文本模态(产品标题)和知识模态(PKG)。如图2所示,PKG包含<h, r, t>形式的三元组。例如,<Item-1, Material,Cotton>表示产品Item-1的材质是棉花。我们这样处理的原因在于,(1)PKG描述了产品的客观特性,它结构化且易于管理,通常为PKG做了很多维护和标准化工作,所以PKG相对干净可信。(2) PKG与其他模态包含的信息有重合也有互补,以图2的Item-1为例,从图片、标题和PKG都可以看出Item-1是一件长袖t恤;另一方面,PKG表明这款t恤不仅适合秋季,也适合春季,但从图片和标题看不出来。因此,当存在模态噪声或模态缺失时,PKG可以纠正或补充其他模态。
四 模型架构
我们提出了一种在电子商务应用中新颖的知识感知的多模态预训练方法K3M。模型架构如图3所示,K3M通过3个步骤学习产品的多模态信息:(1)对每个模态的独立信息进行编码,对应modal-encoding layer,(2)对模态之间的相互作用进行建模,对应modal-interaction layer,(3)通过各个模态的监督信息优化模型,对应modal-task layer。

图3
(1)modal-encoding layer。在对每个模态的单个信息进行编码时,针对图像模态、文本模态以及知识模态,我们采用基于Transformer的编码器提取图像、文本、三元组表面形式的初始特征。其中文本模态和知识模态的编码器参数共享。
(2)modal-interaction layer。当建模模式之间的相互作用时,有两个过程。第一个过程是文本模态和图像模态之间的交互:首先通过co-attention Transformer基于图像和文本模态的初始特征学习对应的交互特征,其次,为了保持单个模态的独立性,我们提出通过初始交互特征融合模块来融合图像和文本模态的初始特征及其交互特征。第二个过程是知识模态和其他两个模态的交互:首先用图像和文本模式的交互结果作为目标产品的初始表示,用三元组关系和尾实体的表面形态特征作为的商品属性和属性值的表示。然后通过结构聚合模块传播并在目标产品实体上聚合商品属性和属性值信息。商品实体的最终表示可以用于各种下游任务。
(3)modal-task layer。图像模态、文本模态和知识模态的预训练任务分别为掩码对象模型、掩码语言模型和链接预测模型。
五 实验与实践
1 实验(论文的实验)
K3M在淘宝4千万商品上训练,其中每个商品包含一个标题,一张图片和一组相关的三元组。我们设置不同的模态缺失和噪音比率,在商品分类、产品对齐以及多模态问答3个下游任务上评估了K3M的效果,并与几个常用的多模态预训练模型对比:单流模型VLBERT,和两个双流模型ViLBERT和LXMERT。实验结果如下:

图3显示了各种模型对商品分类的结果,可以观察到: (1)当模态缺失或模态噪声存在时,基线模型严重缺乏鲁棒性。当TMR增加到20%、50%、80%和100%时,“ViLBERT”、“LXMERT”和“VLBERT”的性能从TMR=0%平均下降10.2%、24.4%、33.1%和40.2%。(2)带有缺失和噪声的文本模态对性能的影响大于图像模态。对比3个基线的“标题噪声”和“图像噪声”,随着TNR的增加,模型性能下降了15.1% ~ 43.9%,而随着INR的增加,模型性能下降了2.8% ~ 10.3%,说明文本信息的作用更为重要。(3)引入知识图可以显著改善模态缺失和模态噪声问题。在无PKG基线的基础上,“ViLBERT+PKG”、“LXMERT+PKG”和“VLBERT+PKG”在TMR从0%增加到100%时的平均改善率分别为13.0%、22.2%、39.9%、54.4%和70.1%。(4)K3M达到了最先进的性能。它将 “ViLBERT+PKG”、“LXMERT+PKG”和“VLBERT+PKG”在各种模态缺失和模态噪声设置下的结果提高了0.6%到4.5%。

图4显示了产品对齐任务的结果。在这个任务中,我们可以得到类似于在项目分类任务中的观察结果。此外,对于模态缺失,模型性能不一定随着缺失率的增加而降低,而是波动的:当缺失率(TMR、IMR和MMR)为50%或80%时,模型性能有时甚至比100%时更低。实际上,这个任务的本质是学习一个模型来评估两个项目的多模态信息的相似性。直觉上,当对齐的商品对中的两个项目同时缺少标题或图像时,它们的信息看起来比一个项目缺少标题或图像而另一个项目什么都不缺时更相似。

表2显示了多模态问答任务的排序结果。在这个任务中,我们也可以看到类似于在商品分类任务中的观察结果。
2 实践(阿里的业务应用效果)
1、饿了么新零售导购算法,离线算法AUC提升0.2%绝对值;在线AB-Test实验,流量5%,5天:CTR平均提高0.296%,CVR平均提高5.214%,CTR+CVR平均提高:5.51%;
2、淘宝主搜找相似服务,离线算法AUC提升1%,业务方反馈是很大的提升;目前在线AB测试中;
3、阿里妈妈年货节商品组合算法,在线算法,基于Emedding的实验桶(5.52%)CTR指标相较于另外2个实验桶(5.50%,5.48%)分别提高0.02%、0.04%的点击率,相对提高分别为0.363%、0.73%;
4、小蜜算法团队低意愿下的相似商品的推荐,整体增加这一路的召回情况下,转化能有2.3%到2.7%左右的提升,相对提升12.5%。之前版本相对提升11%。后续扩展到其他场景。
原文链接
本文为阿里云原创内容,未经允许不得转载。
ACMMM2021|在多模态训练中融入“知识+图谱”:方法及电商应用实践的更多相关文章
- 【机器学习】DNN训练中的问题与方法
感谢中国人民大学的胡鹤老师,人工智能课程讲的很有深度,与时俱进 由于深度神经网络(DNN)层数很多,每次训练都是逐层由后至前传递.传递项<1,梯度可能变得非常小趋于0,以此来训练网络几乎不会有什 ...
- 知识图谱-生物信息学-医学顶刊论文(Bioinformatics-2021)-MSTE: 基于多向语义关系的有效KGE用于多药副作用预测
MSTE: 基于多向语义关系的有效KGE用于多药副作用预测 论文标题: Effective knowledge graph embeddings based on multidirectional s ...
- 知识图谱顶刊综述 - (2021年4月) A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
知识图谱综述(2021.4) 论文地址:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications 目录 知 ...
- 百度大脑UNIT3.0详解之知识图谱与对话
如今,越来越多的企业想要在电商客服.法律顾问等领域做一套包含行业知识的智能对话系统,而行业或领域知识的积累.构建.抽取等工作对于企业来说是个不小的难题,百度大脑UNIT3.0推出「我的知识」版块专门为 ...
- 知识图谱如何运用于RecomSys
将知识图谱作为辅助信息引入到推荐系统中可以有效地解决传统推荐系统存在的稀疏性和冷启动问题,近几年有很多研究人员在做相关的工作.目前,将知识图谱特征学习应用到推荐系统中主要通过三种方式——依次学习.联合 ...
- ISWC 2018概览:知识图谱与机器学习
语义网的愿景活跃且良好,广泛应用于行业 语义网的愿景是「对计算机有意义」的数据网络(正如 Tim Berners Lee.James Hendler 和 Ora Lassila 在<科学美国人& ...
- 知识图谱-生物信息学-医学论文(Chip-2022)-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用
16.(2022)Chip-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用 论文标题: Construction and Application of Chinese Breast Cance ...
- 知识图谱顶会论文(SIGIR-2022) MorsE:归纳知识图嵌入的元知识迁移
MorsE:归纳知识图嵌入的元知识迁移 论文题目: Meta-Knowledge Transfer for Inductive Knowledge Graph Embedding 论文地址: http ...
- NLP知识图谱项目合集(信息抽取、文本分类、图神经网络、性能优化等)
NLP知识图谱项目合集(信息抽取.文本分类.图神经网络.性能优化等) 这段时间完成了很多大大小小的小项目,现在做一个整体归纳方便学习和收藏,有利于持续学习. 1. 信息抽取项目合集 1.PaddleN ...
- 知识图谱与机器学习|KG入门 -- Part2 建立知识图谱
介绍 在本系列前面两篇文章中我一直在讨论Data Fabric,并给出了一些关于Data Fabric中的机器学习和深度学习的概念.并给出了我对Data Fabric的定义: Data Fabric是 ...
随机推荐
- InfluxDB、Grafana、node_exporter、Prometheus搭建压测平台
InfluxDB.Grafana.node_exporter.Prometheus搭建压测平台 我们的压测平台的架构图如下: 配置docker环境 1)yum 包更新到最新 sudo yum upda ...
- 使用自签名证书在Docker中部署Asp.Net Core(Abp)项目
一 编写Dockerfile文件 FROM mcr.microsoft.com/dotnet/aspnet:6.0 COPY / /app WORKDIR /app EXPOSE 80 ENTRYPO ...
- 基于SCCB协议的FPGA实现
SCCB协议 1.协议内容 SCCB协议常用于vo系列的摄像头的寄存器配置中,是有IIC协议演变而来.本来,本人接触这个协议也是想配置摄像头用于摄像模块.但是,由于配置寄存器实在是太多,而且需要找的资 ...
- KingbaseES V8R6集群运维案例之---sys_hba.conf限制客户端访问数据库
KingbaseES V8R6集群运维案例之---sys_hba.conf限制客户端访问数据库 案例说明: 客户端认证是由一个配置文件(通常名为sys_hba.conf并被存放在数据库集簇目录中)控制 ...
- KingbaseES PLSQL 支持语句级回滚
KingbaseES默认如果在PLSQL-block 执行过程中的任何SQL 语句导致错误,都会导致该事务的所有语句都被回滚,而Oracle 则是语句级的回滚.KingbaseES 为了更好的与 Or ...
- KingbaseES V8R6 空闲事务会话超时自动终止机制
背景 如果会话在事务中停留的时间过长,则允许自动终止空闲会话.可以由配置参数idle_in_transaction_session_timeout 事务处于空闲状态的时长,它有助于防止被遗忘的交易事务 ...
- 一个可以让你有更多时间摸鱼的WPF控件(二)
前言 上文介绍了如何通过一个Form自定义控件来简化数据的录入,并自动实现数据校验,自动布局排列等功能.本文继续介绍如何优化表格控件的使用,缩减代码量,实现工作效率的提升. 一.功能实现 上文中分析了 ...
- MySQL配置和常用命令
目录 数据库配置 常用操作 项目地址:https://github.com/aijisjtu/Bot-Battle graph LR A[配置数据源] --> B[建立连接] B --> ...
- 15 JavaScript ES6中的箭头函数
15 JavaScript ES6中的箭头函数 什么是箭头函数 ES6中允许使用=>来定义函数.箭头函数相当于匿名函数,并简化了函数定义. 基本语法 // 箭头函数 let fn = (name ...
- 2023 LGR 非专业级别软件能力认证第一轮(初赛)S组
计算器.背包.代码都不能带进考场 禁赛三年并全国通报 B选项符合while语句 弱类型编程语言指的是可以进行类型转换,可以参与各种类型变量的运算 \[3\times 60(秒)\times 44.1\ ...