ElasticSearch IK 分词器快速上手
简介: ElasticSearch IK 分词器快速上手
一、安装 IK 分词器
1.分配伪终端
我的 ElasticSearch 是使用 Docker 安装的,所以先给容器分配一个伪终端.之后就可以像登录服务器一样直接操作docker 中的内容了
docker exec -it 容器ID /bin/bash
2.使用 elasticsearch-plugin 安装插件
cd plugins进入到 plugins 文件夹
执行如下命令,7.12.0 需要修改成你的 es 版本号
../bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.0/elasticsearch-analysis-ik-7.12.0.zip
3.重启 elasticsearch 容器
docker restart 容器ID
4.常见问题
(1)java.lang.IllegalStateException
执行elasticsearch-plugin install的时候,出现了 Failed installing和java.lang.IllegalStateException
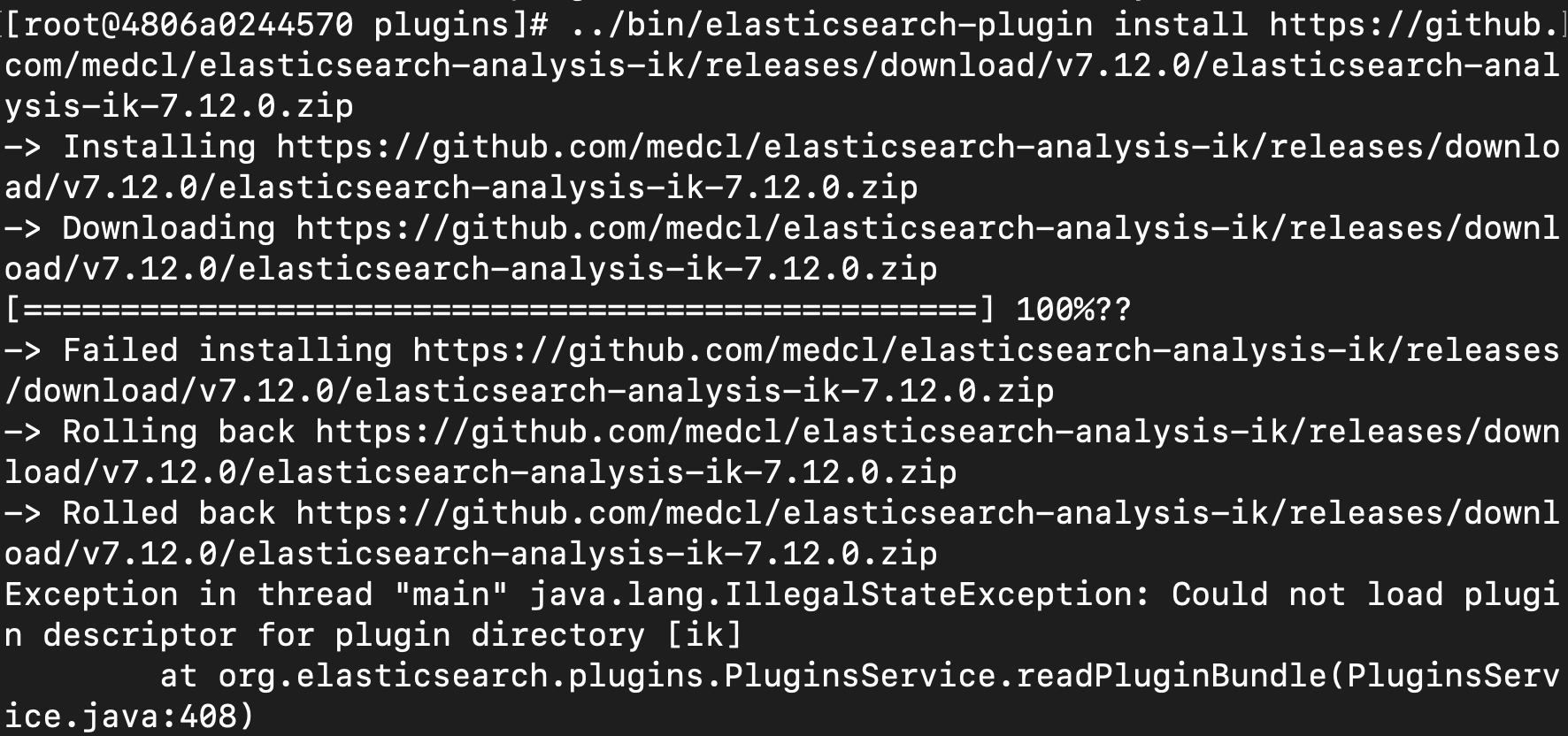
查看了一下,我的 plugins/ 目录下已经有一个名为 ik 的文件夹了.
抱着试试的心态,删掉了这个名为 ik 的文件夹,重新执行
../bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.0/elasticsearch-analysis-ik-7.12.0.zip
安装成功
二、ik 分词原理
(占位,等有时间读源码再来补充)
三、ik_smart 和 ik_max_word
GET _analyze?pretty
{
"analyzer": "ik_smart",
"text": "不像我,只会心疼鸽鸽"
}

GET _analyze?pretty
{
"analyzer": "ik_max_word",
"text": "不像我,只会心疼鸽鸽"
}

结论
- _analyzer构建索引时候的分词,索引的时候使用 max_word
- search_analyzer搜索时的分词,查询的时候使用 smart
原文链接
本文为阿里云原创内容,未经允许不得转载。
ElasticSearch IK 分词器快速上手的更多相关文章
- Elasticsearch IK分词器
Elasticsearch-IK分词器 一.简介 因为Elasticsearch中默认的标准分词器(analyze)对中文分词不是很友好,会将中文词语拆分成一个一个中文的汉字,所以引入中文分词器-IK ...
- SpringBoot整合Elasticsearch+ik分词器+kibana
话不多说直接开整 首先是版本对应,SpringBoot和ES之间的版本必须要按照官方给的对照表进行安装,最新版本对照表如下: (官网链接:https://docs.spring.io/spring-d ...
- 七、Elasticsearch+elasticsearch-head的安装+Kibana环境搭建+ik分词器安装
一.安装JDK1.8 二.安装ES 三个节点:master.slave01.slave02 1.这里下载的是elasticsearch-6.3.1.rpm版本包 https://www.elastic ...
- IK 分词器
目录 IK 分词器-介绍 IK 分词器-安装 环境准备:Maven 安装 IK 分词器 IK 分词器-使用 IK 分词器-介绍 现有问题:ES 默认对中文分词并不友好,实际上是把中文进行了每个字的分词 ...
- Elasticsearch教程(三),IK分词器安装 (极速版)
如果只想快速安装IK,本教程管用.下面看经过. 简介: 下面讲有我已经打包并且编辑过的zip包,你可以在下面下载即可. 当前讲解的IK分词器 包的 version 为1.8. 一.下载zip包. 下面 ...
- Elasticsearch入门之从零开始安装ik分词器
起因 需要在ES中使用聚合进行统计分析,但是聚合字段值为中文,ES的默认分词器对于中文支持非常不友好:会把完整的中文词语拆分为一系列独立的汉字进行聚合,显然这并不是我的初衷.我们来看个实例: POST ...
- docker上安装elasticsearch和ik分词器插件和header,实现分词功能
docker run -di --name=tensquare_es -p 9200: -p 9300:9300 elasticsearch:5.6.8 创建elasticsearch容器(如果版本不 ...
- Elasticsearch下安装ik分词器
安装ik分词器(必须安装maven) 上传相应jar包 解压到相应目录 unzip elasticsearch-analysis-ik-master.zip(zip包) cp -r elasticse ...
- elasticsearch安装ik分词器(极速版)
简介:下面讲有我已经打包并且编辑过的zip包,你可以在下面下载即可. 1.下载zip包.elasticsearch-analysis-ik-1.8.0.jar下面有附件链接[ik-安装包.zip],下 ...
- 【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod ...
随机推荐
- Ubuntu 14.04 升级到Gnome3.12z的折腾之旅(警示后来者)+推荐Extensions.-------(二)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文发布于 2014-12-22 15:33:35 ...
- 如何在UE4中播放本地视频文件?
在UE4中有一套媒体框架方法,它根据视频源的不同,对应的播放方式也不一样,支持的视频源有本地视频文件.影像序列.视频流.实时视频截图.播放形式可选择在场景内的静态网格上播放或者以UI的形式播放.本文主 ...
- Java原生序列化与反序列化
序列化与反序列化 Java序列化是指把Java对象转换为字节序列的过程;而Java反序列化是指把字节序列恢复为Java对象的过程. 为什么需要序列化? 序列化分为两大部分:序列化和反序列化.序列化是这 ...
- FFmpeg开发笔记(六)如何访问Github下载FFmpeg源码
学习FFmpeg的时候,经常要到GitHub下载各种开源代码,比如FFmpeg的源码页面位于https://github.com/FFmpeg/FFmpeg.然而国内访问GitHub很不稳定,经常打 ...
- KingbaseES V8R6集群运维案例之---sys_monitor.sh start启动动态库错误
案例说明: 在KingbaseES V8R6集群部署了postgis后,执行sys_monitor.sh start启动集群时,出现动态库错误,如下图所示: 适用版本: KingbaseES V8R6 ...
- Java 数学运算与条件语句全解析
Java Math Java 的 Math 类 拥有许多方法,允许您在数字上执行数学任务. 常用方法: Math.max(x, y): 找到 x 和 y 的最大值 Math.min(x, y): 找到 ...
- C++ 编译器和链接器的完全指南
C++是一种强类型语言,它的编译和链接是程序开发过程中不可或缺的两个环节.编译器和链接器是两个非常重要的概念.本文将详细介绍C++中的编译器和链接器以及它们的工作原理和使用方法. 编译器 编译器是将源 ...
- Python 安装与快速入门
Python安装 许多PC和Mac已经预装了Python. 要检查在Windows PC上是否安装了Python,请在开始菜单中搜索Python,或在命令行(cmd.exe)上运行以下命令: C:\U ...
- unknow or unsupported command install
错误原因: 今天使用pip下载labelimg时,出现了"unknow or unsupported command install"的错误,这是由于电脑有多个pip文件路径所导致 ...
- Redis 02 基础命令
数据库 Redis 默认有 16 个数据库. 默认使用的是第 0 个数据库. 不同数据库存不同的值. 切换数据库 select 127.0.0.1:6379> select 1 OK 127.0 ...