postgresql性能优化3:分区表
一、分区表产生的背景
随着使用时间的增加,数据库中的数据量也不断增加,因此数据库查询越来越慢。
加速数据库的方法很多,如添加特定的索引,将日志目录换到单独的磁盘分区,调整数据库引擎的参数等。这些方法都能将数据库的查询性能提高到一定程度。
对于许多应用数据库来说,许多数据是历史数据并且随着时间的推移它们的重要性逐渐降低。如果能找到一个办法将这些可能不太重要的数据隐藏,数据库查询速度将会大幅提高。可以通过DELETE来达到此目的,但同时这些数据就永远不可用了。
因此,需要一个高效的把历史数据从当前查询中隐藏起来并且不造成数据丢失的方法。本文即将介绍的数据库表分区即能达到此效果。
二、分区表结构图
数据库表分区把一个大的物理表分成若干个小的物理表,并使得这些小物理表在逻辑上可以被当成一张表来使用。
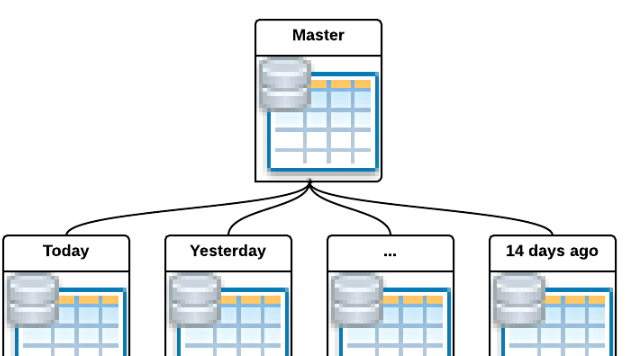
主表/父表/Master Table该表是创建子表的模板。它是一个正常的普通表,但正常情况下它并不储存任何数据。子表/分区表/Child Table/Partition Table这些表继承并属于一个主表。子表中存储所有的数据。主表与分区表属于一对多的关系,也就是说,一个主表包含多个分区表,而一个分区表只从属于一个主表
三、PostgreSQL各个版本 的分区表功能
分区表在不同的文档描述中使用了多个名词:原生分区 = 内置分区表 = 分区表。
PostgreSQL 9.x 之前的版本提供了一种“手动”方式使用分区表的方式,需要使用继承 + 触发器的来实现分区表,使用继承关键字INHERITS,步骤较为繁琐,需要定义附表、子表、子表的约束、创建子表索引,创建分区删除、修改,触发器等。
PostgreSQL 10.x 开始提供了内置分区表(内置是相对于 10.x 之前的手动方式)。内置分区简化了操作,将部分操作内置,最终简单三步就能够创建分区表。但是只支持范围分区(RANGE)和列表分区(LIST),
PostgreSQL 11.x 版本添加了对 HASH 分区。
本文将使用 PostgreSQL 10.x 版本及后续版本中的的内置分区表的使用方式,通过三步来创建分区表
1,创建父表------------指定分区键、分区策略(RANGE | LIST | HASH(11.x 才提供HASH策略))
2,创建分区表----------指定父表,分区键范围(分区键范围重叠之后会直接报错)
3,在分区上创建索引-----通常分区键上的索引是必须的
四、几种分区策略
PostgreSQL内置支持以下3种方式的分区:
1、范围(Range )分区:表被划分为由键列或列集定义的“范围”,分配给不同分区的值的范围之间没有重叠。例如:可以按日期范围或特定业务对象的标识符范围,来进行分区。
2、列表(List)分区:通过显式列出哪些键值出现在每个分区中来对表进行分区。
3、哈希(Hash)分区:(自PG11才提供HASH策略)通过为每个分区指定模数和余数来对表进行分区。每个分区将保存行,分区键的哈希值除以指定的模数将产生指定的余数。
五、建立分区实例
1、创建父表
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
2、创建分区表
CREATE TABLE measurement_200711 PARTITION OF measurement
FOR VALUES FROM ('2007-11-01') TO ('2007-12-01'); CREATE TABLE measurement_200712 PARTITION OF measurement
FOR VALUES FROM ('2007-12-01') TO ('2008-01-01')
TABLESPACE fasttablespace; CREATE TABLE measurement_200801 PARTITION OF measurement
FOR VALUES FROM ('2008-01-01') TO ('2008-02-01')
3、创建索引
CREATE INDEX index_measurement ON measurement USING btree(logdate);
4、 postgresql.conf配置
(1) enable_partition_pruning=on (分区修剪)启用,否则,查询将不会被优化。
如果不进行分区修剪,上述查询将扫描父表 measurement 的每个分区。启用分区修剪后,计划器将检查每个分区的定义并证明不需要扫描该分区,因为该分区不能包含满足查询的WHERE子句的任何行。当计划器可以证明这一点时,它将从查询计划中排除(修剪)该分区。
(2)constraint_exclusion=partition ,配置项没有被disable 。这一点非常重要,如果该参数项被disable,则基于分区表的查询性能无法得到优化,甚至比不使用分区表直接使用索引性能更低。
5、维护分区
Analyze measurement
六、要建立默认分区
默认分区,用于处理没有分区表的异常插入情况,用于存储无法匹配其他任何分区表的数据。显然,只有 RANGE 分区表和 LIST 分区表需要默认分区。
创建默认分区时,使用 DEFAULT 子句替代 FOR VALUES 子句。
CREATE TABLE measurement_default PARTITION OF measurement DEFAULT;
七、分区表不能自动建,怎么办?
方法1:利用定时器,定时某段时间创建分区表,可以利用操作系统定时器或者程序里面的定时任务,但是太麻烦,弃用。
方法2:编写存储过程脚本,一次性生成未来3年,未来10年的多个分区表,下面给出存储过程的脚本。这不是最优解,后面还提供了方法3。
tablepartitionsadd_day,按天生成分区表,一天一个分区表
CREATE OR REPLACE FUNCTION public.tablepartitionsadd_day(
p_tablename text,
p_schema text,
p_date_start text,
p_step integer)
RETURNS void
LANGUAGE 'plpgsql'
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
declare
v_cnt int;
v_schema_name varchar(500);
v_table_name varchar(500);
v_curr_limit varchar(50);
v_curr_limit1 varchar(50);
v_steps int;
v_exec_sql text;
v_partition_name text;
v_date_start text;
--select tablePartitionsAdd_day('wry_gasfachourzsdata','public','2018-12-01',365),从2018-12-01的下1天开始
begin
v_schema_name = p_schema;
v_table_name = p_tablename;
v_date_start = p_date_start;
v_steps = p_step;
v_exec_sql = ' ';
for i in 0 .. v_steps loop
v_curr_limit = to_char(to_date(v_date_start,'yyyy-mm-dd') + i,'yyyy-mm-dd');
v_curr_limit1 = to_char(to_date(v_curr_limit,'yyyy-mm-dd') + 1,'yyyy-mm-dd');
v_partition_name = to_char(to_date(v_date_start,'yyyy-mm-dd') + i, 'yyyymmdd');
SELECT count(1) into v_cnt from pg_tables where schemaname=v_schema_name and tablename = v_table_name||'_'||v_partition_name;
if v_cnt = 0 then
v_exec_sql = v_exec_sql||' create table '||v_schema_name||'.'||v_table_name||'_'||v_partition_name||' partition of '||v_table_name||' for values FROM ('''||v_curr_limit||' 00:00:00'||''') TO ('''||v_curr_limit1||' 00:00:00'||''');';
end if;
end loop;
execute v_exec_sql;
end;
$BODY$;
tablepartitionsadd_month,按月生成分区表,一月一个分区表
CREATE OR REPLACE FUNCTION public.tablepartitionsadd_month(
p_tablename text,
p_schema text,
p_date_start text,
p_step integer)
RETURNS void
LANGUAGE 'plpgsql'
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
declare
v_cnt int;
v_schema_name varchar(500);
v_table_name varchar(500);
v_curr_limit varchar(50);
v_curr_limit1 varchar(50);
v_steps int;
v_exec_sql text;
v_partition_name text;
v_date_start text;
--select tablePartitionsAdd_month('wry_gasfachourzsdata','public','2018-12-01',36),从2018-12-01的下个月开始
begin
v_schema_name = p_schema;
v_table_name = p_tablename;
v_date_start = p_date_start;
v_steps = p_step;
v_exec_sql = ' ';
v_curr_limit=v_date_start;
for i in 1 .. v_steps loop
v_curr_limit = to_char(to_date(v_curr_limit,'yyyy-mm-dd') +interval '1 month','yyyy-mm-dd');
v_curr_limit1 = to_char(to_date(v_curr_limit,'yyyy-mm-dd') +interval '1 month','yyyy-mm-dd');
v_partition_name = to_char(to_date(v_curr_limit,'yyyy-mm-dd'), 'yyyymm');
SELECT count(1) into v_cnt from pg_tables where schemaname=v_schema_name and tablename = v_table_name||'_'||v_partition_name;
if v_cnt = 0 then
v_exec_sql = v_exec_sql||' create table '||v_schema_name||'.'||v_table_name||'_'||v_partition_name||' partition of '||v_table_name||' for values FROM ('''||v_curr_limit||' 00:00:00'||''') TO ('''||v_curr_limit1||' 00:00:00'||''');';
end if;
end loop;
execute v_exec_sql;
end;
$BODY$;
tablepartitionsadd_year,按年生成分区表,一年一个分区表
CREATE OR REPLACE FUNCTION public.tablepartitionsadd_year(
p_tablename text,
p_schema text,
p_date_start text,
p_step integer)
RETURNS void
LANGUAGE 'plpgsql'
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
declare
v_cnt int;
v_schema_name varchar(500);
v_table_name varchar(500);
v_curr_limit varchar(50);
v_curr_limit1 varchar(50);
v_steps int;
v_exec_sql text;
v_partition_name text;
v_date_start text;
--select tablePartitionsAdd_month('wry_gasfachourzsdata','public','2018-01-01',36),从2018-01-01的下个年开始
begin
v_schema_name = p_schema;
v_table_name = p_tablename;
v_date_start = p_date_start;
v_steps = p_step;
v_exec_sql = ' ';
v_curr_limit=v_date_start;
for i in 1 .. v_steps loop
v_curr_limit = to_char(to_date(v_curr_limit,'yyyy-mm-dd') +interval '1 year','yyyy-mm-dd');
v_curr_limit1 = to_char(to_date(v_curr_limit,'yyyy-mm-dd') +interval '1 year','yyyy-mm-dd');
v_partition_name = to_char(to_date(v_curr_limit,'yyyy-mm-dd'), 'yyyy');
SELECT count(1) into v_cnt from pg_tables where schemaname=v_schema_name and tablename = v_table_name||'_'||v_partition_name;
if v_cnt = 0 then
v_exec_sql = v_exec_sql||' create table '||v_schema_name||'.'||v_table_name||'_'||v_partition_name||' partition of '||v_table_name||' for values FROM ('''||v_curr_limit||' 00:00:00'||''') TO ('''||v_curr_limit1||' 00:00:00'||''');';
end if;
end loop;
execute v_exec_sql;
end;
$BODY$;
方法3:利用insert触发器脚本,在触发器里面判断时间,然后建分区表和建索引。(网上很多都是老的继承INHERITS方法的触发器)。
这个方法有个问题:插入数据时,因为锁表的原因,无法修改分区表定义。
使用应用程序逻辑:在插入数据之前,您的应用程序可以检查需要的分区是否存在,并在必要时创建它。这意味着DDL操作与DML操作是分离的。
定期任务:设置一个定期任务(如cron作业),预先为未来的日期创建分区。例如,您可以每月或每周运行此任务,为接下来的月份或周创建分区。
通知/监听模式:当插入失败(因为缺少分区)时,您可以捕获这个错误,并触发一个外部进程来创建缺失的分区。这比较复杂,并可能需要一些时间来实现。
后插入处理:在插入失败时(例如,由于缺少分区),将数据写入到一个备用表或队列中。然后,定期从那里移动数据到主表,并在此过程中创建任何缺失的分区。
下面是使用通知/监听模式的解决办法:
使用
LISTEN和NOTIFY:PostgreSQL提供了LISTEN和NOTIFY命令,允许客户端监听特定的通知事件并对其做出响应。处理流程:
- 当插入数据到分区表失败(例如,由于缺少分区)时,触发一个函数发送
NOTIFY事件,其中包含所需分区的相关信息。 - 一个外部的监听进程(或者说worker)会
LISTEN这个事件。一旦它接收到通知,它会处理通知,比如创建缺失的分区。
- 当插入数据到分区表失败(例如,由于缺少分区)时,触发一个函数发送
实施步骤:
a. 定义发送通知的函数:这个函数将在插入失败时被调用。
CREATE OR REPLACE FUNCTION notify_missing_partition(date_needed DATE) RETURNS void LANGUAGE plpgsql AS $$
BEGIN
NOTIFY missing_partition, date_needed::TEXT;
END;
$$;
b. 修改应用逻辑:当您尝试插入数据并遇到错误(例如,由于缺少分区)时,调用上面定义的
notify_missing_partition函数。c. 创建外部监听进程:这个进程会持续监听
missing_partition事件。当它接收到通知时,它会解析日期,检查分区是否确实不存在,然后创建所需的分区。这可以使用PostgreSQL的驱动和您选择的编程语言来实现。
以下是使用Python和psycopg2库的一个简化的示例:
import psycopg2
from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT conn = psycopg2.connect("your_connection_string")
conn.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)
cursor = conn.cursor() cursor.execute("LISTEN missing_partition;") print("Waiting for notifications on channel 'missing_partition'") while True:
conn.poll()
while conn.notifies:
notify = conn.notifies.pop(0)
print("Received NOTIFY:", notify.payload)
# Here, you'd parse the date from notify.payload, check if the partition is indeed missing, and then create the required partition.
下面是java的示例:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
import java.sql.ResultSet;
import org.postgresql.PGConnection;
import org.postgresql.PGNotification; public class PostgreSQLListener {
public static void main(String[] args) throws Exception {
// JDBC connection parameters
String url = "jdbc:postgresql://localhost:5432/your_database";
String user = "your_user";
String password = "your_password"; // Connect to the database
Connection conn = DriverManager.getConnection(url, user, password);
((PGConnection) conn).addNotificationListener(new PGNotificationListenerImpl()); // Listen to the `missing_partition` channel
try (Statement stmt = conn.createStatement()) {
stmt.execute("LISTEN missing_partition;");
while (true) {
// Wait a while to allow a notification to be received.
Thread.sleep(1000); // Check for notifications.
PGNotification[] notifications = ((PGConnection) conn).getNotifications();
if (notifications != null) {
for (PGNotification notification : notifications) {
System.out.println("Received NOTIFY: " + notification.getParameter());
// Here, you'd parse the date from notification.getParameter(), check if the partition is indeed missing, and then create the required partition.
}
}
}
}
}
} class PGNotificationListenerImpl implements org.postgresql.PGNotificationListener {
@Override
public void notification(int processId, String channelName, String payload) {
System.out.println("Received Notification: " + payload);
}
}
postgresql性能优化3:分区表的更多相关文章
- 连接postgres特别消耗cpu资源而引发的PostgreSQL性能优化考虑
由于是开发阶段,所以并没有配置postgres的参数,都是使用安装时的默认配置,以前运行也不见得有什么不正常,可是前几天我的cpu资源占用突然升高.查看进程,发现有一个postgres的进程占用CPU ...
- PostgreSQL性能优化综合案例 - 2
[调优阶段8] 1. 压力测试 pgbench -M prepared -r -c 1 -f /home/postgres/test/login0.sql -j 1 -n -T 180 -h 172. ...
- PostgreSQL性能优化综合案例 - 1
[测试模型] 设计一个包含INSERT, UPDATE, SELECT语句的业务模型用于本优化案例. [测试表] create table user_info (userid int, engname ...
- PostgreSQL之性能优化(转)
转载自:https://blog.csdn.net/huangwenyi1010/article/details/72853785 解决问题 前言 PostgreSQL的配置参数作为性能调优的一部分, ...
- [转帖]PostgreSQL 参数调整(性能优化)
PostgreSQL 参数调整(性能优化) https://www.cnblogs.com/VicLiu/p/11854730.html 知道一个 shared_pool 文章写的挺好的 还没仔细看 ...
- PostgreSQL 参数调整(性能优化)
昨天分别在外网和无外网环境下安装PostgreSQL,有外网环境下安装的相当顺利.但是在无外网环境下就是两个不同的概念了,可谓十有八折.感兴趣的同学可以搭建一下. PostgreSQL安装完成后第一件 ...
- 基于linux(CentOS7)数据库性能优化(Postgresql)
基于CentOS7数据库性能优化(Postgresql) 1. 磁盘 a) Barriers IO i. 通过查看linux是否加载libata,确定是否开 ...
- Greenplum 性能优化之路 --(二)存储格式
一.存储格式介绍 Greenplum(以下简称 GP)有2种存储格式,Heap 表和 AO 表(AORO 表,AOCO 表). Heap 表:这种存储格式是从 PostgreSQL 继承而来的,目前是 ...
- 转载:SqlServer数据库性能优化详解
本文转载自:http://blog.csdn.net/andylaudotnet/article/details/1763573 性能调节的目的是通过将网络流通.磁盘 I/O 和 CPU 时间减到最小 ...
- 【转载】我眼中的Oracle性能优化
我眼中的Oracle性能优化 大家对于一个业务系统的运行关心有如下几个方面:功能性.稳定性.效率.安全性.而一个系统的性能有包含了网络性能.应用性能.中间件性能.数据库性能等等. 今天从数据库性能的角 ...
随机推荐
- HTTP与WebSocket/WebDAV
WebSocket WebDAV
- ArrayList,LinkedList,Vector三者的区别
List 中元素是有序的,元素可以重复,因为该集合体有索引 ArrayList: 底层数据结构是数组,查询快,增删慢. 线程不安全,效率高. 当元素放满了后,默认以原长度的 50%+1 的长度加长集合 ...
- 10 JavaScrit定时器
10 JavaScrit定时器 在JS中, 有两种设置定时器的方案: // 语法规则 t = setTimeout(函数, 时间) // 经过xxx时间后, 执行xxx函数 // 5秒后打印我爱你 t ...
- #结论#洛谷 3199 [HNOI2009]最小圈
题目 求有向图最小平均权值回路. \(n\leq 3*10^3,m\leq 10^4\) 分析 设 \(f_k(x)\) 表示从点 \(x\) 出发恰好走 \(k\) 条边的最短路, 那么答案就是 \ ...
- #单调队列#JZOJ 1753 锻炼身体
题目 一个\(n*m\)的矩阵,有些格子不能经过,有\(k\)个时段, 要么停留某个格子,要么沿时段规定的方向移动,问最多能够移动多少次 \(n,m,k\leq 200\) 分析 题目已经提示了\(O ...
- #Splay#U137476 序列
题目 给定长度为\(n\)的序列\(Ai\) ,我们将按照如下操作给\(Ai\) 排序, 先找到编号最小的所在位置\(x1\) ,将\([1,x1]\) 翻转, 再找到编号第二小的所在位置\(x2\) ...
- Websphere更新应用文件
说明: 由于war包中存在安全漏洞或者需要变更里面的某个jar包,此处列举了两种更新方法,不需要重启服务器,只需重启应用. Websphere对部署好的应用更新jar包方法如下: 方式一.手动替换 ...
- Godot UI线程,Task异步和消息弹窗通知
目录 前言 线程安全 全局消息IOC注入 消息窗口搭建 最简单的消息提示 简单使用 仿Element UI ElementUI 效果 简单的Label样式 如何快速加载多个相同节点 修改一下,IOC按 ...
- mongodb基础整理篇————副本原理篇[外篇]
前言 简单介绍一下副本集的原理篇. 正文 下面是几个基本的原理: 副本之间是如何复制的? mongodb 实现此功能的方式是保存操作日志,其中包含了主节点执行的每一次操作,这和mysql比较像. op ...
- Windows代理配合Burp抓取客户端+小程序数据包
"感谢您阅读本篇博客!如果您觉得本文对您有所帮助或启发,请不吝点赞和分享给更多的朋友.您的支持是我持续创作的动力,也欢迎留言交流,让我们一起探讨技术,共同成长!谢谢!" 在渗透测 ...