Redis系列之——高级用法
一 慢查询
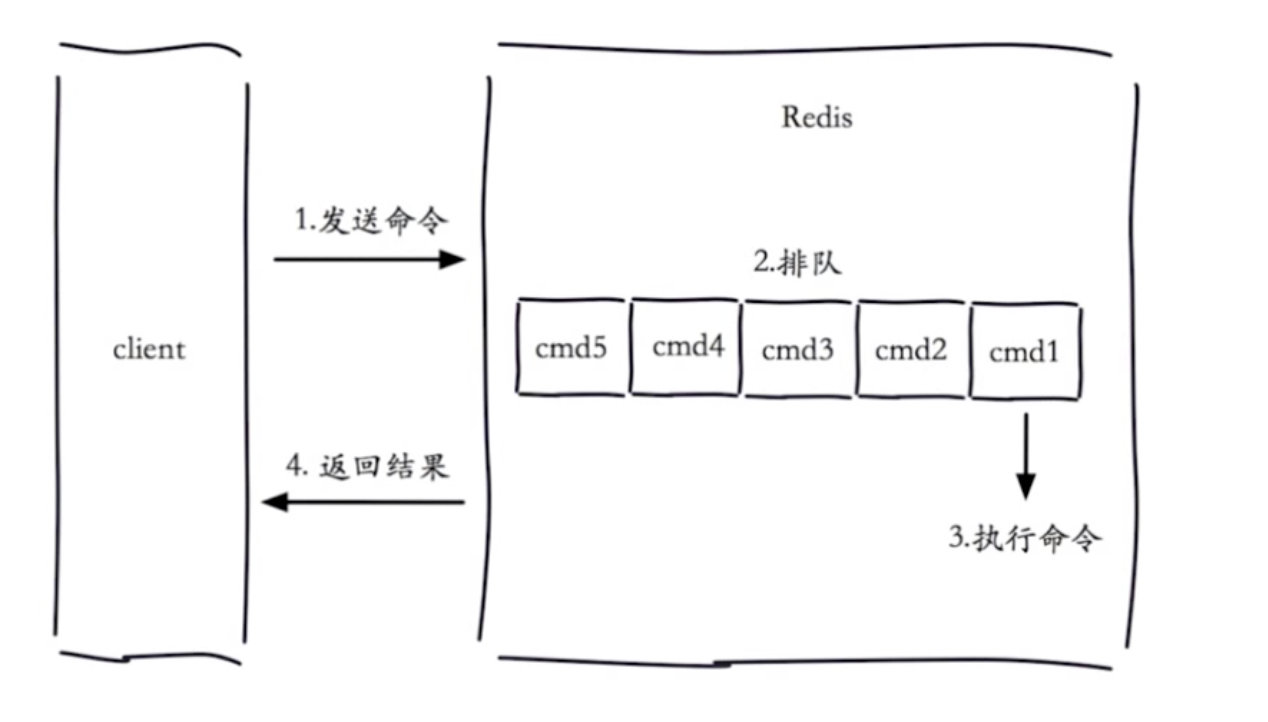
1.1 生命周期
我们配置一个时间,如果查询时间超过了我们设置的时间,我们就认为这是一个慢查询.
慢查询发生在第三阶段
客户端超时不一定慢查询,但慢查询是客户端超时的一个可能因素
1.2 两个配置
1.2.1 slowlog-max-len
慢查询是一个先进先出的队列
固定长度
保存在内存中
1.2.2 slowlog-max-len
慢查询阈值(单位:微秒)
slowlog-log-slower-than=0,记录所有命令
slowlog-log-slower-than <0,不记录任何命令
1.2.3 配置方法
1 默认配置
config get slowlog-max-len=128
Config get slowly-log-slower-than=10000
2 修改配置文件重启
3 动态配置
# 设置记录所有命令
config set slowlog-log-slower-than 0
# 最多记录100条
config set slowlog-max-len 100
# 持久化到本地配置文件
config rewrite
'''
config set slowlog-max-len 1000
config set slowlog-log-slower-than 1000
'''
1.3 三个命令
slowlog get [n] #获取慢查询队列
'''
日志由4个属性组成:
1)日志的标识id
2)发生的时间戳
3)命令耗时
4)执行的命令和参数
'''
slowlog len #获取慢查询队列长度
slowlog reset #清空慢查询队列
1.4 经验
1 slowlog-max-len 不要设置过大,默认10ms,通常设置1ms
2 slowlog-log-slower-than不要设置过小,通常设置1000左右
3 理解命令生命周期
4 定期持久化慢查询
二 pipeline与事务
2.1 什么是pipeline(管道)
Redis的pipeline(管道)功能在命令行中没有,但redis是支持pipeline的,而且在各个语言版的client中都有相应的实现
将一批命令,批量打包,在redis服务端批量计算(执行),然后把结果批量返回
1次pipeline(n条命令)=1次网络时间+n次命令时间
pipeline期间将“独占”链接,此期间将不能进行非“管道”类型的其他操作,直到pipeline关闭;如果你的pipeline的指令集很庞大,为了不干扰链接中的其他操作,你可以为pipeline操作新建Client链接,让pipeline和其他正常操作分离在2个client中。不过pipeline事实上所能容忍的操作个数,和socket-output缓冲区大小/返回结果的数据尺寸都有很大的关系;同时也意味着每个redis-server同时所能支撑的pipeline链接的个数,也是有限的,这将受限于server的物理内存或网络接口的缓冲能力
2.2 客户端实现
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
#创建pipeline
pipe = r.pipeline(transaction=True)
#开启事务
pipe.multi()
pipe.set('name', 'lqz')
#其他代码,可能出异常
pipe.set('role', 'nb')
pipe.execute()
2.3 与原生操作对比
通过pipeline提交的多次命令,在服务端执行的时候,可能会被拆成多次执行,而mget等操作,是一次性执行的,所以,pipeline执行的命令并非原子性的
2.4 使用建议
1 注意每次pipeline携带的数据量
2 pipeline每次只能作用在一个Redis的节点上
3 M(mset,mget….)操作和pipeline的区别
2.5 原生事务操作
# 1 mutil 开启事务,放到管道中一次性执行
multi # 开启事务
set name lqz
set age 18
exec
# 2 模拟事务
# 在开启事务之前,先watch
wathc age
multi
decr age
exec
# 另一台机器
mutil
decr age
exec # 先执行,上面的执行就会失败(乐观锁,被wathc的事务不会执行成功)
三 发布订阅
3.1 角色
发布者/订阅者/频道
发布者发布了消息,所有的订阅者都可以收到,就是生产者消费者模型(后订阅了,无法获取历史消息)
3.2 模型
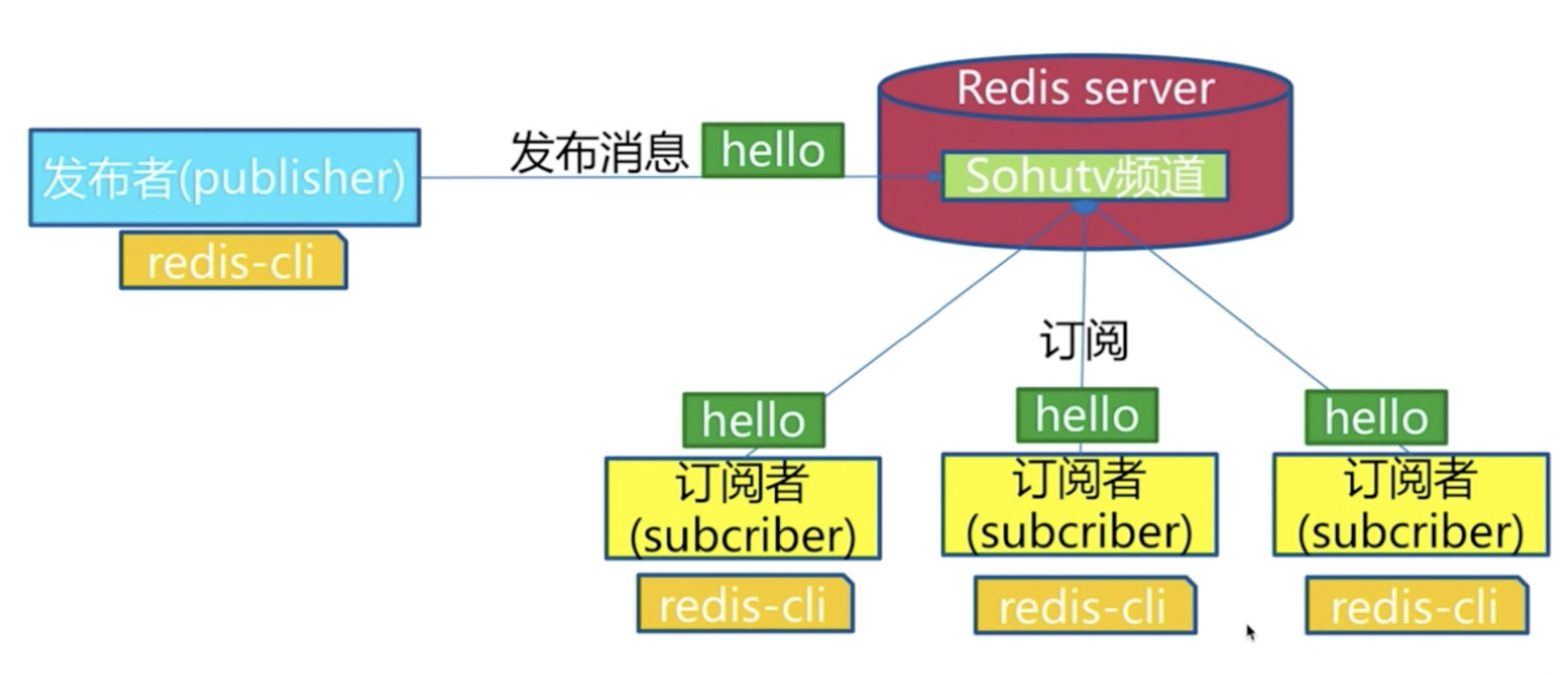
3.3 API
publish channel message #发布命令
publish souhu:tv "hello world" #在souhu:tv频道发布一条hello world 返回订阅者个数
subscribe [channel] #订阅命令,可以订阅一个或多个
subscribe souhu:tv #订阅sohu:tv频道
unsubscribe [channel] #取消订阅一个或多个频道
unsubscribe sohu:tv #取消订阅sohu:tv频道
psubscribe [pattern...] #订阅模式匹配
psubscribe c* #订阅以c开头的频道
unpsubscribe [pattern...] #按模式退订指定频道
pubsub channels #列出至少有一个订阅者的频道,列出活跃的频道
pubsub numsub [channel...] #列出给定频道的订阅者数量
pubsub numpat #列出被订阅模式的数量
3.4 发布订阅和消息队列
发布订阅数全收到,消息队列有个抢的过程,只有一个抢到
四 Bitmap位图
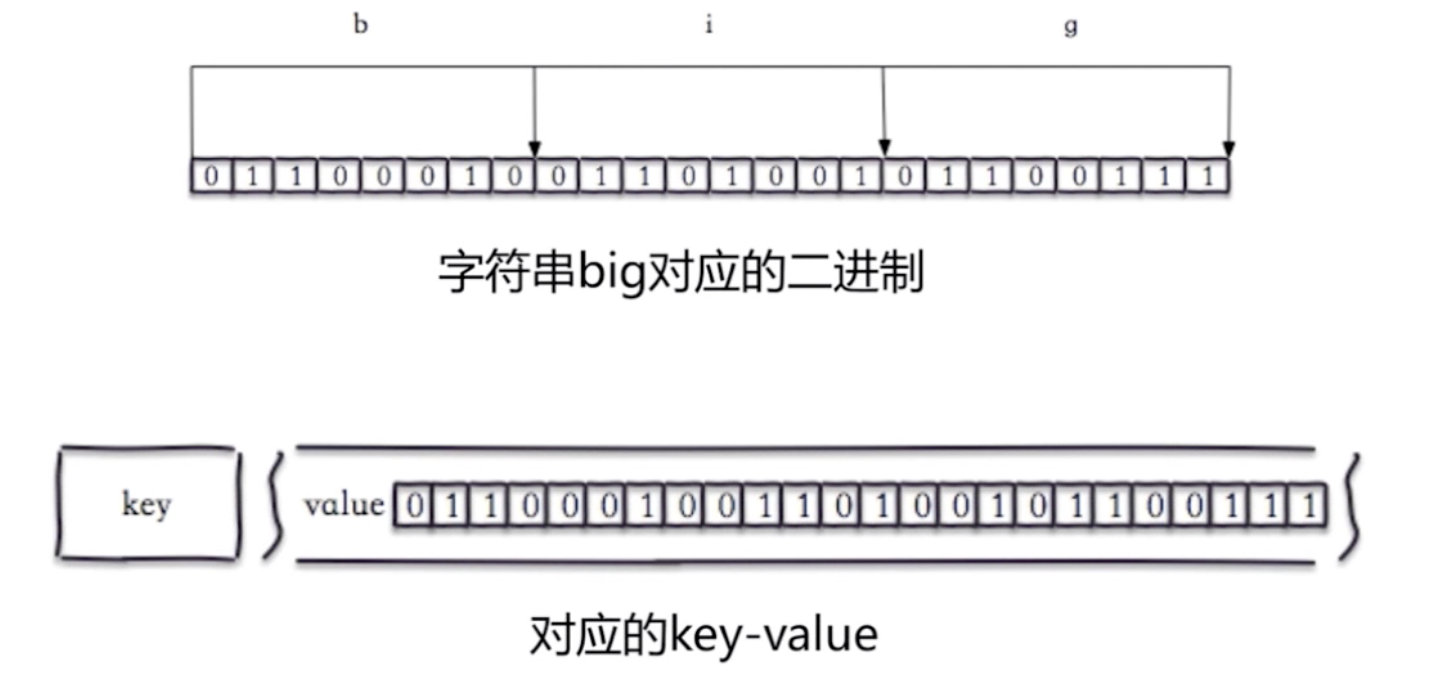
4.1 位图是什么
下面是字符串big对应的二进制(b是98)
4.2 相关命令
set hello big #放入key位hello 值为big的字符串
getbit hello 0 #取位图的第0个位置,返回0
getbit hello 1 #取位图的第1个位置,返回1 如上图
##我们可以直接操纵位
setbit key offset value #给位图指定索引设置值
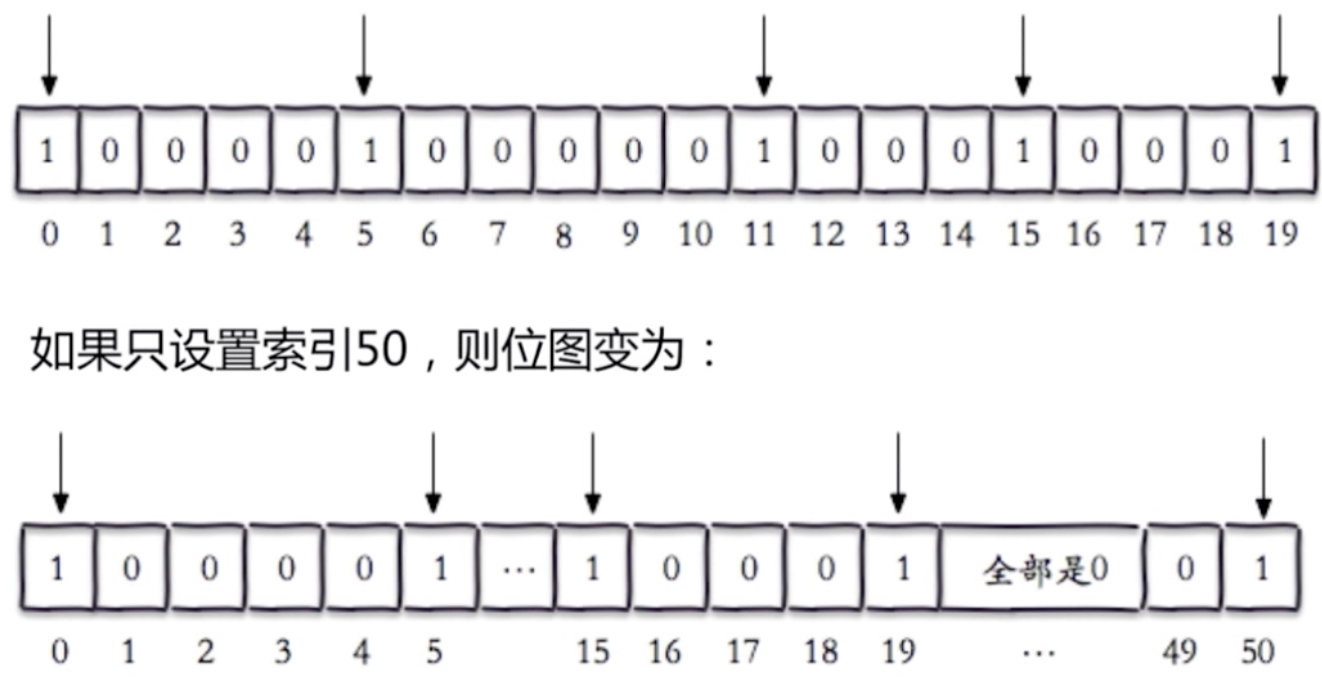
setbit hello 7 1 #把hello的第7个位置设为1 这样,big就变成了cig
setbit test 50 1 #test不存在,在key为test的value的第50位设为1,那其他位都以0补
bitcount key [start end] #获取位图指定范围(start到end,单位为字节,注意按字节一个字节8个bit为,如果不指定就是获取全部)位值为1的个数
bitop op destkey key [key...] #做多个Bitmap的and(交集)/or(并集)/not(非)/xor(异或),操作并将结果保存在destkey中
bitop and after_lqz lqz lqz2 #把lqz和lqz2按位与操作,放到after_lqz中
bitpos key targetBit start end #计算位图指定范围(start到end,单位为字节,如果不指定是获取全部)第一个偏移量对应的值等于targetBit的位置
bitpos lqz 1 #big 对应位图中第一个1的位置,在第二个位置上,由于从0开始返回1
bitpos lqz 0 #big 对应位图中第一个0的位置,在第一个位置上,由于从0开始返回0
bitpos lqz 1 1 2 #返回9:返回从第一个字节到第二个字节之间 第一个1的位置,看上图,为9
4.3 独立用户统计
1 使用set和Bitmap对比
2 1亿用户,5千万独立(1亿用户量,约5千万人访问,统计活跃用户数量)
数据类型
每个userid占用空间
需要存储用户量
全部内存量
set
32位(假设userid是整形,占32位)
5千万
32位*5千万=200MB
bitmap
1位
1亿
1位*1亿=12.5MB
假设有10万独立用户,使用位图还是占用12.5mb,使用set需要32位*1万=4MB
4.5 总结
1 位图类型是string类型,最大512M
2 使用setbit时偏移量如果过大,会有较大消耗
3 位图不是绝对好用,需要合理使用
五 HyperLogLog
5.1 介绍
基于HyperLogLog算法:极小的空间完成独立数量统计
本质还是字符串
5.2 三个命令
pfadd key element #向hyperloglog添加元素,可以同时添加多个
pfcount key #计算hyperloglog的独立总数
pfmerge destroy sourcekey1 sourcekey2#合并多个hyperloglog,把sourcekey1和sourcekey2合并为destroy
pfadd uuids "uuid1" "uuid2" "uuid3" "uuid4" #向uuids中添加4个uuid
pfcount uuids #返回4
pfadd uuids "uuid1" "uuid5"#有一个之前存在了,其实只把uuid5添加了
pfcount uuids #返回5
pfadd uuids1 "uuid1" "uuid2" "uuid3" "uuid4"
pfadd uuids2 "uuid3" "uuid4" "uuid5" "uuid6"
pfmerge uuidsall uuids1 uuids2 #合并
pfcount uuidsall #统计个数 返回6
5.3 内存消耗&总结
百万级别独立用户统计,百万条数据只占15k
错误率 0.81%
无法取出单条数据,只能统计个数
六 GEO
6.1 介绍
GEO(地理信息定位):存储经纬度,计算两地距离,范围等
北京:116.28,39.55
天津:117.12,39.08
可以计算天津到北京的距离,天津周围50km的城市,外卖等
6.2 5个城市纬度
城市
经度
纬度
简称
北京
116.28
39.55
beijing
天津
117.12
39.08
tianjin
石家庄
114.29
38.02
shijiazhuang
唐山
118.01
39.38
tangshan
保定
115.29
38.51
baoding
6.3 相关命令
geoadd key longitude latitude member #增加地理位置信息
geoadd cities:locations 116.28 39.55 beijing #把北京地理信息天津到cities:locations中
geoadd cities:locations 117.12 39.08 tianjin
geoadd cities:locations 114.29 38.02 shijiazhuang
geoadd cities:locations 118.01 39.38 tangshan
geoadd cities:locations 115.29 38.51 baoding
geopos key member #获取地理位置信息
geopos cities:locations beijing #获取北京地理信息
geodist key member1 member2 [unit]#获取两个地理位置的距离 unit:m(米) km(千米) mi(英里) ft(尺)
geodist cities:locations beijing tianjin km #北京到天津的距离,89公里
georadius key logitude latitude radiusm|km|ft|mi [withcoord] [withdist] [withhash] [COUNT count] [asc|desc] [store key][storedist key]
georadiusbymember key member radiusm|km|ft|mi [withcoord] [withdist] [withhash] [COUNT count] [asc|desc] [store key][storedist key]
#获取指定位置范围内的地理位置信息集合
'''
withcoord:返回结果中包含经纬度
withdist:返回结果中包含距离中心节点位置
withhash:返回解雇中包含geohash
COUNT count:指定返回结果的数量
asc|desc:返回结果按照距离中心店的距离做升序/降序排列
store key:将返回结果的地理位置信息保存到指定键
storedist key:将返回结果距离中心点的距离保存到指定键
'''
georadiusbymember cities:locations beijing 150 km
'''
1) "beijing"
2) "tianjin"
3) "tangshan"
4) "baoding"
'''
6.4 总结
3.2以后版本才有
geo本质时zset类型
可以使用zset的删除,删除指定member:zrem cities:locations beijing
Redis系列之——高级用法的更多相关文章
- Redis系列-好玩的用法
分布式锁 客户端执行如下命令,来获取锁和释放锁. random = random() ok = (Set key random PX 2000ms NX) if (ok) { //do somethi ...
- Redis系列目录
第一章 Redis系列之-redis初识 第二章 Redis系列之-常用命令及API的使用 第三章 Redis系列之-高级用法 第四章 Redis系列之-持久化 第五章 Redis系列之-使用常见问题 ...
- Redis系列三 - 缓存雪崩、击穿、穿透
前言 从学校出来,做开发工作也有一定时间了,最近有想系统地进一步深入学习,但发现基础知识不够扎实,故此来回顾基础知识,进一步巩固.加深印象. 最初开始接触编程时,总是自己跌跌撞撞.不断摸索地去学习,再 ...
- redis(二)高级用法
redis(二)高级用法 事务 redis的事务是一组命令的集合.事务同命令一样都是redis的最小执行单元,一个事务中的命令要么执行要么都不执行. 首先需要multi命令来开始事务,用exec命令来 ...
- EF5+MVC4系列(12) 在主视图中直接用RenderAction调用子Action,并返回视图(Return View)或者分部视图(Return PartialView); 从主Action传值到子Action使用TempData传值;TempData高级用法
结论: ViewData 适用于 在一次请求中 传递数据 . 比如我们从 主Action 到 主视图, 然后在 主视图中 用 RenderAction 请求子Action的时候,就是算作 一次请求 ...
- redis的Linux系统安装与配置、redis的api使用、高级用法之慢查询、pipline事物
今日内容概要 redis 的linux安装和配置 redis 的api使用 高级用法之慢查询 pipline事务 内容详细 1.redis 的linux安装和配置 # redis 版本选择问题 -最新 ...
- 分布式缓存技术redis系列(三)——redis高级应用(主从、事务与锁、持久化)
上文<详细讲解redis数据结构(内存模型)以及常用命令>介绍了redis的数据类型以及常用命令,本文我们来学习下redis的一些高级特性. 安全性设置 设置客户端操作秘密 redis安装 ...
- redis系列之3----redis高级应用(主从、事务与锁、持久化)
文章主目录 安全性设置 主从复制 事务与锁 持久化机制 发布以及订阅消息 上文<详细讲解redis数据结构(内存模型)以及常用命令>介绍了redis的数据类型以及常用命令,本文我们来学习下 ...
- flutter系列之:flutter中listview的高级用法
目录 简介 ListView的常规用法 创建不同类型的items 总结 简介 一般情况下,我们使用Listview的方式是构建要展示的item,然后将这些item传入ListView的构造函数即可,通 ...
- Redis系列(2)之数据类型
Redis系列(2)之数据类型 <Redis系列(1)之安装>中介绍了Redis支持以下几种数据类型,那么本节主要介绍学习下这几种数据类型的基本操作 字符串类型,string 散列类型,h ...
随机推荐
- 自然语言处理 Paddle NLP - 情感分析技术及应用-理论
自然语言处理 Paddle NLP - 信息抽取技术及应用 定义:对带有感情色彩的主观性文本进行 分析.处理.归纳和推理的过程 主观性文本分析:技术难点 背景知识 电视机的声音小(消极) 电冰箱的声音 ...
- Python运维开发之路《函数进阶》
面向对象类的进阶 抽象类 python 没有抽象类.接口的概念,所以要实现这种功能需要导入abc模块 py2:导入abc函数,_metaclass__ = abc.ABCMeta;在强制调用类下:@a ...
- 微信小程序 npm包、全局数据共享、分包
[黑马程序员前端微信小程序开发教程,微信小程序从基础到发布全流程_企业级商城实战(含uni-app项目多端部署)] https://www.bilibili.com/video/BV1834y1676 ...
- CF1728A Colored Balls: Revisited题解
去我的Blog观看 修改时间:2022/9/11修改了格式与标点 修改时间:2022/9/13修改了个别不严谨的语句 题目大意 有 \(n\) 种颜色的球,颜色为 \(i\) 的球为 \(cnt_i\ ...
- 报错 no currentsessioncontext configured!
no currentsessioncontext configured! 使用hibernate框架报错 配置了session工厂类,使用getCurrentSession();时候引起的,原因是cu ...
- 2023年郑州轻工业大学校赛邀请赛yy
这也是第一次参加几个人以组队的形式来进行答题.评比,而且这是一场线下赛,收获更是很多.题目一共有十二道,一共五个小时,我们上来也是没有头绪先做哪个,可能三个人的思路不太一样,我们最终先写了第一题,写出 ...
- 文心一言 VS 讯飞星火 VS chatgpt (64)-- 算法导论6.5 3题
文心一言 VS 讯飞星火 VS chatgpt (64)-- 算法导论6.5 3题 三.要求用最小堆实现最小优先队列,请写出 HEAP-MINIMUM.HEAP-EXTRACT-MIN.HEAP DE ...
- Redis 备忘录
redis是什么 Redis 是一个高性能的key-value数据库 常用操作 下载 官网:https://redis.io/ Linux版:https://redis.io/download Win ...
- OO第二次大作业
前言 前言的前言 第二篇blog跟上一篇只隔了将近一个月,但是感觉心境上好像发生了很多的变化,认识到了自己存在的很多不足(可能是菜单折磨的),感觉对很多东西都一知半解,希望在写完这篇总结性blog之后 ...
- Linux 修改文本dos/unix 格式
使用 vi 命令打开文件,使用 :set ff 查看格式 如果显示dos,可使用 :set ff=unix 修改 pem 证书,使用 cat xx.key xx.crt DigiCertCA.crt ...