多线程系列(二十一) -ForkJoin使用详解
一、摘要
从 JDK 1.7 开始,引入了一种新的 Fork/Join 线程池框架,它可以把一个大任务拆成多个小任务并行执行,最后汇总执行结果。
比如当前要计算一个数组的和,最简单的办法就是用一个循环在一个线程中完成,但是当数组特别大的时候,这种执行效率比较差,例如下面的示例代码。
long sum = 0;
for (int i = 0; i < array.length; i++) {
sum += array[i];
}
System.out.println("汇总结果:" + sum);
还有一种办法,就是将数组进行拆分,比如拆分成 4 个部分,用 4 个线程并行执行,分别计算,最后进行汇总,这样执行效率会显著提升。
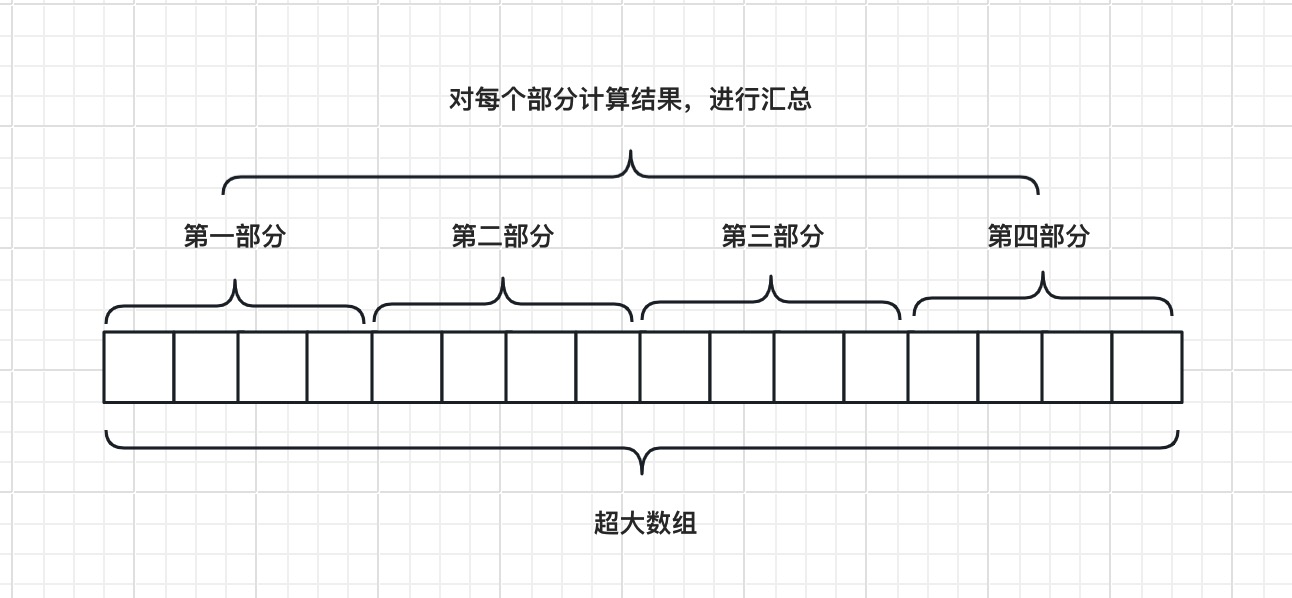
如果拆分之后的部分还是很大,可以继续拆,直到满足最小颗粒度,再进行计算,这个过程可以反复“裂变”成一系列小任务,这个就是 Fork/Join 的工作原理。
Fork/Join 采用的是分而治之的基本思想,分而治之就是将一个复杂的任务,按照规定的阈值划分成多个简单的小任务,然后将这些小任务的执行结果再进行汇总返回,得到最终的执行结果。分而治之的思想在大数据领域应用非常广泛。
下面我们一起来看看 Fork/Join 的具体用法。
二、ForkJoin 用法介绍
以计算 2000 个数字组成的数组为例,进行并行求和, Fork/Join 简单的应用示例如下:
public class ForkJoinTest {
public static void main(String[] args) throws Exception {
// 创建2000个数组成的数组
long[] array = new long[2000];
// 记录for循环汇总计算的值
long sourceSum = 0;
for (int i = 0; i < array.length; i++) {
array[i] = i;
sourceSum += array[i];
}
System.out.println("for循环汇总计算的值: " + sourceSum);
System.out.println("---------------");
// fork/join汇总计算的值
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Long> taskFuture = forkJoinPool.submit(new SumTask(array, 0, array.length));
System.out.println("fork/join汇总计算的值: " + taskFuture.get());
}
}
public class SumTask extends RecursiveTask<Long> {
/**
* 最小任务数组最大容量
*/
private static final int THRESHOLD = 500;
private long[] array;
private int start;
private int end;
public SumTask(long[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 检查任务是否足够小,如果任务足够小,直接计算
if (end - start <= THRESHOLD) {
long sum = 0;
for (int i = start; i < end; i++) {
sum += this.array[i];
}
return sum;
}
// 任务太大,一分为二
int middle = (end + start) / 2;
// 拆分执行
SumTask leftTask = new SumTask(this.array, start, middle);
leftTask.fork();
SumTask rightTask = new SumTask(this.array, middle, end);
rightTask.fork();
System.out.println("进行任务拆分,leftTask数组区间:" + start + "," + middle + ";rightTask数组区间:" + middle + "," + end);
// 汇总结果
return leftTask.join() + rightTask.join();
}
}
输出结果如下:
for循环汇总计算的值: 1999000
---------------
进行任务拆分,leftTask数组区间:0,1000;rightTask数组区间:1000,2000
进行任务拆分,leftTask数组区间:1000,1500;rightTask数组区间:1500,2000
进行任务拆分,leftTask数组区间:0,500;rightTask数组区间:500,1000
fork/join汇总计算的值: 1999000
从日志上可以清晰的看到,for 循环方式汇总计算的结果与Fork/Join方式汇总计算的结果一致。
因为最小任务数组最大容量设置为500,所以Fork/Join对数组进行了三次拆分,过程如下:
- 第一次拆分,将
0 ~ 2000数组拆分成0 ~ 1000和1000 ~ 2000数组 - 第二次拆分,将
0 ~ 1000数组拆分成0 ~ 500和500 ~ 1000数组 - 第三次拆分,将
1000 ~ 2000数组拆分成1000 ~ 1500和1500 ~ 2000数组 - 最后合并计算,将拆分后的最小任务计算结果进行合并处理,并返回最终结果
当数组量越大的时候,采用Fork/Join这种方式来计算,程序执行效率优势非常明显。
三、ForkJoin 框架原理
从上面的用例可以看出,Fork/Join框架的使用包含两个核心类ForkJoinPool和ForkJoinTask,它们之间的分工如下:
ForkJoinPool是一个负责执行任务的线程池,内部使用了一个无限队列来保存需要执行的任务,而执行任务的线程数量则是通过构造函数传入,如果没有传入指定的线程数量,默认取当前计算机可用的 CPU 核心量ForkJoinTask是一个负责任务的拆分和合并计算结果的抽象类,通过它可以完成将大任务分解成多个小任务计算,最后将各个任务执行结果进行汇总处理
正如上文所说,Fork/Join框架采用的是分而治之的思想,会将一个超大的任务进行分解,按照设定的阈值分解成多个小任务计算,最后将各个计算结果进行汇总。它的应用场景非常多,比如大整数乘法、二分搜索、大数组快速排序等等。
有个地方可能需要注意一下,ForkJoinPool线程池和ThreadPoolExecutor线程池,两者实现原理是不一样的。
两者最明显的区别在于:ThreadPoolExecutor中的线程无法向任务队列中再添加一个任务并在等待该任务完成之后再继续执行;而ForkJoinPool可以实现这一点,它能够让其中的线程创建新的任务添加到队列中,并挂起当前的任务,此时线程继续从队列中选择子任务执行。
因此在 JDK 1.7 中,ForkJoinPool线程池的实现是一个全新的类,并没有复用ThreadPoolExecutor线程池的实现逻辑,两者用途不同。
3.1、ForkJoinPool
ForkJoinPool是Fork/Join框架中负责任务执行的线程池,核心构造方法源码如下:
/**
* 核心构造方法
* @param parallelism 可并行执行的线程数量
* @param factory 创建线程的工厂
* @param handler 异常捕获处理器
* @param asyncMode 任务队列模式,true:先进先出的工作模式,false:先进后出的工作模式
*/
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
默认无参的构造方法,源码如下:
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
默认构造方法创建ForkJoinPool线程池,关键参数设置如下:
parallelism:取的是当前计算机可用的 CPU 数量factory:采用的是默认DefaultForkJoinWorkerThreadFactory类,其中ForkJoinWorkerThread是Fork/Join框架中负责真正执行任务的线程asyncMode:参数设置的是false,也就是说存在队列的任务采用的是先进后出的方式工作
其次,也可以使用Executors工具类来创建ForkJoinPool,例如下面这种方式:
// 创建一个 ForkJoinPool 线程池
ExecutorService forkJoinPool = Executors.newWorkStealingPool();
与ThreadPoolExecutor线程池一样,ForkJoinPool也实现了Executor和ExecutorService接口,支持通过execute()和submit()等方式提交任务。
不过,正如上面所说,ForkJoinPool和ThreadPoolExecutor在实现上是不一样的:
- 在
ThreadPoolExecutor中,多个线程都共有一个阻塞任务队列 - 而
ForkJoinPool中每一个线程都有一个自己的任务队列,当线程发现自己的队列里没有任务了,就会到别的线程的队列里获取任务执行。
这样设计的目的主要是充分利用线程实现并行计算的效果,减少线程之间的竞争。
比如线程 A 负责处理队列 A 里面的任务,线程 B 负责处理队列 B 里面的任务,两者如果队列里面的任务数差不多,执行的时候互相不干扰,此时的计算性能是最佳的;假如线程 A 的任务执行完毕,发现线程 B 中的队列数还有一半没有执行,线程 A 会主动从线程 B 的队列里获取任务执行。
在这时它们会同时访问同一个队列,为了减少线程 A 和线程 B 之间的竞争,通常会使用双端队列,线程 B 从双端队列的头部拿任务执行,而线程 A 从双端队列的尾部拿任务执行,确保两者不会从同一端获取任务,可以显著加快任务的执行速度。
Fork/Join框架中负责执行任务的线程ForkJoinWorkerThread,部分源码如下:
public class ForkJoinWorkerThread extends Thread {
// 所在的线程池
final ForkJoinPool pool;
// 当前线程下的任务队列
final ForkJoinPool.WorkQueue workQueue;
// 初始化时的构造方法
protected ForkJoinWorkerThread(ForkJoinPool pool) {
// Use a placeholder until a useful name can be set in registerWorker
super("aForkJoinWorkerThread");
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
}
3.2、ForkJoinTask
ForkJoinTask是Fork/Join框架中负责任务分解和合并计算的抽象类,它实现了Future接口,因此可以直接作为任务类提交到线程池中。
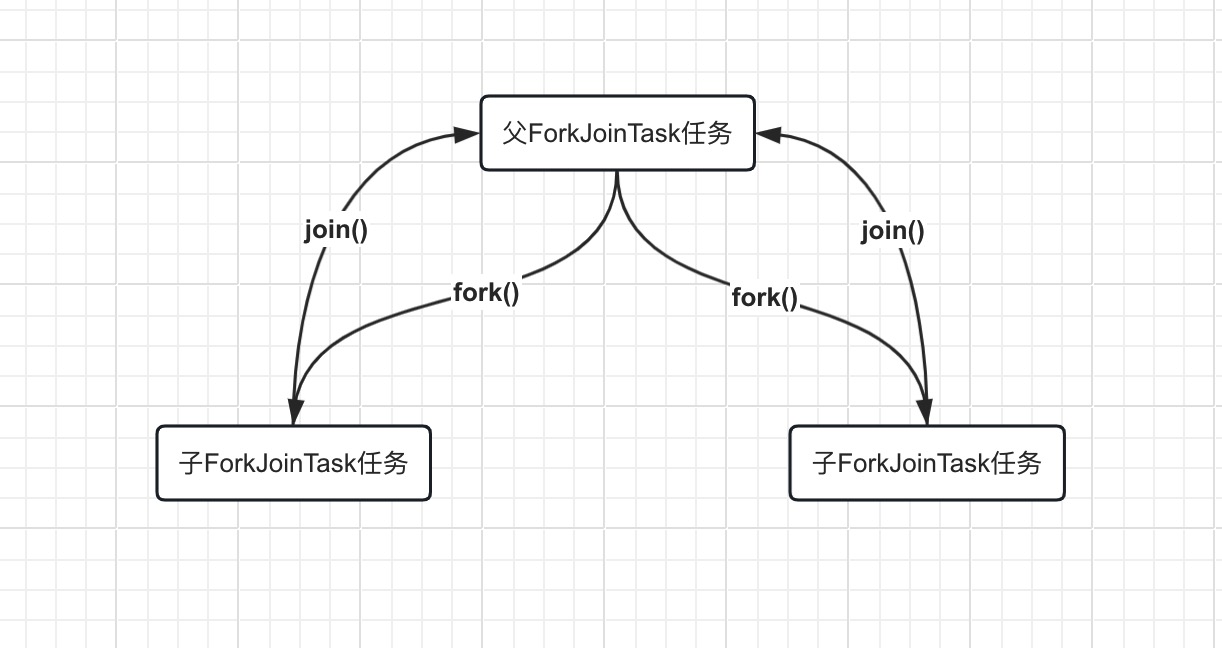
同时,它还包括两个主要方法:fork()和join(),分别表示任务的分拆与合并。
可以使用下图来表示这个过程。
ForkJoinTask部分方法,源码如下:
public abstract class ForkJoinTask<V> implements Future<V>, Serializable {
// 将任务推送到任务队列
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
// 等待任务的执行结果
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
}
在 JDK 中,ForkJoinTask有三个常用的子类实现,分别如下:
RecursiveAction:用于没有返回结果的任务RecursiveTask:用于有返回结果的任务CountedCompleter:在任务完成执行后,触发自定义的钩子函数
我们最上面介绍的用例,使用的就是RecursiveTask子类,通常用于有返回值的任务计算。
ForkJoinTask其实是利用了递归算法来实现任务的拆分,将拆分后的子任务提交到线程池的任务队列中进行执行,最后将各个拆分后的任务计算结果进行汇总,得到最终的任务结果。
四、小结
整体上,ForkJoinPool可以看成是对ThreadPoolExecutor线程池的一种补充,在工作线程中存放了任务队列,充分利用线程进行并行计算,进一步提升了线程的并发执行性能。
通过ForkJoinPool和ForkJoinTask搭配使用,将超大计算任务拆分成多个互不干扰的小任务,提交给线程池进行计算,最后将各个任务计算结果进行汇总处理,得到跟单线程执行一致的结果,当计算任务越大,Fork/Join框架执行任务的效率,优势更突出。
但是并不是所有的任务都适合采用Fork/Join框架来处理,比如读写数据文件这种 IO 密集型的任务就不合适,因为磁盘 IO、网络 IO 的操作特点就是等待,容易造成线程阻塞。
五、参考
1.https://www.liaoxuefeng.com/wiki/1252599548343744/1306581226487842
2.https://juejin.cn/post/6986899215163064333
3.https://developer.aliyun.com/article/806887
多线程系列(二十一) -ForkJoin使用详解的更多相关文章
- Velocity魔法堂系列二:VTL语法详解
一.前言 Velocity作为历史悠久的模板引擎不单单可以替代JSP作为Java Web的服务端网页模板引擎,而且可以作为普通文本的模板引擎来增强服务端程序文本处理能力.而且Velocity被移植到不 ...
- Zookeeper系列二:分布式架构详解、分布式技术详解、分布式事务
一.分布式架构详解 1.分布式发展历程 1.1 单点集中式 特点:App.DB.FileServer都部署在一台机器上.并且访问请求量较少 1.2 应用服务和数据服务拆分 特点:App.DB.Fi ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- Maven系列二setting.xml 配置详解
文件存放位置 全局配置: ${M2_HOME}/conf/settings.xml 用户配置: ${user.home}/.m2/settings.xml note:用户配置优先于全局配置.${use ...
- Linux学习之CentOS(二十一)--Linux系统启动详解
在这篇随笔里面将对Linux系统的启动进行一个详细的解释!我的实验机器是CentOS6.4,当然对于现有的Linux发行版本,其系统的启动基本上都是一样的! 首先我们来看下Linux系统启动的几个 ...
- Java 虚拟机系列二:垃圾收集机制详解,动图帮你理解
前言 上篇文章已经给大家介绍了 JVM 的架构和运行时数据区 (内存区域),本篇文章将给大家介绍 JVM 的重点内容--垃圾收集.众所周知,相比 C / C++ 等语言,Java 可以省去手动管理内存 ...
- Java多线程(三)—— synchronized关键字详解
一.多线程的同步 1.为什么要引入同步机制 在多线程环境中,可能会有两个甚至更多的线程试图同时访问一个有限的资源.必须对这种潜在资源冲突进行预防. 解决方法:在线程使用一个资源时为其加锁即可. 访问资 ...
- Java8初体验(二)Stream语法详解(转)
本文转自http://ifeve.com/stream/ Java8初体验(二)Stream语法详解 感谢同事[天锦]的投稿.投稿请联系 tengfei@ifeve.com上篇文章Java8初体验(一 ...
- Java8初体验(二)Stream语法详解---符合人的思维模式,数据源--》stream-->干什么事(具体怎么做,就交给Stream)--》聚合
Function.identity()是什么? // 将Stream转换成容器或Map Stream<String> stream = Stream.of("I", & ...
- 深入浅出Mybatis系列(四)---配置详解之typeAliases别名(mybatis源码篇)
上篇文章<深入浅出Mybatis系列(三)---配置详解之properties与environments(mybatis源码篇)> 介绍了properties与environments, ...
随机推荐
- 斐讯K3C改散热
斐讯K3C改散热 斐讯K3C日常使用还是不错的,就是日常的温度还是比较高的,不过冬天用来当暖手宝还是不错的. 这个改散热的方法是跟贴吧老哥学的,不得不说贴吧老哥还是牛皮,原贴在这,我当时拍的照片不够, ...
- ffmpeg之avformat_alloc_output_context2
函数原型: int avformat_alloc_output_context2(AVFormatContext **ctx, const AVOutputFormat *oformat, const ...
- 解决iso方式安装win10找不到固态硬盘!!!
问题说明 朋友的一台联想小新笔记本需要安装win10,我给弄了个iso启动U盘,但是在选择安装盘时找不到笔记本的固态硬盘... 问题原因 联想的锅! 以联想为例,出厂系统的BIOS内,SATA Con ...
- python课本学习第六章
一.字典的概念 #示例代码 student = {'name':'xx','name':'yy','grade1':98.1,'grade':99.2} print(student) #output: ...
- [BUUCTF][Web][GXYCTF2019]Ping Ping Ping 1
打开靶机对应URL 提示有ip参数 尝试构造url http://714ad4a2-64e2-452b-8ab9-a38df80dc584.node4.buuoj.cn:81/?ip=127.0.0. ...
- OpenResty中如何实现,按QPS、时间范围、来源IP进行限流
OpenResty是一个基于Nginx与Lua的高性能Web平台,它通过LuaJIT在Nginx中运行高效的Lua脚本和模块,可以用来处理复杂的网络请求,并且支持各种流量控制和限制的功能. 近期研究在 ...
- Mybatis-Plus自动生成代码的CodeGenerator代码
官方地址:Mybatis-Plus:https://mp.baomidou.com/guide/generator.html pom中导入mybatis plus的jar包,因为后面会涉及到代码生成, ...
- 项目实战:Qt + 树莓派3B+ 智能笔筒系统
红胖子(红模仿)的博文大全:开发技术集合(包含Qt实用技术.树莓派.三维.OpenCV.OpenGL.ffmpeg.OSG.单片机.软硬结合等等)持续更新中-(点击传送门) 需求 1.基于树莓 ...
- go值接收者和指针接收者的区别
方法的接收者 package main import ( "fmt" ) type Person struct { Name string Age int } func (p Pe ...
- ECMA Script Module(ES module)知识点
1.每个 ES Module 都是运行在单独的私有作用,ESM 自动采用严格模式,忽略use strict <script type="module">console. ...