GaussDB(DWS) NOT IN优化技术解密:排他分析场景400倍性能提升
摘要:本文针对8.1.2版本中的NOT IN场景的Mixed-HashJoin新技术进行介绍。该技术在GaussDB(DWS)与招商银行的联创项目中落地,为招商银行的批量作业带来了总体15%的性能提升。
本文分享自华为云社区《排他分析场景400倍性能提升-GaussDB(DWS) 独家NOT IN优化技术解密【这次高斯不是数学家】》,作者:两杯咖啡。
本文针对8.1.2版本中的NOT IN场景的Mixed-HashJoin新技术进行介绍。该技术在GaussDB(DWS)与招商银行的联创项目中落地,为招商银行的批量作业带来了总体15%的性能提升。同时,该文件也同时介绍了NOT IN的使用场景和在GaussDB(DWS)中的调优手段,希望各位读者试用该技术。
对于金融类客户业务来说,经常会出现类似基于某些条件排他的查找,例如:基于客户ID、客户ID和业务ID的组合,查找不在某个特征范围内的用户集合等等。此类查询特定记录的使用场景,可以使用NOT IN的语法来实现。NOT IN场景在分析型数据库中被广泛使用,例如:GaussDB(DWS)的大客户:工商银行、招商银行、光大银行在业务场景中都有数量众多的NOT IN语句。这类语句一般在进行集合排他比较时使用,例如如下语句:
select * from t1 where a not in (select a from t2);
该语句的语义为:查找a值不在t2表中的所有t1表中的记录。
由于NOT IN对于NULL值的特殊处理,导致这类语句无法使用高效的HashJoin进行高效处理,性能比较差,调优门槛比较高,成为困扰大多数客户的一大难题。Teradata、Oracle等数据库友商也针对 NOT IN问题进行了大量探索,但始终未能完美解决该场景的性能问题。GaussDB(DWS)在8.1.2最新版本实现了独家的分布式Mixed-HashJoin的NOT IN优化技术,在招商银行联合创新项目中得到了应用,共有近900个作业(占作业总数的3%)中包含的NOT IN语句性能平均提升400倍,招行生产集群单日所有作业端到端性能提升15%,效果明显,解决了客户的痛点问题。
这篇文章针对NOT IN的使用方法进行介绍,希望广大用户都可以尝试使用GaussDB(DWS)的NOT IN优化高级特性。
一. 数据库中的三值逻辑
提到NOT IN,就不得不提到数据库中的三值逻辑。在数理逻辑中,我们用true和false的二值逻辑表示真假,而在现实世界中,会存在一些数据,目前是未知的,因此存储在数据库中是用NULL来表示的,遇到NULL值运算时,我们也无法判断其真假,故引入了第三值逻辑,即NULL。注意,NULL值不同于空串,因为空串是一个固定的值。当然,在Oracle兼容的模式下,空串是被视为空值的,但在TD和MYSQL兼容模式下就是不等的。NULL值与任意值的比较均未知,属于游离于True和False之外的第三值,通俗来说,NULL值无法确定与任意值相等,但它可能是任意值,因此也无法确认NULL值与任意值不等。因此,如果需要查询NULL值,不能使用等值比较的方式,而应该使用IS NULL的形式,例如:
select * from t where a = NULL; --错误
select * from t where a is NULL; --正确
而NOT IN中的IN操作符,由于其与=的等价关系,导致IN和NOT IN操作符均不会包含NULL值,例如:
对于包含{1,-1,NULL}的数据表t,对应以下的查询结果:

上述后两条语句返回1,只有1符合条件。

上述两条语句返回1,只有-1符合条件;NULL和1的等值比较为NULL,取非后仍为NULL,不为真。

上述语句返回2,1和-1符合条件。

上述语句返回0,任意值与NULL比较结果均为NULL,非真。
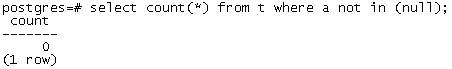
返回0,任意值比较结果NULL取非后仍为NULL,非真。
二. NOT IN的使用场景和示例
NOT IN一般在特征提取时会有广泛使用。例如:我们需要查找不符合A,B两个属性中部分属性组成的相应条件的特定人群,可以将相应的条件插入一个表t2中,例如:满足A=1且B=3,则将(1,3)插入表中;满足B=4时,A值置为NULL。然后将目标表和表t2进行NOT IN操作,含义为:查找(A,B)组合不为(1,3)、同时B不为4的元组。在金融行业中,经常出现基于某些条件组合进行用户的筛选的业务,条件组合中由于部分未知情况可能包含某些列的缺失,则业务逻辑就可以这样实现。
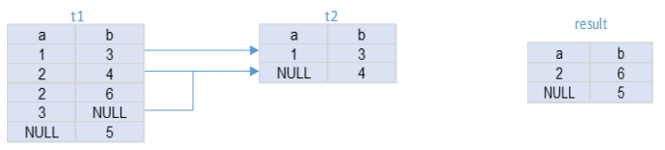
如上面例子所示,假如判断匹配的表t2(a, b)中包含如上两条记录,而参与查找的表t1(a,b)中包含5条记录:(1,3), (2,4), (2,6), (3,null), (null,5)。对于语句
select * from t1 where (a,b) not in (select a,b from t2);
在进行NOT IN运算时,NULL值可以看成和任意值匹配,只有两列中存在不匹配的列时,NOT IN返回true。t1各元组和t2目标表的匹配情况(如箭头所示)及输出结果result如下图所示。
三. NOT IN与NOT EXISTS的区别
某些数据库的用户还知道NOT EXISTS的用法,和NOT IN很相似,但是有一定区别。例如:上例的NOT IN语句可以改写成下面的语句:
select * from t1 where (a,b) not in (select a,b from t2);
->
select * from t1 where not exists (select 1 from t2 where t1.a=t2.a and t1.b=t2.b);
同样是获取不满足在某个范围内的元组,对于上例的输入,输出结果为4条元组,仅不包含(1,3)。为什么会这样呢?
通过上面的分析,我们可以知道,NOT IN中IN使用等值(=)比较,而NOT IN则使用不等值(<>)比较。对比起来,EXISTS同样使用等值(=)比较,而NOT EXISTS则等价于等值(=)比较取反,即EXISTS和NOT EXISTS是互补的。因此,IN和EXISTS是等价的,而NOT IN和NOT EXISTS是不等价的,两者之间差了NULL的处理,如下图所示。
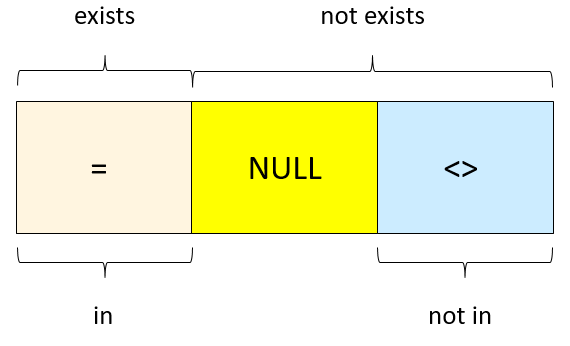
从另一个角度来理解,NOT IN运算相当于NULL值的强过滤,均不输出。NOT EXISTS运算则相当于不进行NULL值过滤,均输出。对比两个语句的执行计划,可以看出Join条件上的差别。由于NOT IN在内核使用Anti Join(反连接运算)来实现,即元组不匹配才输出,因此条件上也增加了NULL值返回true的条件。

四. GaussDB(DWS) NOT IN优化技术
NOT IN性能问题是业务公认的技术难题,友商Teradata和Oracle均针对NOT IN进行了部分场景的优化,即Null-aware技术,针对单列的NOT IN问题进行了NULL干预,但对于多列NOT IN问题仍然存在各种已知问题。下图为友商在NOT IN场景下,分布式以及单列/多列NOT IN的调研结论。
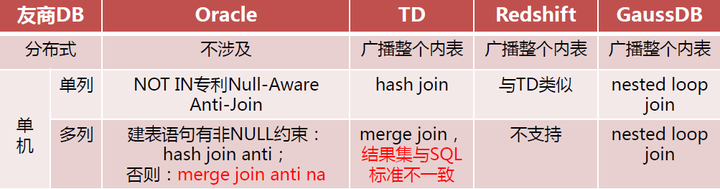
GaussDB(DWS)也一直致力于该问题的求解,新版本针对NOT IN有两个优化技术。
- NOT NULL约束识别。
通过上面的分析我们可以看出,NOT IN运算需要增加额外的NULL值判断,出现的OR条件导致必须通过低效的NestLoop计算。GaussDB(DWS)可以根据用户定义的NOT NULL约束来自动检测去掉NULL值判断,例如:上面的语句中,如果t1表的a列,及t2表的a列上均有NOT NULL约束,则条件t1.a=t2.a不再包含NULL值判断的OR条件,可以转化为高效的HashJoin来进行处理。同时,GaussDB(DWS)也支持部分表达式的NULL值推导,只要基表列上包含NOT NULL约束,参与NOT IN运算的表达式也可以由于推导出的NOT NULL约束进行计划层的优化。
- 分布式Mixed-HashJoin技术。
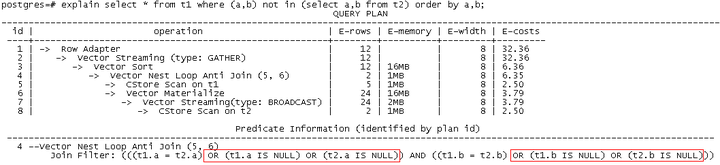
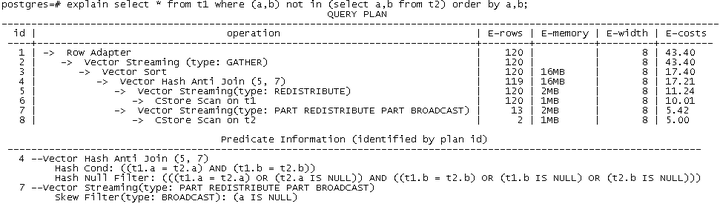
如果NOT IN运算的列值中包含NULL值,则必须采取对NULL值的单独处理来解决问题。GaussDB(DWS) 8.1.2版本实现了分布式Mixed-HashJoin技术,在执行时各DN可以动态分离出包含NULL值的元组,进行NestLoop特殊匹配处理;而对于非NULL值,则可以使用高效的HashJoin来进行执行。由于业务中的NULL值为不确认因素,所占的比例较少,因此,该技术可以保证该类场景的性能优势最大化,在NULL值很少的场景,性能和NOT EXISTS持平。新版本执行计划如下所示:

该技术目前已经支持向量化引擎,后续将针对行引擎进行进一步的完善。同时,针对不同列的NULL值情况,也可以建多个NULL值的hash表加速匹配,避免NULL值过多时使用NestLoop仍然过慢。
同时,由于外表的NULL值可能匹配到内表的任意值,因此通常需要将内表进行广播(Broadcast)操作。如果内表较大,则占用较多网络资源且影响性能。此时,如果外表在NOT In的某列上有NOT NULL约束,内表可以在该列上对非NULL值进行重分布,仅广播NULL值,减少网络数据发送量。例如,如果上例中,t1表的a列包含NOT NULL约束,则会生成如下的计划(t2表对应的a列进行了重分布,同时将NULL值广播):
五. NOT IN场景的调优手段
如果使用GaussDB(DWS)早期版本的用户也不必着急,本章介绍一些NOT IN场景的调优手段,供大家在实践中使用。
- 修改NOT IN为NOT EXISTS
上文详细分析了NOT IN和NOT EXISTS的区别。因此,如果用户可以通过自身的业务逻辑,确认NOT EXISTS的语义也可以满足,通常可能是因为对于NULL值的处理不关心,或者数据中根本不存在NULL值,则可以通过等价改写将NOT IN改写为NOT EXISTS来进行优化。通用改写方法为:
… WHERE … (col1, col2, …, coln) NOT IN (SELECT c1, c2, …, cn FROM …) … 改写为: … WHERE NOT EXISTS(SELECT 1 FROM … WHERE col1=c1 AND col2=c2 AND … AND coln=cn ...) …
- 为基表列增加NOT NULL约束
由于GaussDB(DWS)在早期版本中即支持NULL值的推导逻辑,因此可以通过对NOT IN运算的基表列增加NOT NULL约束,将OR条件转化为等值条件进行优化。注意,对于多列的NOT IN场景,仅需要将内外表对应的一列均增加NOT NULL约束即可进行调优。例如上例,可以单独为col1和c1增加NOT NULL约束,也可以为coln和cn增加NOT NULL约束,以此类推。也可以在SQL语句里显式增加IS NOT NULL的条件来过滤掉无用的NULL值,或者提示优化器该列上的非空约束,例如:select * from t1 where (a,b) not in (select a, b from t2 where a is not null) and a is not null;
- 使用Mixed-HashJoin新技术
8.1.2版本中,由于分布式Mixed-HashJoin技术仅支持向量化引擎,因此可以通过将语句中涉及的表均创建为列存表,并设置参数rewrite_rule包含’notinopt’值,即可使用新的技术。由于该参数为多值参数,因此,需要通过show rewrite_rule命令查看当前设置的值(如未设置则为默认值),通过在其后添加’notinopt’值进行设置。关于rewrite_rule的其它值,后续将在其它文章中介绍。
如果用户使用的表为行存表,GaussDB(DWS)还提供参数enable_force_vector_engine强制使用向量化引擎处理,同样可以使用新技术。该参数为bool值,默认为off。以上两个参数均可以session级设置生效。
进一步地,为了减少内表广播带来的资源消耗,如果在外表某些NOT IN列理论上不为空的情况下,可以为其中某些列增加NOT NULL约束,或在语句中指定IS NOT NULL条件,则可以通过数据重分布减少网络发送量,进一步提升性能。
六. 结语
通过本文的分析,相信用户朋友已经充分了解了分析型业务排他操作-NOT IN的使用场景、SQL语法,以及GaussDB(DWS)的NOT IN实现方式,可行的调优方法。希望广大用户能够通过深入的了解,对GaussDB(DWS)的性能调优产生浓厚的兴趣并深度参与进来。如NOT IN问题的攻克一样,GaussDB(DWS)目前正着力解决其它棘手的性能问题,期待在其它场景中,也可以给用户带来极致的性能体验,减少用户调优的成本。
理论不如实践,那如何快速体验DWS呢?DWS现推出了一项Demo体验活动。进入DWS首页,点击“Demo体验”,快速便捷体验一把!体验过程中有任何建议和意见,可以去DWS社区论坛反馈哦;)
GaussDB(DWS) NOT IN优化技术解密:排他分析场景400倍性能提升的更多相关文章
- 详解GaussDB(DWS) explain分布式执行计划
摘要:本文主要介绍如何详细解读GaussDB(DWS)产生的分布式执行计划,从计划中发现性能调优点. 前言 执行计划(又称解释计划)是数据库执行SQL语句的具体步骤,例如通过索引还是全表扫描访问表中的 ...
- 十八般武艺玩转GaussDB(DWS)性能调优(三):好味道表定义
摘要:表结构设计是数据库建模的一个关键环节,表定义好坏直接决定了集群的有效容量以及业务查询性能,本文从产品架构.功能实现以及业务特征的角度阐述在GaussDB(DWS)的中表定义时需要关注的一些关键因 ...
- 从数据仓库双集群系统模式探讨,看GaussDB(DWS)的容灾设计
摘要:本文主要是探讨OLAP关系型数据库框架的数据仓库平台如何设计双集群系统,即增强系统高可用的保障水准,然后讨论一下GaussDB(DWS)的容灾应该如何设计. 当前社会.企业运行当中,大数据分析. ...
- GaussDB(DWS)应用实践丨负载管理与作业排队处理方法
摘要:本文用来总结一些GaussDB(DWS)在实际应用过程中,可能出现的各种作业排队的情况,以及出现排队时,我们应该怎么去判断是否正常,调整一些参数,让资源分配与负载管理更符合当前的业务:或者在作业 ...
- 十八般武艺玩转GaussDB(DWS)性能调优:SQL改写
摘要:本文将系统介绍在GaussDB(DWS)系统中影响性能的坏味道SQL及SQL模式,帮助大家能够从原理层面尽快识别这些坏味道SQL,在调优过程中及时发现问题,进行整改. 数据库的应用中,充斥着坏味 ...
- 十八般武艺玩转GaussDB(DWS)性能调优:路径干预
摘要:路径生成是表关联方式确定的主要阶段,本文介绍了几个影响路径生成的要素:cost_param, scan方式,join方式,stream方式,并从原理上分析如何干预路径的生成. 一.cost模型选 ...
- GaussDB(DWS)中共享消息队列实现的三大功能
摘要:本文将详细介绍GaussDB(DWS)中共享消息队列的实现. 本文分享自华为云社区<GaussDB(DWS)CBB组件之共享消息队列介绍>,作者:疯狂朔朔. 1)共享消息队列是什么? ...
- 细说GaussDB(DWS)复杂多样的资源负载管理手段
摘要:对于如此多的管控功能,管控起来实际的效果到底如何,本篇文章就基于当前最新版本,进行效果实测,并进行一定的分析说明. 本文分享自华为云社区<GaussDB(DWS) 资源负载管理:并发管控以 ...
- 一文详解GaussDB(DWS) 的并发管控和内存管控
摘要:DWS的负载管理分为两层,第一层为cn的全局并发控制,第二层为资源池级别的并发控制. 本文分享自华为云社区<GaussDB(DWS) 并发管控&内存管控>,作者: fight ...
- GaussDB(DWS)网络调度与隔离管控能力
摘要:调度算法是调度器的核心,设计调度算法要充分考虑业务场景和用户需求,没有万能的调度算法,只有合适的调度算法. 本文分享自华为云社区<GaussDB(DWS)网络调度与隔离管控能力>,作 ...
随机推荐
- js闭包使用之处
1.循环绑定 No Use: var lists = document.getElementsByTagName('li'); for(var i=0;i<lists.length;i& ...
- C# -WebAPIOperator.cs
说明:一个用C#编写的WebAPI操作类,只写了Get Post 部分. using Newtonsoft.Json; using Newtonsoft.Json.Linq; using System ...
- 2023 SHCTF-校外赛道 WEB WP
WEEK1 babyRCE <?php $rce = $_GET['rce']; if (isset($rce)) { if (!preg_match("/cat|more|less| ...
- eclipse安装velocity插件(转)
http://www.jspxcms.com/knowledge/46.html http://blog.csdn.net/superbeck/article/details/5721382 插件地址 ...
- C#判断字符串的显示宽度
C#判断字符串的显示宽度 起因: 公司有一个使用项目使用HTML转换为PDF,其中有一个表格,表格的最后一列中的单元格,其字符串超长后会被丢弃,而不是换行到下一行展示(HtmlToPdf渲染引擎导致的 ...
- Senparc 基础库全面适配 .NET 8.0
概要 Senparc 全家桶中的基础库已经全面适配 .NET 8.0,目前随着 .NET 8.0 的 RC 版本不断发布,对应的版本号也将同步进行更新,直到本月 Ignite 大会微软官方发布 .NE ...
- 放弃"Jenkins"的种种理由,期待更好赋能研发的持续交付平台
Jenkins 很酷,但是不完美,有历史局限性造成的问题.本文仅从"如何更好给研发团队赋能的角度",剖析Jenkins, 探讨理想的持续交付平台, 不带货无广告- 不完美的Jenk ...
- PEP9
利用循环语句 counter 是计数器 需要在后面输入个3才是3个数字之和 Set sum to 0 Set counter to 0 Set limit to number of values to ...
- 【VMware NSX-T】在vCenter内直接将Manager设备删除后,ESXi上还遗留N-VDS交换机及网卡被占用等问题的解决方法。
由于之前在实验平台安装了NSX-T的测试环境,但是由于太忙了没怎么测试,后来实验环境出了点小问题,索性就将上面所有虚拟机给清空了.但是没想到上面遗留了NSX-T上创建的N-VDS交换机,还占用了服务器 ...
- Modbus通用串口转PROFINET IO网关TS-180 在锅炉厂智能温湿度监控系统中的应用
背景: 现代科学技术和工业的迅速发展,不断促进着自动化控制技术及设备通信技术的创新和发展.当前,PLC.DCS.智能仪表等已广泛应用到现场生产控制系统中,本应用案例是在锅炉行业的温湿度监控系统中,西门 ...