python编码格式
python编码总结:
1).首先python有两种格式的字符串,str和unicode,其中unicode相当于字节码那样,可以跨平台使用。
str转化为unicode可以通过unicode(),u,str.decode三种方式
unicode转化为str,如果有中文的话,一般通过encode的方式
2).如果代码中有中文的话,我们一般会添加 "# coding=utf-8",这个是什么作用呢,一般如下:
- 如果代码中有中文注释,就需要此声明
- 比较高级的编辑器(比如我的emacs),会根据头部声明,将此作为代码文件的格式。
- 程序会通过头部声明,解码初始化 u”人生苦短”,这样的unicode对象,(所以头部声明和代码的存储格式要一致
所以,当我们填上编码头的时候,使用s="中文",实际上type(s)是一个str,是已经将unicode以utf-8格式编码成str。
其次,如果我们在代码中使用s=u'中文',相当于将str以utf-8解码成unicode.
# coding=utf-8
__author__ = 'lenovo' a='中文'
print a,type(a) a2=unicode(a,"utf-8")
print a2,type(a2) a3=u'中文'
print a3,type(a3)
这样的输出如下,说明声明头的作用一方面是自动将unicode转化为utf-8,另一方面是使用u的时候指定了utf-8:

3)如果在unicode上面再unicode的话,实际上并没有起到效果
a='中文'
a2=unicode(a,"utf-8")
print a2,type(a2) a3=unicode(a2)
print a3,type(a3)
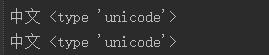
4)u,unicode()和str.decode等价,都可以将str转化成unicode。但是decode不能像unicode()那样连续调用
a='中文'
a2=unicode(a,"utf-8")
a3=a.decode("utf-8")
print a2,type(a2)
print a3,type(a3)
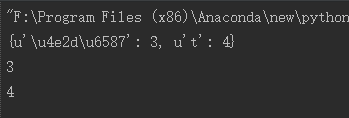
5)当使用map存储的key为中文的时候,可以str转化成unicode才行,这样就可以跨平台
a='中文'
map={}
map[a.decode('utf-8')]=3
map[unicode('t')]=4
print map
print map[u'中文']
print map['t']
6)一个需要注意的点就是ascii码的话,unicode和str等价,也就是unicode('t')=='t'
7)文件操作时,open(filename),要求文件的格式和编码头一致,这样读取后是str类型
如果不一致,可以调用io.open()并且指定编码,这样读取后是unicode
python编码格式的更多相关文章
- 解决python编码格式错误问题
一:前言 遇到问题:print输入汉字时提示错误信息 UnicodeDecodeError: 'ascii' codec can't decode byte 0x?? in position 1: o ...
- Python编码格式导致的csv读取错误
Python编码格式导致的csv读取错误(pandas.read_csv) 本文记录python小白我今天遇到的这两个问题(csv.reader和pandas.csv_read): pandas模块“ ...
- Python编码格式的指定方式
参考自: http://python.jobbole.com/85852/, 原文探究的更深,有兴趣的可以去看看. 简介来讲就是使用一种特殊的注释来声明编码格式,如何判断这种格式也用了很简单粗暴有效的 ...
- python 编码格式
1. 字符编码简介 1.1. ASCII ASCII(American Standard Code for Information Interchange),是一种单字节的编码.计算机世界里一开始只有 ...
- Python 编码格式的使用
编码史 ASCII > Unicode > UTF-8 Unicode支持多语言,UTF-8自动转换长短细节节省空间 在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传 ...
- Python 浅谈注释的重要性
最近参加了一个比赛,然后看到队友编程的代码,我觉得真的是难以下咽,几乎每个字符都要咨询他,用老师的话来说,这就是山炮编程员,所以此时的我意识到写一篇关于注释程序的重要性了,因此特地的写一篇文章帮助大家 ...
- Python 浅谈编程规范和软件开发目录规范的重要性
最近参加了一个比赛,然后看到队友编程的代码,我觉得真的是觉得注释和命名规范的重要性了,因为几乎每个字符都要咨询他,用老师的话来说,这就是命名不规范的后续反应.所以此时的我意识到写一篇关于注释程序的重要 ...
- Python UNICODE GBK UTF-8 之间相互转换
Python 编码格式检测,可以使用 chardet , 例如: import urllib rawdata = urllib.urlopen('http://www.google.cn/').rea ...
- python浅谈编程规范和软件开发目录规范的重要性
前言 我们这些初学者,目前要做的就是遵守代码规范,这是最基本的,而且每个团队的规范可能还不一样,以后工作了,尽可能和团队保持一致,目前初学者就按照官方的要求即可 新人进入一个企业,不会接触到核心的架构 ...
随机推荐
- 【solr专题之三】Solr常见异常
1.RemoteSolrException: Expected mime type application/octet-stream but got text/html 现象: SLF4J: Fail ...
- [C++程序设计]用数组名作函数参数
1. 用数组元素作函数实参 #include <iostream> using namespace std; int max_value(int x, int max) { return ...
- 话说 MAX_FILE_SIZE
PHP关于文件上传部分,特别提到表单隐藏域:MAX_FILE_SIZE,意思是接收文件的最大尺寸.文档中给出的例子如下: <form enctype="multipart/form-d ...
- ZendFramework2 文件结构
Application |__ config // 配置文件目录 |__ language // 语言包目录 |__ src |__ Application |__ Controller // 控制器 ...
- Delphi 10.1 Berlin 与 Delphi 10 Seattle 共存
以下安装环境是win7 64位 1. 安装Delphi10.1 Berlin 版本. 2.修改C:\Program Files (x86)\Embarcadero\Studio\18.0\cglm.i ...
- 摆方块(贪心)P1087
描述 给你一个n*n的方格,每个方格里的数必须连续摆放如 1 2 4 3 ,下图为不连续的,请输出从左上角到右下角的对角线上的最大和 1 2 3 4 输入 ...
- perl 爬取某理财网站产品信息
use LWP::UserAgent; use utf8; use DBI; $user="root"; $passwd="xxxxx"; $dbh=" ...
- 生成excel文件
java操作Excel最常用的开源组件有poi与jxl.jxl是韩国人开发的,发行较早,但是更新的很慢,目前似乎还不支持excel2007.poi是apache下的一个子项目,poi应该是处理ms的o ...
- ZOJ3761(并查集+树的遍历)
Easy billiards Time Limit: 2 Seconds Memory Limit: 65536 KB Special Judge Edward think a g ...
- hdu 5631 Rikka with Graph(图)
n个点最少要n-1条边才能连通,可以删除一条边,最多删除2条边,然后枚举删除的1条边或2条边,用并查集判断是否连通,时间复杂度为O(n^3) 这边犯了个错误, for(int i=0;i<N;i ...